一種高效多標準視頻解碼器架構研究與設計
2019-12-10 03:09:18劉慧超王志君梁利平
湖南大學學報·自然科學版 2019年10期
劉慧超 王志君 梁利平


摘 ? 要:針對目前視頻解碼器實現方案存在的靈活度低、開發周期長、不能適應快速變化的算法升級等問題,提出一種面向多種視頻編解碼標準的通用視頻解碼器架構設計方案. 采用軟硬件協同設計方法,基于可編程同構多核處理器+協處理器的硬件架構,同構多核處理器采用指令級和任務級并行加速,協處理器采用硬件定制單元實現矢量加速,同時利用分布式片上便箋式存儲器(Scratchpad Memory, SPM)代替數據Cache實現高效的數據存儲系統,以應用廣泛的H.264視頻標準為驗證實例. 實驗結果表明,基于本文所提架構實現的H.264視頻解碼器高效可行,平均并行加速比為9.12,相比于傳統多核并行解碼算法提高了1.31倍.
關鍵詞:多標準;視頻解碼器;可編程;協處理器;便箋存儲器;H.264解碼器;架構設計
中圖分類號:TN919.3 ? ? ? ? ? ? ? ? ? ? ? ? ? ? 文獻標志碼:A
Research and Design of an Efficient
Multi-standard Video Decoder Architecture
LIU Huichao1,2,WANG Zhijun1,LIANG Liping1?覮
(1. Institute of Microelectronics,Chinese Academy of Sciences,Beijing 100029,China;
2. University of Chinese Academy of Sciences,Beijing 100049,China)
Abstract: Aiming at the problems such as low flexibility, long development cycle, and incapability of adapting to rapidly changing algorithms for current video decoder implementation solutions, a generic video decoder architecture design scheme for multiple video coding and decoding standards is proposed using software and hardware collaboration. The methodology of the design is based on a programmable homogeneous multi-core processor and coprocessor hardware architecture. The homogeneous multi-core processor uses instruction-level and task-level parallel acceleration. The coprocessor uses a hardware customization unit to achieve the vector acceleration, while it uses distributed on-chip scratchpad memory instead of data cache to achieve an efficient data storage system. Taking the H.264 video standard widely used as an example, the experimental results show that the H.264 video decoder based on the architecture proposed in this paper is highly efficient and feasible, with an average speed-up of 9.12, which is 1.31 times better than the traditional multi-core parallel decoding algorithm.
Key words: multi-standard;video decoder;programmability;coprocessor;scratchpad memory;H.264 decoder;architectural design
視覺是人們感知和認知外部世界的主要途徑. 實驗心理學家赤瑞特拉通過大量實驗證實人類獲取信息的80%以上都是來自視覺[1]. 信息化時代下,與視覺相關的應用廣泛地存在于通信、多媒體消費、安防監控、抗震救災等領域. 視頻應用的一項關鍵技術就是視頻編解碼,自20世紀80年代開始,先后出現了一系列國際化視頻編解碼標準,如H.26x標準、MPEG-x標準、H.264/AVC標準、AVS標準以及最新的HEVC標準等. 針對不同的視頻標準,不同應用環境下如何快速實現一個實時的視頻解碼器成為研究熱點. 目前比較常見的實現方案有:1)基于ASIC專用集成芯片實現[2-3]方案,已商業化的有富士通的MB91696AM、Sigma Designs的SMP8630和國產代表華為海思的Hi3535,雖性能穩定、功耗低,但研發周期長、靈活度低,當算法升級或變化時不能及時修正;2)基于DSP處理器實現[4-5]方案,以TI的DM64x系列為代表,還有Philips的PNX1500系列、ADI的Blackfin處理器,雖功能強大、性能可靠,但功耗較大、啟動速度慢;3)基于FPGA硬件實現[6-7]方案,通過自主設計或購買商業IP實現. 首先商業IP費用高、靈活度差且關鍵模塊為黑盒、調試風險大,核心技術受制于人. 自主研發IP相對靈活、可定制且代碼可見,但實現整個解碼系統任務復雜,且穩定性有待測試、驗證任務繁重;4)基于CPU+GPU的系統實現[8-9]方案,需要使用高級編程語言,門檻高、線程調度復雜、同步開銷大. 近年來,隨著集成電路技術的快速發展,開始出現基于多核處理器和SoC架構實現的視頻解碼器[10-13].
本文通過分析不同視頻標準間的共性,創新性地提出了一種基于同構多核處理器+協處理器的通用視頻解碼器架構,并以H.264視頻解碼器為實例進行驗證. 采用媒體運算指令并行加速和硬件協處理器矢量加速,實驗結果表明本文所提架構可行有效,便于軟硬件升級.
1 ? 多標準視頻編解碼算法分析
1.1 ? 視頻編解碼標準發展歷程
視頻編解碼標準自20世紀80年代起至今,不斷完善和發展. 自H.261標準開始,普遍采用包括基于運動補償的幀間預測、離散余弦變換(Discrete Cosine Transform,DCT)、量化、zig-zag掃描和熵編碼等編碼方法. 這些技術組合在一起形成了沿用至今的混合編碼框架. 圖1為混合編碼器核心結構框圖.
■
圖1 ? 混合編碼器框圖
Fig.1 ? The block diagram of hybrid encoder
混合編碼架構主要包括預測編碼和變換編碼兩大部分. 其中,變換編碼包括DCT和IDCT(Inverse Discrete Cosine Transform,反離散余弦變換)、Q(Quantization,量化)和IQ(Inverse Quantization,反量化). 輸入視頻后的減法器、運動估計(Motion Estimation,ME)和運動補償(Motion Compensation,MC)屬于預測編碼部分. 編碼視頻輸出前的熵編碼是一種變長編碼,可進一步提高混合編碼的壓縮效率. 重排序過程使得量化后的DCT非零系數集中,減少統計事件的個數,進一步增加熵編碼的壓縮率.
1.2 ? 不同標準編解碼算法對比分析
本文以最新的AVS2、H.264和HEVC 3種視頻標準為例,重點分析對應視頻解碼算法在結構上的共性和差異. 整體上,3種標準均采用混合解碼架構,如圖2所示,解碼器包括熵解碼、重排序、IQ、IDCT、幀間預測、幀內預測和環路濾波,但各模塊內部算法細節卻存在較大差異.
■
圖2 ? 混合解碼器框圖
Fig.2 ? The block diagram of hybrid decoder
1.2.1 ? 幀間預測
AVS2、H.264和HEVC標準都支持變塊大小的運動補償和四分之一精度像素插值,但插值使用的濾波器階數和濾波系數均不相同. 此外,運動矢量(Motion Vector,MV)雖均由相鄰塊MV預測而來,但具體的預測策略也各不相同.
首先,AVS2和HEVC的分像素插值算法類似. 亮度分量,HEVC對半像素位置采用8抽頭濾波器,1/4和3/4像素采用7抽頭濾波器;AVS2統一采用8抽頭濾波器,只是分像素位置不同,對應濾波系數不同. 對色度分量而言,兩者均采用4抽頭濾波器,且根據分像素位置采用不同的濾波系數. 具體如表1所示.
表1 ? 亮度插值濾波器系數比較
Tab.1 ? Comparison of luminance interpolation
filter coefficients
■
與AVS2和HEVC相比,H.264標準對亮度分量半像素點采用6抽頭濾波器插值得出,濾波系數為{1,-5,20,20,-5,1},1/4和3/4像素點則利用相鄰整像素和/或分像素的線性內插得出,計算量較低. 相應地,色度分量通過相鄰整像素的雙線性內插得出.
3種視頻標準雖然采用的分像素插值算法不同,但都可以歸結為像素點積和均值計算兩種算子,有利于采用高性能乘累加指令編程實現.
關于運動矢量預測算法,由于策略不同,所以這部分需針對特定標準采用軟件或硬件方式獨立
實現.
1.2.2 ? 幀內預測
幀內預測充分利用了幀內像素的空間相關性,通過鄰近已編碼或解碼塊的重建值進行預測. H.264幀內預測算法,4×4和16×16亮度塊分別擁有9種、4種預測模式,色度分量以8×8為預測單元,擁有4種預測模式. AVS2和HEVC與H.264類似,但比
H.264預測方向更精細更靈活,分別為亮度預測塊定義了33種和35種不同的預測模式,色度預測塊均定義了5種預測模式. 但從算法結構來看,雖然3種視頻標準預測模式總數不同,但可分為以下3類:Planar模式、DC模式和角度模式.
1.2.3 ? 環路濾波
視頻壓縮編碼是一種有損壓縮,編碼中的量化和計算誤差會給重建后的圖像造成不可恢復的失真. 因此自H.263和MPEG-2標準開始,在視頻編解碼器中均加入了環路濾波處理,以改善圖像質量. 然而,不同視頻標準中的環路濾波算法又存在些許差別. 以H.264為例,采用自適應去塊效應濾波器,對所有的4×4塊邊界和樣點值進行邊界強度判斷和自適應濾波處理,整個過程幾乎涉及重建圖像所有像素點,計算復雜度高.
AVS2和HEVC均相對于H.264環路濾波技術做了精簡,主要體現在以下3個方面:
1)亮度和色度分量均以8×8塊為單位進行邊界濾波,相比于H.264,濾波邊界數大大減少;
2)邊界濾波時,每條邊界兩邊最多各修正3個像素點,使得8×8塊之間相互獨立,可以并行處理,而H.264只能串行操作;
3)可以先對整幅圖像進行垂直邊界濾波,然后進行水平邊界濾波,而H.264必須以宏塊為單位交替執行垂直邊界濾波和水平邊界濾波.
此外,在去塊效應濾波器后,AVS2和HEVC又增加了不同的補償技術,AVS2引入了自適應樣點偏移和樣本補償濾波,而HEVC則引入了樣點自適應補償技術,用于抑制DCT變換后高頻交流系數量化失真造成的振鈴效應.
1.2.4 ? 熵解碼
預測+變換編碼消除信源的時間和空間冗余,經量化處理后得到預測殘差變換系數,連同其他控制信息和標識信息等句法元素,利用熵編碼方法進一步壓縮,消除碼字之間的冗余. H.264、AVS2
和HEVC分別采用了不同的熵編碼策略,如表2
所示.
表2 ? 不同視頻標準熵編碼算法對比
Tab.2 ? Comparison of entropy coding algorithms
in different video standards
■
熵編解碼算法基于信息熵原理實現數據的無損編解碼,算法按照信息比特完成運算,計算粒度最小,分支復雜. 通用處理器運算粒度為字或字節,基于通用處理器實現的熵編解碼算法無論速度和功耗均不具有優勢. 以熵解碼過程為例,目前的研究主要分兩種途徑實現:其一,實現完整的句法解析過
程[14];其二,僅實現單純的熵解碼單元,通過調用解碼單元實現句法解析[15]. 采用第2種途徑時,單一句法元素的解析由硬件完成,而碼流結構的多分支控制由主控方實現,影響主控方的執行性能. 相反,采用第1種途徑時,碼流結構控制和句法元素解析均由硬件實現,緩解主控方壓力,同時不會帶來巨大的硬件開銷.
總結不同視頻編解碼算法特點,有以下共性:1)統一的混合編解碼架構,功能模塊和輸入輸出在算法級是一致的,這為采用統一的視頻解碼體系架構提供了基礎. 2)不同功能模塊內部細節差異較大,但計算過程具有很大相似性,如分像素插值、幀內預測和環路濾波,可由高性能乘累加單元編程實現. 以上特點為本文解碼器架構提供了基礎.
2 ? 多標準視頻解碼器體系架構
2.1 ? 流水線的視頻解碼器架構
2.1.1 ? 流水線任務劃分
如前文所述,不同視頻標準對解碼系統的可編程性提出了很高的要求. 本文結合視頻解碼器特點,提出一種多標準通用的多核流水解碼體系架構. 系統由兩部分組成:專用協處理器ECore和高性能同構4核處理器Core0-Core3. 采用軟硬件協同的設計方法,由專用協處理器實現熵解碼等計算粒度小、計算不規整、分支復雜的解析過程,高性能同構4核處理器實現幀間預測、幀內預測和環路濾波等計算密集、計算規整的解碼過程. 如圖3所示. 混合解碼結構中,變換解碼完成對殘差系數的反量化和反變換,得到像素殘差;預測解碼通過幀間或幀內預測算法計算得到像素預測值,兩個過程相互獨立. 預測值和殘差疊加得到像素重建值. 考慮到當前塊進行幀內預測時需要參考已解碼相鄰塊像素,為避免流水線出現反饋環路,將幀內預測與IQ、IDCT和重建映射到流水線的同一級.
■
圖3 ? 多核視頻解碼器系統架構
Fig.3 ? Multi-core video decoder system architecture
2.1.2 ? 存儲結構
對于多媒體流數據的處理面臨兩個關鍵問題:其一,流數據吞吐量大;其二,流數據時間局部性差,每個元素的生命周期短. 傳統多核解碼器采用共享存儲器和片上私有Cache的兩級存儲結構,共享存儲器結構使得多核之間訪存沖突嚴重,高速緩存Cache利用局部性原理實現快速訪存,恰恰與流數據局部性差的特點相違背,導致Cache miss嚴重,不僅影響整個系統的吞吐率,而且會造成大量的功耗損失. 本文采用分布式片上便箋存儲器作為數據緩存單元,如圖4所示,多核處理器均配置一塊支持多核并行訪問不同存儲體的片上SPM存儲器,開辟乒乓結構實現核與核之間數據通信,有效解決傳統多核解碼器對共享存儲器的訪問沖突,降低Cache miss造成的性能損失,提高多核解碼效率.
■
圖4 ? 流水線視頻解碼器存儲架構
Fig.4 ? Storage architecture of pipelined video decoder
此外,視頻解碼器中,幀間預測和環路濾波兩部分需要頻繁的與外部存儲器進行數據通信. 其中,幀間預測過程需要讀取片外參考幀像素進行插值運算,環路濾波完成后需要將濾波結果寫回到位于片外存儲器的解碼幀緩存空間. 本文采用基于宏塊組(此處的宏塊定義是針對H.264標準的,與HEVC和AVS2中的編碼單元CU是一個概念)濾波結果寫回與參考幀預取,并由DMA(Direct Memory Access,DMA)方式實現快速訪存.
1)基于宏塊組濾波結果寫回:文中采用基于宏塊組的功能并行解碼算法,宏塊組的大小根據解碼視頻分辨率進行選取. 選取依據是:根據對應分辨率下視頻幀每行包含的宏塊數,選擇其對應的一個因子數作為宏塊組的大小. 當前宏塊組解碼完成后,可以按照二維結構順序寫回幀緩存空間,而不用考慮跨行存儲問題,整個宏塊組只需啟動3次DMA搬運過程(亮度和色度分開存儲),相比于以宏塊為單位寫回,可以大大降低DMA調用次數. 同時,基于宏塊組的存儲策略,每次只需將當前解碼完成的宏塊組最右邊界拷貝到下一個待解碼宏塊組的左邊界上,相比于傳統的基于宏塊級并行解碼,可以有效避免宏塊組內相鄰宏塊邊界數據的拷貝過程,避免了基于宏塊行或更高級別并行對存儲器資源占用率高的劣勢.
2)參考幀預取:采用窗口式并行讀取方式,降低訪問片外存儲器的頻次. 根據宏塊不同預測模式,找出宏塊內所有分割塊參考數據在參考幀中水平和垂直方向的最大最小坐標位置,確定宏塊的參考數據范圍,如圖5所示.
■
圖5 ? 基于窗口式的參考像素預取
Fig.5 ? Window-based reference pixel prefetch
以H.264標準為例,亮度分量讀取范圍為(min_xPos-2,min_yPos-2)~(max_xPos+3,max_yPos +3),色度分量讀取范圍為(min_x/2,min_y/2)~(max_x/2+1,max_y/2+1). 同時,采用乒乓雙緩存單元,當前宏塊幀間預測與下一個宏塊參考數據預取并行執行,最大限度降低幀間預測模塊的數據等待.
2.1.3 ? 流水線同步與負載平衡
為保證同構多核處理器與協處理器之間相互協調工作,進一步減少同步等待造成的周期損耗,設計實現環形隊列和乒乓緩存單元. 如圖6所示,首先在Core0片上SPM空間開辟一個長度為32個單元的環形隊列loopbuf0,用于接收來自協處理器解碼后的中間數據,Core0將接收到的數據“按需分配”打包發送到3個從核各自的環形隊列loopbuf1、loopbuf2和loopbuf3上. 當loopbuf0滿時,Core0不再響應協處理器的讀請求,此時協處理器需等待;同理,當loopbuf1、loopbuf2或loopbuf3任意一個為滿時,Core0需等待,只是,由于Core3處于流水線末端,所以Core0只需判斷loopbuf3的狀態是否為滿即可.
■
圖6 ? 核間同步環形隊列
Fig.6 ? Loop queue for inter-core synchronization
除環形隊列外,負責解碼的3個從核之間利用上一節所述的兵乓緩存單元進行數據通信. 為實現同一時刻相鄰2個核不同時訪問一個緩存單元,文中每個核均維護一個選擇信號bufsel,值為0對應a單元,為1對應b單元,bufsel的值也會第一時間更新到對應核的郵箱中. 當某個核開始對下一個緩存單元解碼前,只需判斷當前選擇信號與相鄰核選擇信號是否一致,若不一致則繼續,否則等待.
基于以上兩種同步機制,可以很好地實現核與核之間的協同工作.
2.2 ? 協處理器設計
本文對熵解碼、反掃描和運動矢量與濾波強度計算采用硬件定制的協處理器進行加速,如圖7所示.
■
圖7 ? 協處理器結構圖
Fig.7 ? Coprocessor structure diagram
協處理器除包括熵解碼、反掃描等功能單元外,還有通信控制單元、碼流讀寫控制單元和碼流緩存單元和解碼結果緩存單元,實現與核0的數據交互. 采用FPGA實現的協處理器具有3點優勢:1)可以快速地實現細粒度運算;2)相比于通用處理器的分支預測,可以高效地實現分支復雜的運算過程;3)對于不同視頻標準中熵編解碼過程的差異,可以很容易實現協處理器在線升級. 關于這部分的具體實現不在本文所述范圍內. 本文中,協處理器在FPGA上實現,工作頻率為50 MHz,可以滿足H.264標準1080P解碼要求.
2.3 ? 多核調度
本文采用一種簡單易實現的調度方法. 首先,核0負責解碼器的初始化,然后協處理器開始工作,此時核1~核3均處于休眠狀態. 然后,利用前文所述的環形隊列結構,當核0用于接收協處理器解碼數據的環形隊列非空時,通過多核中斷順序啟動核1~核3. 之后,核間按照前文所述的流水線同步機制開始協同解碼,不再需要核0干預.
3 ? 實例驗證
本文以應用廣泛的H.264視頻解碼器為例,對提出的通用視頻解碼器架構進行了實例驗證. 驗證平臺采用中國科學院微電子研究所完全自主研發設計的IME-Diamond同構多核處理器[16-17]和Altera公司的型號為Cyclone IV EP4CE115F23I7的FPGA芯片. IMD-Diamond是一款高性能32位嵌入式定點處理器,具有CPU和DSP功能融合性架構. 其中CPU支持嵌入式操作系統和各種通信協議處理的控制,DSP支持無線寬帶通信和多媒體等高計算密集度的數字信號處理. 采用VLIW靜態多發射硬件架構,支持最大8條指令并行執行. 單核片上SPM為128 kB;指令高速緩存I-Cache大小為16 kB;數據高速緩存D-Cache大小為16 kB. 擁有強大的DMA功能,支持多核SPM之間以及與外部Memory之間數據的全交叉通信,可實現視頻數據的1D-2D、2D-1D和2D-2D多模態傳輸等.
本文采用IME-Diamond處理器作為視頻解碼器架構中的通用同構處理器Core0~Core3,基于FPGA設計實現可升級的協處理器.
IME-Diamond處理器提供了豐富的高性能多媒體運算指令,表3列舉了其中的一小部分.
采用IME-Diamond處理器提供的多媒體運算指令,可以加速實現諸如分像素插值、IDCT和邊界濾波等計算密集的運算過程. 此處以4 × 4塊半像素插值為例,簡要說明其在IMD-Diamond處理器上的實現過程.
表3 ? IME-Diamond指令簡集
Tab.3 ? Instructions list for IME-Diamond
■
H.264標準對亮度分量半像素點采用6抽頭濾波器濾波得出,濾波系數為{1,-5,20,20,-5,1},本文將其擴展為8系數濾波器,擴展后的濾波系數為{0,1,-5,20,20,-5,1,0},利用IME-Diamond提供的vpixdprb和vpixdprba兩條指令實現8像素點積運算. 如圖8所示.
■
圖8 ? 4×4塊半像素插值實現
Fig.8 ? Half-pixel interpolation for 4×4 block
圖8中,白色方塊代表整像素參考樣點,灰色方塊為待插值的半像素點. 8抽頭濾波計算分為前后兩部分,前四點乘累加運算由vpixdprb指令完成,后四點乘累加運算及與前四點結果的累加由vpixdprba指令完成. 由于不同行插值過程相互獨立,且IME-Diamond處理器支持最大8條指令并行,所以每次可以并行計算4 × 4塊的四行像素插值運算,若不考慮數據準備過程,兩個時鐘周期可以完成4個半像素點的插值運算. 同理,IDCT和邊界濾波等運算也可以按照上述類似的方法實現,不再贅述.
4 ? 性能仿真及比較
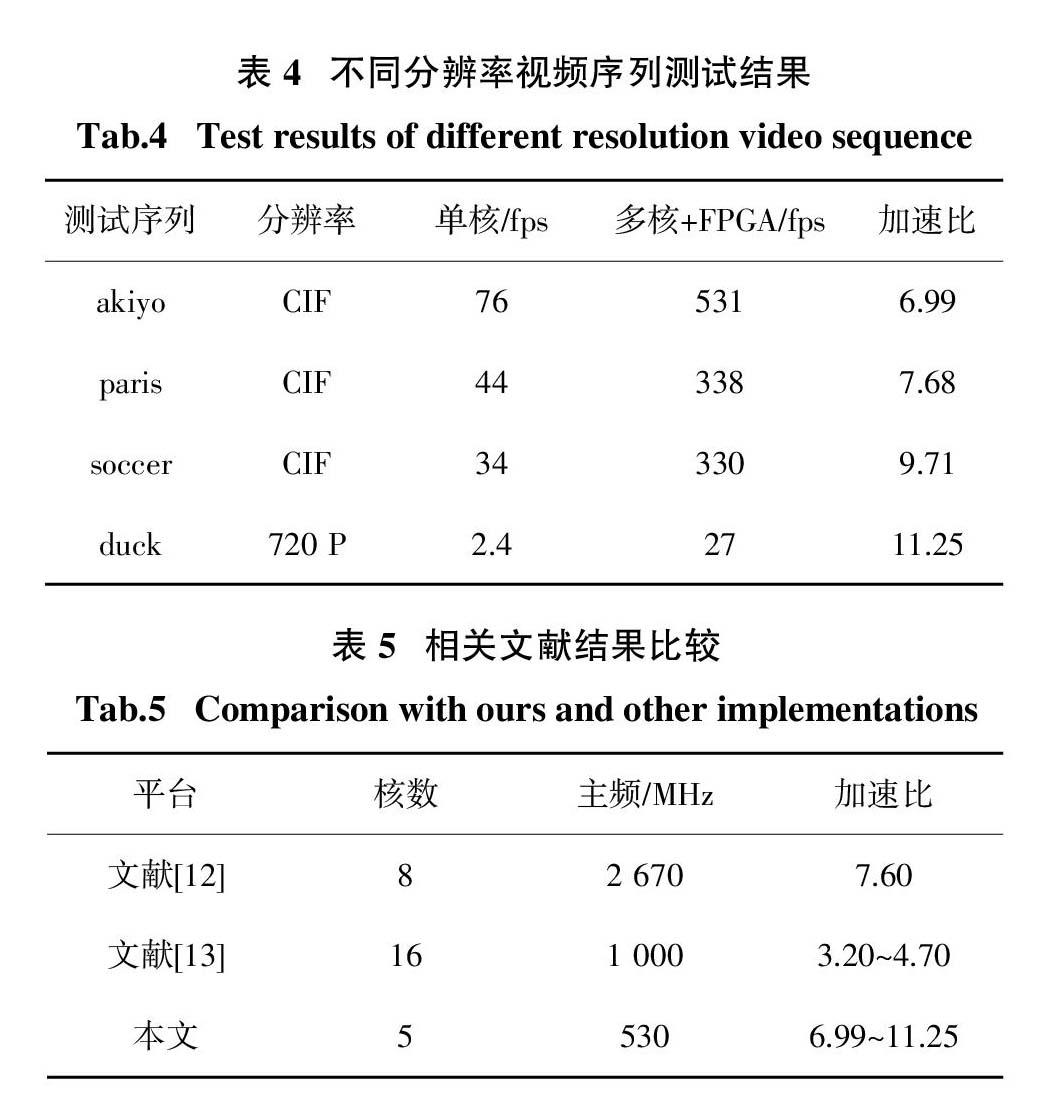
本文以IME-Diamond處理器為實驗平臺,以H.264傳統單核軟解碼器為對照,以H.264官方提供的標準測試序列akiyo、paris、soccer和duck對基于本文提出的通用多標準視頻解碼器體系架構下實現的H.264多核解碼器進行了驗證測試. 測試結果如表4所示.
表4 ? 不同分辨率視頻序列測試結果
Tab.4 ? Test results of different resolution video sequence
■
從表4中數據可以看出,相比于單核解碼器,本文提出的解碼方案切實有效,最大加速比可達11.25. 表5為相關文獻結果對比.
表5 ? 相關文獻結果比較
Tab.5 ? Comparison with ours and other implementations
■
文獻[13]并行算法在配置為16核時的加速比為3.20~4.70,中值為3.95;與之相比,雖然本文使用的處理器核數目比較少,但卻取得了高的加速比,中值為9.12,平均提高了1.31倍. 文獻[12] 8核并行算法雖然取得了7.60的加速比,但主頻卻是本文的5.03倍,盡管如此,相比之下,本文加速比平均提高了20%. 文獻[12-13]均從軟件層次出發,通過設計多線程算法實現線程級并行解碼,相比之下,本文根據不同解碼模塊算法復雜度,將分支情況復雜、計算粒度低的熵解碼等過程采用定制硬件協處理器進行加速,實現了更高的加速比.
此外,對于商業化代表海思Hi35系列視頻解碼SoC芯片,其解碼核心為硬件固化的HiVXE2.0處理引擎,雖性能獨具優勢,但仍舊屬于ASIC范疇,研發周期長,靈活度差. 相比之下,本文提出的基于軟硬件協同的視頻解碼器架構,無論從軟件算法還是協處理器單元結構均支持在線升級,可編程性強,為未來新標準視頻解碼器設計提供了新的方向.
功耗方面,由于不同實現方法所采用的硬件平臺和軟件環境不同,暫時無法給出準確的功耗對比結果. 本文從自身出發,對系統架構修改前后的功耗情況做了簡單的評估,修改前系統功耗約1.7 W,其中內核功耗約1.1 W;修改后系統功耗約5.3 W,內核功耗約3.6 W. 總體上,相比于修改前的單核系統,修改后系統由4個處理器核與一個FPGA協處理器同時運行,導致系統功耗增加了兩倍;但是,由于FPGA分擔了部分負載,主系統單個內核平均功耗有所降低,約為0.9 W.
5 ? 結 ? 論
本文提出了一種通用的支持多標準的視頻解碼器體系架構,并以H.264視頻解碼器為實例進行了驗證. 通過FPGA定制協處理器加速單元,實現熵解碼、運動矢量和濾波強度計算;通過多核處理器并行實現計算密集的運動補償、IDCT和環路濾波模塊;通過宏塊組的存儲結構,有效減少了DMA啟動次數和相鄰宏塊邊界數據的拷貝;利用分布式片上便箋存儲器實現快速的核間數據通信. 實驗結果表明,本文提出的并行解碼方案平均并行加速比為9.12,比傳統算法提高了1.31倍. 同時,與現有視頻解碼器架構相比,具有很好的靈活性和可編程性,更能適應不斷升級優化的視頻解碼算法.
參考文獻
[1] ? TREICHLER D G. Are you missing the boat in training aids[J]. Filem and Audio-Visual Communication,1967,48(1):28—30.
[2] ? 沈沙. H.264/HEVC視頻解碼的VLSI結構及實現研究[D]. 上海:復旦大學微電子學院,2013:7—9.
SHEN S. Research on VLSI architecture and implementation of
H.264/HEVC video decoding[D]. Shanghai: School of Microelectronics,Fudan University,2013:7—9. (In Chinese)
[3] ? 郝秀麗. 基于GF14 nm工藝的H.264視頻解碼器綜合與物理實現[D]. 哈爾濱:哈爾濱理工大學應用科學學院,2016:7—10.
HAO X L. The physical implement and synthesis of H.264 video decoder based on GF14 nm technology[D]. Harbin: College of Applied Sciences,Harbin University of Science and Technology,2016:7—10. (In Chinese)
[4] ? 王珊珊. 基于TI C6678多核處理器的HEVC視頻解碼軟件設計[D]. 杭州:浙江工業大學信息工程學院,2014:16—22.
WANG S S. Design of HEVC video decoder based on TI C6678 multi-core processor[D]. Hangzhou: College of Information Engineering,Zhejiang University of Technology,2014:16—22. (In Chinese)
[5] ? 胡宏華,諶德榮. 基于DSP的H.264解碼器優化設計[J]. 中北大學學報(自然科學版),2011,32(6):763—767.
HU H H,CHEN D R. Optimal design of DSP-based H.264 decoder[J]. Journal of North University of China(Natural Science Edition),2011,32(6):763—767. (In Chinese)
[6] ? 馬雨然. 基于FPGA的H.264解碼器設計[D]. 成都:中國科學院光電技術研究院,2017:1—4.
MA Y R. Design of H.264 decoder based on FPGA[D]. Chengdu: Institute of Optics and Electronics,Chinese Academy of Sciences,2017:1—4. (In Chinese)
[7] ? 劉寧寧,田澤,許宏杰. H.264/AVC解碼芯片驗證系統及驗證策略[J]. 計算機技術與發展,2014(5):191—194.
LIU N N,TIAN Z,XU H J. Verification system and strategy of
H.264/AVC decoder[J]. Computer Technology and Development,2014(5):191—194. (In Chinese)
[8] ? 潘俊夫. H.264視頻解碼器宏塊級并行實現與調度優化策略[D]. 武漢:華中科技大學計算機科學與技術學院,2016:28—38.
PAN J F. Macroblock level parallel implementation and its scheduling optimization strategy for H.264 decoders[D]. Wuhan: School of Computer Science & Technology,Huazhong University of Science & Technology,2016:28—38. (In Chinese)
[9] ? 楊杭軍. 基于多核處理器的視頻編解碼并行算法研究[D]. 南京:南京大學電子科學與工程學院,2013:3—4.
YANG H J. Video codec parallel algorithm based on multi-core processors[D]. Nanjing: School of Electronic Science and Engineering,Nanjing University,2013:3—4. (In Chinese)
[10] ?潘競. SOC結構的MPEG-4編解碼器設計[D]. 上海:上海交通大學軟件學院,2007:13—16.
PAN J. The MPEG-4 codec design base on SoC[D]. Shanghai: School of Software,Shanghai Jiao Tong University,2007:13—16. (In Chinese)
[11] ?VU D,KUANG J L,BHUYAN L. An adaptive dynamic scheduling scheme for H.264/AVC decoding on multicore architecture[C]//IEEE International Conference on Multimedia and Expo. Melbourne,VLC,Australia: IEEE Computer Society,2012:491—496.
[12] ?RICHTER H,STABERNACK B. Architectural decomposition of video decoders for many core architectures[C]//Design and Architectures for Signal and Image Processing. Karlsruhe,Germany: IEEE,2012:1—8.
[13] ?BAAKLINI E,SBEITY H,NIAR S. H.264 macroblock line level parallel video decoding on embedded multicore processors[C]//Euromicro Conference on Digital System Design. Izmir,Turkey: IEEE Computer Society,2012:902—906.
[14] ?林子明. 高幀率實時HEVC熵編解碼關鍵技術研究[D]. 北京:中國科學院大學,2015:78—80.
LIN Z M. Key Research on entropy coding/decoding of HEVC in high frame rate real-time application[D]. Beijing: The University of Chinese Academy of Sciences,2015:78—80. (In Chinese)
[15] ?俞政. 可擴展64核處理器關鍵技術研究——單核、加速器架構及H.264解碼器實現[D]. 上海:復旦大學微電子學院,2014:51—52.
YU Z. Research on key technologies of scalable 64-core processor-single core,accelerator-rich architecture and realization of H.264 decoder[D]. Shanghai: School of Microelectronics,Fudan University,2014:51—52. (In Chinese)
[16] ?王志君,梁利平,吳凱,等.一種面向多媒體和通信應用的處理器指令集及架構實現[J].湖南大學學報(自然科學版),2014,41(10):108—114.
WANG Z J,LIANG L P,WU K,et al. Architecture and implementation of an application specific instruction set for multimedia and communication[J]. Journal of Hunan University(Natural Sciences),2014,41(10):108—114. (In Chinese)
[17] ?王志君,梁利平,洪欽智,等. 一種DSP和通用CPU一體化的處理器架構及其4核實現[J].微電子學與計算機,2014,31(10):32—38.
WANG Z J,LIANG L P,HONG Q Z,et al. The architecture of an unified DSP plus general-purpose CPU and the implementation of a 4-core homogeneous processor[J]. Microelectronics & Computer,2014,31(10):32—38. (In Chinese)
