區(qū)分冗余序列的抽象文本摘要
2019-11-29 10:25:30俞鴻飛殷明明段湘煜
廈門大學學報(自然科學版) 2019年6期
俞鴻飛,王 坤,殷明明,段湘煜,張 民
(蘇州大學計算機科學與技術學院,江蘇 蘇州 215006)
自動摘要主要有兩種方法:抽取方法[1]和抽象方法[2].抽取方法主要分析文檔信息,提取源句子中的一部分信息并按照順序連接,生成最終的摘要文本.抽象方法主要是基于源文本的核心思想將源文本概述成短文本摘要.抽象方法能夠正確重寫源文本的核心思想,并且十分切合人類摘要的方法.隨著神經(jīng)網(wǎng)絡發(fā)展,序列到序列模型也被運用到了抽象文本摘要領域.其主要結構是通過編碼長文本序列,在目標端融入注意力機制解碼成短摘要文本.
序列到序列架構主要有3種:遞歸神經(jīng)網(wǎng)絡[3-4](recurrent neural network,RNN)、卷積神經(jīng)網(wǎng)絡[5](convolutional neural network, CNN)以及自注意力機制的神經(jīng)網(wǎng)絡[6].基于RNN的模型架構被廣泛采用和探索,主要方法有融入源端句子信息的RNN模型[7];使用統(tǒng)計語言特征命名實體識別(NER)和詞性(POS)標簽進一步豐富RNN的編碼器信息[8].除了有在RNN框架上的修改,也有將CNN架構運用到摘要文本中.如:Gehring等[5]在編碼器和解碼器都采用了CNN的模型結構,并將其運用到了抽象摘要任務;Wang等[9]在ConvS2S的基礎上融入了主題詞的嵌入信息,并結合強化學習訓練文本摘要系統(tǒng).此外,還有通過改進訓練方法進一步加強文本摘要系統(tǒng)的訓練能力.如:Ayana[10]所提出的最小風險訓練;Eduno等[11]提出的訓練結構化預測模型;以及Lin等[12]提出全局編碼結構.以上實驗方法通過改進模型結構,融入多種訓練方法等對RNN和CNN模型進行拓展以提升文本摘要系統(tǒng)生成摘要的質(zhì)量.
雖然序列到序列模型能夠得到高質(zhì)量的摘要文本,但并不能有效地區(qū)分源端句子中的冗余信息,而且這種冗余信息對于生成摘要的影響往往是負面的.為了解決這一問題,本文中提出了一種能夠區(qū)分冗余序列的模型結構以提升抽象文本摘要方法的摘要性能.考慮到基于自注意力機制神經(jīng)網(wǎng)絡的Transformer模型在機器翻譯領域取得的卓越性能效果,且抽象文本摘要系統(tǒng)與機器翻譯相類似,也符合序列到序列的結構特征,因此本文中將Transformer模型結構應用于抽象文本摘要.在Transformer模型基礎上,利用冗余序列區(qū)分源端序列中的冗余部分,進而更好地提取摘要信息.以Transformer模型作為強基準系統(tǒng),在Gigaword和DUC2004英語測試集以及LCSTS中文測試集上進行實驗驗證.
1 基準系統(tǒng)
Transformer模型是基于注意力機制的序列到序列的結構,采用編碼器-解碼器的框架,該結構先將源文本編碼成隱藏向量,再基于源端信息和目標生成的歷史信息解碼出摘要文本.與傳統(tǒng)的序列到序列模型RNN和CNN不同的是,Transformer模型在編碼器和解碼器上完全采用了自注意力機制.
1.1 詞嵌入以及位置編碼
對輸入的句子元素進行建模,將源端句子X={x1,x2,…,xn}通過分布空間映射成為詞向量h=[h1,h2,…,hi,…,hn],其中hi∈Rd,n表示源端輸入序列的單詞個數(shù),d為詞向量的維度大小.需要注意的是,Transformer模型結構無法表示詞與詞之間的先后順序關系.為了解決這一問題,Transformer模型嵌入了輸入元素的絕對位置向量p=[p1,p2,…,pi,…,pn],其中pi∈Rd;并將兩者組合得到最終的詞向量e=[h1+p1,h2+p2,…,hn+pn].與源端類似,目標端獲得的詞向量為g=[g1,g2,…,gm].位置編碼對于神經(jīng)網(wǎng)絡十分重要,這能讓神經(jīng)網(wǎng)絡學習到句子的序列信息,了解到當前詞在序列中相應位置.
1.2 編碼器
如圖1左側(cè)所示,編碼器堆疊了N層的相同網(wǎng)絡層,每層都包含了兩個子層:多頭的自注意力機制層(本文中簡稱:自注意力層)以及全連接的前饋神經(jīng)網(wǎng)絡層(本文中簡稱:前饋子層).并且每個子層的輸出都運用了殘差網(wǎng)絡[13]以及層歸一化[14],以便訓練更深層次的神經(jīng)網(wǎng)絡.
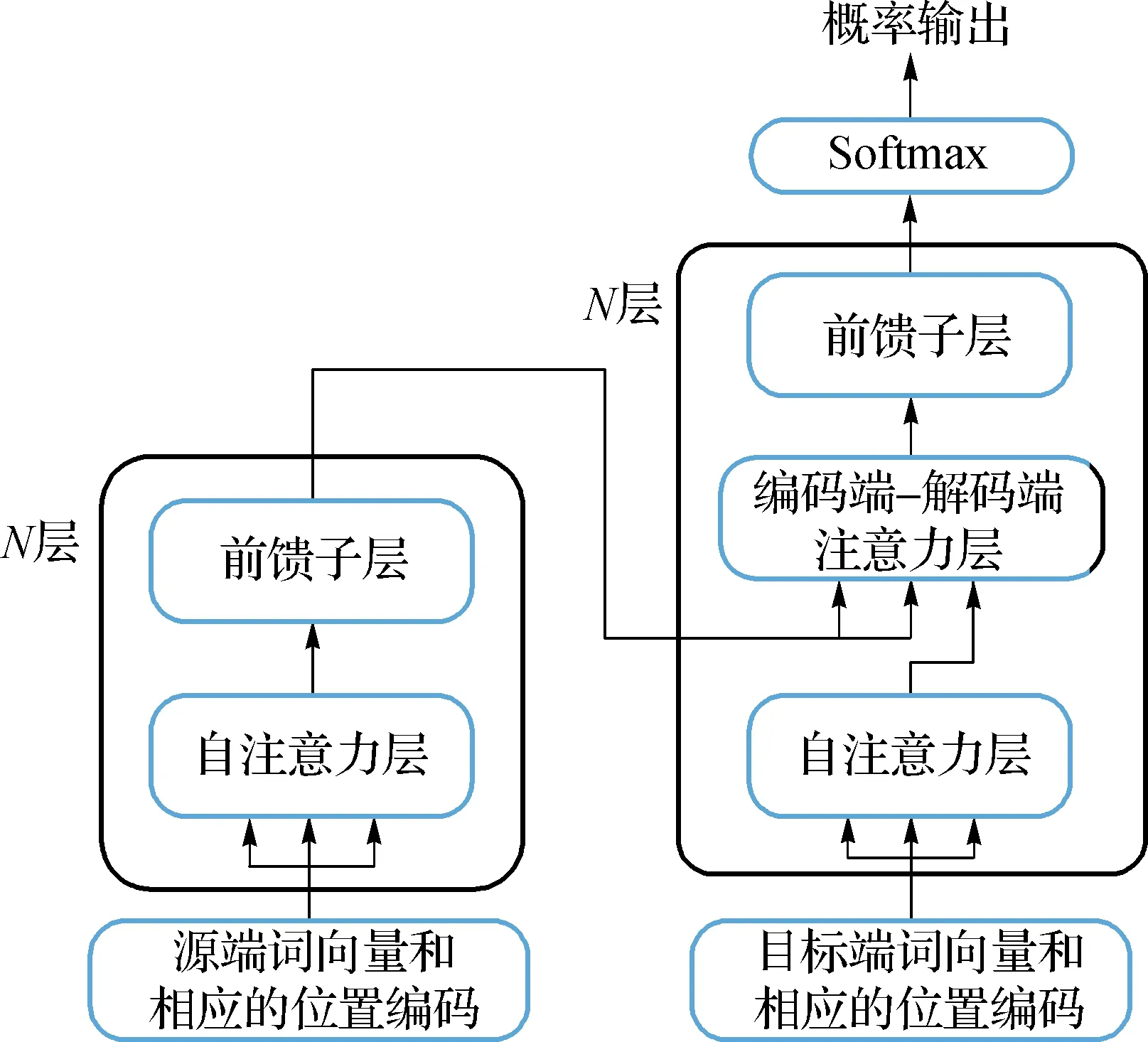
圖1 Transformer模型結構Fig.1 The model structure of Transformer
自注意力層主要采用劃分成多頭的注意力機制以及規(guī)范化點乘的注意力機制,具體如式(1)和(2)所示:
(1)
(2)
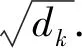
前饋子層主要由兩個全連接層以及ReLU激活函數(shù)組成,具體公式如(3)所示:
fff(z)=max(0,zW1+b1)W2+b2,
(3)
其中:fff為前饋網(wǎng)絡函數(shù);W1∈Rdff×d,W2∈Rdff×d;dff表示前饋子層的內(nèi)層網(wǎng)絡維度;z表示自注意力機制層提取之后的隱藏向量.在通過前饋子層之后,最后的輸出會重新輸出給后一層的自注意力機制層的,進行更深層次的信息提取,直到N層網(wǎng)絡提取特征信息結束再輸出給目標端得到相應的概率分布.
1.3 解碼器
如圖1右側(cè)部分所示,與編碼器類似,解碼端也堆疊了N層的相同的網(wǎng)絡,但是每層由3個子層組成:自注意力層、編碼-解碼注意力層和前饋子層.目標端的自注意力層的Q,K,V都來自于目標端的詞向量g.與源端自注意力層不同的是,目標端需要對當前詞的未來信息增加掩碼,防止未來單詞信息參與隱藏層計算,前饋子層則保持不變.
目標端編碼-解碼注意力層的主要目的是為了獲取更多的源端信息,除了目標端序列的信息,還需要獲取當前的目標端詞對應源端序列中的某一個詞或者某一段的源端序列信息.在編碼-解碼注意力中,Q來自于解碼器的自注意力子層的輸出,而K和V則是來自于編碼器最后一層的輸出.無論是自注意力層還是編碼-解碼注意力層,依舊采用的是多頭的注意力機制并且在每次輸出之后仍運用了殘差網(wǎng)絡和層歸一化方法.
2 區(qū)分冗余序列的抽象文本摘要
2.1 數(shù)據(jù)處理
Transformer模型結構最初為機器翻譯研究所提出.雖然抽象文本摘要與機器翻譯任務都屬于序列到序列的任務,但是在數(shù)據(jù)方面和句子形式上有不同之處.在抽象文本摘要中,目標端的句子相較于源端句子的長度更短,更加精煉.因此在源端句子中有一部分信息是冗余的,不能幫助到目標端摘要的生成,而機器翻譯則無冗余信息.
為了解決這一問題,實驗分成兩個步驟進行:先獲取相對應的冗余信息,再將冗余信息運用到Transformer模型結構.獲取冗余信息:本文中使用GIZA++工具對平行的摘要數(shù)據(jù)進行詞對齊,獲得目標端詞對應源端多個詞的對齊信息,如圖2所示.之后將目標端所對應的源端詞用特殊符號
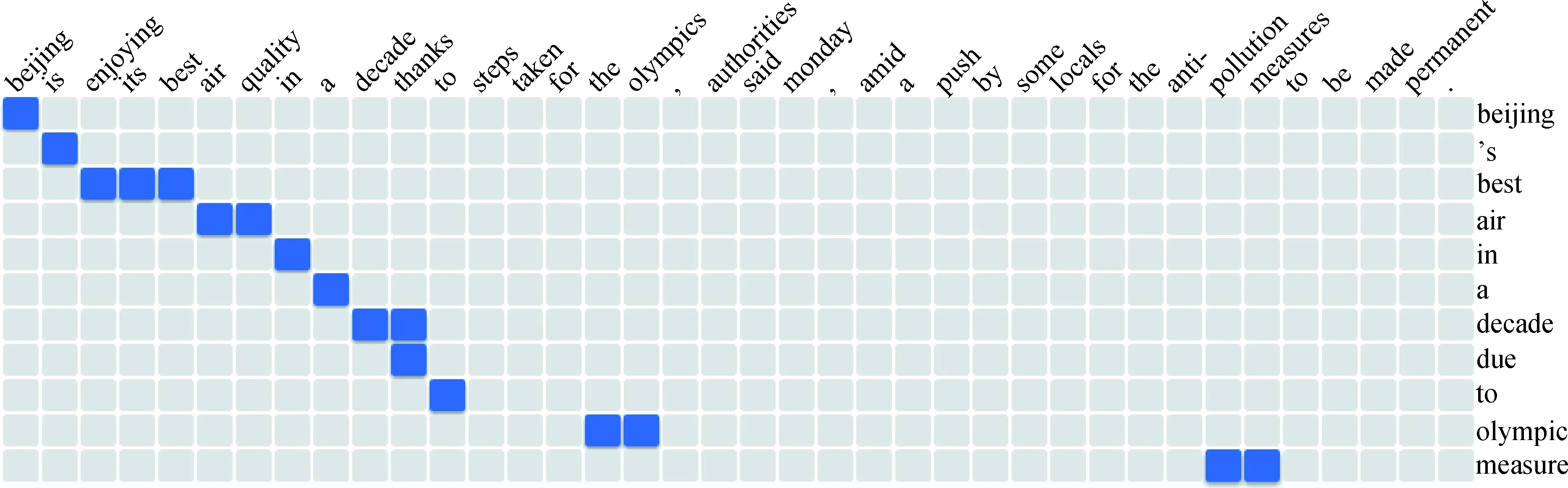
圖2 對齊樣例Fig.2 Alignment example

Source: Beijing is enjoying its best air quality in a decade thanks to steps taken for the olympics, authorities said monday, amid a push by some locals for the anti- pollution measures to be made permanent.GIZA++: 0-0 1-1 2-2 3-2 4-2 5-3 6-3 7-4 8-5 9-6 10-6 10-7 11-8 15-9 16-9 31-10 32-10Redundancy_Source:
通過上述兩個步驟對訓練數(shù)據(jù)和驗證集數(shù)據(jù)進行處理,分別得到了3份數(shù)據(jù).第一份是源端文本,第二份是目標端抽象摘要文本,第三份是源端的冗余文本.
2.2 模型搭建
在獲得冗余信息之后,本文中對Transformer模型結構做進一步改進.使得Transformer模型能夠更好的區(qū)分相關信息以及冗余信息.如圖3所示,左側(cè)的解碼器與基準系統(tǒng)的解碼器保持一致,輸入摘要序列并輸出相對應的摘要序列概率.本文中在原解碼器的基礎上又增加了一個解碼器用于解碼冗余特征序列,將GIZA++得到的冗余序列作為輸入,通過共享左側(cè)解碼器的參數(shù)以及經(jīng)過不同的輸出層得到相對應的冗余序列概率.在解碼器中所包含的子層都與Transformer中子層保持一致.
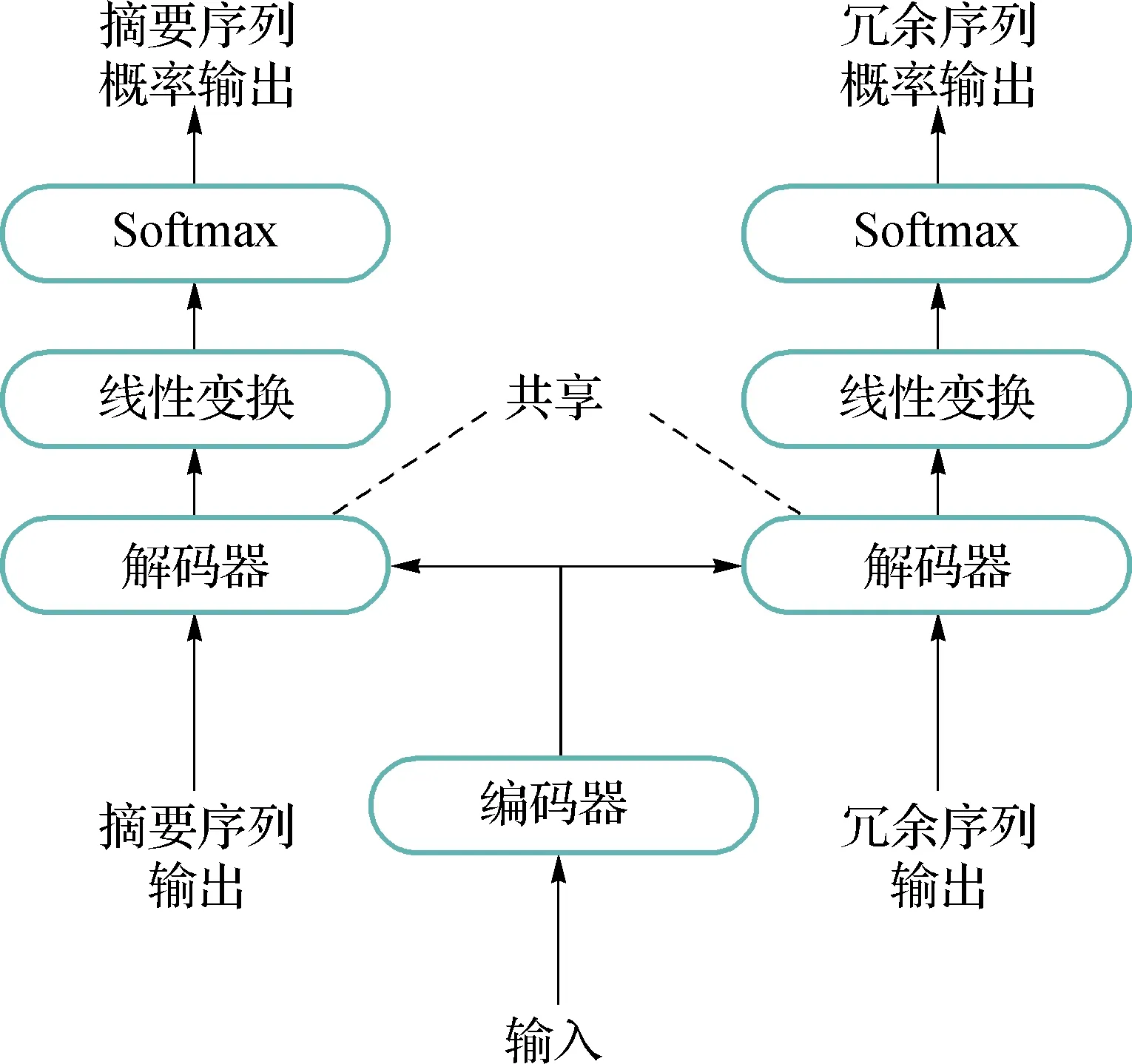
圖3 區(qū)分冗余序列的模型結構Fig.3 Model structure that distinguishes redundant sequences
本文中通過給定冗余信息的方法,讓神經(jīng)網(wǎng)絡能夠?qū)W習區(qū)分源端句子中的相關信息以及冗余信息.摘要序列對應著源端的相關信息,冗余序列則對應著源端的冗余信息.通過反向傳播更新神經(jīng)網(wǎng)絡的權值分布,以達到區(qū)分冗余序列以及專注源端相關信息的效果.
2.3 損失函數(shù)
本文中在原損失函數(shù)的基礎上融入了冗余損失函數(shù),具體式為:
(4)
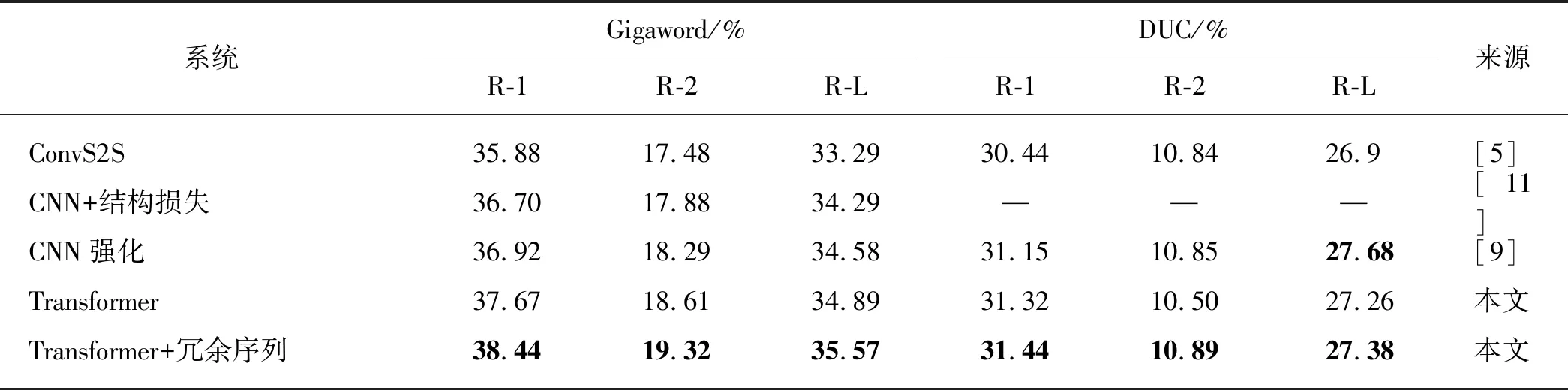
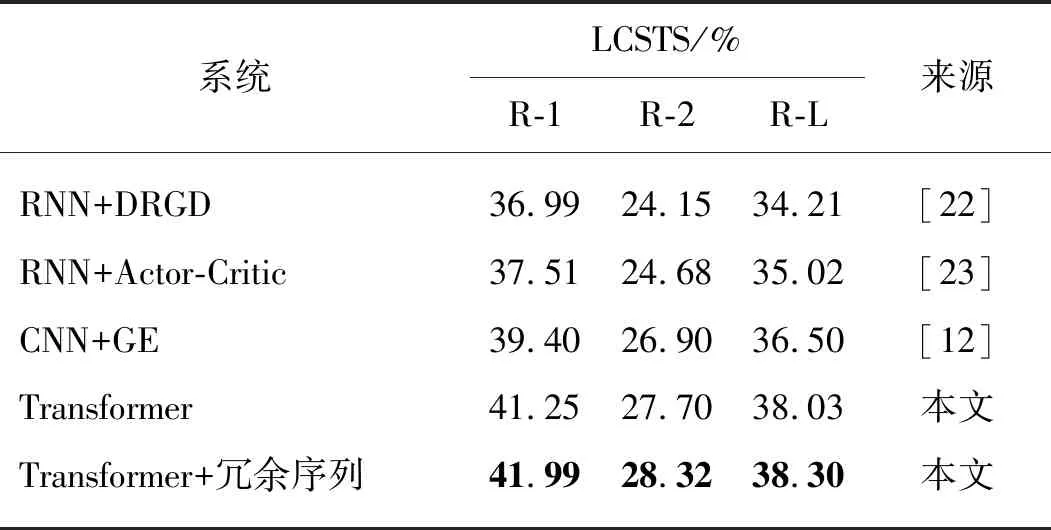
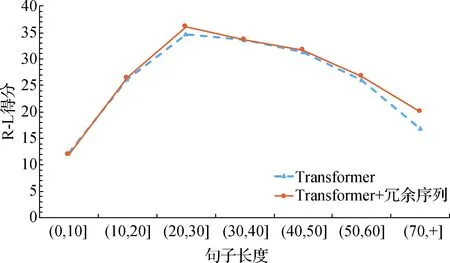
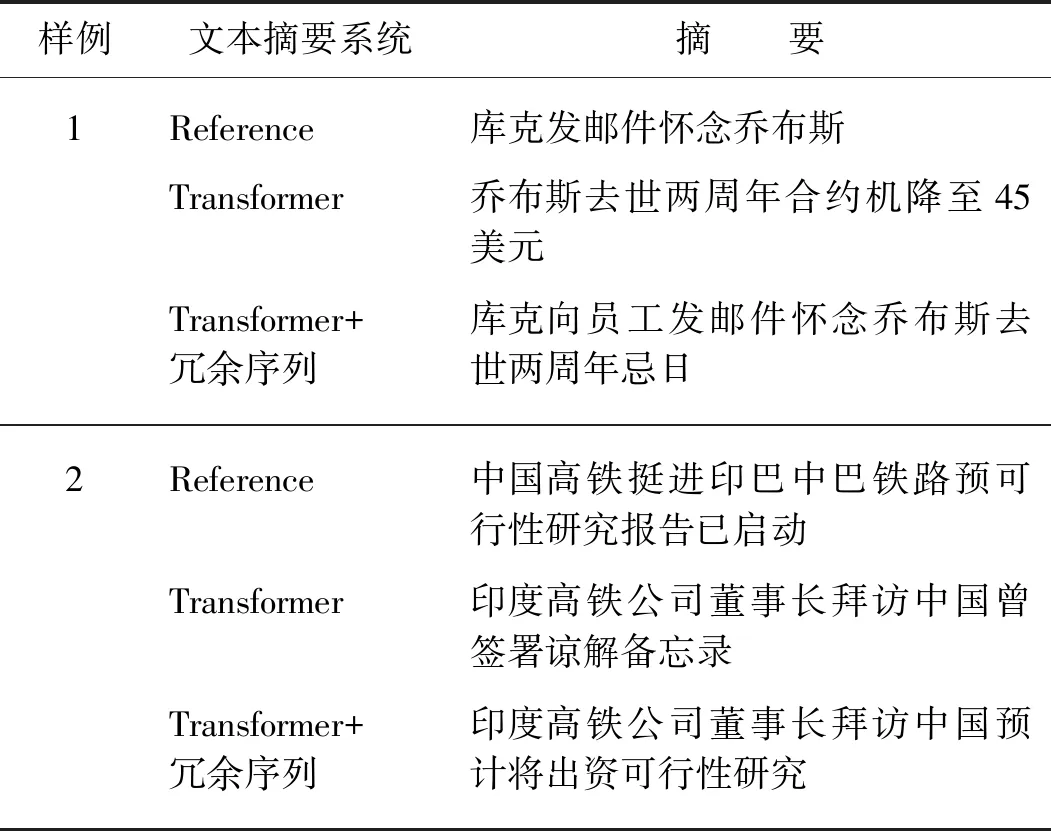
其中:M表示目標端摘要的長度;J表示目標端冗余序列的長度;p(yi|y 本實驗在3個抽象文本摘要數(shù)據(jù)集上評估所提出的方法.首先,將帶注釋的Gigaword語料采取與Rush等[15]相同的預處理,產(chǎn)生約380萬個訓練樣本、19萬個驗證樣本和1 951個測試樣本進行評估.文本到摘要的平行數(shù)據(jù)對是通過將每篇文章的第一句與其標題配對形成.另外,本文采用DUC-2004[16]作為另一個英文數(shù)據(jù)集,僅用于實驗測試.它包含500個文檔,每個文檔包含4個人工生成的參考摘要. 本實驗使用的最后一個數(shù)據(jù)集是中文短文本摘要的數(shù)據(jù)集(LCSTS)[17],該數(shù)據(jù)集由新浪微博網(wǎng)站收集.遵循原始論文的數(shù)據(jù)分割,將來自語料庫的2 400 000 對文本到摘要的平行數(shù)據(jù)對用于訓練,8 000 對的平行句對用于驗證集,并且挑選了高得分的725對平行句對用于測試. 本文中采用Transformer作為基礎架構,按圖1在編碼器和解碼器各堆疊6層,嵌入向量和所有隱藏向量的維度設置為512,前饋子層的內(nèi)層維度為2 048,多頭注意力層m=8.在本實驗中共享源端、目標端詞嵌入層以及目標端的摘要輸出層,但并不共享冗余序列的輸出層.在英語數(shù)據(jù)上,本文中運用了字節(jié)對編碼(byte-pair-encoding,BPE)[18],共享源端到目標端的詞匯量并設置為32 000. 本實驗在NVDIA 1080 GPU上進行,采用基于深度學習框架PyTorch的Transformer模型為基準框架.在訓練期間,調(diào)用Adam優(yōu)化器[19],其中超參數(shù)β1=0.9,β2=0.98,ε=10-9,初始學習率為0.000 5.另外,本實驗在所有數(shù)據(jù)集上失活率(dropout)都設置為0.3,標簽平滑[20]值設置為0.1.在評估時,本實驗采用面向召回替補的摘要評估(recall-oriented understudy for gisting evaluation,ROUGE)[21]作為評估指標.由于標準的ROUGE包只能用于評估英文摘要系統(tǒng),本文中采用Hu等[17]的方法將中文字映射成的數(shù)字ID,以評估中文數(shù)據(jù)集的性能,在解碼的時候,集束搜索(beam search)的大小設置為12. 4.1.1 英文測試集結果 表2給出了近些年神經(jīng)網(wǎng)絡模型在Gizaword和DUC2004上所展現(xiàn)的實驗效果以及基準系統(tǒng)Transformer模型和使用了本文中所提出的模型結構的實驗結果.需要注意一點,對于Gizaword數(shù)據(jù)所采用的評估指標是基于F值(正確率(P)與召回率(R)的加權調(diào)和平均)的ROUGE-1(R-1)、ROUGE-2(R-2)、ROUGE-L(R-L),而DUC數(shù)據(jù)的則是基于R.表中列舉了3個在抽象文本摘要上的最新成果:Gehring等[5]提出的完全基于卷積構成ConvS2S框架的結果;在此結構的基礎上,Edunov等[11]和Wang等[9]分別從結構損失(CNN+結構損失)和強化學習(CNN強化)的角度改進模型的結果.表格中“—”表示文章中并未提及此類數(shù)據(jù)的實驗結果.最后兩行分別是Transformer基準系統(tǒng)以及本文方法(Transfomer+冗余序列)的實驗結果.從表中可以發(fā)現(xiàn),Transformer基準系統(tǒng)在英文測試集上的表現(xiàn)十分顯著.在Gigaword數(shù)據(jù)上,相較于其他系統(tǒng),Transformer基準系統(tǒng)的R-1,R-2和R-L得分均最高;并且在添加了冗余序列的信息之后,系統(tǒng)性能得到了進一步地提升.相對于Transformer基準系統(tǒng),本文中的方法在每種評估指標上的得分均增加了0.7個百分點.在DUC2004數(shù)據(jù)上,該方法也在基準系統(tǒng)上獲得了一定的提升.整體上講,該方法能夠獲得更加精準、質(zhì)量更高的摘要文本. 表2 Gizaword與DUC2004英文測試上的實驗結果 4.1.2 中文測試集結果 表3中列出了在LCSTS的中文數(shù)據(jù)上所嘗試的3個最新實驗系統(tǒng)以及實驗結果:Li等[22]2017年在RNN模型結構的基礎上融入深度循環(huán)生成解碼器(deep recurrent generative decoder, DRGD)的結果;其在2018年提出運用actor-critic框架[23]來增強RNN的訓練過程得到的改進結果;Lin等[12]在CNN模型結構上提出全局編碼結構(global encoding,GE)的結果.從表3可以看出,基準系統(tǒng)Transformer模型取得了相當高的ROUGE得分,在R-1評估標準下的得分達到了41.25%.在運用了冗余序列信息之后,R-1 得分達到了41.99%,證明本文中的方法能夠進一步改善摘要文本的準確度.需要注意的是,以上的實驗都是在基于字的數(shù)據(jù)上所作的嘗試. 表3 LCSTS的中文測試集結果 本實驗進一步測試了不同長度的Gizaword英文測試集在新模型上的效果.經(jīng)過調(diào)研,Gizaword測試集中的源端句子長度范圍主要是從10到90之間.因此,將句子長度以10為單位進行分組,得到了9個組.但是由于第8組和第9組的句子數(shù)量過少,將其合并到60+的區(qū)間內(nèi),整合成為7組.如圖3所示的,在大部分區(qū)間內(nèi),實驗模型效果都超過了基準模型的水平.尤其是在(20,30]內(nèi),實驗結果提升相當明顯,R-L得分有超過1.2個百分點的提升.在句子長度超過20的區(qū)間上,實驗模型都獲得了一定的得分提升. 圖4 在不同句長上的R-L的得分對比Fig.4 Comparison of R-L scores on different sentence lengths 在表4中,將由本實驗方法所生成的摘要文本與基準模型的摘要文本做了對比. 樣例文本如下: 樣例1:當?shù)貢r間5日是史蒂夫·喬布斯去世兩周年忌日,公司現(xiàn)任CEO庫克向全體員工發(fā)布郵件懷念這位蘋果公司的精神領袖.與此同時,美國三大零售商集體開始對剛剛上市兩周的iPhone5C進行優(yōu)惠促銷,兩年期的合約機最低售價降至45美元,跌幅過半. 樣例2:12月1日,印度高速鐵路公司董事長阿格尼霍特里一行來國家鐵路局拜訪.發(fā)言人稱,印度鐵道部團隊目前正在中國,預計會在本周簽署協(xié)議,中國將出資進行可行性研究并完成報告.中印9月曾簽署諒解備忘錄. 第一個例子中的主要信息是“庫克發(fā)郵件懷念喬布斯,同時三大零售商降價合約機”.基準系統(tǒng)關注了“合約機降價”方面,但是源文本的突出重點應該是“懷念喬布斯”,基準系統(tǒng)得到的摘要文本顯然沒有達到預期的效果,而關注了冗余信息.在使用了本實驗中的模型之后,關注點聚焦在“懷念喬布斯”上.在第二個樣例中,主要內(nèi)容是“中國將對中印鐵路進行可行性研究”.基準系統(tǒng)還是注意到了“簽署諒解備忘錄”這個冗余信息,而本實驗模型還是著重了“中印鐵路的可行性研究”,這樣的摘要文本就達到了比較好的水平. 表4 摘要文本樣例對比 本文中主要提出了能夠區(qū)分冗余序列的Transformer的模型結構.該模型結合了抽象文本摘要的特征,在最新的Transformer結構基礎上做了進一步的拓展,新增了冗余序列解碼器以獲取源文本冗余信息.實驗結果表明本文中所提出的模型架構有效地提升了抽象文本摘要的水平,并且在中英文測試集上都取得了性能提升. 在目前的實驗方法中,本文中僅考慮了冗余信息的抽象文本摘要,并未對相關信息做進一步的研究.在未來的工作中,將考慮如何在模型中更充分地提取與源端相關信息以提升抽象文本摘要的性能.3 實 驗
3.1 數(shù)據(jù)集
3.2 實驗設置
4 實驗結果和分析
4.1 實驗結果
4.2 長度分析
4.3 質(zhì)量評估分析
5 結 論
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
制造技術與機床(2019年10期)2019-10-26 02:48:08
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
發(fā)明與創(chuàng)新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
小學教學參考(2015年20期)2016-01-15 08:44:38
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
