基于Transfer-crf神經網絡的電子表格智能識別算法
2019-11-15 02:17:32毛尚偉張志清鄭成坤符云清
重慶理工大學學報(自然科學) 2019年10期
毛尚偉,張志清,湯 檳, 鄭成坤,翟 波,符云清
(1.中冶賽迪技術研究中心有限公司, 重慶 401122;2.重慶中冶賽迪信息技術有限公司, 重慶 401122; 3.重慶大學, 重慶 400044)
電子表格是一種交互式計算機應用程序,用于以表格的形式組織、分析和存儲數據,已被廣泛用于構建、排序和共享表格列表的任何環境中。據微軟公司統計,在全球范圍內Excel用戶的數量已超過4億人次,如果加上其他一些電子表格軟件,這個數目將會更加龐大。據弗雷斯特研究公司(Forrester Research)的調查估計,有50%~80%的企業在商務活動中使用了電子表格[1]。
電子表格通常具有高度靈活的編輯方式,可呈現的表格結構形式廣泛,利于用戶快捷使用。然而,當進行大規模的電子表格自動處理時,表格形式的多樣性給計算機的自動處理帶來了挑戰,嚴重影響了基于電子表格的復雜數據分析、可視化、錯誤檢測等功能。因此,對海量表格的結構識別是獲取表格數據、利用表格數據的必要步驟。目前,國內外對電子表格的識別主要集中在表頭結構,如Dou等在2018年提出了一種表格的可擴展組檢測方法[2],以表頭位于表格的前4行為前提,構建了基于行的類型、格式以及類型和格式這3種規則來推斷表格的表頭結構。Abraham等采用分類的方法研究表頭識別方法[1],提出了一種基于分類算法的表頭框架。總體而言,現有相關研究較少,且存在算法識別條件較為苛刻、算法精度不高等問題。針對這些問題,本文對電子表格結構的自動識別進行了研究。
本文主要針對工商業大量使用的縱向表格,采用深度學習模型transfer算法與條件隨機場算法(CRF)相融合,實現對電子表格行屬性的自動識別。本文基于中國國家統計局以及相關政府機構公開的電子表格數據集開展工作,采用提出的transformer-crf算法進行實驗,并與CRF算法進行比較。實驗結果表明:本文提出的算法識別精度優于CRF算法,能夠滿足電子表格自動化處理需求。
1 表格結構識別定義與分析
電子表格按內容布局方式可分為縱向電子表格、橫向電子表格、混合電子表格。由于縱向電子表格是商業和工業中最為常見的表格布局方式,本文重點研究縱向電子表格的結構識別,后文電子表格均指縱向電子表格。典型的縱向排布電子表格如圖1[3]所示。

圖1 縱向電子表格樣例
電子表格通常由若干行內容組成,可記為如下形式:
R=[r1,r2,r3,…,rn]T
(1)
其中ri(i= 1,2,3,…,n)表示表格的一行內容。表格的一行內容可能是表格的表頭、變量名、數據或者表尾,假設表格的行屬于且僅屬于前述4種行類別中的一類。表格的具體定義如表1所示。
對于縱向電子表格的結構識別,需要識別出表格中每一行內容的類別,R的類別標簽序列可記為:
A=[a1,a2,a3,…,an]T
(2)
其中ai是ri的類別標簽,ai∈{0,1,2,3}。其中,0是表頭的標簽,1是變量名的標簽,2是數據的標簽,3是表尾的標簽。
表格結構識別模型M的目標是判斷表格各行的類別標簽,可記為:

A=M(R) (3)
2 表格結構識別的問題建模
2.1 表格結構特征提取
為量化電子表格結構,本文提出了一系列的表格結構特征,并以此為基礎構建表格結構識別模型,見表2。

表2 表格結構特征

續表(表2)
2.2 基于Transformer-CRF神經網絡結構的表格結構識別
表格各行的類別標簽之間存在關聯,如表頭下面很有可能是變量名而不是數據,數據行下面更可能是表尾而不是表頭等。因此,表格結構識別問題可轉換為序列標注問題,如式3所示。
近幾年深度學習技術的快速發展使自然語言處理的各項任務取得了較大進展,特別是近兩年出現的Transformer[4]結構,基于注意力機制構建特征提取和表示模型,突破了原有LSTM模型不能很好地處理遠距離依賴關系的限制,進一步提升了針對語言序列的特征提取和表示能力,基于該結構的GPT[5]、GPT2.0[6]、BERT[7]等預訓練模型刷新了各大自然語言處理任務測評比賽最佳成績。
本文基于Transformer和CRF構建一種新的深度學習序列標注模型,如圖2所示。該結構由row encoder、table encoder、CRF 3部分神經網絡組成。row encoder網絡用于對表格內容的每一行進行編碼,目的是期望提取表格各行的語義信息,table encoder網絡則是對整個表格進行編碼,重新得到表格各行的特征表示,以期提取表格行與行之間的關系,然后再經過一層線性網絡得到CRF的發射概率,該結構類似于BiLSTM-CRF[8],CRF層構建了轉移概率矩陣。最后,基于table encoder層輸出的發射概率和轉移概率計算條件概率最大的輸出序列。
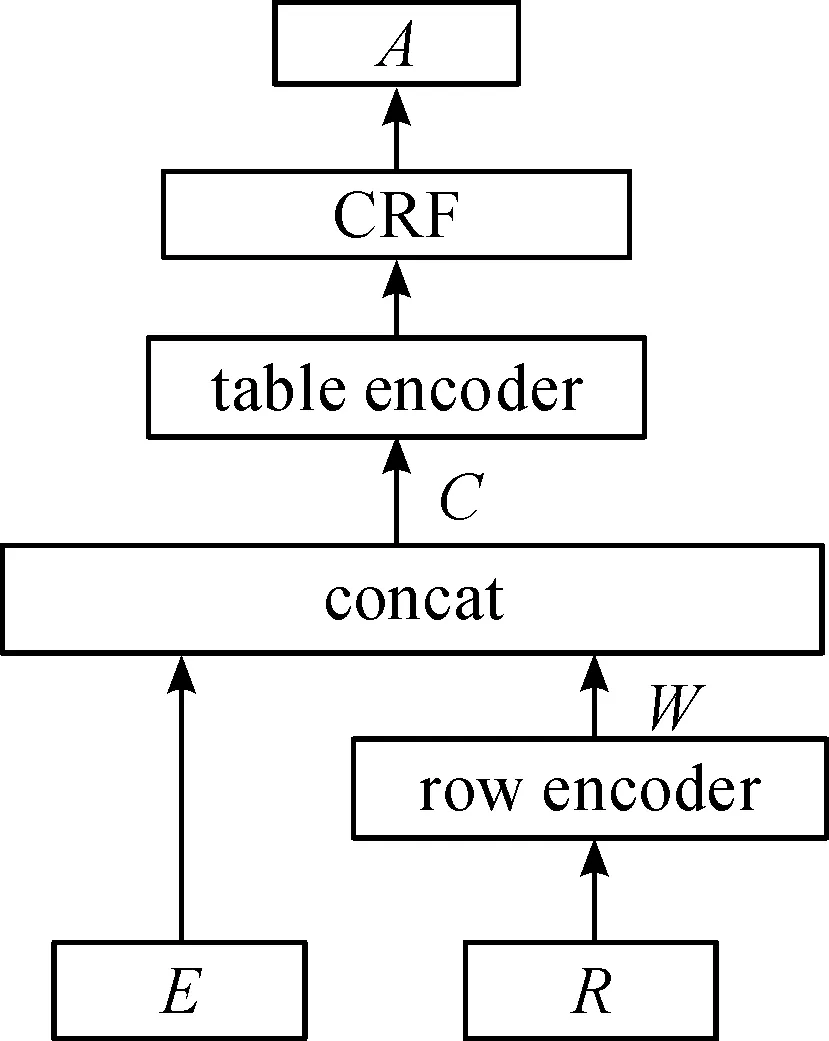
圖2 Transformer+CRF網絡結構
Transformer-CRF網絡的輸入有人工特征E和表格內容R兩部分。人工特征E來自表2的特征,表格內容R表示了整個表格的內容信息。為了便于提取語義信息,將每一行的單元格內容拼接在一起形成長字符串,并利用預先構建的字符集將字符串映射為數值向量[9-11]。
輸入的E和R在網絡中傳輸的過程可用下式表示:
Wn,b=row(Rn,m)
(4)
Cn,a+b=[Wn,b;En,a]
(5)
Tn,4=table(Cn,a+b)
(6)
An,1=CRF(Tn,4)
(7)
式(4)中的Rn,m是n×m的矩陣,表示n行且每一行的內容長度為m的表格。在row encoder層對每一行獨立進行編碼后得到Wn,b,b為編碼長度。具體row encoder層的示意圖如圖3所示。rij(j= 0,…,m) 表示了ri行的第j個字符,ri進入網絡后首先經過embeding將單數值rij映射為連續向量,然后再進入transformer提取高階信息,最后將ri1對應的輸出作為整個序列的編碼結果wi。Wn,b由wi組成,可表示為
(8)
圖2中的concat可用式(5)表示,其中En,a是n×a的矩陣,保存了n行a維人工特征向量;符號[A;B]表示將矩陣A和B水平方向拼接,式中Cn,a+b即是Wn,b與En,a拼接的結果。
式(6)表示了table encoder的處理過程,輸出的Tn,4是n×4的矩陣,矩陣T的列之所以為4,是因為待預測的行標簽有4類。式(7)表示了CRF推斷過程,輸出表格的行標簽序列A。圖3、4表明了table encoder和CRF的結構,C進入網絡后首先經過transformer進行表格編碼提取表格行關系特征,然后經過linear層將每一行的編碼映射成4維向量得到CRF發射概率矩陣Tn×4,最后進入CRF層推斷輸出標簽序列Anx1。

圖3 Row encoder結構

圖4 Table encoder結構
3 實驗結果與分析
3.1 數據集
本文以中國國家統計局及相關政府機構的官方網站獲取的電子表格作為實驗數據集,主要來自:中國統計年鑒、工業物料清單、采購訂單、工業生產數據和市場調研表。數據集中包含10 265張表格,共計661 937行。將其按照7∶3的比例(考慮到表格劃分的一些特殊情況,實際的比例約為7.07∶2.93)分成訓練集和測試集,其中訓練集中包含了7 257張表格,共計466 115行;測試集中包含了3 008張表格,共計195 822行。
3.2 評估指標
對于行屬性每個類別的預測,可將其視為二分類問題。根據模型的預測結果可以劃分為:真正例TPi、 假正例FPi、假負例FNi。以表頭的預測結果為例,TP0即真實類別為表頭且模型預測結果也為表頭的行的數量;FP0即真實類別為非表頭且模型預測結果為表頭的行的數量;FN0即真實類別為表頭且模型預測結果為非表頭的行的數量。以上述指標為基礎,本文從行和表格這2個角度分別評估模型的優劣程度,分別構建了行評估指標和表格評估指標。
3.2.1行評估指標
行評估指標由以下2個指標構成:
1) 微平均(Micro-average)
包括微平均準確率mP,微平均召回率mR,微平均F1分值mF1,計算公式如下:
(9)
(10)
(11)
2) 宏平均(Macro-average)
包括宏平均準確率MP,宏平均召喚率MR,宏平均F1分值MF1,計算公式如下:
(12)
(13)
(14)

3.2.2表格評估指標
表格評估指標為整表識別準確率FTP,即模型對該表格所有行的類別全部識別正確的表格數NRT與測試集中總表格數NT之比:
(15)
3.3 實驗步驟
1) 配置實驗平臺
平臺主要軟硬件參數:CPU為 i7-6850k,64 G內存,顯卡GeForce GTX 1080Ti 2塊,軟件核心平臺python 3.7.2,深度學習框架為PyTorch 1.1.0,CRF 模型使用crfsuite(集成于sklearn)。
用本文2.1節的方法對表格特征進行提取構造CRF模型的數據集,將表格內容和表格信息進行拼接,構造字典,利用字典構造詞向量,作為Transformer-CRF的數據集。將數據集按照7∶3分為訓練集和測試集。
3) 分別對CRF、Transformer-CRF模型進行訓練
模型網絡結構見圖2。Transformer-CRF模型訓練部分核心代碼如下:
model = TableNet(vocab_size_w,w_embd_size,c_embd_size,r_embd_size,
class_size,class_embd_size,row_info_size,row_info_embd_size,
bilstm_hidden_dim)
optimizer = optim.SGD(model.parameters(),lr=0.01,weight_decay=1e-4)
neg_log_likelihood_avg_min = 1000000000
1、農田區域建造防護林網。農田防護林網是治理風沙的一項基本生態工程。低矮灌木和林木根系可以防止土壤風蝕,喬木林冠帶可以截留隨風飄移的顆粒,從而減少土壤及其中營養物質的損失,從根本上保證土壤營養質的保留,為農作物的生長與防護林的進一步固化成長具有重要的奠基作用。
for epoch in tqdm(range(epochs)):
neg_log_likelihood_avg = 0
for afile in tqdm(train_data):
model.zero_grad()
# Step 3.Run our forward pass.
neg_log_likelihood = model.neg_log_likelihood_wh([afile[1]],[afile[2]],[afile[3]],[afile[4]])
neg_log_likelihood_avg += neg_log_likelihood
# Step 4.Compute the loss,gradients,and update the parameters by
# calling optimizer.step()
neg_log_likelihood.backward()
optimizer.step()
print(epoch)
temp = (neg_log_likelihood_avg/len(train_data)).data[0]
print(temp)
if neg_log_likelihood_avg_min >= temp:
neg_log_likelihood_avg_min = temp
joblib.dump(model,′best_model.pkl′)
4) 對訓練好的模型在測試集進行測試
按照本文3.2.1、3.2.2節進行評估計算。
3.4 實驗結果
使用此前篩選和構造的特征在訓練集上分別訓練了傳統的CRF模型和Transformer-CRF模型,并使用訓練好的模型分別在測試集上進行了測試和驗證。
根據各個模型在測試集上的測試結果,計算并得到了CRF、Transformer-CRF模型在測試集上的評估指標結果,如表3、4所示。

表3 2種模型在測試集上的行評估指標對比
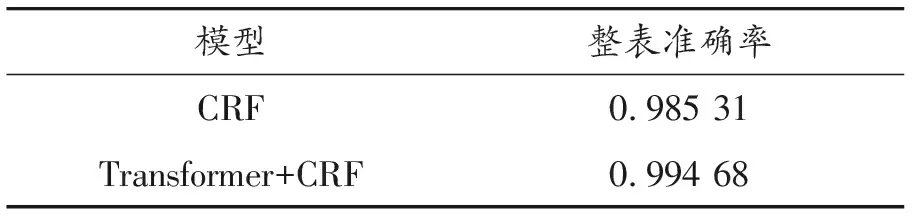
表4 2種模型在測試集上的表格評估指標對比
從實驗結果來看,transformer-CRF模型在識別表格每一行的類別方面的性能優于CRF模型。
4 結束語
本文就電子表格的結構識別進行了研究,使用人為構造的表格特征模板,采用序列標注模型對表格結構的識別進行建模,提出了transformer-CRF的模型結構用于表格結構識別。實驗結果表明:本文方法能較好地識別表格的行類別,transformer-CRF模型結果最優識別在本文實驗數據集上,行識別精度高達99.988%,整表識別準確率高達99.468%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
哲學評論(2021年2期)2021-08-22 01:53:34
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華詩詞(2019年7期)2019-11-25 01:43:04
模具制造(2019年3期)2019-06-06 02:10:54
影視與戲劇評論(2016年0期)2016-11-23 05:26:01
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
現代企業(2015年9期)2015-02-28 18:56:50
