基于人工神經網絡的二分類方法
2019-11-18 07:26:20聶文都蔡錦凡
現代計算機 2019年28期
關鍵詞:分類
聶文都,蔡錦凡
(西京學院信息工程學院,西安710123)
0 引言
人工神經網絡(Artificial Neural Network,ANN)從信息處理的角度對人腦神經元進行抽象,建立一種簡單模型,按不同的連接方式組成不同的網絡。神經網絡是一種運算模型,由大量的節點(或稱神經元)之間相互聯接構成。每個節點代表一種特定的輸出函數,稱為激勵函數(Activation Function)[1]。每兩個節點間的連接都代表一個對于通過該連接信號的加權值,稱之為權重,這相當于人工神經網絡的記憶。網絡的輸出則依網絡的連接方式,權重值和激勵函數的不同而不同。而網絡自身通常都是對自然界某種算法或者函數的逼近,也可以是對一種邏輯策略的表達。
相對于傳統的線性邏輯回歸算法[2],人工神經網絡具有良好的容錯性,泛化能力好,適于擬合復雜的非線性關系,應用領域廣泛,是當前許多工程領域的研究熱點。現在很多問題都是二分類[3-4]問題,現在很多都是利用人工神經網絡實現而分類問題。
1 人工神經網絡的結構與模型
1.1 生物神經元的結構
神經細胞是構成神經系統的基本單元,稱之為生物神經元[5],簡稱神經元。神經元主要由三部分構成:①細胞體;②軸突;③樹突。生物神經元結構如圖1所示。
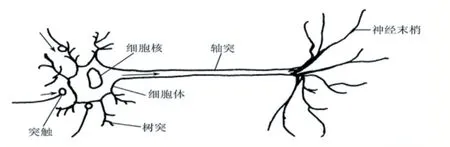
圖1 生物神經元結構
神經元的功能特性:①時空整合功能;②神經元的動態極化性;③興奮與抑制狀態;④結構的可塑性;⑤脈沖與電位信號的轉換;⑥突觸延期和不應期;⑦學習、遺忘和疲勞。
1.2 人工神經元結構
人工神經網絡是由大量處理單元經廣泛互連而組成的人工網絡,用來模擬腦神經系統的結構和功能。而這些處理單元我們把它稱作人工神經元[6]。人工神經元結構如圖2 所示。
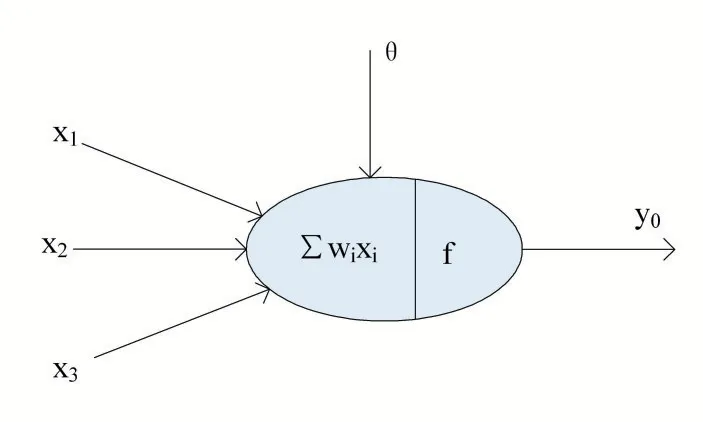
圖2 人工神經元結構
神經網絡從兩個方面模擬大腦:
(1)神經網絡獲取的知識是從外界環境中學習得來的;
(2)內部神經元的連接強度,即突觸權值。用于儲存獲取的知識。
神經網絡系統由能夠處理人類大腦不同部分之間信息傳遞的由大量神經元連接形成的拓撲結構組成,依賴于這些龐大的神經元數目和它們之間的聯系,人類的大腦能夠收到輸入的信息的刺激由分布式并行處理的神經元相互連接進行非線性映射處理,從而實現復雜的信息處理和推理任務。對于某個處理單元(神經元)來說,假設來自其他處理單元(神經元)i 的信息為xi,它們與本處理單元的互相作用強度即連接權值為wi,i=0,1,2,…,n-1,處理單元的內部閾值為θ。而處理單元的輸出為:

式中,xi為第i 個元素的輸入,wi為第i 個處理單元與本處理單元的互聯權重即神經元連接權值。f 稱為激活函數或作用函數,它決定節點(神經元)的輸出,θ表示隱含層神經節點的閾值。
1.3 人工神經網絡模型
一個人工神經網絡由多個神經元結構組成,每一層的神經元都擁有輸入和輸出,每一層都是由多個神經元組成。第i-1 層網絡神經元的輸出是第i 層神經元的輸入,輸入的數據通過神經元上的激活函數來控制輸出數值的大小。該輸出數值是一個非線性值,通過激活函數得到的數值,根據極限值來判斷是否需要激活該單元。一般多層人工神經網絡由輸入層、輸出層和隱藏層組成。如圖3 所示。
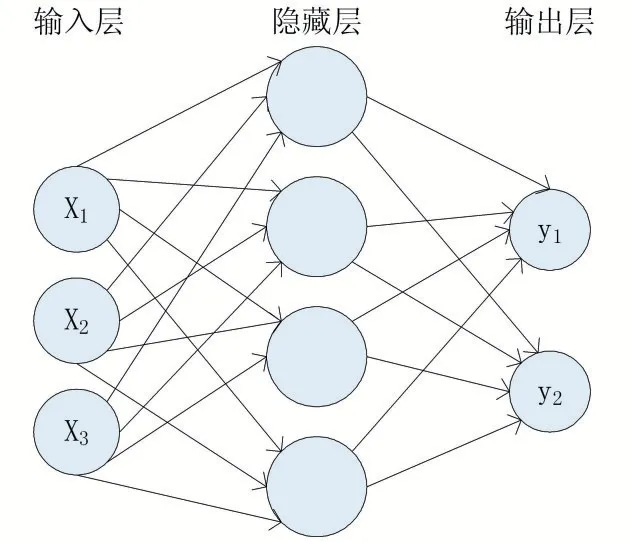
圖3 三層人工神經網絡模型
輸入層(Input Layer)是接受輸入信號作為輸入層的輸入;輸出層(Output Layer)是信號在神經網絡中經過神經元的傳輸、內積、激活后,形成輸出信號進行輸出;隱藏層(Hidden Layer):隱藏層也被稱為隱層,它介于輸入層和輸出層之間,是由大量神經元并列組成的網絡層,通常一個人工神經網絡可以有多個隱藏層。
2 人工神經網絡的訓練與預測
2.1 人工神經網絡的訓練
首先給所有的權重向量W 和偏置b 賦予隨機值,使用這些隨即生成的權重參數值來預測訓練中的數據樣本。樣本的預測值為y^,真實值為y,現在定義一個損失函數[7-8],目標是使預測值盡可能接近真實值,損失函數就是使得神經網絡的損失值和盡可能的小。其基本公式為:

使得模型效果最佳就是如何改變神經網絡中的參數W 和b,使得損失函數的值最小。
2.2 人工神經網絡的預測
在訓練階段,通過算法修改神經網絡的權值向量W 和偏置b,使得損失函數最小。當損失函數收斂到某個閾值或者等于零時,停止訓練,就可以得到權值向量W 和偏置b。到此為止,人工神經網絡模型結構中所有的參數(輸入層、輸出層、隱層的節點數、權值向量W、偏置b)都是已知的,只需要將向量化后的數據從人工神經網絡的輸入層開始輸入,順著數據流動的方向在網絡中進行計算,直到數據傳輸到輸出層并進行輸出(一次前行傳播),就完成一次預測并得到分類結果。
3 人工神經網絡的核心算法
3.1 梯度下降算法(Gradient Descent Algorithm)
假設函數L(θ)為損失函數,為了找到損失函數的最小值,需要沿著與梯度向量相反的方向更新變量θ,這樣可以使梯度減小得最快,直至損失函數收斂至最小值。該算法稱為梯度下降算法[9-11],其基本公式為:

其中,η∈R 為學習率,用于控制梯度下降的幅度(快慢)。在神經網絡中,上式中的變量θ是由神經網絡的參數所組成的向量θ={w1,w2,…,wn,b1,b2,…,bn}。梯度下降的目標就是找到參數θ*使得神經網絡總損失L最小,從而確定神經網絡中的權重向量W 和偏置b。梯度下降算法的特點是:越接近目標值,變化越小,梯度下降的速度越慢。梯度下降的算法有很多變種形式,主要有以下三個:①批量梯度下降算法(Batch Gradient Descent,BGD);②隨即梯度下降算法(Stochastic Gradient Descent,SGD);③小批量隨機梯度下降算法(Min-batch SGD)。如圖4 所示,(a)批量梯度下降算法的下降軌跡平滑,經過多次迭代后達到全局最優解處;而(b)小批量隨機梯度下降算法在下降過程中持續的小幅振蕩,但每次迭代的數據量少,能夠更快地找到全局最優解。因此小批量隨機梯度下降算法在實際工程中使用的頻率更高。
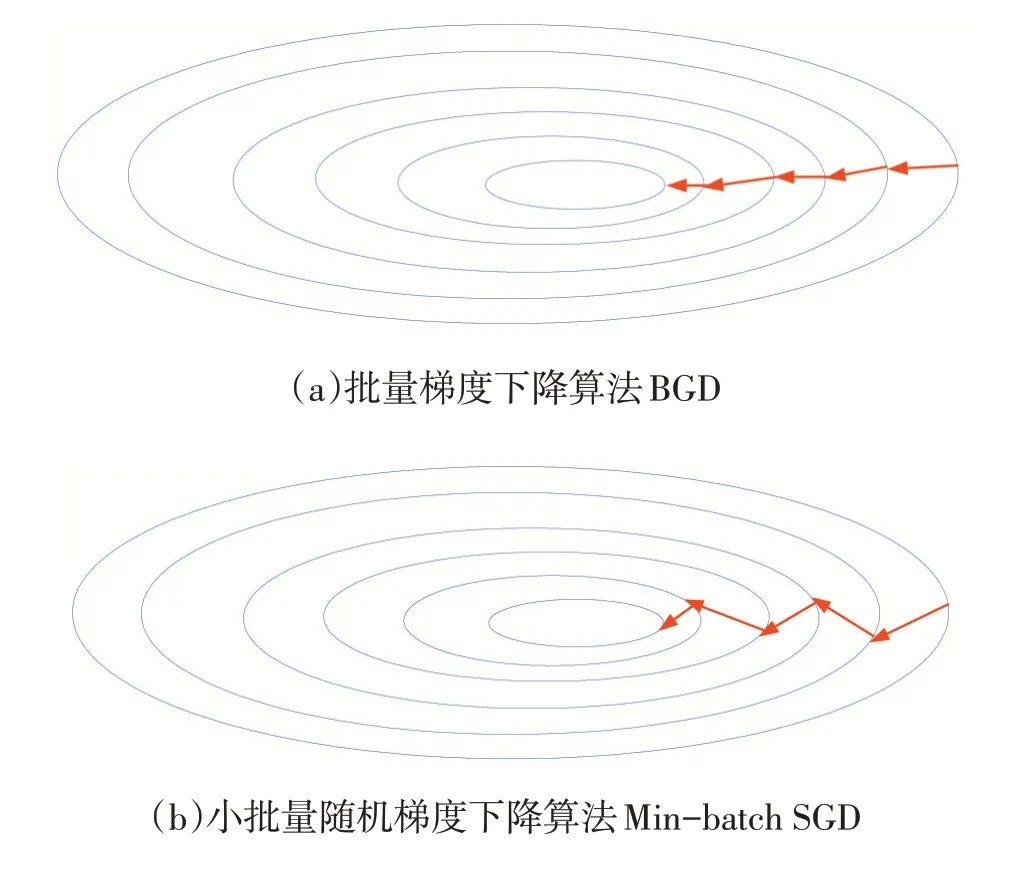
圖4 BGD 和Min-batch SGD 梯度下降示意圖
3.2 向前傳播算法(Forward Propagation Algorithms)
向前傳播(Feed Forward)算法在神經網絡的訓練和預測階段都會被反復用到,是神經網絡中最常見的算法。其計算方式簡單,只需要根據神經網絡模型的數據流動方向對輸入的數據進行計算,最終得到輸出結果。圖5 所示是一個簡單的人工神經網絡模型[12],其輸入層有兩個節點,隱層、輸出層均有3 個節點。可以通過矩陣的方式對向前傳播算法進行解析。假設zi(l)為第l 層網絡第i 個神經元到第l+1 層網絡中的第j 個神經元的連接,那么根據神經元基本公式有:

神經網絡的參數進行量化[9],表示為:

因此,單層神經網絡的向前傳播算法可以使用矩陣表達為:

其中,a(l)為第l 層網絡的輸出矩陣,f 為激活函數。
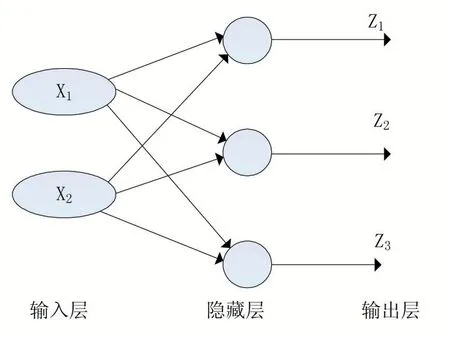
圖5 單隱藏層神經網絡的向前傳播
3.3 反向傳播算法(Back Propagation Algorithms)
反向傳播算法[13-15]的數學定義是根據微積分里面的一些數學法則來闡述的。假設神經網絡模型的參數為θ={w1,w2,…,wn,b1,b2,…,bn},那么反向傳播算法的精髓是:通過鏈式求導法則,求出網絡模型中的每個參數的偏導數。
反向傳播算法中最基本的四個方程如下:
BP1 輸出層誤差:

BP2 第l 層誤差:

BP3 損失函數關于偏置的偏導:

BP4 損失函數關于權值的偏導:

其中,定義第l 層的第i 個神經元的誤差為L 對z的偏導。▽a為在ail處的梯度,為f 激活函數,w 為權值,b 為偏置。反向傳播算法流程是根據四個基本方程進行總結的,具體流程如圖6 所示。

圖6 反向傳播算法流程
4 人工神經網絡二分類實驗
4.1 實驗環境及其相關參數設置
基于華為Matebook-X 筆記本電腦,使用Python 3.6 作為編程開發語言,系統的操作環境為Windows10,硬件開發環境為Intel i5 處理器,8GB 運行內存,CPU 為 Intel Core i5-7200U CPU @2.50GHz 2.71GHz,使用PyCharm 作為神經網絡開發框架。此次實驗是為了實現醫療數據的二分類,所用到的數據為球菌數據,數據源醫療公共數據集。并用了兩種方法實現此二分類,一種人工神經網絡,一種線性邏輯回歸。
建立一個3 層人工神經網絡模型,輸入層中的神經元節點數目由輸入數據的維數決定,本實驗中有鏈球菌x1,因此輸入維度是2,輸入有兩個神經元節點組成。同理,輸出層中的神經元節點數由輸出的分類維度決定,本實驗中為病原體I(0)和病原體II(1),因此輸出層有兩個神經元組成。最后可以將此次實驗的人工神經網絡定義為如圖7 所示。
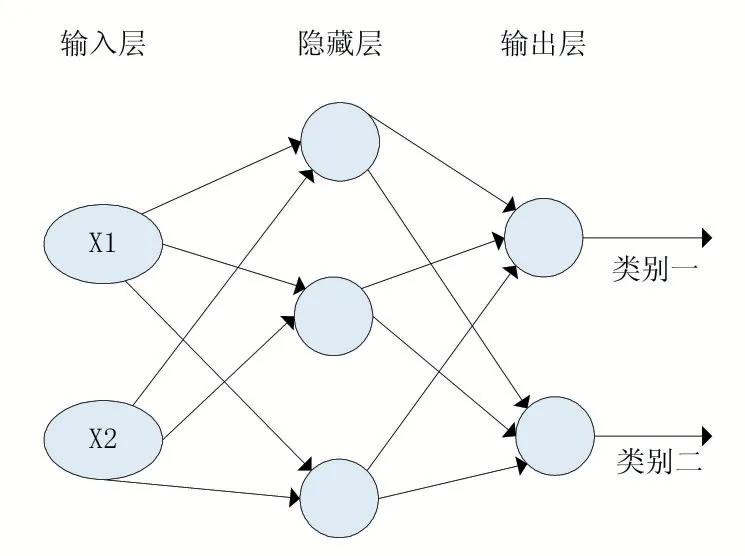
圖7 二分類3層人工神經網絡
本實驗中用到了3 個隱藏層,根據實際情況,我們可以增加隱藏層數和每一個隱藏層的節點數,隱藏層越多,隱藏層節點越多,就能夠處理更加復雜的數據模型,但是代價開銷大:
(1)隱藏層越多,意味著網絡模型越大,參數越多,占用GPU 顯存越多;
(2)參數量越多,數據過擬合的可能性越大,網絡越有可能不穩定,預測效果反而下降。
4.2 實驗結果及其分析
實驗結果如圖8、圖9 所示。
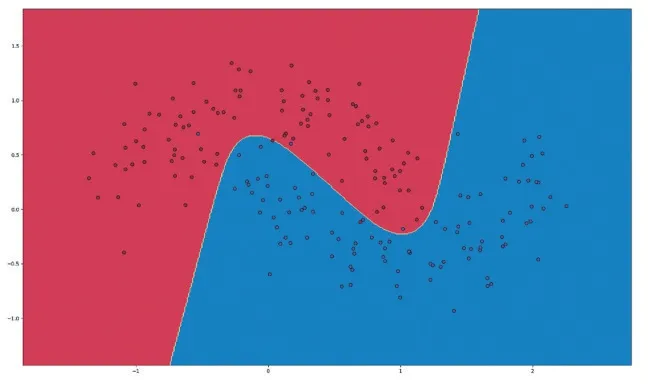
圖8 ANN二分類結果
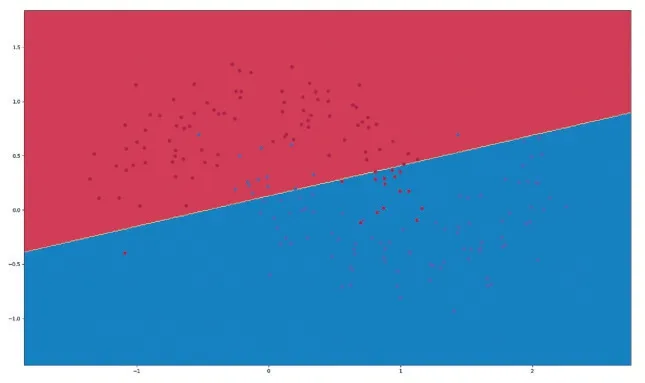
圖9 線性邏輯回歸二分類結果
實驗結果分析:
圖8 ANN 二分類實驗結果中,錯誤分類的點較少,分類效果較好;圖9 線性邏輯回歸二分類實驗結果中,錯誤分類較多,分類效果較差。但是ANN 二分類仍然有一些錯誤分類的點,可能是隱藏層神經元節點數不夠合理,可以適當增加一點隱藏層神經元節點數。但是要注意增加節點數就會使得過擬合的可能性越高,經過代碼調試得知,當隱藏層數達到50 層時,過擬合現象就會很嚴重。本次實驗,兩種方法上對比分類結果可以看出,ANN 的二分類效果要比線性邏輯回歸的二分類效果更好。
5 結語
本文通過對人工神經網絡核心算法的介紹,與傳統的線性邏輯回歸算法進行對比,人工神經網絡在處理二分類問題上更優于線性邏輯回歸算法。雖然人工神經網絡應用非常廣泛,也相比傳統的算法在二分類問題上更加精確,但是人工神經網絡有關參數的計算量大,需要對數據和參數進行優化。對未來人工神經網絡的發展和機器人在處理二分類問題上有著一定的幫助。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
