基于卷積神經網絡的視頻軟廣播
2019-12-05 08:35:54尹文斌范曉鵬
智能計算機與應用 2019年5期
尹文斌 范曉鵬


摘 要:隨著信息技術和互聯網技術的不斷發展,無線視頻廣播越來越受到人們的歡迎,成為流行的多媒體應用之一。然而,傳統的數字編碼和傳輸方法很難適應于向多個具有不同信道質量的用戶同時發送視頻的場景,通常會遭遇懸崖效應。近期,一種新穎的無線視頻廣播方法稱為SoftCast被提出,其保存在信道中傳輸的信號與視頻像素值之間所具有線性關系并利用有效的能量分配方法,使得視頻重構質量隨著信道噪聲的增加而平緩下降。在本文中,提出了一種新型的無線視頻廣播方法,其利用深度卷積網絡和基于圖像組的稀疏表示模型,通過解碼端估計的信道質量,優化視頻的解碼過程并減輕多種由信源編碼和信道噪聲造成的視覺失真。通過視頻軟傳輸技術,本文提出的方法具有出色的視頻廣播質量可伸縮性并避免了懸崖效應的發生,同時還能提供視覺友好的主客觀重構質量。實驗結果表明,本文提出的方法在視頻廣播場景下能夠獲得優于傳統SoftCast最高1.2 dB的重建質量。
關鍵詞: 無線視頻廣播; 卷積神經網絡; 基于圖像組的稀疏表示; 視頻軟廣播
【Abstract】 With the continuous development of information technology and Internet technology, video broadcasting is becoming more and more popular in wireless networks. However, the existing digital coding and transmission approaches can hardly accommodate users with diverse channel conditions, which is called the cliff effect. Recently, a novel video broadcasting method called SoftCast has been proposed. It achieves graceful degradation with increasing noise by making the magnitude of the transmitted signal proportional to the pixel value and using a novel power allocation scheme. This paper proposes a novel video broadcast method that exploits deep convolutional networks and group based sparse representation. They utilize the channel condition information generated from decoder to optimize the decoding process and reduce the various artifacts caused by source and channel coding. By utilizing soft video broadcast transmission, it achieves good broadcasting performance, avoids the cliff effect, and also can provide visually friendly subjective and objective reconstruction quality. The experimental results show that the proposed scheme provides better performance compared with the traditional SoftCast with up to 1.2 dB coding gain.
【Key words】 ?wireless video broadcasting; Convolutional Neural Networks; group based sparse representation; soft video broadcast
0 引 言
隨著科技的不斷發展,人們開始更多地使用圖片或者視頻來交流和分享信息。在無線通信技術進步的推動下,關于無線視頻廣播技術研究已然成為當前學界熱點,其研發成果也在陸續涌現。與此同時,3G、4G技術的逐漸應用和近年來智能手機與平板電腦的處理能力越來越強而且日趨普及,人們也越來越青睞使用這些移動終端來觀看視頻,因為這樣做更方便、更智能、也更快捷。
傳統數字視頻廣播標準[1]中主要包含2部分。一部分是分層傳輸方法[2-3],另一部分則是可伸縮視頻編碼技術(SVC)[4-5]。其中,可伸縮編碼技術是指編碼端將視頻信號編碼為一個基本層(BL)和多個增強層(EL)。分層調制(HM)[6]可用于將基本層和增強層的比特流疊加到一個需要傳輸的無線信號中,如此一來也就實現了同一編碼端對于信道質量不同的用戶進行視頻廣播的目的。傳統偽模擬傳輸應用Softcast[7-8]軟廣播技術的主要貢獻是將所要傳輸的信號的線性變換直接在模擬信道上進行傳輸,這些信號只需要執行能量分配而不需要進行量化、編碼和調制。因此信道噪聲也就直接轉化為了重構噪聲,具有質量可伸縮性。為了緩解塊效應,學者們提出了很多去塊效應的后處理方案,大體上可分為2類[9-10],即:基于圖像增強的去塊效應方法和基于圖像恢復的去塊效應方法。總地來說,對于圖像增強類的方法,其基本思路是將去塊效應視為一種圖像增強過程,通過在空域和頻域進行濾波來平滑可見的失真效應。對于圖像復原類的方法,去塊效應通常被表述為一個病態圖像優化問題并利用一些圖像先驗知識和觀測數據進行求解。全變差[11]、基于塊的稀疏表示[12-14]以及馬爾科夫隨機場(MRF)均被作為圖像先驗模型用于尋找原始圖像的MAP估計。在各類研究中,文獻[15]將量化失真作為高斯噪聲,使用FoE作為圖像先驗來建立圖像去塊效應最優化問題。深度神經網絡在圖像處理、視頻分析、自然語義理解等方面取得了可觀進展。深度神經網絡是一種多層的神經網絡,通過網絡學習,從原始數據中提取不同層級的抽象信息。這種方法自然地體現了底層視覺特征到高層語義特征的演變。使用深度學習方法可以自適應地捕獲到目標的多層次表示特征,相比于人工設計的特征,通常有著更好的應用性能。以圖像去噪為例,文獻[16]提出了一種基于卷積神經網絡的圖像去噪方法并證明卷積神經網絡具有對馬爾科夫隨機場相近、甚至更高的表達能力。文獻[17]成功地將多層感知器應用于圖像去噪問題。文獻[18]利用稀疏去噪自編碼器來處理高斯噪聲去除問題,并取得了與K-SVD相近的結果。文獻[19]中,提出了一個可訓練的非線性映射傳遞模型,而且可以通過一個前饋神經網絡得以實現。
1 提出的基于卷積神經網絡的無線視頻廣播方案
時下,無線視頻廣播面臨3個主要問題就是可伸縮性、魯棒性和重建視頻質量。傳統的SoftCast無線視頻廣播系統雖然能夠避免懸崖效應的發生,但是由于其采用基于塊的編碼方式且信道噪聲直接疊加在傳輸信號上,所以其重構視頻中不可避免地含有編碼失真和傳輸失真,極大地降低了重構視頻的主客觀質量,因此如何去除編碼與傳輸失真是亟待解決的研究課題。針對圖像復原問題,稀疏表示理論利用先驗知識和重構圖像進行稀疏表示優化求解;深度網絡模型可以通過強大的特征提取能力對自然圖像的深層次特征進行學習,提取降質圖像中的有效信息。根據稀疏表示理論,本文擬利用視頻幀的局部稀疏性和非局部自相似性,通過基于組的稀疏表示模型減輕信重構視頻中的編碼失真。基于深度神經網絡特性,利用卷積神經網絡對視頻幀進行緊致而高效的表達,從而區分重構幀中的信道噪聲與有效視頻信息,以便于提升重構幀質量。實驗結果表明,本文提出的方案不僅具有良好的視頻廣播可伸縮性,還能提供視覺友好的主客觀重構質量。
1.1 編碼框架
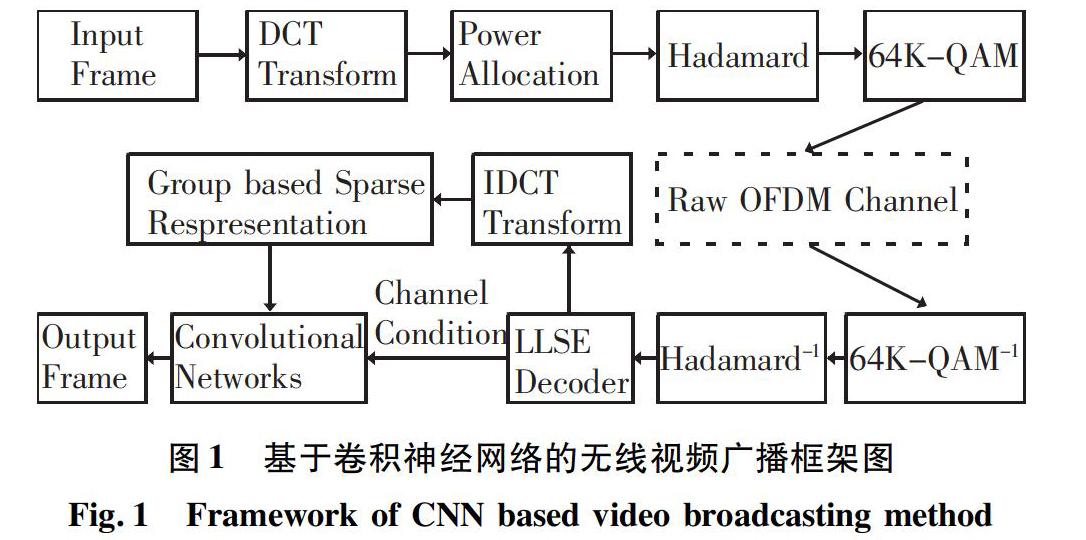
基于卷積神經網絡的無線視頻廣播框架如圖1所示。本文提出的基于深度神經網絡的無線視頻傳輸方案的編碼框架主要包含:視頻壓縮、視頻軟傳輸、基于圖像組的稀疏表示以及深度卷積網絡。
在編碼端,通過BDCT (Block based DCT) 去除視頻幀中的冗余,對視頻進行壓縮處理。利用對視頻的頻域系數的伸縮來最小化信號在信道傳輸中的總體失真。編碼后的信號直接經過稠密的64K-QAM星座圖發送給具有不同信道質量的多個用戶。傳統的數字視頻傳輸方案中,懸崖效應嚴重影響了各用戶的解碼體驗。在本文提出的方案中,通過軟傳輸的方式直接將編碼后的信號發送給客戶端,為用戶提供具有良好的視頻質量可伸縮性。在解碼端,其利用LLSE對接收到的信號進行解碼。基于圖像組的稀疏表示模型能夠同時利用視頻幀的局部稀疏性和非局部自相似性,本文利用基于圖像組的稀疏表示模型降低由BDCT編碼所造成的塊效應。由于深度神經網絡可以通過學習的方式提取不同程度的信道噪聲特征,在獲得具有平滑屬性的解碼視頻幀后,本文利用卷積神經網絡優化由軟傳輸中信道噪聲引起的失真。
1.2 基于塊的變換
由于視頻幀內通常具有較強的空域相關性,本文的方法利用這一性質,通過BDCT變換的方式對視頻幀內信息進行緊致表達。傳統的視頻編碼方法需要已知信道條件,根據信道條件選擇碼率并對頻域系數進行量化。這類的量化方案會迫使所有的用戶觀看質量一致的解碼視頻。
本文提出的方案將視頻幀劃分為圖像塊,再利用BDCT變換將視頻幀由空域轉換到頻域。通常來說,DCT系數具有能量集中的特性,也就是具有較高重要性的低頻系數集中的變換系數矩陣的左上角,而具有較低重要性的高頻系數集中在系數矩陣的右下角,數值通常是接近或等于零。由于高頻DCT系數對于視頻幀內信息的影響較輕微,所以采用丟棄DCT系數中的零值的方式對視頻數據進行壓縮。當帶寬受限時,本文的方案會根據DCT系數的分布特性,根據帶寬要求進一步丟棄當前最不重要的DCT系數。然而這樣的方式需要面臨的問題是編碼端不得不發送大量的元數據來標識丟棄的DCT系數所在的位置。
為了減少傳輸被丟棄頻域系數位置所需的元數據,本文的方法將不同塊的頻域系數按照頻率劃分為band,以band為單元對視頻進行壓縮。具體來說,可將不同塊的同一位置系數放入一個band。而后根據壓縮率及帶寬需求,以band為單位判別是否丟棄其中的DCT系數。不同圖像塊變換系數的高頻信息通常處于接近或者一致的區域,所以對band進行丟棄操作與對獨立的DCT系數進行丟棄操作具有接近的壓縮性能,卻大幅減少了元數據規模。
1.3 能量分配與傳輸
1.6 深度神經網絡去噪
傳統的軟傳輸方案直接將信號通過raw OFDM信道進行發送,可以取得良好的可伸縮性能,為不同用戶提供與其信道質量相一致的重構視頻。但是由于信道噪聲直接疊加在接收的噪聲中,會導致重構視頻中存在噪聲模糊效應。借助于深度神經網絡從原始數據中提取不同層級的抽象信息的能力。研究利用卷積神經網絡提取由不同信道噪聲所形成的特征,對解碼端重構的視頻進行復原。卷積神經網絡的結構如圖2所示。
由圖3中可以看出,所有基于H.264的傳統視頻廣播方案,無論信道編碼率如何,都會遭遇嚴重的懸崖效應。舉例來說,H.264+BPSK方案在CSNR為3~5 dB時表現良好,但是當CSNR低于3 dB時,會導致信道保護編碼失效,視頻無法解碼;而當CSNR高于10 dB時,由于信源編碼率的限制,導致CSNR上升時用戶的視頻質量無法進一步提升。
相反地,SoftCast與本文的方案都較好地避免了懸崖效應,為用戶提供了具有良好可伸縮性的平滑性能曲線。隨著CSNR的提高,用戶解碼的視頻質量也有相應的提升。但是由于本文利用GSR以及卷積神經網絡對重構幀中的失真進行了優化,本文方案的重構質量在全部CSNR范圍內都優于SoftCast。
2.3.2 視覺質量
本文方法的主觀質量對比如圖4所示。在相同CSNR條件下,可以清晰看到本文提出的方案具有更好的重建質量。SoftCast的重構幀中有較為明顯的塊效應和噪聲干擾,而本文方案的重構幀中幾乎沒有塊效應。實驗證明,基于GSR的方法表現出優秀的去塊效應性能。在相似PSNR條件下,本文方案的重構幀具有平滑的紋理以及清晰的邊界,在主觀視覺感受上更易于被接受。
本文方案與SoftCast在不同序列上的測試結果如圖5所示。由于GSR需要在視頻幀內尋找相似塊,使得當視頻內容運動劇烈時,會在一定程度上影響去塊效應結果,例如bus.cif中的測試結果。但是從圖5中可以看出,本文的方案具有良好的魯棒性,對于不同的視頻序列都取得了高于SoftCast的重構質量。
2.3.3 多播性能
文中使用3種方案服務一組客戶(3個具有不同信道質量的客戶),每個客戶的CSNR分別為5 dB、10 dB和20 dB。傳統的數字視頻廣播方案采用H.264+BPSK的組合。多播性能的效果對比即如圖6所示。由于3個客戶中信道最差的CSNR只有5 dB,所以傳統方案將必須采用BPSK進行調制,否則會導致CSNR為5 dB的客戶無法做到正確解碼。在SoftCast與本文方案的對比中,發送端可以同時適應多種信道條件。而在本文方案的測試結果中,雖然客戶1的重構質量略低于傳統方案,但是其余客戶均獲得了高于傳統方案的視頻質量。從圖6中可以看出,本文較傳統方案具有更好的可伸縮性,較SoftCast有著更好重構質量。
3 結束語
在本文中,提出了基于深度神經網絡的無線視頻傳輸方案。針對傳統視頻軟傳輸系統中存在的不足,利用深度神經網絡、基于圖像組的稀疏表示和軟傳輸技術設計了一種高效的無線視頻廣播方案。利用基于圖像組的稀疏表示對基于塊的編碼方案進行低質圖像復原處理。充分發揮卷積神經網絡對于數據深層特征的挖掘能力,對信道噪聲引起失真進行優化。通過軟傳輸的方式,本文方案在廣播場景下避免了懸崖效應的發生,并展示了出色的質量可伸縮性。實驗結果表明本文提出的基于深度神經網絡的無線視頻廣播方案在性能上明顯優于傳統數字視頻廣播系統。
參考文獻
[1]Digital Video Broadcasting (DVB)[EB/OL].[2009]. http://www.etsi.org/deliver /etsien/300700300799/300744/01.06.0160/en300744v010601p.pdf.
[2]SHACHAM N. Multipoint communication by hierarchically encoded data [C]//INFOCOM '92. Eleventh Annual Joint Conference of the IEEE Computer and Communications Societies.Florence, Italy: IEEE, 1992:2107-2114.
[3]MCCANNE S, JACOBSON V, VETTERLI M. Receiver-driven layered multicast[M]//Readings in multimedia computing and networking.San Francisco, CA, USA: Morgan Kaufmann Publishers Inc, 2001:593-606.
[4]WU Feng, LI Shipeng, ZHANG Yaqin. A framework for efficient progressive fine granularity scalable video coding[J]. IEEE Trans. Circuits and Systems for Video Technology,2001,11(3):332-344.
[5]SCHWARZ H, MARPE D, WIEGAND T. Overview of the scalable video coding extension of the H.264/AVC standard[J]. IEEE Transactions on Circuits and Systems for Video Technology, 2007,17(9):1103-1120.
[6]JAKUBCZAK S, KATABI D. A cross-layer design for scalable mobile video[C]//Proceedings of the 17th Annual International Conference on Mobile Computing and Networking, MOBICOM 2011. Las Vegas, Nevada, USA: ACM, 2011: 289-300.
[7]JAKUBCZAK S, KATABI D. SoftCast: One-size-fits-all wireless video[J].ACM SIGCOMM Computer Communication Review,2010,41(4):449-450.
[8]DONOHO D L. Compressed sensing[J]. IEEE Transactions on Information Theory, 2006, 52(4):1289-1306.
[9]SHEN Meiyin, KUO C C J. Review of postprocessing techniques for compression artifact removal[J]. Journal of ?Visual Communication and Image Representation, 1998, 9(1):2-14.
[10]YEH C H, KANG Liwei, CHIOU Yiwen, et al. Self-learning-based post-processing for image/video deblocking via sparse representation[J]. Journal of Visual Communication and Image Representation, 2014,25(5): 891-903.
[11]BREDIES K, HOLLER M. A totao variation based JPEG decompression model[J]. SIAM Journal on Imaging Science, 2012, 5(1):366-393.
