用于交通標志檢測的窗口大小聚類殘差SSD模型
2019-12-10 03:09:18宋青松王興莉張超陳禹宋煥生KHATTAKAsadJan
湖南大學學報·自然科學版 2019年10期
關鍵詞:深度學習
宋青松 王興莉 張超 陳禹 宋煥生 KHATTAK Asad Jan

摘 ? 要:SSD通常被認為適合于求解小目標圖像檢測問題,但在特征表征和檢測效率兩方面還存在改進空間.提出一種聚類殘差SSD模型,一方面將原始SSD模型中的VGG16基礎網絡替換為更深的ResNet50殘差網絡,以改善特征表征能力.另一方面采用K-均值聚類算法取代盲目搜索機制,確定SSD中默認窗口的大小,以改善檢測效率.針對德國交通標志檢測數據集,模型獲得了97.1% mAP和每幅圖像0.07 s的檢測速度.針對中國交通標志數據集,模型獲得89.7% mAP和每幅圖像0.08 s的檢測速度.與原始SSD模型比較,本文所提模型的檢測性能得到改善.
關鍵詞:交通標志檢測;深度學習;單拍多盒探測器(SSD);K-均值;聚類
中圖分類號:TP391.4 ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ?文獻標志碼:A
A Residual SSD Model Based on Window
Size Clustering for Traffic Sign Detection
SONG Qingsong,WANG Xingli,ZHANG Chao?覮,
CHEN Yu,SONG Huansheng,KHATTAK Asad Jan
(School of Information Engineering,Changan University,Xian ?710064,China)
Abstract:Single Shot MultiBox Detector (SSD) is generally considered to be suitable for solving small target detection in images. However,its performance on feature extraction and detection efficiency is still required to be improved. A clustering residual SSD model is proposed in this paper. On one hand,in order to improve the feature extraction quality,the basic network VGG16 which consists of the original SSD model is replaced with a deeper residual network ResNet50. On the other hand, in order to improve the detection efficiency, K-means algorithm other than the blind search mechanism used in the original SSD model is exploited to find and determine the assignments of the sizes of default windows. For German traffic sign detection dataset, it obtains 97.1% mAP in detection accuracy and 0.07 s per image in detection efficiency. For Chinese traffic sign dataset, it obtains 89.7% mAP in detection accuracy and 0.08 s per image in detection efficiency. Compared with the original SSD model, the proposed model obtains the improved detection performance.
Key words:traffic sign detection;deep learning;Single Shot MultiBox Detector (SSD);K-mean;clustering
交通標志的檢測與分類是智能駕駛領域重要研究課題之一.傳統的方法多為基于候選區域和分類器的兩段式分類檢測方法.首先,使用滑動窗口選定圖像的某一區域作為候選區域;針對選定的候選區域提取諸如HOG(Histogram of Orientated Gradient,HOG)、Haar、SIFT(Scale-invariant feature transform,SIFT)、LBP(Local Binary Pattern,LBP)等[1-4] 特征. 然后,使用隨機森林(Random Forest,RF)、支持向量機(Support Vector Machine,SVM)、Adaboost等[5-9]分類算法對提取的特征進行分類,得出該候選區域的檢測結果. 文獻[9]以圖像中交通標志的顏色、形狀、空間位置等作為特征,使用Adaboost算法訓練決策樹模型,以此生成候選區域;之后使用SVM給出候選區域的類別,這是一種典型的兩段式分類檢測方法.該類方法在候選區域的選取上往往存在盲目性,同一圖像會生成數以千計的候選區域,難以滿足實時性要求;同時人工提取的特征通常難以很好地表征圖像,影響檢測準確率.
文獻[10]提出區域卷積神經網絡(Region CNN,R-CNN),使用特征表征能力強的卷積神經網絡(Convolutional Neural Networks,CNN)[11]提取候選區域的特征,檢測準確率得到了很大的提升. 文獻[12]首先使用全卷積網絡(Fully Convolutional Network,FCN)[13]分割出交通標志候選區域,然后使用CNN對候選區域進行分類.該類方法本質上仍然是兩段式的分類檢測方法,在檢測實時性方面改善有限.
YOLO算法[14]將圖像網格化,生成一組默認窗口,進而在該組默認窗口中心區域檢測目標,由于不依賴候選區域,YOLO算法在檢測實時性方面取得了巨大的突破;但分類層使用的特征尺度單一,在檢測準確率方面沒有獲得顯著提升.圖像金字
塔[9,15]和多尺度特征往往有利于模型性能的提升.文獻[15]使用圖像金字塔進行交通標志檢測并取得一定效果. SPP-Net[16]、FPN[17]等算法將多尺度特征加入到分類決策層,有效提升了檢測準確率.文獻[18]提出的SSD在一定程度上綜合了YOLO算法的默認窗口生成機制和FPN使用的多尺度特征融合思想,在檢測速度和準確率方面都取得了良好的提升,但對于交通標志小目標的檢測問題,在特征表征和檢測效率兩方面還存在改進空間.
針對交通標志小目標檢測問題,本文提出一種聚類殘差SSD模型,一方面將原始SSD模型中的基礎網絡替換為ResNet50[19],提升特征表征能力;另一方面,引入K-均值聚類算法取代默認窗口的隨機生成機制,改善檢測效率.實驗結果表明,所提模型能改善交通標志小目標的檢測性能.
1 ? 模型結構
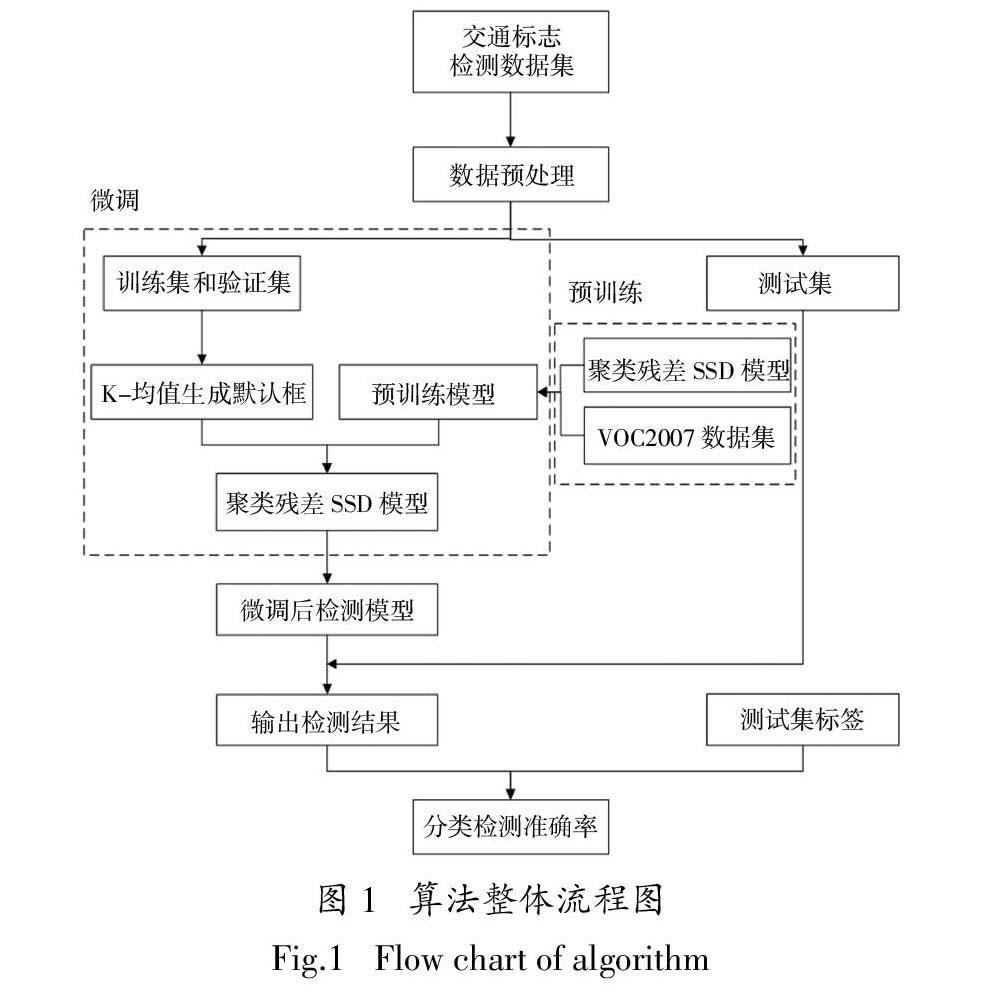
本文所提算法整體流程如圖1所示.首先對數據進行預處理,擴充訓練樣本;然后對模型依次進行預訓練和微調,微調過程中引入K-均值聚類算法實現窗口大小的啟發式生成,克服原始SSD模型窗口生成機制具有內在盲目性這一缺陷;最后對模型檢測性能進行評價.
■
圖1 ? 算法整體流程圖
Fig.1 ? Flow chart of algorithm
1.1 ? 原始SSD模型
原始SSD是以VGG16[20]為基礎網絡,額外再依次堆疊5個卷積模塊構成的一種深度CNN模型,共有25個卷積層和5個最大池化層. 輸入為512×512像素圖像,其中5個最大池化層將基礎網絡VGG16分隔為6個部分,前5個部分每部分包含卷積層的個數分別為2、2、3、3和3,即卷積層1~13,包含的卷積通道數分別為64、128、256、512和512. 前13個卷積層卷積核大小均為3×3,卷積跨度均為1. 最大池化層的池化窗口為2×2,跨度為2. 第6個部分有兩層卷積(卷積層14、15),卷積層14的卷積核大小為3×3,卷積通道為1 024. 卷積層15的卷積核大小為1×1,卷積通道為1 024.
5個額外堆疊的卷積模塊中每個模塊都有2層卷積(卷積層16~25),第1個模塊第1層卷積(卷積層16)的卷積核大小為1×1,第2層卷積(卷積層17)的卷積核大小為3×3. 卷積層16和17的跨度分別為1和2,通道數分別為256和512. 第2、3、4個模塊的第1層卷積(卷積層18、20和22)的卷積核大小均為1×1,跨度均為1,通道數均為128;第2層卷積(卷積層19、21和23)的卷積核大小均為3×3,跨度均為2,通道數均為256. 第5個模塊第1層卷積(卷積層24)的卷積核大小為1×1,第2層卷積(卷積層25)的卷積核大小為4×4. 卷積層24和25的跨度均為1,但通道數分別為128和256.原始SSD模型綜合10、15、17、19、21、23、25這7層卷積層,將7層不同尺度的特征層用于目標的分類檢測與位置回歸[18].
1.2 ? ResNet50殘差網絡
通常通過增加網絡層數可以改善特征表征質量,但是由于受梯度消失或爆炸等梯度不穩定問題制約,以VGG16為基礎的SSD模型難以通過進一步擴充網絡深度以改善特征表征質量.深度殘差網絡(ResNet)引入殘差連接在一定程度上規避了梯度問題,這為改善SSD檢測性能提供了可能.
常規深度神經網絡的特征以連乘方式在層間傳播,HL(xi)為特征分布函數,見式(1),xi為輸入數據(i = 1)或第i層網絡特征(i > 1),L表示網絡總層數,wi為網絡第i層權重參數. 網絡權重wi與輸入數據xi經過卷積和激活函數σ,最后以連乘方式輸出特征,可能導致梯度不穩定發生[21].
HL(xi) = ■wl xl
xl = σ(wl - 1 xl - 1) ? ? ? ?(1)
ResNet定義一個殘差函數F(xi) = HL(xi) - xi,將特征層間乘性傳播改善為特征殘差的層間加性傳播,如公式(2)所示,從而避免了梯度不穩定問題發生. ResNet的卷積層數可以達到數十甚至上百層,ResNet50是一個典型模型,其深度可以達到50層[19]. 本文將ResNet50取代原始SSD模型中的VGG16,以改善特征表征質量.
HL(xi) = xi + ■F(xi,wi) ? ? (2)
1.3 ? K-均值聚類確定默認窗口大小
原始SSD模型采用基于默認窗口的目標預測檢測. 默認窗口有兩個自由參數:大小和長寬比.原始SSD模型中默認窗口的大小以隨機方式指定,具體地,事先指定使用7個不同尺度的特征層作為預測層,通過
sk = smin + ■(k - 1),k∈[1,m]
確定每個預測層中默認窗的基準大小[18]. 其中m表示預測層的數量,m = 7;smin、smax分別表示第1和第7個預測層默認窗的基準大小;sk表示其他預測層默認窗的基準大小. 實踐中smin和smax的值往往需要多次嘗試,本質上是盲目搜索的,不具備任何啟發性,導致檢測效率受限.
本文采用K-均值聚類算法取代原始SSD的盲目搜索方法生成默認窗的基準大小sk. 采用K-均值算法對訓練集中交通標志的大小聚類,鑒于選用7個不同尺度的特征層作為預測層,聚類中心個數指定取值7,即聚成7個簇. 聚類中心點對應的窗口大小即為默認窗口的基準大小sk. 從而,訓練集中檢測目標的大小作為一種先驗知識被聚類發現,指導默認窗口基準大小的選取.
1.4 ? 聚類殘差SSD模型
如圖2所示,所提聚類殘差SSD模型是以ResNet50作為基礎網絡,再額外疊加5個卷積模塊構成的一個深度殘差網絡.模型的參數設置如表1所示,網絡共由65層,包含59個卷積層,5個最大池化層. 輸入為512×512像素圖像,每經過池化層后輸出的特征層大小都會減小為上層輸入大小的1/2,最后一層卷積層的大小為1×1.
表1 ? 聚類殘差SSD模型的參數設置
Tab.1 ? Parameter settings of
the cluster residual SSD model
■
已有研究表明,低層特征圖含有更豐富的細節信息,對小目標的檢測十分有用,而高層特征圖具有較強的語義信息,適用于大目標的檢測,結合高低多層特征圖有利于不同尺度目標的檢測. 首先,將模型中的Stage3_5、Stage4_3、Conv1_2、Conv2_2、Conv3_2、Conv4_2和Conv5_2,7種不同尺度的特征層用于預測目標,實現多尺度檢測與識別. 接著,針對7種不同尺度的預測層,使用卷積核進行目標預測,同時輸出目標分類置信度和目標框與預測框的相對位置偏移量.記一個特征圖的分辨率是m × n,每個像素單元指定sk為基準大小的b個不同寬高比的默認框,每個默認框需要預測c個類別和4個相對偏移量Δ(cx,cy,w,h),那么當前特征圖有(c + 4)× b × m × n個自由參數.不同寬高比默認框的使用可以有效地離散輸出框的形狀,提高匹配精度和速度. 之后,當預測到該層有目標時,使用默認框與目標框進行匹配,匹配結果即為預測框. 本文使用Jaccard Overlap策略來匹配目標框和默認框[18],文中Jaccard Overlap的閾值設置為0.5. 最后使用非極大值抑制去除冗余的預測框,本文非極大值抑制的閾值設為0.6.
模型中總損失函數為定位損失和分類損失的加權和,其定義如式(3)所示,其中Lconf和Lloc分別表示分類損失和定位損失,N是匹配的默認框個數,如果N = 0,則總的損失為0,f是每個預測框與目標框的匹配標志(f = 1表示匹配,f = 0表示不匹配),例如f ?pij=1表示類別為p的第i個默認框與第j個目標框相匹配. 分類損失如式(4)所示,其中c表示類的置信度. 定位損失如式(5)所示,其中l表示預測框,g表示目標框,d為默認框,(cx,cy)是相對中心點的偏移量[18].
L(f,c,l,g) = ■(Lconf (f,c) + αLloc (f,l,g)) ? ?(3)
Lconf (f,c) = -■f ?pij log(■pi) - ■log(■0i)
■pi = ■ ? ? ?(4)
Lloc(f,l,g) = ■■ f ?pijsmoothL1(l mi - ■ mj)
■ cxj= (g cxj - d cxi ?)/d wi,■ cyj= (g cyj - d cyi ?)/d hi
■ wj= log■,■ hj= log■ ? ?(5)
2 ? 實驗數據和性能評價指標
2.1 ? 數據集
2.1.1 ? 德國交通標志檢測數據集 (GTSDB)
GTSDB[22]數據庫中的交通標志圖像全部從自然場景中采集得到,如圖3所示,有不同道路(高速公路、城市道路、鄉村道路),不同光線(光線強和光線弱),不同天氣(雨天、霧天、雪天)下的圖像,合計900幅圖像,每幅圖像大小為1 360×800像素. 每一幅圖像有1~4個交通標志或者沒有交通標志.交通標志大小在16×16~128×128像素之間.將所有交通標志按照如圖4方式分為3類: 禁止標志( Prohibitory)、指示標志(Mandatory)、危險標志(Danger).900幅圖像被分為訓練集和測試集兩部分,其中訓練集為600幅圖像,測試集為300幅圖像.
■
圖3 ? GTSDB交通場景圖像
Fig.3 ? Traffic scene image of GTSDB
■
(a)禁止標志(Prohibitory)
■
(b)指示標志(Mandatory)
■
(c)危險標志(Danger)
圖4 ? GTSDB交通標志類別圖
Fig.4 ? Traffic sign class image of GTSDB
2.1.2 ? 中國交通標志數據集 (CTSD)
CTSD[23]數據庫中的圖像是通過采集北京和廈門不同天氣(晴天、雨天、大風)、不同道路(高速公路、城市道路、鄉村道路)下的自然場景圖像,部分如圖5所示.圖像為1 024×768和1 270×800像素兩類. 一共有1 100幅圖像,訓練集700幅,測試集400幅.訓練集中交通標志的大小在20×20~380×378像素之間,測試集中交通標志的大小在26×26~573×557像素之間.將所有交通標志按照如圖6所示方式分為3類: 禁止標志( Prohibitory)、指示標志(Mandatory)、危險標志(Danger).
■
圖5 ? CTSD交通場景圖像
Fig.5 ? Traffic scene image of CTSD
■
(a)禁止標志(Prohibitory)
■
(b)指示標志(Mandatory)
■
(c)危險標志(Danger)
圖6 ? CTSD交通標志類別圖
Fig.6 ? Traffic sign class image of CTSD
2.2 ? 訓練樣本擴充
為了改善模型魯棒性,擴充訓練數據集. 擴充后的訓練集包括①原始圖像;②對原始圖像再采樣得到的圖像塊,與原圖像目標的Jaccard Overlap[18]分別為0.1、0.3、0.5、0.7、0.9;③將原始圖像隨機采樣一部分. 采樣后圖像的大小為原始圖像的0.1~1倍,寬高比在1/2~2之間,當目標框的中心在采樣后的圖像中時,裁去目標框落在圖像外面的部分,保留重疊部分. 經過上述采樣之后,將每個采樣的小塊調整到512×512像素,并以0.5的概率對其水平翻轉.
2.3 ? 性能評價
采用精確率(Precision)和召回率(Recall)的曲線PR所包圍的面積AP來評價模型測試準確率. AP取值越大,表明檢測準確率越高. mAP是所有類別AP的平均值.其中Precision與假陽性樣本個數(FP)和正陽性樣本個數(TP)的關系,Recall與假陰性樣本個數(FN)和正陽性樣本個數(TP)的關系如式(6)所示:
Precision = ■
Recall = ■ ? ? (6)
3 ? 實驗結果及分析
針對原始SSD模型和所提SSD模型,開展對比實驗.
3.1 ? 預訓練與微調
本文所提聚類殘差SSD模型僅在預先訓練好的ResNet50網絡的基礎上進行微調.預訓練使用VOC 2007數據集[24]. 微調過程中,通過損失函數最小化達到模型最優.優化器選用Adam;訓練輪次為500;學習率采用動態的方式,當輪次小于300時,學習率為10-4;當輪次大于300時,學習率為10-5.
3.2 ? 實驗過程及結果
本文所用實驗環境,硬件配置為I7 7700K處理器、16 G內存和Titan XP顯卡,軟件配置為Ubuntu16.04、Python3.5和Keras.
3.2.1 ? 原始SSD模型的訓練
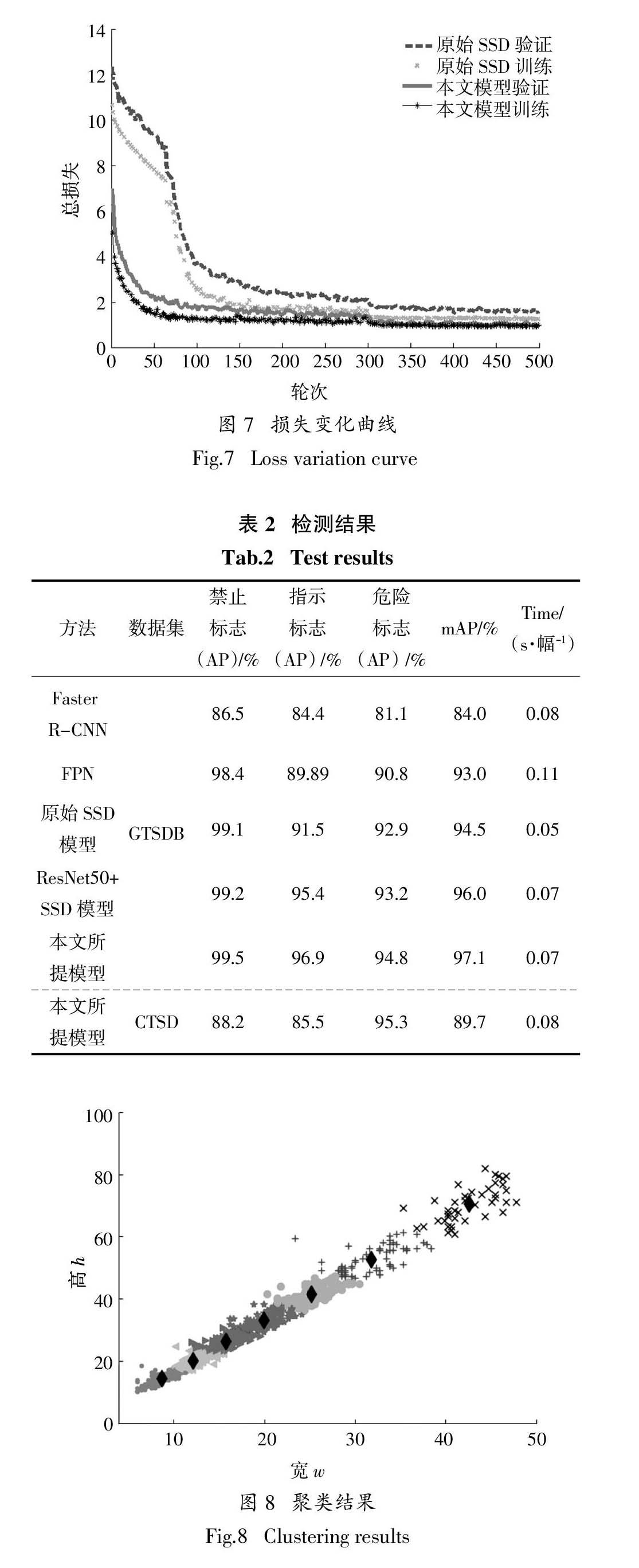
使用2.1中所介紹的GTSDB數據集,對原始SSD模型進行訓練,根據文獻[18]中默認框的生成方式將sk設置為[0.05,0.13,0.21,0.29,0.37,0.45, 0.53],訓練和驗證過程中損失函數如圖7所示,訓練集和驗證集的損失不斷減小,當輪次到300次時訓練基本達到收斂. 將測試集在該模型上進行實驗,測試結果如表2第4行所示,檢測的mAP可以達到94.5%,每幅圖像的檢測速度是0.05 s. 將原始SSD模型的基礎網絡替換為ResNet50,檢測結果如表2第5行所示,檢測的mAP可以達到96%,每幅圖像的檢測速度是0.07 s.以ResNet50為基礎網絡的SSD模型比原始SSD模型的mAP高1.5%,每幅圖像的檢測速度慢0.02 s,檢測效率略降,準確率得到改善.
3.2.2 ? 聚類殘差SSD模型訓練
使用GTSDB對所提模型進行訓練.首先根據K-均值聚類算法將GTSDB訓練集中交通標志的長和寬聚成7個簇,如圖8所示,聚類中心點對應默認窗口的基準大小.得到默認窗口的基準大小分別是[8.65,14.69],[12.12,20.38],[15.69,26.48],[19.95,33.44],[25.25,41.88],[31.81,52.80]和[42.57,70.56]. 訓練和驗證過程中損失函數如圖7所示,當輪次到300次時認為模型已收斂. 從圖中可以發現,所提模型最后收斂損失小于原始SSD模型的收斂損失. 檢測結果如表2第6行所示,mAP達到97.1%,每幅圖像的檢測速度0.07 s.所提模型比以ResNet50為基礎網絡的SSD模型mAP高出1.1%,比原始SSD模型高出2.6%.同時開展本文算法和Faster R-CNN[25]和FPN檢測比對實驗,結果見表2第2行和第3行,均表明所提模型檢測性能得到明顯改善.
■
輪次
圖7 ? 損失變化曲線
Fig.7 ? Loss variation curve
表2 ? 檢測結果
Tab.2 ? Test results
■
■
寬w
圖8 ? 聚類結果
Fig.8 ? Clustering results
圖9給出了不同天氣、不同交通場景下2幅典型圖像的交通標志小目標檢測結果. 圖9(a)中所有的目標都被檢測出來,圖9(b)中第1幅圖像有一個漏檢的目標,第2幅圖像有一個誤檢的目標. 所提模型對天氣變化和交通場景改變具有更好的魯
棒性.
■
(a)所提模型的檢測結果
■
(b)原始SSD模型的檢測結果
圖9 ? GTSDB圖像檢測結果
Fig.9 ? Detection results on GTSDB images
3.3 ? 實驗分析
表2給出了同一數據集(GTSDB)下不同算法的實驗結果. 可以看出,在檢測準確率方面,本文算法達到最優mAP為97.1%,比原始SSD模型有2.6%的提升,比FPN算法有4.1%提升;同時檢測效率并沒有受到明顯的影響,僅比原始的SSD模型減少0.02 s. 單類檢測準確率方面,禁止標志的AP可以達到99.5%,優于其他所有算法;指示標志和危險標志的AP分別為96.9%和94.8%,檢測準確率優于其他所有算法,但并沒有達到和禁止標志相當的檢測準確率. 針對這一問題,對數據集中禁止標志、指示標志、危險標志進行統計,并以直方圖的方式可視化,如圖10所示,可以看出指示標志和危險標志的數量都較少,存在數據不均衡問題,影響了模型對該類標志的檢測性能. 后續研究中,考慮適當增加數據,或收集更豐富的數據集進行研究,以提升不同場景圖像檢測的魯棒性.
3.4 ? 算法驗證
在相同實驗條件下,針對CTSD驗證所提模型的有效性. 根據K-均值算法得到默認窗口的基準大小分別為[12.95,19.65],[21.00,32.21],[31.65, 48.29],[44.19,68.46],[62.05,97.23],[87.02,129.97]和[152.35,233.55]. 其他訓練和測試過程與GTSDB的相同. 檢測結果如表2第7行所示,本文所提模型獲得了89.7% mAP和每幅圖像0.08 s的檢測速度.
■
圖10 ? 3類標志的數量分布
Fig.10 ? The number of distribution map of three class markers
圖11給出了CTSD中兩幅典型的自然場景交通圖像,左圖是晴朗天氣下城市道路場景,右圖是陰雨天氣下高速公路場景. 本文所提模型將圖中的交通標志小目標全部正確檢出.
■
圖11 ? CTSD圖像檢測結果
Fig.11 ? Detection results on CTSD images
4 ? 總 ? 結
針對自然場景中交通標志小目標檢測問題,以及原始SSD模型用于小目標檢測時特征表征能力和檢測效率兩方面的不足,提出一種聚類殘差SSD模型. 一方面將原始SSD模型的基礎網絡VGG16替換為特征表征能力更強的ResNet50深度殘差網絡;另一方面采用K-均值聚類算法發現小目標默認窗口的大小,實現默認窗口大小的優化選擇,改善了原始SSD模型中盲目搜索默認窗口大小的缺陷.針對GTSDB基準數據集的測試獲得了97.1% mAP和每幅圖像0.07 s的檢測速度,針對CTSD基準數據集的測試獲得了89.7% mAP和每幅圖像0.08 s的檢測速度,表明所提模型求解交通標志小目標檢測問題的有效性.
參考文獻
[1] ? ?DALAL N,TRIGGS B. Histograms of oriented gradients for human detection[C]//IEEE Conference on Computer Vision & Pattern Recognition.Washington DC:IEEE Computer Society,2005:886—893.
[2] ? ?VIOLA P,JONES M. Rapid object detection using a boosted cascade of simple features[C]//Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington DC: IEEE Computer Society,2001:511—518.
[3] ? ?LOWE D G. Distinctive image features from scale-invariant key points[J]. International Journal of Computer Vision,2004,60(2):91—110.
[4] ? ?OJALA T,HARWOOD I. A comparative study of texture measures with classification based on feature distributions[J]. Pattern Recognition,1996,29(1):51—59.
[5] ? ?BOI F,GAGLIARDINI L. A support vector machines network for traffic sign recognition[C]//International Joint Conference on Neural Networks. Washington DC: IEEE Computer Society,2011:2210—2216.
[6] ? ?WANG G Y,REN G H,WU Z L,et al. A hierarchical method for traffic sign classification with support vector machines[C]//The 2013 International Joint Conference on Neural Networks (IJCNN). Washington DC: IEEE Computer Society,2013:1—6.
[7] ? ?TANG S S,HUANG L L. Traffic sign recognition using complementary features[C]//2013 2nd IAPR Asian Conference on Pattern Recognition (ACPR). Washington DC: IEEE Computer Society,2013:210—214.
[8] ? ?SUGIYAMA M. Local fisher discriminant analysis for supervised dimensionality reduction[C]//Proceedings of the 23rd International Conference on Machine Learning. New York : ACM,2006: 905—912.
[9] ? ?CHEN T,LU S J. Accurate and efficient traffic sign detection using discriminative AdaBoost and support vector regression[J].IEEE Transactions on Vehicular Technology,2016,65(6):4006—4015.
[10] ?GIRSHICK R,DONAHUE J,DARRELL T,et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C] // Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition. Ohio: IEEE,2014: 580—587.
[11] ?LECUN Y,BOTTOU L,BENGIO Y,et al. Gradient-based learning applied to document recognition[J].Proceedings of the IEEE,1998,86(11):2278—2324.
[12] ?ZHU Y Y,ZHANG C Q,ZHOU D Y,et al. Traffic sign detection and recognition using fully convolutional network guided proposals[J].Neurocomputing,2016,214:758—766.
[13] ?SHELHAMER E,LONG J,DARRELL T,et al. Fully convolutional networks for semantic segmentation[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2017,39(4): 640—651.
[14] ?REDMON J,DIVVALA S,GIRSHICK R,et al. You only look once: unified,real-time object detection[C] // Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern. Nevada: IEEE,2016:779—788.
[15] ?MENG Z B,FAN X C,CHEN X,et al. Detecting small signs from large images[C] // Proceedings of the 2017 IEEE International Conference on Informatiorn Reuse and Integration. California: IEEE,2017: 217—224.
[16] ?HE K M,ZHANG X Y,REN S Q,et al. Spatial pyramid pooling in deep convolutional networks for visual recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2015,37(9):1904—1916.
[17] ?TSUNG Y L,PIOTR D,ROSS G,et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Honolulu:IEEE,2007:936—944.
Facebook AI Research (FAIR),Cornell University and Cornell Tech,2017.
[18] ?LIU W,ANGUELOV D,ERHAN D,et al. SSD: single shot multibox detector[C]//Proceedings of the 2016 European Conference on Computer Vision. Amsterdam: ECCV,2016:21—37.
[19] ?HE K M,ZHANG X Y,REN S Q,et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas:IEEE,2016: 770—778.
[20] ?SIMONYAN K,ZISSERMAN A. Very deep convolutional networks for large-scale image recognition[C]//International Conference on Learning Representations. San Diego:Oxford,2015:1—14.
[21] ?陳建廷,向陽. 深度神經網絡訓練中梯度不穩定現象研究綜述[J]. 軟件學報,2018,29(7):2071-2091.
CHEN J T,XIANG Y. Research review on gradient instability in deep neural network training [J]. Journal of Software,2018,29(7):2071—2091.(In Chinese)
[22] ?HOUBEN S,STALLKAMP J,SALMEN J,et al. Detection of traffic signs in real-world images:The German traffic sign detection benchmark[C]//The 2013 International Joint Conference on Neural Networks(IJCNN). Dallas:IEEE,2013:1—8.
[23] ?YANG Y,LUO H L,XU H R,et al. Towards real-time traffic sign detection and classification[J]. IEEE Transactions on Intelligent Transportation Systems,2016,17:2022—2031.
[24] ?EVERINGHAM M,GOOL L,WILLIAMS C K,et al. The pascal visual object classes (VOC) challenge[J]. International Journal of Computer Vision,2010,88(2): 202—228.
[25] ?REN S Q,HE K M,GIRSHICK R,et al. Faster R-CNN: towards real-time object detection with region proposal networks[C]// Advances in Neural Information Processing Systems 28. Montreal: NIPS,2015:91—99.
猜你喜歡
中國教育技術裝備(2016年19期)2016-12-27 19:23:52
中國遠程教育(2016年11期)2016-12-27 18:07:31
現代商貿工業(2016年25期)2016-12-26 09:58:02
江蘇教育·中學教學版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學教學版(2016年11期)2016-12-21 11:36:29
現代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導刊(2016年9期)2016-11-07 22:20:49
