以學(xué)生為中心的“Hadoop大數(shù)據(jù)平臺”課程的教學(xué)設(shè)計
2019-11-19 06:40:32曹素麗楊延廣張翠軒
微型電腦應(yīng)用 2019年11期
曹素麗, 楊延廣, 張翠軒
(石家莊郵電職業(yè)技術(shù)學(xué)院 計算機系, 石家莊 050021)
0 引言
截至到2018年,開設(shè)“大數(shù)據(jù)技術(shù)與應(yīng)用”專業(yè)的高職院校已達到208所,越來越多的學(xué)校加入到了該專業(yè)人才培養(yǎng)中來。我校于2015年開始籌建該專業(yè),2016年正式開始招生(原名是:計算機應(yīng)用技術(shù)——大數(shù)據(jù)技術(shù)應(yīng)用方向),是全國最早招收該專業(yè)的高職院校之一,由于該專業(yè)是新設(shè)專業(yè),可借鑒經(jīng)驗少,各教學(xué)環(huán)節(jié)都需要教師去摸索。三年多來,我校投入大量的精力對專業(yè)建設(shè)、實驗室建設(shè)和課程建設(shè)等做了深入的調(diào)查研究與實踐,截至目前,該專業(yè)在我校即將完成一個完整的教學(xué)周期。在教學(xué)中我們堅持以學(xué)生為中心的教學(xué)理念,以學(xué)生的目標崗位需求來確定教學(xué)內(nèi)容,按照“以學(xué)生為主體,以教師為主導(dǎo),充分發(fā)揮學(xué)生的主動性”原則來設(shè)計各個環(huán)節(jié)。本文將對該專業(yè)中核心課程《Hadoop大數(shù)據(jù)平臺》的教學(xué)設(shè)計與實施方案進行討論與總結(jié)。
1 面向?qū)嶋H應(yīng)用的課程內(nèi)容設(shè)計
在“大數(shù)據(jù)技術(shù)與應(yīng)用”專業(yè)課程體系,“Hadoop大數(shù)據(jù)平臺”是最核心的課程,目的是讓學(xué)生在具備先修課“Linux系統(tǒng)管理”“關(guān)系數(shù)據(jù)庫”“Java開發(fā)”“大數(shù)據(jù)與云計算概論”等技術(shù)基礎(chǔ)課后,進一步學(xué)習(xí)分布式存儲技術(shù)、并行計算框架技術(shù)等大數(shù)據(jù)系統(tǒng)相關(guān)技術(shù)課程,本課程計劃課時為100學(xué)時。
大數(shù)據(jù)系統(tǒng)是一個龐大的生態(tài)系統(tǒng),而Hadoop是生態(tài)系統(tǒng)的典型代表,其提供的分布式存儲方案HDFS、并行計算方案MapReduce構(gòu)成了大數(shù)據(jù)系統(tǒng)的基礎(chǔ)架構(gòu),在此框架基礎(chǔ)上,為了解決不同應(yīng)用場景的問題又逐漸發(fā)展起了面向各種不同應(yīng)用的生態(tài)組件,這就是學(xué)生畢業(yè)后要面對的主要系統(tǒng),如圖1所示。
根據(jù)高職教育的特點和目標崗位需求,我們秉承理論夠用、重在實踐的原則,通過分析企業(yè)的實際應(yīng)用情況,我們精選最主流最常用的技術(shù)與組件來構(gòu)成本課內(nèi)容。Hadoop體系結(jié)構(gòu)、HDFS、MapReduce屬于大數(shù)據(jù)技術(shù)的基礎(chǔ)性知識,是學(xué)習(xí)和理解其他技術(shù)的前提;Hive是一種簡便開發(fā)MapReduce程序解決大數(shù)據(jù)離線分析的工具,能解決企業(yè)近一半應(yīng)用,簡單易用廣受歡迎;HBase是適合大數(shù)據(jù)實時查詢應(yīng)用的非關(guān)系數(shù)據(jù)庫,底層采用HDFS進行大數(shù)據(jù)存儲;Sqoop可以將企業(yè)已經(jīng)收集起來的大量的關(guān)系型生產(chǎn)數(shù)據(jù)導(dǎo)入到Hadoop中進一步處理,還可以將處理后的結(jié)果再傳回到關(guān)系數(shù)據(jù)庫,Sqoop在很多企業(yè)中有著硬性的應(yīng)用需求;Spark是一種與Hadoop相似的集群計算環(huán)境,基于內(nèi)存計算,從而數(shù)據(jù)分析速度更快,有逐步替代MapReduce計算的趨勢,是Hadoop生態(tài)系統(tǒng)中重要的組成成員。由此我們將Hadoop框架和這6個功能組件共7個模塊確定為本課的核心內(nèi)容,見圖1中的灰色部分,其中的YARN與ZooKeeper是學(xué)習(xí)7個模塊過程中的輔助學(xué)習(xí)內(nèi)容。

圖1 Hadoop體系架構(gòu)及教學(xué)模塊
本課程包含的內(nèi)容模塊較多,對每個模塊我們定位在初步認識和簡單使用這一層面,讓學(xué)生理解Hadoop及其各組件的基本工作機制、學(xué)會整個系統(tǒng)的安裝部署與調(diào)試,具備一定的操作、維護與應(yīng)用能力,后期學(xué)生可以在MapReduce開發(fā)、Hive數(shù)據(jù)分析等方面繼續(xù)深入學(xué)習(xí)。
2 任務(wù)驅(qū)動的教學(xué)方案設(shè)計
Hadoop是由多個相互關(guān)聯(lián)又相對獨立的功能模塊構(gòu)成的,課程實踐性、操作性強,非常適合采取任務(wù)驅(qū)動教學(xué)方式。任務(wù)驅(qū)動是一種以學(xué)生為主體,以教師為主導(dǎo)的教學(xué)做一體化的教學(xué)形式。學(xué)習(xí)過程中,由老師提出問題布置任務(wù),學(xué)生在完成任務(wù)的過程中學(xué)到新知識和技能。在任務(wù)驅(qū)動下,學(xué)生變被動為主動,體現(xiàn)了“以學(xué)生為中心”的原則,是一種適合于學(xué)習(xí)新知識、掌握新技能的探究式學(xué)習(xí)方式。
任務(wù)驅(qū)動學(xué)習(xí)方式下,教學(xué)組織以“任務(wù)”為載體,老師需要根據(jù)教學(xué)內(nèi)容要求,把知識、技能分解,根據(jù)學(xué)生水平和學(xué)習(xí)條件設(shè)計為一個個適當?shù)娜蝿?wù),讓學(xué)生逐個去完成,將教學(xué)內(nèi)容蘊含于任務(wù)之中。該課程模塊劃分清晰,我們將每個模塊設(shè)計成一項綜合任務(wù),每個任務(wù)中又包括知識準備和實戰(zhàn)兩類多項具體子任務(wù),即要先簡單學(xué)習(xí)基本概念、功能及原理等預(yù)備知識,之后再動手進行系統(tǒng)安裝部署,進行實際操作完成任務(wù),最后進行總結(jié)交流,進一步加深理解、完善知識體系。
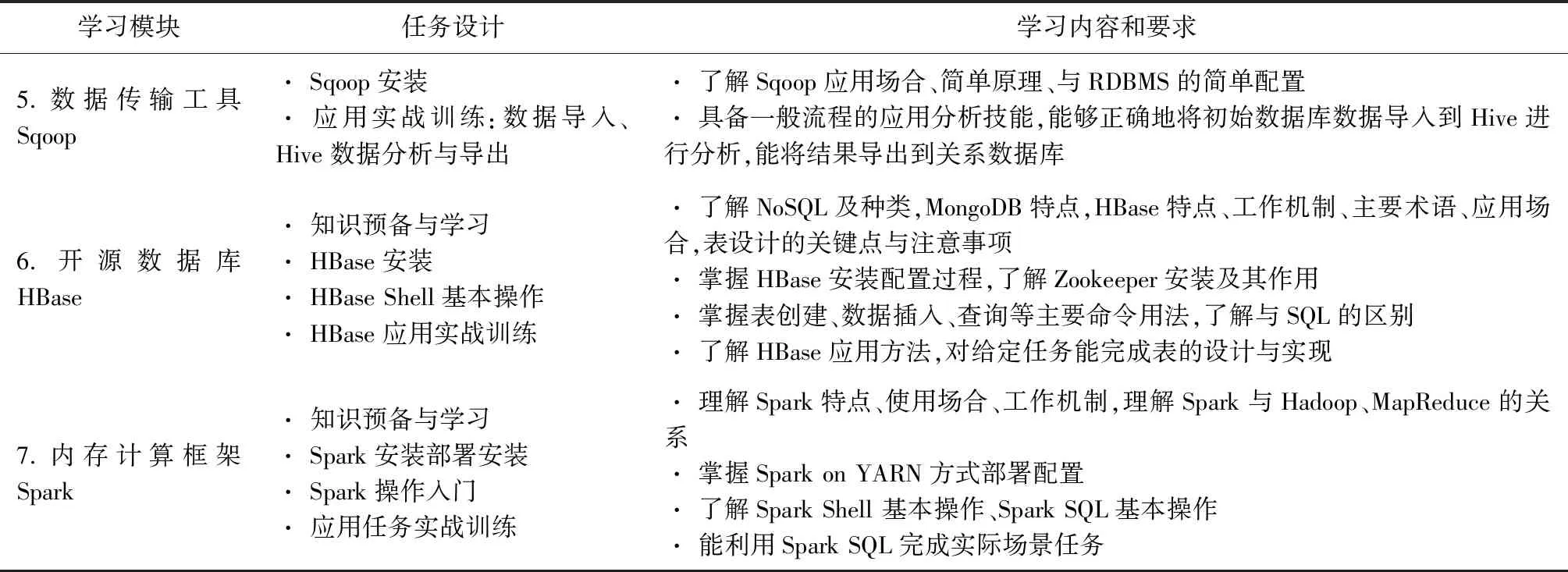
任務(wù)的先后順序主要基于該組件在Hadoop生態(tài)圈所處的層次與地位來考慮,本課程按照自底向上、自里到外,自基礎(chǔ)到擴展的原則來設(shè)計安排講解的次序,逐步遞進。針對7個模塊共設(shè)計了20多項學(xué)習(xí)任務(wù),如表1所示。

表1 教學(xué)任務(wù)設(shè)計
學(xué)習(xí)模塊任務(wù)設(shè)計學(xué)習(xí)內(nèi)容和要求5.數(shù)據(jù)傳輸工具Sqoop· Sqoop安裝 · 應(yīng)用實戰(zhàn)訓(xùn)練:數(shù)據(jù)導(dǎo)入、Hive數(shù)據(jù)分析與導(dǎo)出· 了解Sqoop應(yīng)用場合、簡單原理、與RDBMS的簡單配置 · 具備一般流程的應(yīng)用分析技能,能夠正確地將初始數(shù)據(jù)庫數(shù)據(jù)導(dǎo)入到Hive進行分析,能將結(jié)果導(dǎo)出到關(guān)系數(shù)據(jù)庫6.開源數(shù)據(jù)庫HBase· 知識預(yù)備與學(xué)習(xí) · HBase安裝 · HBase Shell基本操作 · HBase應(yīng)用實戰(zhàn)訓(xùn)練· 了解NoSQL及種類,MongoDB特點,HBase特點、工作機制、主要術(shù)語、應(yīng)用場合,表設(shè)計的關(guān)鍵點與注意事項 · 掌握HBase安裝配置過程,了解Zookeeper安裝及其作用 · 掌握表創(chuàng)建、數(shù)據(jù)插入、查詢等主要命令用法,了解與SQL的區(qū)別 · 了解HBase應(yīng)用方法,對給定任務(wù)能完成表的設(shè)計與實現(xiàn)7.內(nèi)存計算框架Spark· 知識預(yù)備與學(xué)習(xí) · Spark安裝部署安裝 · Spark操作入門 · 應(yīng)用任務(wù)實戰(zhàn)訓(xùn)練· 理解Spark特點、使用場合、工作機制,理解Spark與Hadoop、MapReduce的關(guān)系 · 掌握Spark on YARN方式部署配置 · 了解Spark Shell 基本操作、Spark SQL基本操作 · 能利用Spark SQL完成實際場景任務(wù)
每個模塊對應(yīng)3-4個任務(wù),所有要求的知識技能點都有對應(yīng)的子任務(wù),任務(wù)設(shè)計由簡到繁,由易到難,循序漸進,課程知識全部涵蓋其中。完成所有任務(wù)后,學(xué)生即可完成一個大數(shù)據(jù)系統(tǒng)的完整安裝配置,同時完成其中蘊含的、課程要求的知識技能的學(xué)習(xí)任務(wù)。本課程內(nèi)容具體組織與要求如下表所示(按100學(xué)時設(shè)計)。
具體教學(xué)實施過程:
(1) 接受任務(wù):接受老師下達的任務(wù)書,明確任務(wù)要求,成立任務(wù)小組。
(2) 定方案:學(xué)習(xí)相關(guān)預(yù)備知識,準備資料,研討確定完成步驟和方案。
(3) 學(xué)做一體化完成任務(wù):安裝部署項目的系統(tǒng)環(huán)境,進行調(diào)測配置,利用系統(tǒng)環(huán)境完成規(guī)定任務(wù),進行技能訓(xùn)練。
(4) 總結(jié)交流:進行小組項目總結(jié),形成PPT匯報,集中交流點評。
(5) 課程診改:對階段教學(xué)進行效果評估,設(shè)計下一步的教學(xué)任務(wù)及改革方案。
通過教學(xué)做一體化過程實踐,學(xué)生達到學(xué)知識、練技能、提能力、悟原理的目標。同時提高了學(xué)習(xí)能力、分析問題解決問題能力、動手能力和團隊精神。
3 注重能力培養(yǎng)的實訓(xùn)方案設(shè)計
實訓(xùn)環(huán)境是實施任務(wù)驅(qū)動教學(xué)的必要保障條件,本課程涉及到的實訓(xùn)環(huán)境復(fù)雜,這是由大數(shù)據(jù)系統(tǒng)本身的復(fù)雜性和教學(xué)實施的過程性決定的,整個學(xué)習(xí)過程是循序漸進的,這就需要根據(jù)學(xué)習(xí)進度,為學(xué)生提供不同場景、不同階段、不同層次的實訓(xùn)環(huán)境。其中,既有單節(jié)點環(huán)境又有多節(jié)點的完全分布式環(huán)境,既需要有現(xiàn)成的操作訓(xùn)練平臺,又需要有讓學(xué)生從零開始一步一步的系統(tǒng)搭建平臺的環(huán)境,還需要有處在不同狀態(tài)下的實訓(xùn)場景和安裝好不同組件的半成品平臺,既有基本的使用操作又有應(yīng)用案例的綜合操作,既有字符界面又有圖形化界面,既有小任務(wù)又有大任務(wù)(需要保留環(huán)境下次繼續(xù)操作)。
3.1 兩種實訓(xùn)環(huán)境分析
當前可以采用的實訓(xùn)方案基本分兩種:一是本地機器方式,二是學(xué)生登錄校內(nèi)服務(wù)器線上操作,但前提是學(xué)校需購買專門的大數(shù)據(jù)實訓(xùn)平臺軟件并搭建集群服務(wù)器環(huán)境。
1. 本地機器方式:這種方式下,每個學(xué)生需要一臺Linux機器,而且是Linux虛擬機。因為用Linux物理機會有很多問題,如:很難準備出多個安裝了不同組件進度的Hadoop環(huán)境,學(xué)生使用一臺機器必須從課程開頭一直做到尾,中間如出現(xiàn)問題很難繼續(xù)前行,即使恢復(fù)系統(tǒng)也不易控制恢復(fù)點,再有,Linux對PC機硬件的兼容性也不是太好,因此我們采用了更靈活的虛擬機方式。
但是這種方式,教師需要親自將每一種狀態(tài)的虛擬機環(huán)境準備出來,而且有時候準備并不順利、會遇到各種意外的問題或返工或排除,投入的精力會相當大,當然老師從中也能積累實踐經(jīng)驗,提高執(zhí)教能力。
2. 在線大數(shù)據(jù)實訓(xùn)平臺方式:近兩年,市場上已經(jīng)出現(xiàn)一些商品化的大數(shù)據(jù)實訓(xùn)平臺軟件,它部署于多節(jié)點構(gòu)成的服務(wù)器集群上,專門用于大數(shù)據(jù)技術(shù)實驗教學(xué)。這個平臺提供了比較全面的實驗機類型,也提供了一些實際的應(yīng)用案例,學(xué)生可以隨時隨地的線上操作練習(xí),學(xué)生使用簡單,老師管理和備課難度降低,但是因為實驗中學(xué)生只要按規(guī)定步驟做即可完成任務(wù),內(nèi)容死板,不夠靈活,不利于鍛煉學(xué)生的實際能力,發(fā)揮余地小。
所以經(jīng)過實踐測試和分析比較,我們最終設(shè)計的實訓(xùn)環(huán)境方案是本地虛擬機方式與在線大數(shù)據(jù)實訓(xùn)平臺相結(jié)合,互補進行。
3.2 實訓(xùn)方案設(shè)計
根據(jù)各模塊的內(nèi)容特點、教學(xué)目標、學(xué)生學(xué)情,我們具體設(shè)計的實訓(xùn)方案如下。
1. 本地虛擬機方式實訓(xùn)方案:設(shè)計并提供4種虛擬機,供學(xué)生的不同實訓(xùn)項目使用。由于每一種虛擬機其實就是Windows下的一些文件,因此,課前要把教師已做好的虛擬機文件,分發(fā)到每臺學(xué)生機上,實訓(xùn)時學(xué)生直接打開虛擬機,即可直接進入相應(yīng)的實訓(xùn)環(huán)境中。
Linux虛擬機:僅安裝Linux,即一臺Linux機器,供學(xué)生完成Linux平臺下的各種實訓(xùn)項目,包括Linux基本操作與應(yīng)用、Hadoop本地模式安裝、Hadoop偽分布式安裝、圖形化升級、eclipse安裝、Hadoop開發(fā)插件安裝、Java 的HDFS API開發(fā)、Hadoop完全分布式安裝等實訓(xùn)實驗項目;
單個Hadoop虛擬機(偽分布模式):即一臺Linux機器,并已安裝Hadoop系統(tǒng)。供Hadoop shell操作、MapReduce應(yīng)用案例實驗、Hive安裝、HBase安裝、Spark安裝等;
完全分布式Hadoop虛擬機:3個虛擬機、構(gòu)成3節(jié)點的Hadoop集群,供Hadoop集群運維、HA拓展實驗等;
Hadoop完全實驗機:安裝了本課程所有模塊軟件,供Hive實驗、HBase實驗、Spark實驗及應(yīng)用案例等實驗。
計算機配置采用8GB內(nèi)存,4個節(jié)點時運行流暢。以上是我們的做法,實際中也可以根據(jù)需要提供更多處于不同階段的虛擬機,供學(xué)生實訓(xùn)使用。這種方式的優(yōu)點是學(xué)習(xí)方便,適合進行技能學(xué)習(xí)訓(xùn)練,存在的主要問題是虛擬機方式缺乏直觀性、與生產(chǎn)環(huán)境有差異。
2. 在線大數(shù)據(jù)實訓(xùn)平臺方式實訓(xùn)方案:根據(jù)這種方式開放性好,不受時間地點限制、環(huán)境穩(wěn)定操作簡單、方便重復(fù)的特點,在平臺上設(shè)計的實訓(xùn)項目主要有:階段性技能練習(xí)項目,原理視頻的學(xué)習(xí)、課下的作業(yè)完成與實訓(xùn)練習(xí)、各部分中shell命令的操作練習(xí)、單一步驟的操作實訓(xùn)、平臺集成的案例操作、以及平臺提供的其他成熟實訓(xùn)項目等。另外在平臺還可安排需要多次課連續(xù)操作的大任務(wù)大應(yīng)用實訓(xùn)、三個節(jié)點以內(nèi)的完全分布式安裝、元數(shù)據(jù)存至MySQL的Hive部署等實訓(xùn)項目。
需注意的是這些平臺為了操作簡單往往會對用戶屏蔽很多內(nèi)容,做實驗的環(huán)境都是一個與之綁定的實驗機,很多東西已經(jīng)內(nèi)置好了,學(xué)生按要求步驟繼續(xù)操作下去即可,導(dǎo)致學(xué)生對實驗環(huán)境難以深刻了解,操作過程中程序在哪、數(shù)據(jù)在哪,總是云里霧里、心里不透亮,會影響對內(nèi)容的理解。同時教師也很難在平臺上部署個性化的教學(xué)環(huán)境,所以更靈活的拓展實訓(xùn)需要結(jié)合本地虛擬機方式進行。
4 總結(jié)
目前,我們已經(jīng)完成了兩個班級的教學(xué)活動,在教學(xué)過程中,根據(jù)設(shè)計方案堅持通過學(xué)生主體參與,強化能力培養(yǎng);通過教師主導(dǎo),突破學(xué)習(xí)難點提高效率;通過分組分層照顧個體差異,保證所有人都能學(xué)有所獲,取得了良好效果。但教學(xué)研究永無止境,為了更好地培養(yǎng)學(xué)生,需要大家共同努力,堅持診改,不斷優(yōu)化教學(xué)方案。
猜你喜歡
中老年保健(2021年12期)2021-08-24 03:30:40
中國傳媒大學(xué)學(xué)報(自然科學(xué)版)(2021年1期)2021-06-09 08:43:00
內(nèi)蒙古教育(2021年20期)2021-03-08 01:09:14
計算機教育(2020年5期)2020-07-24 08:53:38
裝備制造技術(shù)(2020年12期)2020-05-22 09:25:38
中國生殖健康(2020年6期)2020-02-01 06:28:50
家庭影院技術(shù)(2019年11期)2019-12-09 09:14:30
中國生殖健康(2019年11期)2019-01-07 01:28:02
電子制作(2017年8期)2017-06-05 09:36:15
信息記錄材料(2016年4期)2016-03-11 15:22:54
