面向任務調度優化的分布式系統信息管理框架①
2019-11-15 07:05:56胡亞輝朱宗衛劉黃河
計算機系統應用 2019年11期
胡亞輝,朱宗衛,劉黃河,王 超
1(中國科學技術大學 計算機科學與技術學院,合肥 230027)
2(中國科學技術大學 軟件學院,蘇州 215123)
1 引言
深度學習作為機器學習的一個分支,近年來取得了飛躍式的發展,在眾多領域如計算機視覺、語音識別等都取得了令人矚目的成果.以AlexNet 將ImageNet數據集上的圖像識別top-5 準確率由73.8% 提高至84.7%為標志,深度學習中所使用的神經網絡模型開始朝著更深、更復雜的方向發展,隨后又出現了VGG和ResNet 等更加復雜的網絡模型[1].然而,伴隨著使用更加復雜的網絡來實現準確率的提高,傳統的CPU 已經遠遠滿足不了其性能需求,因此,以GPU 為代表的具有高度數據并行性的計算設備逐漸被用于深度學習計算的加速.除GPU 以外,還有眾多基于FPGA[2-5]或基于ASIC[6,7]的深度學習加速器.這些工作都大大提升了單節點上深度學習推理計算的性能,然而在面臨海量數據處理的應用場景,單個節點的性能仍顯不足.一直以來分布式系統都是提供計算力的重要途徑,因此也被用作深度學習推理的加速平臺,并與深度學習加速器相結合使用.例如,谷歌早在2015年就部署了TPU集群專用于加速神經網絡的推理過程[8].然而,構建分布式深度學習推理系統依然面臨著如下挑戰.第一,以GPU 為代表的深度學習加速器如今正處于快速發展階段,不斷涌現的新型硬件使得系統必須具有高度靈活的硬件兼容性以適應其快速的更新迭代;第二,任務調度對系統整體性能影響顯著,而不同深度學習應用之間所呈現的計算和訪存特征差別巨大,因此系統必須具有靈活調整任務調度策略的能力.為應對分布式系統軟硬件環境的動態性以及各類深度學習應用特點的多樣性,本文設計并實現了可擴展的系統信息管理框架,支持對系統信息收集策略和處理策略的定制化,一方面提高系統對各類深度學習加速器的兼容性,另一方面使得分布式深度學習推理系統具有根據軟硬件環境以及實際應用的特點動態調整調度策略的能力.
2 背景與動機
2.1 分布式系統下任務調度的研究現狀
分布式系統中任務調度起著至關重要的作用,選擇合適的調度算法有利于提高系統整體的資源利用率和吞吐率,從而提升系統性能.因其重要性,分布式系統調度算法一直是分布式系統研究領域的一個熱點問題.隨著異構計算平臺的產生和發展,集群中硬件資源越來越豐富多樣,各類芯片對于不同類型的計算在性能、功耗上表現各不相同,尤其是對于深度學習類應用,不同計算部件的處理能力相差巨大,因此在面向大規模數據集的深度學習推理的場景下,考慮針對具體的應用特點進行任務負載劃分以及任務調度策略的設計是非常有必要的.此外,從用于加速深度學習推理的硬件的發展角度來看,此次人工智能熱潮中,涌現了大批的深度學習加速硬件及平臺,其中有代表性的有谷歌的TPU、寒武紀公司的智能芯片系列、微軟公司的基于FPGA 的深度學習加速平臺BrainWave[9]等.深度學習加速硬件的快速迭代迫使分布式系統應該對于新型計算資源具有更好的兼容性,然而現今的分布式計算系統中一般對這些新型資源的支持都不夠友好,如Hadoop 的資源管理器Yarn 在默認情況下僅支持對CPU、內存、硬盤等資源的管理[10].為了適應硬件的快速迭代,用于深度學習的分布式推理系統應該支持對資源種類的易擴展性,并且在任務調度時應根據系統資源以及作業特點的變化動態調整任務調度策略.
近年來,每年有上百篇與分布式系統下的任務調度問題相關的論文發表,然而據統計,2005年至2015年期間發表的1050 篇論文中,22%從未被引用過,在所有引用中,超過60%僅來自其中12%的文章[11].這足以說明目前大部分的研究成果屬于一次性工作.并且如此大量的研究成果的發表也增加了后來研究者的困難,為此,目前有大量的關于分布式系統任務調度問題的綜述性文章,對該領域的研究脈絡進行梳理,以期為研究人員提供理論基礎.Lopes 等人中從工作負載、資源、調度需求三個維度出發,并進一步對每個維度進行細分,對分布式系統中的調度問題和解決方案進行分類以及形式化描述[11],來幫助研究人員方便地對之前的研究成果加以利用.Gautam 等人針對Hadoop 集群中的任務調度常見算法(FIFO、Fari、Capacity、Delay 等)從多個方面進行了歸類總結,包括是否支持任務優先級、資源共享是否公平、適用環境為同構還是異構、任務分配策略為動態還是靜態等,分析各算法的優勢和劣勢[12].
諸如此類的綜述性文章為以后的研究工作提供了一定的理論基礎,但是對于最大規模的重復利用已有成果,仍遠遠不夠.究其原因,系統規模擴大、軟硬件資源復雜、應用負載多樣性等因素都為分布式系統下的任務調度帶來了更大的挑戰,設計合理的調度算法必須將大量的因素考慮在內.然而,考慮大量因素所帶來的大量重復的細節工作使得調度算法的設計難以進行,目前大多數算法都是針對少量具體的影響因素進行設計或優化.例如,Hammoud 等人考慮了數據局部性以及網絡傳輸對任務的影響,對MapReduce 框架中的Reduce 任務調度進行優化,將任務放置在更靠近數據所在節點進行處理[13].Arslan 等人綜合考慮了文件訪問代價以及CPU 負載等因素,做為MapReduce 框架中Reduce任務調度優化的依據[14].這類工作由于出發點本身的局限性,在設計時僅考慮具體的某一個或兩個因素,因而難以適應集群軟硬件環境以及工作負載的變化.
對現有的分布式系統下任務調度的相關工作進行總結可以發現,目前有大量工作都是面向特定場景對調度算法進行優化;另外有大量綜述性的工作,對調度問題進行抽象及形式化表述,以更好地為研究人員提供理論上的依據;但尚缺乏從如何簡化調度器設計的角度出發的工作,考慮將大量與算法核心設計無關的系統信息收集與處理的工作獨立出來,以提升分布式系統中調度算法研究工作的效率和質量.
2.2 分布式系統下任務調度關鍵步驟描述
分布式系統中任務調度可以看作是在滿足某些約束條件的前提下,將一個作業分解成為若干任務,并將這些分解后的任務分配給一組處理單元進行處理的過程,處理單元一般對應于一個能夠完成任務處理的資源組合,例如CPU、內存和網卡的組合,一個物理機、虛擬機、容器都可以看作是一個處理單元.而調度策略則決定了如何劃分作業以及各個劃分后的任務在哪個處理單元于何時開始處理,因此,任務調度策略是整個調度器的最關鍵部分.在實際設計中,調度器通常會對多種信息進行綜合分析,包括系統中的軟硬件資源、作業執行需要滿足的指標、任務執行的歷史信息等,最終得到一個合理的調度策略.分析的方法可以是某種啟發式算法,如蟻群算法、遺傳算法,也可以是神經網絡等機器學習類算法.上述過程如圖1所示,為了實現調度器的可用性和高效性,需要解決兩方面的挑戰.
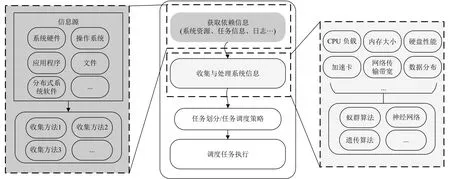
圖1 分布式系統任務調度主要過程示意圖
(1)生產信息的數據源以及信息本身的表示形式均豐富多樣且容易隨時間發生變化,例如,在集群的使用過程中,隨著機器的更新迭代,系統中會加入各種各樣的新型硬件或者不同類型的操作系統及基于此的各種軟件系統,調度器必須有獲取并處理這些信息的能力.即使這些信息的收集及處理在調度算法設計中并非核心問題,但對調度器的實現以及實際的調度效果有重要的影響,是否具有對某種信息的獲取能力,以及獲取和處理的方法是否高效可靠,則直接決定了所設計的調度算法是否具有可行性.
(2)采用啟發式或者機器學習算法對大量系統信息進行分析以尋求合理調度策略的過程具有極高的計算復雜度,并且實現難度較高,不僅使得此類算法在實際系統中的實現或者或者移植變得困難,且可能成為系統性能的瓶頸,這大大限制了各種復雜分析算法在調度器中的使用,如何保證這部分計算邏輯的正確性以及健壯性值得深入探究.
3 框架設計與實現
本文所描述的系統信息管理框架的核心設計思想是將系統信息收集與處理這兩部功能的實現獨立于調度器,調度器只需通過RESTful API 接口進行數據訪問以獲取所需信息,信息的收集和分析處理分別由信息收集器和信息處理器負責,信息收集器以及信息處理器均可獨立優化且具有功能可擴展性,從而保證系統可用性和高效性.如圖2所示,收集器負責采集各種數據源生產的信息,具體的數據源可以是操作系統、硬件設備、應用軟件、日志文件或分布式系統軟件等等,對于不同數據源,收集器可以根據數據源以及數據表示形式的不同進行設計和擴充,以實現對不同類型信息的支持.
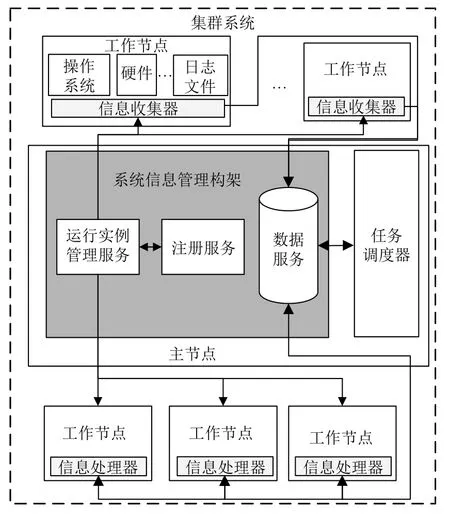
圖2 系統信息管理框架功能框圖
信息處理器則是對收集的基礎數據做進一步加工處理,得到更具使用價值的信息.例如,將各節點CPU負載和節點間文件訪問代價作為MapReduce 框架中renduce 任務調度的依據,則可以使用信息收集器從操作系統獲取各節點的網絡帶寬以及硬盤性能等相關信息,從MapReduce 框架中獲取數據塊的分布信息,信息處理器使用這些信息計算出節點間數據訪問的代價并通過數據管理服務提供的數據寫入接口保存數據,調度器僅需通過數據讀取接口獲取數據,并依此完成任務調度,使得大量復雜的信息獲取和處理邏輯對調度器透明化.
系統信息管理框架的核心服務模塊包括3 個,分別為:
(1)注冊服務,負責完成信息收集器以及信息處理器的注冊.
(2)管理服務,負責管理各信息收集器和信息處理器,包括啟動、停止、副本控制等.
(3)數據服務,負責完成數據的存儲和讀寫,收集器和信息處理器產生數據之后通過數據服務中的寫入接口將數據寫入存儲系統,信息處理器和調度器在需要使用數據時則通過數據服務的數據讀取接口獲取數據.
接下來分別對這三者的設計與實現進行詳細說明.
3.1 信息收集器與處理器的注冊
注冊服務的核心功能是維護框架中所有的信息收集器與信息處理器的注冊信息.信息收集齊與處理器本質上都是采用特定方法獲取所需的數據并生產供系統中其他模塊所用的的數據,可獨立實現及優化,具體實現可以是任意完成數據采集或處理功能的可執行文件.例如,一個信息收集器的功能是收集節點的內存使用情況,則其實現方式之一是使用shell 腳本讀取proc 文件系統中的數據來獲取相關信息.信息處理器與此類似,不同的是其數據輸入通常為某信息收集器或另一信息處理器的輸出,這些數據由數據服務維護并提供訪問接口.數據來源體現在具體數據處理器或收集器的程序設計中,可以通過操作系統的接口、系統健康監測程序的輸出文件或數據數據服務提供的數據訪問接口等方式獲取數據.
注冊服務的功能如圖3所示,設計者通過命令行客戶端或者在程序中使用注冊接口向框架內添加一個收集器或處理器,注冊信息需包含數據對象,以及獲取該數據的信息處理器或者信息收集器的信息,可以是某一個可執行文件的路徑.注冊服務接收并處理注冊信息,并存入存儲系統.注冊完成后,任何程序可以通過注冊服務提供的數據查詢接口來獲取當前系統中已注冊的數據及其獲取方式.當某類數據的信息處理器或者信息收集器的設計者對其邏輯進行更改后,通過更新接口對注冊信息進行更新.
3.2 信息收集器與處理器的運行管理
信息收集器與處理器管理服務的功能是控制收集器與處理器的具體實力在各個節點的啟動與停止,決定了具體的收集器或者處理器的工作模式,包括何時啟動、何時停止以及收集或處理數據的時間間隔等,這些信息在注冊時已經指定.
運行管理服務的實現架構如圖4所示,管理服務采用的是Master-Slave 架構,Master 端程序負責通知運行與各個節點之上的Slave 端程序進行運行實例的啟動或停止,二者之間通過RESTful API 進行通信.Slave 端程序在接收到Master 端程序所發送的信息收集器/處理器的啟動命令后,對啟動命令進行解析,獲取該收集器/處理器所負責生產的數據的標識以及執行運行實例的命令.之后,為運行實例分配運行槽,運行槽負責啟動具體的運行實例并與其進行交互,運行實例從數據源獲取數據,最后運行槽對所獲取的數據進行包裝并通過數據服務提供的數據寫入接口對獲取的數據進行保存.
3.3 數據管理
注冊服務的核心功能在于維護了數據在節點上的獲取方式,在不同的節點上可能存在多個副本而產生多個具體數據,對這些具體數據必須進行有效的組織與管理,并提供相應的讀寫接口,此即數據管理服務的功能.如圖5所示,數據服務負責存儲具體的數據,提供數據的讀寫、更新等接口,數據的使用者直接通過數據讀取接口獲取數據,數據的使用者包括數據處理器和任務調度器等.數據的生產者通過寫入接口寫入數據,數據服務接收到寫入請求后,對請求進行解析后將獲取的信息寫入存儲系統.
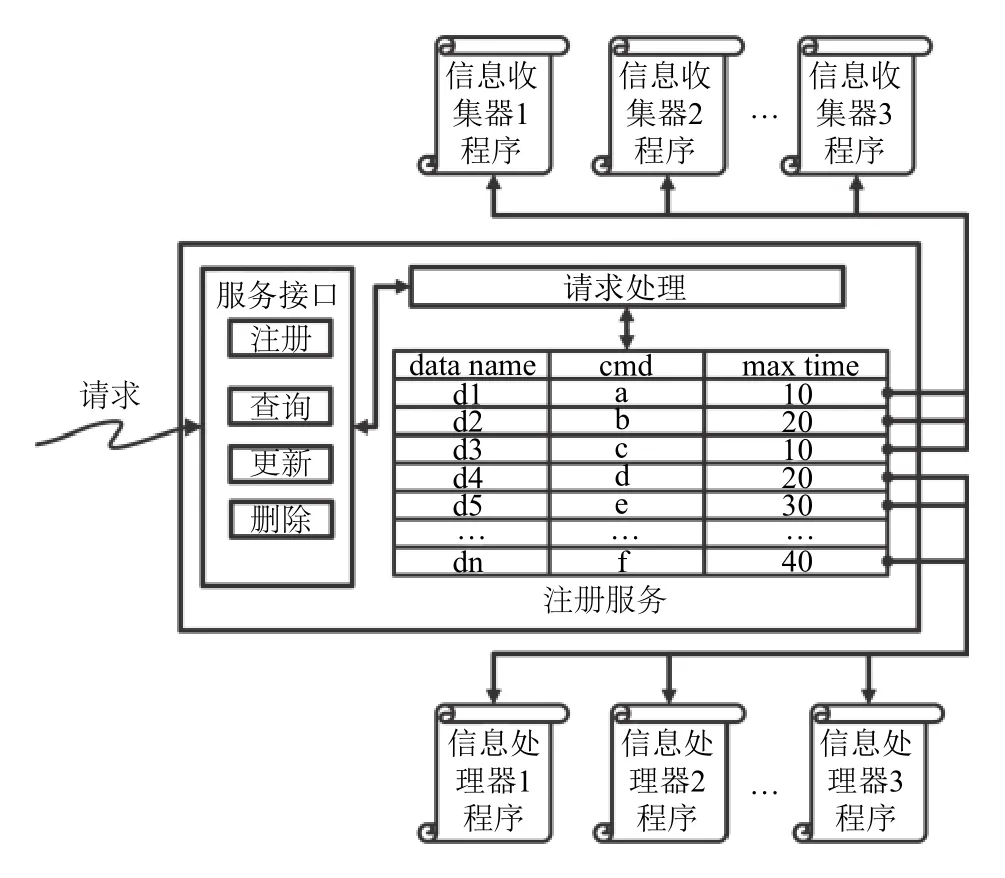
圖3 注冊服務功能示意圖
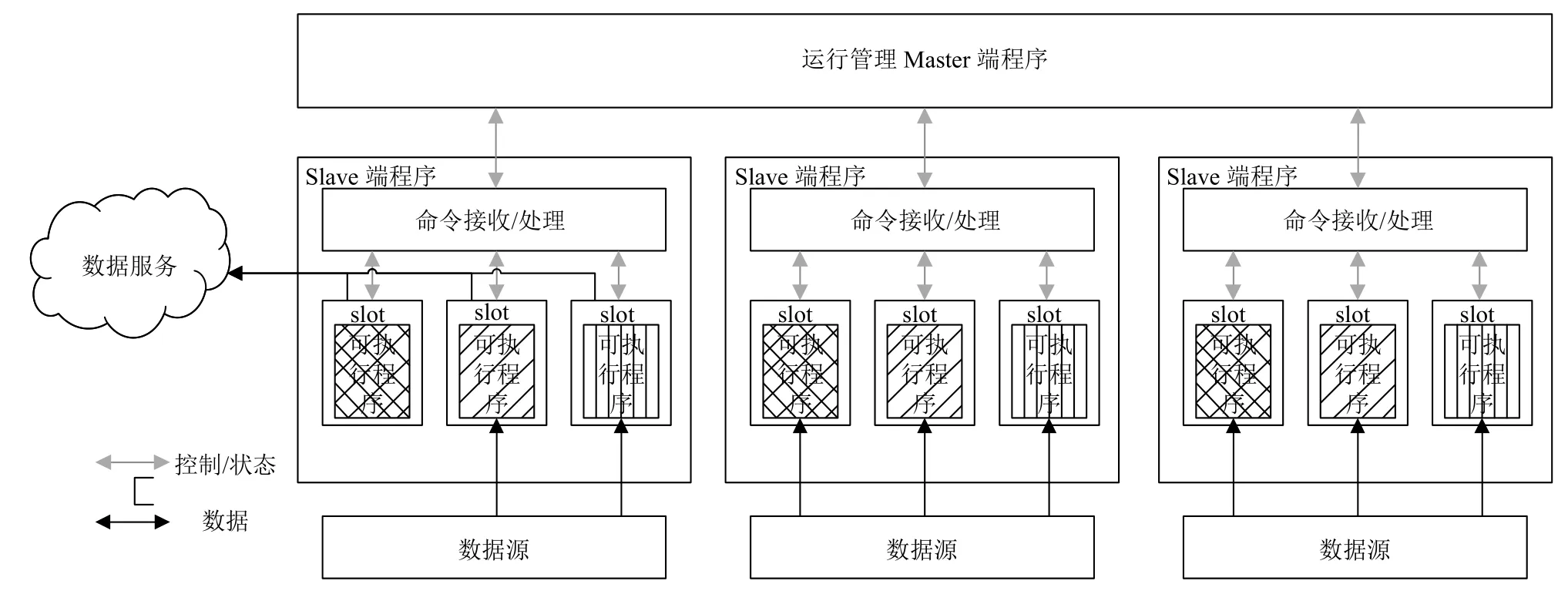
圖4 運行管理服務功能示意圖
系統信息管理框架的核心功能及設計目標之一是支持調度器靈活高效的獲取所需數據以靈活調整其調度策略.而數據服務能否提供高效的數據訪問機制則決定了整個系統信息管理框架的可用性.在設計中我們采用了異步的數據訪問機制來保證數據訪問的高效性.所謂異步的數據訪問機制,是指將數據的收集與處理和數據獲取異步進行.通常情況下,當任務調度器需要某些數據時,會通過一定方式臨時性地從系統中獲取基礎信息,再通過一系列的處理最終獲取所需的數據.這樣做的好處是可以保證數據的準確性和有效性較高,然而伴隨著的是較長的數據獲取時間,尤其是在所需的信息量非常大的情況下,并且在分布式系統的環境中,還需要面臨各種不確定性.設計所采用的異步數據訪問機制中,各運行槽的數據寫入過程和調度器的數據訪問過程完全分離.這雖然犧牲了一定的數據準確性,但提升了調度器數據訪問的效率和穩定性.
3.4 原型系統實現與接口設計
在構建原型系統的過程中,主要使用了SpringBoot框架.Spring 框架是一個開源的用于企業級應用開發的編程框架,SpringBoot 是由Pivotal 團隊開發的用于簡化Spring 應用的初始搭建以及開發過程.依賴于SpringBoot 我們可以較快地實現各個服務模塊的功能并對外提供RESTful API 接口,接口設計如表1所示.本次原型系統的設計中,數據存儲通過輕量級的關系型數據庫mysql 實現,具體的,包含表t_Data、t_DP.表t_Data 用于存儲數據,包含id、data_name、data_value和node_name 等列,其中data_name 為數據名稱,data_value 為數據的值,node_name 為產生該條數據的節點名稱,id 為data_name 與node_name 的組合作為主鍵;表t_DP 用于存儲注冊信息,包含data_name、cmd 和time_max 等列,data_name 為所注冊的信息收集器/處理器所生產的數據名稱,cmd 為執行該信息收集器/處理器實例的命令,time_max 為兩次運行之間的時間間隔.
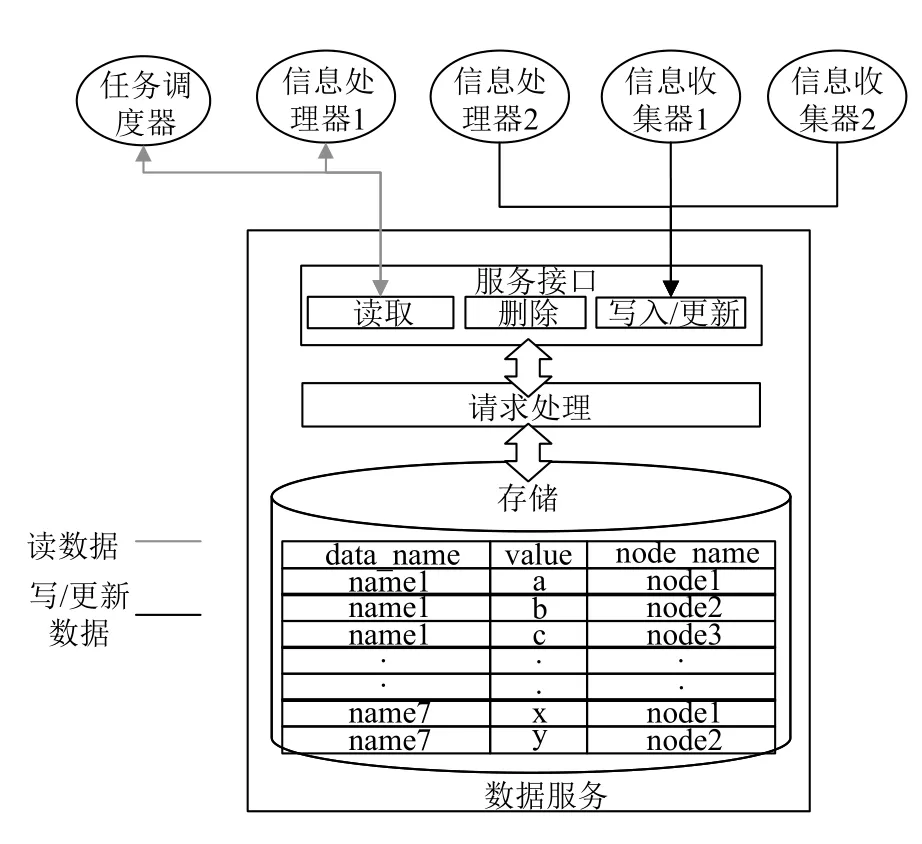
圖5 數據管理服務功能示意圖
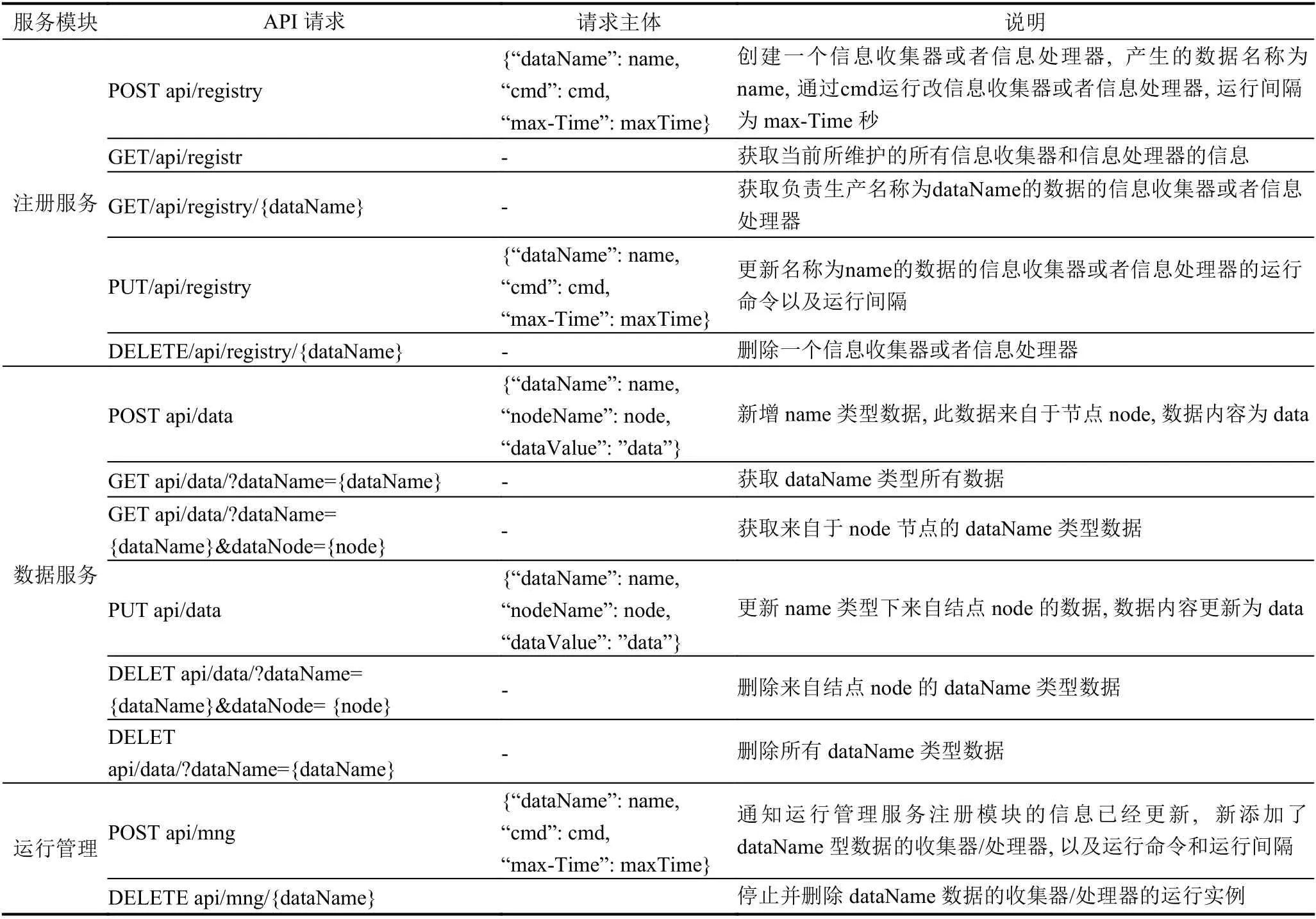
表1 API 接口設計
4 應用實例
本節將通過一個具體實例介紹如何通過系統信息管理框架來輔助調度器完成更合理的調度.分兩個主要步驟:(1)系統信息收集的可執行程序設計完成后,通過注冊模塊提供的注冊接口進行注冊并生成數據訪問接口.(2)通過設計不同的信息處理邏輯來對所獲取的數據進行加工,并生成相應數據訪問接口.
4.1 實驗設置
為了說明本文所描述的系統信息管理框架對任務調度器的支持,本次實驗中,針對分布式系統中使用深度神經網絡模型對含量圖片進行分類處理的應用場景,設計并實現了一個任務調度器,其主要功能是對作業負載進行靜態劃分,即將待處理的數據集劃分為多個子集,指定各個節點所需處理的數據子集.實驗中選取的實際任務為,在具有1 個主節點和4 個工作節點的集群中使用基于AlexNet 的物體分類程序對大批量圖片進行分類處理,數據集為從ImageNet 中選取的包含400 張圖片的子集.主節點及各個工作節點的配置為,英特爾至強W1505 型CPU,主頻2.53 GHz,4 GB 內存,各個節點配有千兆網卡,節點之間通過萬兆交換機互連.圖片存儲于分布式存儲系統HDFS 中.
調度器采用的負載劃分算法的主要步驟為:

算法1.調度器負載劃分算法輸入:數據集合D,節點集合N (Node1,…,Noden).輸出:D 的一個劃分{D1,…,Dn},Di 為節點Nodei 負責處理的數據子集,D=D1∪D2∪…∪Dn.1.得出數據在節點上的存儲分布作為初始劃分{D1,…,Dn};2.獲取各個節點當前負載量{L1,…,Ln};3.獲取每個節點的處理能力{C1,…,Cn};4.按節點i 的處理能得出節點i 的目標負載量Loi= Cin∑ ×n∑j=1 Lj k=1 Ck 5.將N 劃分為3 個子集H={Ni|Loi <Li},E={Ni|Loi=Li},L={Ni|Loi >Li}6.若H=?||L=?,則算法結束,{D1,…,Dn}為劃分結果,否則進入步驟7;7.從H 中選取一個節點Nh,從L 中選取一個節點N1 8.分別計算Nh 與Nl 載的差值Δh 與Δl,并將Nh 的部分負載轉移至Nl 轉移量為min{Δh,Δl};將達到理想負載的節點轉移至集合E;跳轉至步驟6.
算法核心思想為,步驟1-2 先按照數據在節點上的分布對數據做初始劃分,得到節點初始負載量,各節點負責所持有的本地數據進行處理;由于各節點的數據量以及處理能力的不匹配,需要對數據進行重新劃分.步驟3-4 首先按照節點的計算能力占總計算能力的比值得出各節點的理想負載量,步驟5 按照節點的處理能力與理想負載量是否匹配將所有節點劃分為3 個子集,H集合內節點負載過高、L集合內節點負載過低、E集合內結點負載程度較為理想.步驟6-8 循環多次,將高負載節點的負載劃分至低負載節點,直到各節點之間達到負載均衡.
算法1 的關鍵之處在于對各個節點的處理能力以及計算負載的評估,直接決定了任務劃分結果,而節點處理能力的評估方法應是隨著系統的實際情況變化的,例如向系統中添加具有加速器的節點則會影響性能評估的方式,原先的算法可能會喪失其有效性.而對計算負載的評估則應結合具體任務而定.通過系統信息管理框架中的信息收集器以及信息處理器的修改來完成節點性能評估以及負載評估,算法步驟2 中僅需通過固定的API 接口獲取評估結果,從而在避免修改調度算法的前提下完成調度策略的動態調整.
4.2 信息管理框架的應用
在不對調度算法做任何修改的前提下,通過采用不同的信息收集器及信息處理器來實現不同的節點性能評估方法,以適應實際需求.實驗中設計了3 種評估方法,分別如表2所示.
對應于3 種評估方法,需分別實現相應的數據收集器或者處理器,并向系統完成注冊.在此,我們以CPU 使用率作為評估指標為例進行說明.
4.2.1 信息收集器實現
信息收集器可以通過任意編程語言或工具進行實現,這里使用Linux Shell 腳本進行實現,關鍵代碼如圖6所示,通過讀取/proc 文件系統的信息獲取CPU 狀態,進一步計算并輸出CPU 總體使用率.腳本設計完成并進行功能正確性驗證后,分發至各個節點的統一路徑下,這里假設在/usr/Apps/bin 路徑下,則運行該腳本的命令為/usr/Apps/bin/getCpuUsage.sh.用于收集數據的腳本部署完畢之后,通過注冊服務的注冊接口完成注冊.注冊完成后,管理模塊運行各個節點之上的腳本程序,并將獲取的數據通過數據服務的寫入接口寫入數據表,而其他任意程序則可通過該數據的訪問接口獲取數據.
4.2.2 信息處理器實現
針對使用CPU 負載為評估指標的節點性能評估方法,我們在本次實驗依據式(1)對節點的處理能力進行計算.CpuFree為處理器當前的總體空閑比率,CpuReq為程序對CPU 的需求占CPU 總體性能的比率,得出的性能結果為相對值,1 為最好.
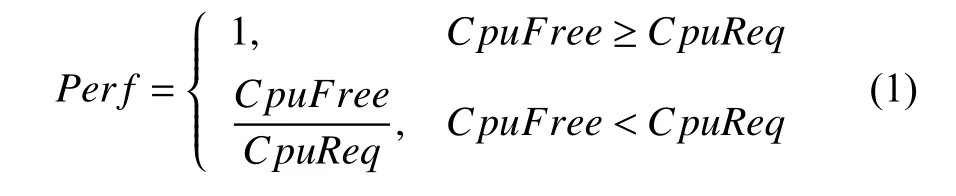
在具體實現上,流程如圖7所示,首先通過數據管理服務提供的RESTful API 風格的數據訪問接口獲取當前各個節點的CPU 負載,再根據式(1)對節點的處理性能進行評估,最后將評估結果輸出.

表2 評估方法

圖6 獲取CPU 使用率關鍵代碼

圖7 根據CPU 使用率進行性能評估主要步驟
需要指出的是,評估方法的改變,對應的只是相關信息收集器與處理器的變化,并不對算法的計算過程造成任何影響,算法實現中僅是通過數據訪問的API 直接獲取節點處理性能.
4.3 實驗結果及分析
在采用3 種不同節點處理能力評估方法的情況下,對作業負載進行不同的劃分,各個節點的任務處理時間完成時間如圖8所示.可以看出,在不修改調度算法的前提下,通過改進節點性能評估方法而使得負載均衡的程度發生了改變.在本次實驗中,各個節點的處理器配置相同,但集群中運行的其他各類應用導致了各個節點的負載情況不同,因此如圖8(a)所示,在采用按照處理器配置也即在各個節點間平均分配負載時,效果并不理想.
如圖8(b)所示是按照CPU 負載來評估節點性能,這種方法依賴于具體采用的計算公式,需要合理分析應用對處理器的需求,例如應用中是否針對多處理器進行了優化,是否是計算密集型等.通常采用這種方法,需要綜合考慮應用對處理器、內存、IO 的敏感程度而得出一個合理的性能評估公式.在這次實驗中,我們的目的并不是為了尋求一個非常合理的公式,而是為了說明通過我們提出的框架可以方便地對評估邏輯進行修改,從而使得設計、開發和驗證的效率更高.
從如圖8(b)所示的實驗結果來看,該評估方法采用式(1)進行節點性能評估的效果并不理想,但如前所述,可通過重新設計該處理器的評估邏輯進行優化,或啟用另一個數據處理器,直接從各個節點的歷史運行信息中獲取節點在運行該程序時的處理速度來評估節點性能,這種方法的運行結果如圖8(c)所示,其較好的效果得益于在本次實驗中,即使各個節點之間的運行性能差異較大,但節點各自的運行狀態均比較穩定,因此程序歷史運行信息對下一次運行的處理速率有較高的指導意義.這種方法在運行應用環境發生變化時很可能會變得不再適用,這種情況下我們仍舊可以通過調整信息處理器的邏輯來適應新的變化.
5 結論與展望
本文介紹了面向分布式深度學習推理系統優化而設計的系統信息管理子系統,該子系統的設計目的是為了將任務調度時需要的各類系統信息的收集工作從調度器設計中獨立出來,一方面是為了簡化任務調度器的設計復雜性,另一方面是為了提高調度器的靈活性.當前的主流分布式系統能夠提供的系統信息有限,留給任務調度器的發揮空間不足,如果設計者希望在調度中考慮復雜多變的系統信息,這些信息的收集工作本身就會制約設計者的工作.本文所描述的系統系統信息管理子系統支持靈活的功能擴展,設計者可以通過對信息收集器與處理器的定制化來獲取所需的系統信息.同時在設計時,通過Restful API 接口對外提供服務,保證了平臺及語言無關性.

圖8 不同節點性能評估方法下各節點的處理時間(s)
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
中華手工(2017年2期)2017-06-06 23:00:31
中外會展(2014年4期)2014-11-27 07:46:46
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
