基于Gradient Boosting算法的ERMS輻射數據預測①
2019-11-15 07:05:46朱武峰王廷銀林明貴蘇偉達李汪彪吳允平
計算機系統應用 2019年11期
朱武峰,王廷銀,林明貴,蘇偉達,李汪彪,吳允平,3,4
1(福建師范大學 光電與信息工程學院,福州 350007)
2(福建省輻射環境監督站,福州 350013)
3(數字福建環境監測物聯網實驗室,福州 350117)
4(福建省光電傳感應用工程技術研究中心,福州 350000)
引言
核能發電不僅經濟高效、排放無污染,而且原料來源廣泛,是當今社會重要的電力能源之一[1],通常,核電站會圍繞自身建立輻射監測系統(Radiation Monitoring System,RMS),以保障運行安全[2];其中,環境輻射監測系統(ERMS)是RMS 的一個重要組成部分;所謂ERMS,是為了保證核電站外圍環境安全,在核電站四周若干公里范圍內設置若干個監測站點,每個監測站點都會配備監測儀器和通信裝置,以便通過網絡把數據傳到計算機.其系統數據采集框架如圖1所示,監測站采集設備主要分為輻射數據采集設備(如NaI 能譜探測儀和高壓電離室)和氣象數據采集設備(如雨量計、溫度傳感器、風速傳感器等),采集的數據種類主要有HPIC劑量率、雨量、氣溫、濕度及風速風向等;其中,HPIC劑量率是指示輻射監測站點實時γ輻射空氣吸收劑量率的重要指標.
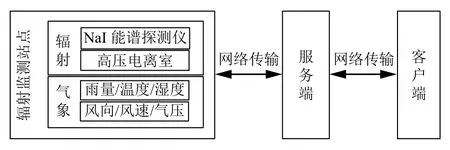
圖1 ERMS 系統數據采集系統框架圖
這些數據蘊含著核電站運行安全性的重要價值指示信息,一直以來都是各國保障核電安全的研究熱點,具有重大的研究意義.
國外,2015年,Chen 等人[3]針對γ輻射劑量率的仿真模擬問題,以蒙特卡羅方法為基礎提出一種可用于進行曝光劑量估計的光譜測定G(E)函數方法,用于進行γ劑量率的仿真模擬,獲得的仿真值與電離室測量的γ劑量率實際值之間最大偏差僅6.31%,對確保γ劑量率的可靠性具有很大應用價值.2017年,印尼國家核安全局的Susila 等人[4]則對塞彭核設施周圍5年的序列輻射數據應用關聯分析方法進行分析,發現γ輻射劑量率的數值與空氣中碘和氬的放射性同位素含量具有較強的正相關關系;同年,Bossew 等人[5]指出空氣中的天然放射性元素氡與γ輻射劑量率也有較強關系,采用統計關聯方法對歐洲地區兩者之間進行相關性研究,得出大部分地區氡對γ輻射劑量率的監測結果的貢獻值低于5 nSv/h,部分地區則達到30 nSv/h,這對加強核輻射環境監測的預警能力具有很好的參考意義.
國內,2015年,朱耀明、林明貴等人[6]提出要加強ERMS 數據應用能力和人員配置管理問題,指出對ERMS 管理維護上要安排專業工作人員,以便可以立時應對不同緊急情況,如當出現輻射數據異常或多個站點γ輻射劑量率數值超高,觸發閾值報警時,確保工作人員可以及時收到預警信息并迅速進行處理,查找問題根源以尋求解決.2017年,高澤泉等人[7]則應用線性統計方法對序列輻射數據中降雨與γ輻射劑量率的相關性進行分析發現,降雨天氣時,降雨會導致γ輻射劑量率的升高,造成γ輻射劑量率的實時數值的不準確性,這對我們在日常監測中進行γ輻射劑量率數值的判斷是一個很好的參考指標.2018年,羅敦燁等人[8]也基于線性統計方法、關聯分析及可視化技術對日常監測中γ輻射劑量率的特征影響因子進行了更全面的挖掘分析,總結了眾多與γ輻射劑量率數據相關的特征影響因子,如宇宙射線、自然放射性物質、溫濕度、風向及氣壓等氣象因素,這對建立和完善γ輻射劑量率數值可靠性評價指標具有很大意義.
總的來說,在ERMS日常監測過程中,γ輻射監測數值的影響因素較多,如上述的源相關的放射性物質、降雨、溫濕度、風向及氣壓等自然因素,還有設備老化故障等都會導致γ輻射監測數據的不準確性.近年,我國物聯網技術愈發成熟,數據資源獲取能力逐步增強,圍繞ERMS 的設備可靠性、數據可信度以及源相關性等方面取了一些進展,但ERMS 輻射數據分析卻仍以實時數據判定、事后報警為主;圍繞γ劑量率監測也進行相關影響因子的定性分析,提供了對實時γ劑量率監測準確性的輔助判斷依據,但是在一定程度上對各影響因子融合進行數據價值挖掘未作出過多研究,如在自然因子影響下,如何有效識別和降低自然因素干擾,提高對HPIC 劑量率的可靠性評估能力.而當今數據挖掘在醫療衛生[9]、網絡安全[10]、企業管理[11]、城市交通[12]及工業生產[13]等諸多領域都取得了顯著的應用成果,為我們提升智能化監管效率和實現新的監管技術創新指出了新思路.其中以GB 回歸為代表的人工智能算法,在解決回歸問題上發揮了巨大的優勢.2013年,山東大學陳爽爽等[14]人應用GB 算法對癲癇及復發概率數據進行建模,取得很好的檢測效果,達到了初步臨床實驗的標準;2015年,瑞典艾滋病研究團隊為預測戒煙成功率和艾滋病復發率,采用GB 算法模型進行回歸分析,取得很好的效果,具有很強的實用性[15];而縱觀我們的輻射監測數據、太陽活動數據及氣象數據,整體為時間序列的離散值,以HPIC 劑量率值作為γ劑量率監測的重要指標,特征數據有類別特征(如風向)、離散值(如雨量、各監測站點HPIC 劑量率歷史數據、溫濕度及天頂方向電子量VETC 等),其總體數據特征完全符合GB 算法模型,而且對模型誤差,我們不排除其他因素干擾,充分考慮作為回歸模型輸入特征,可以一定程度排除未知因素干擾.GB 算法對幫助我們解決ERMS 中HPIC 劑量率在線預測的問題是一個較佳選擇.
1 GB 算法理論
GB 算法[16]是一種機器學習方法,其算法的核心思想在于:將損失函數看作模型的“靠譜程度”,當損失函數數值較大時,說明模型的可信度較低,預測結果的準確率較差.因此,我們通常會根據起始的損失函數,進行損失函數的優化工作,通常做法是根據梯度下降法來實現損失函數在梯度方向上的不斷迭代減小直至收斂,此時模型最優,殘差也達到最小值,殘差通常認為就是目標實際值與模型預測值的誤差.基于GB 算法進行回歸預測大致流程如圖2所示,首先基于訓練集建立一個基模型,然后將這個模型的殘差作為下一個模型的優化學習目標輸入,得到新的基模型,不斷重復此迭代過程,直到模型的殘差達到理想數值范圍內.
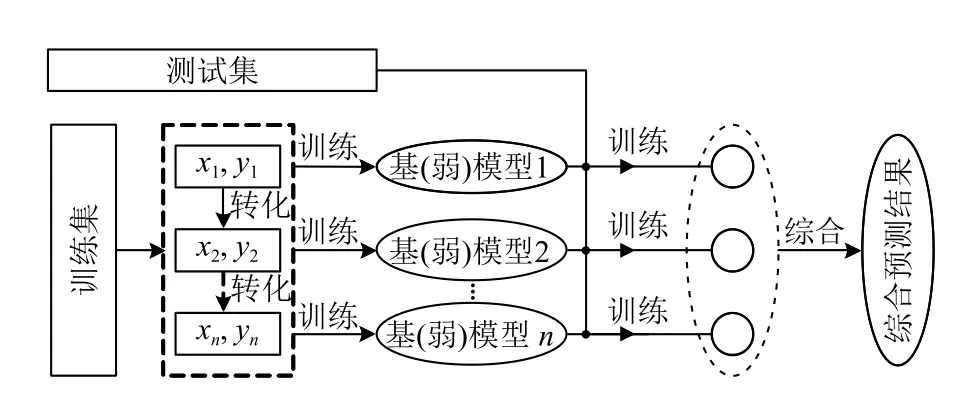
圖2 Gradient Boosting 回歸模型預測流程圖
算法基本形式可表示如下:
算法的輸入數據集是一組屬性值x={x1,x2,···,xm)及 實際值y={y1,y2,···,ym},設定與之間具有某種回歸關系:
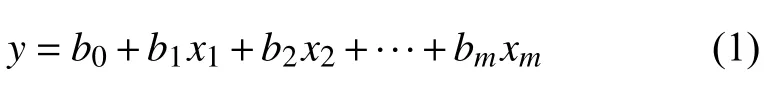
設定損失函數為L(y,f(x)),基函數是{a(x;γ)}.首先,設定初始化預測函數為:

其次,設置算法最大迭代次數N,在設定的迭代次數基礎上:
(1) 極小化算法的損失函數,使用如下方式求得使損失函數最小化的最佳參數bn,γn:
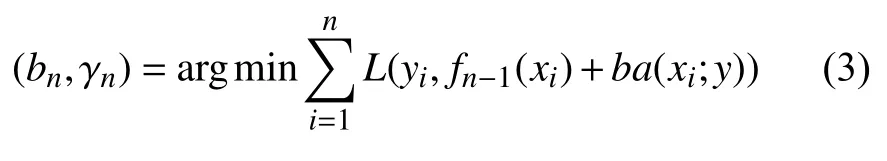
(2) 迭代更新預測函數,在舊的弱學習器基礎上不斷學習新的弱學習器(決策樹) 模型fn(x)來優化模型損失函數,如下式:
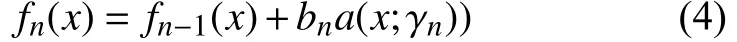
(3) 累加預測函數,求得最終強學習器預測函數公式如下:
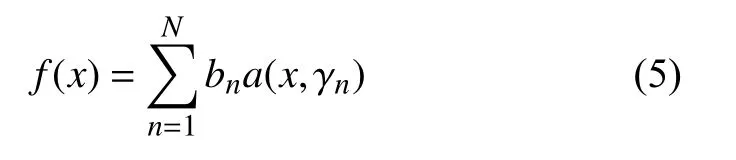
GB 算法是一種集成學習算法.該算法基于多個弱學習器組成強學習器的思想,可以很好地克服算法建模中存在的諸如過擬合問題等,在解決分類回歸問題上具有很好的適用性.
2 GB 算法在輻射監測數據挖掘的應用
2.1 環境輻射監測系統概況
如圖3所示為福建省某S 核電站ERMS 輻射監測站點空間分布圖,以此核電站為中心,在周圍設置了11 個監測子站;從圖3中可以看出,S1-S11號自動站圍繞核電站整體呈現放射狀分布,保證充分檢測四周環境放射性核素劑量,同時實施多點連續監測,在一定程度上可以更好地防止突發情況發生,提高安全效率,這樣就形成了區域核輻射外圍網絡分布.
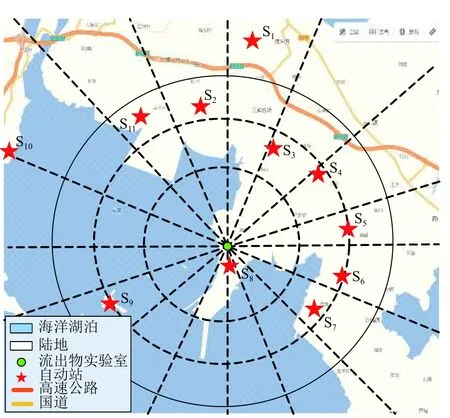
圖3 某核電站ERMS 輻射監測站空間分布圖
2.2 數據來源
數據資料主要分3 部分:(1)輻射監測子站環境日常監測數據可以從某核電站輻射監測中心平臺數據庫直接導出2015-2017年文本格式歷史輻射監測數據;(2)所需太陽日常活動歷史數據從空間環境預報中心直接獲取,以對方提供的2015-2017年文本格式天頂方向電子量VTEC 數據為主;(3)氣象數據指標可從氣象局網站通過網頁記錄獲取,相關數據指標如表1.

表1 數據來源
2.3 實驗方案
2.3.1 實驗環境
硬件方面,本實驗運用8 核、16 GB 內存PC 機進行.
軟件方面,在Windows10 系統環境下配置JDK1.8、Anaconda3.4 及MySql 等,以Mysql 作為文件存儲數據庫進行數據存儲,以Anaconda3.4 自帶軟件Spyder作為實驗編程平臺,以Python 作為程序編程語言,借助Python 第三方科學計算相關類庫(如numpy、pandas、matplotlib 及sklearn 等)進行整體數據挖掘分析工作;具體實驗環境配置如表2所示.
2.3.2 模型設計方案
如圖4所示為本實驗模型構建整體實驗過程方案,主要包括數據存儲、數據預處理、數據抽取、數據建模及模型應用五部分.首先,實驗數據主要為3.2 中闡述的歷史離線數據集,數據特征為時間序列的離散型數據,所以采用MySQL 數據庫進行數據持久存儲;其次,數據存在來源不一,有如風向等類別特征,各屬性特征之間量綱也存在不統一,數據缺失等問題,因此為獲得較好質量的建模數據,必須進行一定的數據集成、清洗、規整及變換等預處理等工作;然后,對處理后的建模數據按一定比例進行拆分以獲得訓練集和測試集兩部分;接著,使用訓練數據對GB 模型進行訓練工作,同時結合交叉驗證法和網格搜索法進行模型的評估優化工作,以獲得最優的模型;最后,將構建好的HPIC 劑量率預測模型在測試集上進行測試,測試模型的預測效果.
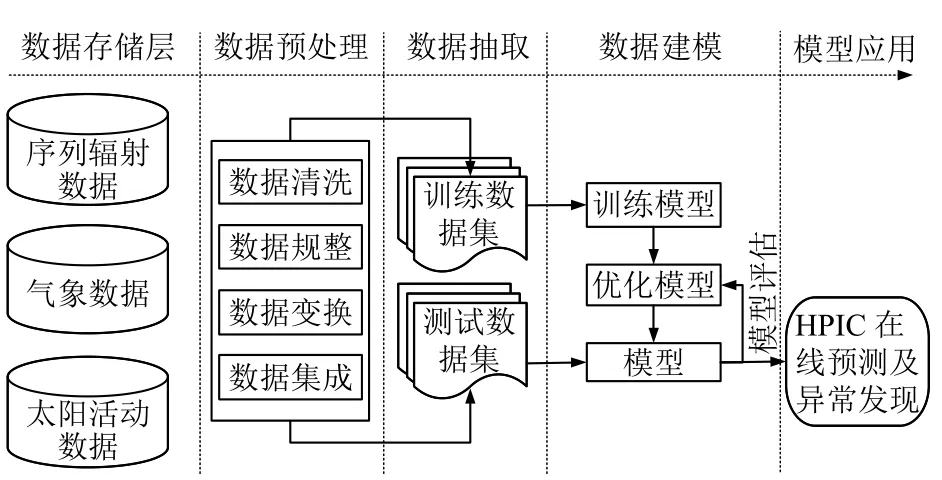
圖4 HPIC 劑量率在線預測流程方案
2.4 相關特征分析
我們以S1輻射監測站為目標研究對象.如圖5所示是采用可視化技術展現出的某降雨時段前后,其HPIC 劑量率監測數據數值隨時間的變化信息圖;從圖中可以看出HPIC 劑量率在降雨時段會有明顯的上升,隨著降雨停后,其數值又緩慢降低回至正常水平.
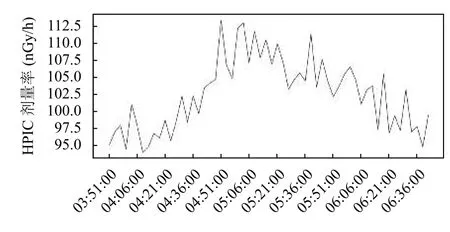
圖5 降雨時段HPIC 波動圖
根據該核電站區域核輻射各站點2015-2017年三年輻射序列數據進行異常值處理及數據標準化后,對其溫濕度、氣壓與HPIC 劑量率進行皮爾遜相關系數分析,分析結果如表3所示:溫度整體與HPIC 劑量率數值之間的相關性較弱,但是在S7站點相關性較強;各輻射監測站點濕度與HPIC 劑量率之間存在很強的正相關;對氣壓相關性來說,除了S2、S10與S113 個站點與HPIC 劑量率相關性較弱,整體上與HPIC 劑量率數值之間存在著很強的負相關關系.

表3 溫度、濕度及氣壓與HPIC 劑量率皮爾遜相關系數表
進一步具體分析S1站點溫度與HPIC 劑量率之間存在的相關關系,將溫度等寬分為3 個區間:偏低溫、偏中溫及偏高溫,如圖6所示,對每個區間HPIC 劑量率標準化后數據采用箱線圖統計分析可以得知,HPIC 劑量率在偏高溫時集中偏大,低溫時偏小,兩者整體特點表現為溫度越高,HPIC 劑量率越高;因此我們可以認為溫度也是HPIC 劑量率的特征影響因子之一,兩者之間存在著正相關關系.
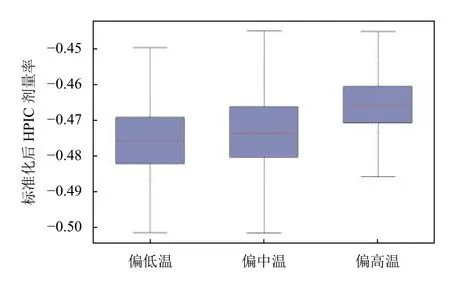
圖6 2015年度S1 點HPIC 劑量率在溫度區間數據分布箱線圖
如圖7所示,先通過標準化方法消除量綱問題,采用線性分析方法對VTEC 與HPIC 劑量率數值進行相關性分析得出,在VTEC 電子含量與HPIC 劑量率呈現明顯的同升同降變化規律,采用皮爾遜算法計算得出兩者相關系數值r高達0.669,具有顯著的相關性.
如圖8所示,以箱線圖方法統計出8 個不同風向時HPIC 劑量率數據信息,可以看出,HPIC 劑量率數據在不同風向上,其數據集中程度有稍許差異,從中位數可以看出,在風向偏南風及西南風時,其HPIC 劑量率數值中位數明顯較大,且數據整體數值較偏北風及東北風時明顯偏大;在風向為東風和東北風時,其HPIC劑量率數值中位數是最低,整體數值也是集中偏低,不同風向上HPIC 劑量率數值差值約在(0~4) nGy/h 之間.考慮風向為類別特征屬性,所以實驗中采用one-hot對屬性值進行了編碼轉換為八維的0 或1 的數值型.
再如表4,通過計算S1目標監測站點與其它站點之間HPIC 劑量率皮爾遜系數得知,除了S5、S10站點,S1站點與其余站點具有較強的相關性;所以亦可以將其他監測站點監測數據作為當前監測數據的特征因子進行定性的預測;我們考慮相關性較強的幾個站點,將與目標站點之間皮爾遜系數在0.35 以上的6 個站點作為模型特征參數輸入,進行模型構建.
同時,考慮目標屬性HPIC 劑量率的時間序列離散特征,其自身在時間前后也是有著較強的關聯性;所以為實現模型對當前時HPIC 劑量率目標屬性值預測能力,本實驗也考慮加入上一時刻的HPIC 劑量率目標屬性值作為特征輸入,以此作為基準.
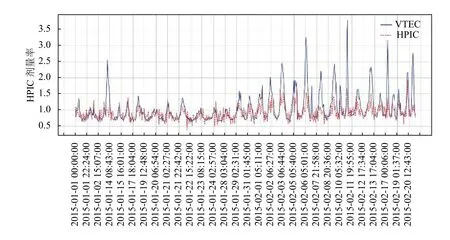
圖7 VTEC 與劑量率同一時段波動對比圖
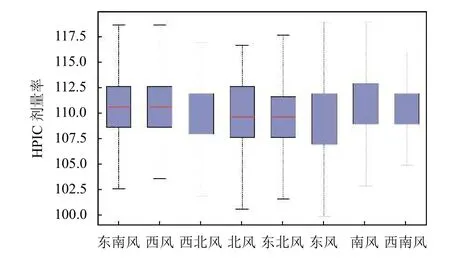
圖8 風向與HPIC 劑量率關系箱線圖
綜合看來,上述降雨、溫濕度、氣壓、太陽輻射的VTEC 及風向都與HPIC 劑量率之間有著緊密的強關聯性.這些自然因素對HPIC 劑量率的日常監測會產生較強的干擾作用,不利于異常情況發生時,對異常成因的即時分析及準確定位,如當監測過程中發現某些站點HPIC 劑量率驟然上升時,而此時區域內同時伴隨上述不利于異常判斷的自然因素發生,這時要及時得出異常成因就比較困難,可能需要提前進行預警,實行人工檢測,比較費時耗力.因而,我們在此基礎上設計如下在線預測模型,在一定程度上降低自然因素的綜合干擾,幫助進行異常情況的快速檢出工作.
2.5 模型構建及驗證
2.5.1 模型構建
如圖9所示為我們所提出的基于GB 算法的HPIC劑量率在線預測模型,輸入采用第二章節中提出的各種相關特征屬性參數,如溫度、濕度及風向等氣象參數,天頂方向電子總量VTEC,與目標站點具有時空關聯性的其它各站點HPIC 劑量率數值,最后加上自身在時間前后存在時間關聯性的目標站點上一時刻HPIC劑量率數值,輸出采用當前時刻目標HPIC 劑量率數值,這樣就形成20 個維度的特征輸入,1 個HPIC 劑量率數值的輸出.經過類別特征one-hot 編碼、零-均值標準化、缺失值填補、數據去重及異常值處理等數據預處理工作后,獲得了質量較好的數據樣本,然后將數據按照2:8 的比例進行測試集和訓練集的劃分,再采用交叉驗證方法將訓練集等量劃分為10 等份,進行10 折交叉驗證,同時結合GridSearch 網格尋優算法進行超參空間的構建,進行模型參數優化和選擇,以此得出最優的GB 預測模型.

表4 目標監測站點與其他監測子站HPIC 監測值顯著相關系數表
實驗過程中,對于GB 算法模型的性能參數最主要有兩個:模型中弱學習器的數量以及尋找最佳分割點要考慮的特征數量;這兩個性能參數都是需要我們自己去設定,弱學器數量從10 到140 每隔20 個進行數量的選取設定,最佳分割點的特征數量從16 到最大特征數量20 個每隔1 個進行選取設定,總共取得5 個特征數量取值;其模型在每種情況下的決定系數R-square和平均絕對誤差MAE 結果如圖10和圖11所示.
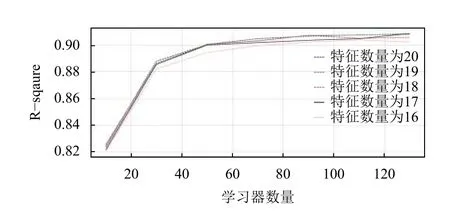
圖10 GB 模型參數的選取對評價指標R-square決定系數的影響
從圖10和圖11中可以看出,GB 模型的R-square決定系數值隨弱學習器數量的增加及特征數量的增加而增大;平均絕對誤差MAE 則隨弱學習器數量的增加及特征數量的增加而減小;但是當弱學習器的數量達到120 以上,其性能就開始趨于平緩;然而弱學器數量和特征數量越多,整體模型構建時間效率偏低;綜合圖中顯示情況來說,設定弱學器數量為120,特征數量為19 時,模型效果最好.
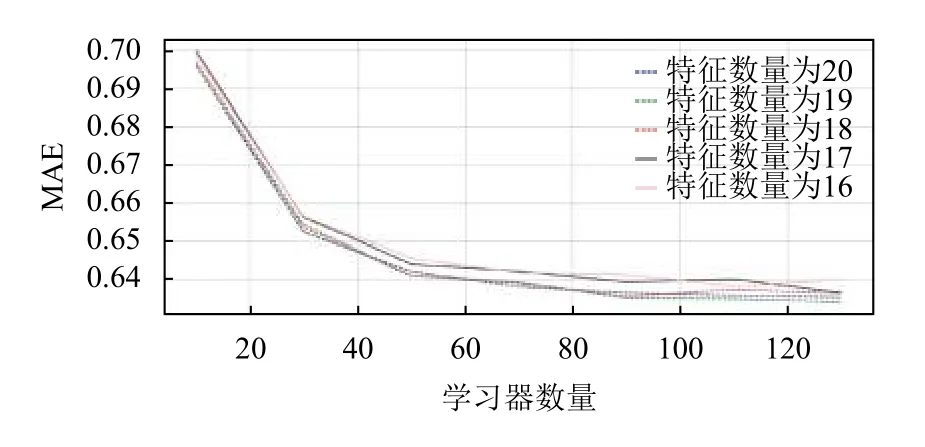
圖11 GB 模型參數的選取對評價指標平均絕對誤差MAE 的影響
2.5.2 模型測試
將訓練好的模型對測試集進行預測,預測結果可以用線性擬合圖和散點圖直觀展示,如圖12和圖13所示;從圖12中可以看出預測曲線與實際值曲線擬合性較好,計算得出決定系數R-Square 約0.91,MAE 約0.635,但是在一些這些極值點處的預測效果會有所偏差.監測站HPIC 劑量率監測儀器高壓電離室測量閾值誤差一般在±5 nGy 左右,所以這個預測差額幅度在可接受范圍內;圖13中HPIC 劑量率預測值與實際值基本分布在圖形45°斜對角附近,所以認為模型預測精度還是較好的.
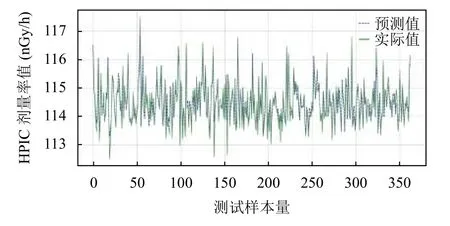
圖12 目標站點HPIC 劑量率預測值與實際值擬合對比
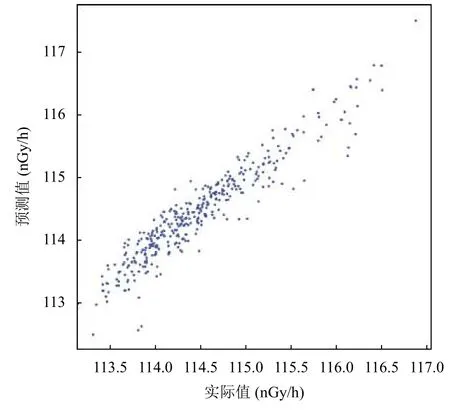
圖13 HPIC 預測結果和實際結果散點圖
綜上,此模型較好地融合了各種自然特征影響因子,并考慮目標站點與自身、各站點在HPIC 劑量率值之間關聯性構建起來的HPIC 實時預測模型,模型實驗結果較好,若能有效結合預測值與實際值誤差閾值方法,在一定程度上是可以幫助降低自然因素干擾輻射數據異常分析判斷的影響,實現對設備故障、放射性狀況導致的輻射數據異常的更準確的定位;比如,設置誤差閾值為5 nGy,可以假定當預測值與實際值的絕對誤差低于5 nGy,輻射監測數據無異常情況發生;當預測值與實際值的絕對誤差高于5 nGy,輻射監測數據可能就出現了異常,并即時向工作人員發出預警,立時進行處理.這對提高ERMS 的異常發現能力和維保效率具有很大應用價值.
3 結論
首先,感謝省級輻射中心、國家空間環境預報中心提供的數據支撐.我們以機器學習算法進行數據的挖掘工作,基于核電站積累的海量歷史數據,并引入氣象數據及太陽活動數據,充分考慮影響輻射監測中HPIC 劑量率數值的重要特征因子,并結合與目標監測站HPIC 劑量率數值相關的上一時刻HPIC 劑量率及其它相關站點的HPIC 劑量率數值作特征輸入,進行大量的數據規整工作,以GB 回歸模型建立起HPIC 劑量率數值在線預測模型,實現對當前時刻HPIC 劑量率值的精準預測.這對提高核電站對偏遠外圍監測站的環境輻射監測異常檢測效率、管理水平及ERMS 維保工作效率具有很大的現實意義和理論價值.
HPIC 劑量率數值除了受文中分析的多個自然因素的影響外,還與空氣中微量元素含量、維保日志、雷電、潮汐等有關,但是囿于資源有限,還未獲取到這些數據,如果增加這些數據進行挖掘分析,可能得到更多有用的信息用于HPIC 劑量率的預測和異常發現,也是我們下一步將要進行的研究工作所在.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
