基于自注意力機制的軍事命名實體識別
2019-12-10 05:54:36張曉海操新文
指揮控制與仿真 2019年6期
張曉海,操新文,張 敏
(1.國防大學(xué)聯(lián)合作戰(zhàn)學(xué)院,河北 石家莊 050084;2.國防大學(xué)聯(lián)合勤務(wù)學(xué)院,北京 100858)
命名實體識別是從非結(jié)構(gòu)化文本中抽取實體信息的方法,一般包括人名、地名、機構(gòu)名、專有名詞等。它是信息抽取、機器翻譯等自然語言處理中眾多應(yīng)用領(lǐng)域的重要基礎(chǔ)。近年來,深度學(xué)習(xí)取得了飛速發(fā)展,命名實體識別研究也取得了很多成果。Hammerton等[1]采用了長短時記憶網(wǎng)絡(luò)(Long Short-Term Memory,LSTM)來替代人工設(shè)計特征的工作,使用神經(jīng)網(wǎng)絡(luò)自動提取特征;Mccallum等人[2]的工作是采用條件隨機場(Conditional Random Field,CRF)作為解碼層對命名實體進行識別,能夠更好地提升識別率;Chiu等人[3]在前人工作基礎(chǔ)上,采用雙向LSTM進行編碼,能提取到更豐富的上下文特征。
隨著大數(shù)據(jù)、人工智能的快速發(fā)展,作戰(zhàn)指揮模式正在由傳統(tǒng)的語言形式向數(shù)據(jù)化形式轉(zhuǎn)變。指揮信息的數(shù)據(jù)化作為指揮信息系統(tǒng)的重要組成部分,成為適應(yīng)未來信息化戰(zhàn)爭的重要研究方向。軍事命名實體識別作為一種智能化信息抽取方法,能夠更加快速、準確地從指揮文本中提取軍事命名實體等數(shù)據(jù)元素,是指揮信息數(shù)據(jù)化研究發(fā)展的關(guān)鍵基礎(chǔ)。本文在BLSTM-CRF模型的基礎(chǔ)上,引入自注意力來豐富文本的內(nèi)部特征,在軍事命名實體識別任務(wù)中取得了不錯的效果。
1 軍事文本特點
在信息化條件下,軍事文本作為一種重要的指揮信息載體,是指揮信息在指揮信息系統(tǒng)中流轉(zhuǎn)的主要表現(xiàn)形式。軍事命名實體主要包括機構(gòu)名、作戰(zhàn)編成、軍事地名、武器裝備名、軍職軍銜等幾大類實體。軍事文本相對于通用領(lǐng)域文本,雖然具有格式統(tǒng)一、語句規(guī)范等特點,但同樣存在其特殊性。其中最為明顯的特點是組合嵌套復(fù)雜,比如,“第XX集團軍XX合成旅XX營XX連XX排XX班”中,涉及6個實體的組合情況,較大的長度和可能的組合關(guān)系增加了實體識別的難度,這類部隊編制名稱、作戰(zhàn)編成等實體中存在的組合嵌套現(xiàn)象,在通用領(lǐng)域中較少出現(xiàn);同時,由于專業(yè)特點導(dǎo)致不同軍兵種的軍事文書表述不一,陸軍的作戰(zhàn)編成一般使用部隊編制實體的組合進行表述,如“XX營XX連(欠XX排)”等,而海軍和空軍則常使用“編制+武器裝備+艦名/數(shù)量”的形式進行表述,如“XX隊XX型驅(qū)逐(護衛(wèi))艦XX號”和“XX隊‘殲十’飛機XX架”,這就需要模型能同時識別不同組合類型的數(shù)據(jù)元素,對模型的泛化能力提出了更高要求。此外,有監(jiān)督學(xué)習(xí)需要大規(guī)模的標注語料作為支撐,以此學(xué)到更準確的特征分布,而人工標注成本高、耗時長,因此,在研究過程中更多通過自行標注的小規(guī)模樣本集進行機器學(xué)習(xí)模型的訓(xùn)練,這也從另一個方面限制了模型的識別效果。可見,軍事文本的大量命名實體識別任務(wù)存在著特殊性,這些特殊性為軍事命名實體識別造成了困難。
2 軍事命名實體識別框架
本文參照大部分命名實體識別方法,將軍事命名實體識別任務(wù)作為序列標注問題進行研究。圖1所示為基于自注意力機制的軍事命名實體識別模型。整體分為4個部分:1)利用卷積神經(jīng)網(wǎng)絡(luò)提取字符級特征;2)采用雙向長短期記憶網(wǎng)絡(luò)提取上下文特征;3)加入自注意力機制豐富文本內(nèi)部特征;4)使用條件隨機場線性層進行解碼。
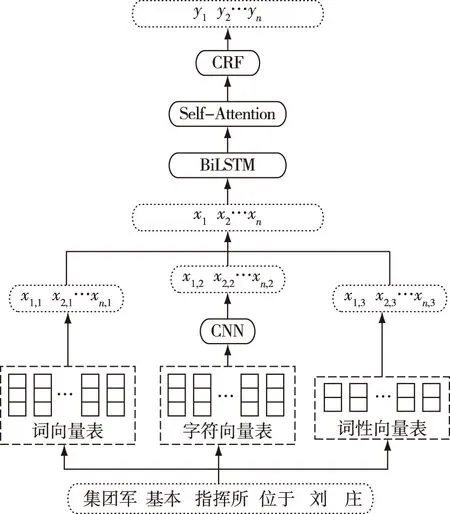
圖1 基于自注意力機制的軍事命名實體識別模型
2.1 標注方法和詞嵌入
標注方法選擇中[4],為了更好地表達實體邊界信息,本文采用“BIOES”策略進行手工標注。其中,B表示實體的開始,I表示實體內(nèi)部,E表示實體結(jié)尾,O表示非實體部分,S表示該詞可獨立成為一個實體。本文將位置、部隊、人員、物品、數(shù)量五大類細分為13個小類進行標注,具體方法如表1所示。
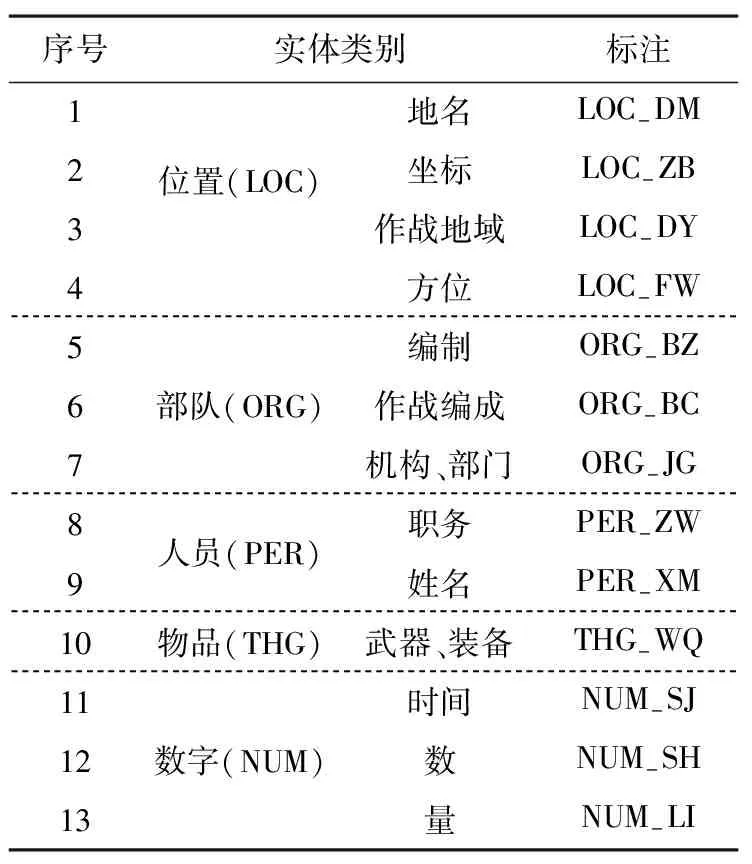
表1 實體類別及標注方法
注:非實體類用“O”標注。
為了更好地表達文本內(nèi)部特征,發(fā)揮注意力機制的作用,本文以字向量和詞向量進行拼接作為輸入。圖2為字符級向量模型。首先,將詞中的每個字進行字符向量轉(zhuǎn)換,由于詞的長度不同導(dǎo)致字符級矩陣大小不一,以語料中最長的詞為基準,在單詞的左右兩端分別補充占位符,從而得到大小一致的字符級矩陣。最終,將該矩陣送入卷積神經(jīng)網(wǎng)絡(luò)(Convolutional Neural Networks,CNN)通過反向傳播進行更新,經(jīng)過卷積層和池化層得到字符級的特征向量。

圖2 字符級CNN模型
中文分詞采用中科院的ICTCLAS工具進行處理,詞向量和字符向量則使用Google開源的Word2vec工具進行訓(xùn)練得到。在訓(xùn)練向量的過程中,本文選用Word2vec工具中的Skip-gram模型,詞一級窗口設(shè)置為3,字符級設(shè)置為5,向量維度均為200。在嵌入時,輸入向量由該字符向量與所在詞向量拼接得到,若出現(xiàn)向量表中不存在的字或詞,則賦予一個隨機向量。
2.2 BLSTM模型
長短期記憶模型(LSTM)[5]是一種改進的遞歸神經(jīng)網(wǎng)絡(luò)(RNN)模型[6],通過輸入、輸出和遺忘三個門來控制上下文信息的選擇,克服了傳統(tǒng)RNN的梯度消失和梯度爆炸的問題。公式(1)為LSTM網(wǎng)絡(luò)的形式化表示。


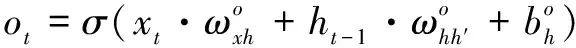
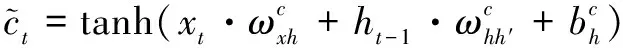
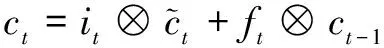
ht=ot?tanh(ct)
(1)
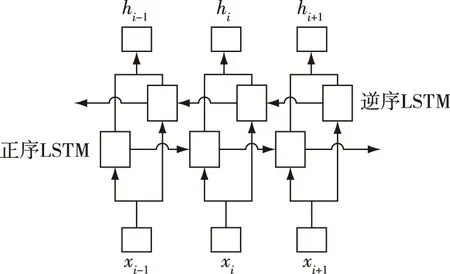
圖3 BLSTM模型結(jié)構(gòu)
2.3 Self-Attention層
注意力機制模仿人的認知方式,可將有限的信息處理能力進行選擇分配。直觀來看,就是通過一定的選擇機制將注意力集中在關(guān)鍵的信息上。通過融入注意力機制,可以更好地關(guān)注到對模型訓(xùn)練有效的關(guān)鍵信息上,并忽略同一時刻得到的非重要信息,從而有效地提升軍事命名實體識別的準確率。
自注意力(Self-Attention)機制[7]是在注意力機制基礎(chǔ)上的改進模型,主要包括查詢(Query)、鍵(Key)和值(Value)三個要素,其可理解為從Query到一系列Key-Value對的映射。如果{X1,X2,X3}為輸入序列,那么自注意力機制就是尋找序列內(nèi)部的聯(lián)系,即attention(X1,X2,X3)。
本文使用點乘注意力(Scaled Dot-product Attention)函數(shù),先通過Query和Key中每個詞向量的點乘運算來得到每兩個詞之間的相關(guān)性,再利用softmax進行歸一化處理,最后對Value進行加權(quán)求和。
(2)
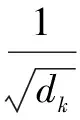
考慮到自建的軍事文本語料規(guī)模較小,使用單個注意力機制效果弱,本文使用多頭注意力(Multi-head Attention)機制從多角度、多層次進行文本特征提取,以使得文本特征的表達更加豐富[8-11]。
多頭注意力機制是將Q、K、V分別通過參數(shù)矩陣進行映射后,再進行點乘注意力的計算,將該過程重復(fù)h次后進行拼接,得到最終的特征信息,其計算公式如下:
headi=attention(Q′,K′,V′)
(3)
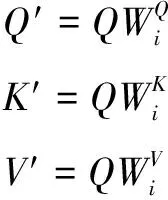
(4)
mulhead=concat(head1,…,headh)
(5)
2.4 CRF線性層
條件隨機場(CRF)可以在給定輸入觀測序列的前提下,輸出最大概率的預(yù)測序列,使用CRF線性層可以有效解決Self-Attention層輸出時的錯誤標注情況。
若矩陣P表示Self-Attention層輸出,其中n為序列長度,k表示不同的標簽個數(shù),那么,Pi,j即表示矩陣中第i行第j列的概率,對于給定序列X和預(yù)測標注序列Y,該模型可定義為
(6)
其中,A是轉(zhuǎn)移矩陣,若Aij表示由標簽i到j(luò)的概率,則y0,yn即為句子開始和結(jié)束的標記。而后通過一個softmax層得到標簽序列Y的概率
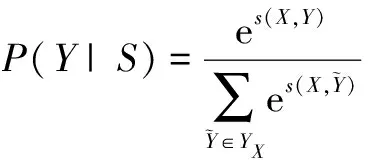
(7)
訓(xùn)練的最終目的是使正確標注的序列概率最大,因此,將概率最大的一組序列作為預(yù)測序列作為輸出
(8)
3 實驗結(jié)果與分析
3.1 樣本集
本文收集作戰(zhàn)文書、方案計劃、新浪網(wǎng)軍事新聞等共300余篇軍事文本,手工標注構(gòu)建了小規(guī)模樣本集,共計1121句、73523字;選擇其中900句作為訓(xùn)練集,其余221句作為測試集,進行開放測試。實驗通過召回率R、精確率P和F值三個指標進行評測,計算方法如下:
(9)
(10)
(11)
3.2 實驗設(shè)置
本文采用Tensorflow-1.7.0框架,使用Python實現(xiàn)模型的構(gòu)建和訓(xùn)練,模型參數(shù)的具體設(shè)置如表2所示。

表2 超參數(shù)初始化
3.3 實驗結(jié)果分析
在上述實驗樣本集和參數(shù)設(shè)置基礎(chǔ)上,設(shè)置4個模型進行對比實驗,表3所示為不同模型的對比實驗結(jié)果。
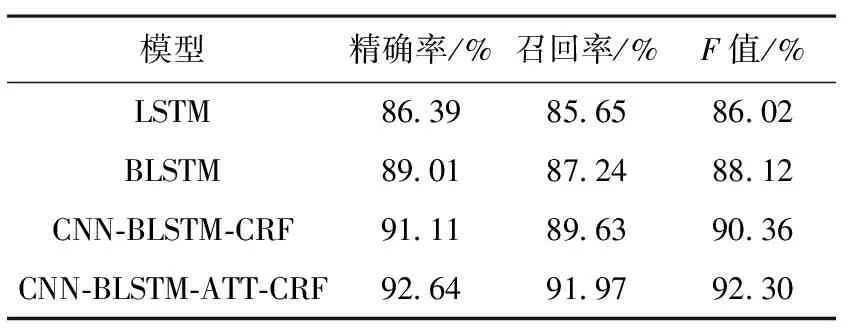
表3 各模型對比實驗結(jié)果
為了驗證BLSTM模型的有效性,首先進行了LSTM-CRF與BLSTM-CRF的對比實驗,結(jié)果表明,在軍事命名實體識別任務(wù)中,BLSTM模型的精確率、召回率和F值分別為89.01%、87.24%和88.12%,對比LSTM模型分別高出了2.62%、1.59%、2.1%。可見,BLSTM由于能夠更好地利用上下文信息,效果要優(yōu)于單向LSTM網(wǎng)絡(luò)。
為了展現(xiàn)使用CNN提取字符級特征的有效性,以及CRF線性層的效果,設(shè)置了CNN-BLSTM-CRF 模型,其精確率、召回率、F值,相比BLSTM模型分別提高了2.1%、2.39%和2.24%。這是由于CRF模塊能夠通過聯(lián)合概率的計算,對相鄰標簽的特征更加敏感,并且能夠減少不符合規(guī)則的標注錯誤。比如,部隊機構(gòu)中的編制實體往往因長度較大且組合嵌套,對實體類型的識別造成影響。增加CNN和CRF模塊后的模型能夠提高對該類實體的識別正確率。同時,為了使詞向量能夠包含更多的特征,本文在使用CNN提取字符級向量同時,還加入了詞性向量作為外部特征。
本文在模型4中加入了自注意力機制,即表3中的CNN-BLSTM-ATT-CRF模型,其精確率、召回率、F值分別達到了92.64%、91.97%和92.30%。相較實驗3中未包含Self-Attention層的模型分別提高了1.53%、2.34%和2.06%。可以看到,自注意力機制的引入提升了模型性能,表明了多頭注意力機制能在多個不同子空間捕獲上下文信息,從而獲取更豐富的文本內(nèi)部特征信息。
為了研究自注意力機制對長期依賴學(xué)習(xí)的貢獻,本文根據(jù)不同長度句子對識別率的影響進行了統(tǒng)計,進一步對未引入Self-Attention的模型3和引入Self-Attention的模型4進行對比分析。表4為CNN-BLSTM-CRF與CNN-BLSTM-ATT-CRF的對比結(jié)果。由表4可見,隨著句子長度的增加,模型3和模型4的F值均有不同程度的下滑,這說明了對長期依賴關(guān)系的學(xué)習(xí)始終是一個巨大的挑戰(zhàn)。

表4 模型3和模型4在不同句長區(qū)間的F值
通過實驗對比不難發(fā)現(xiàn),模型4在實驗中的表現(xiàn)更為出色,隨著句長增加,F值下降較為緩慢,這是由于自注意力機制能夠在句子內(nèi)部的任意標記之間建立聯(lián)系,從而減小了長句子對序列標注的影響。
4 結(jié)束語
本文針對軍事命名實體識別任務(wù)的特點,提出了一種基于自注意力機制的軍事命名實體識別方法,以LSTM為基線模型,分別對雙向LSTM模型、CRF線性層、CNN提取字符級特征和自注意力機制4種不同模型,在自建數(shù)據(jù)集上進行了對比實驗。實驗結(jié)果表明了引入自注意力機制的有效性,特別是學(xué)習(xí)長距離依賴關(guān)系的表現(xiàn)更好,最終系統(tǒng)識別軍事命名實體的精確率、召回率和F值分別達到92.64%、91.97%和92.30%。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學(xué)生數(shù)理化·七年級數(shù)學(xué)人教版(2020年10期)2020-11-26 08:24:50
數(shù)學(xué)物理學(xué)報(2020年2期)2020-06-02 11:29:24
制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
文苑(2018年21期)2018-11-09 01:23:06
光學(xué)精密工程(2016年6期)2016-11-07 09:07:19
小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38
中國衛(wèi)生(2015年9期)2015-11-10 03:11:12
中國衛(wèi)生(2014年3期)2014-11-12 13:18:12
