包含跨域建模和深度融合網絡的手繪草圖檢索?
2019-12-11 04:27:46劉玉杰邢敏敏李宗民
軟件學報 2019年11期
于 鄧 , 劉玉杰 , 邢敏敏 , 李宗民 , 李 華
1(中國石油大學(華東)計算機通信工程學院,山東 青島 266580)
2(中國科學院 計算計算技術研究所,北京 100190)
近年來,隨著互聯網技術和移動終端設備的產品更新,觸屏技術快速發展,多媒體信息(尤其是圖像信息)急劇增加.伴隨著觸屏技術的不斷進步,平板電腦、掌上設備和超寬屏幕手機制造產業和使用正蓬勃發展,可觸屏設備逐漸成為人們生活中不可或缺的一部分,用戶可以用手繪草圖的方式在移動終端快捷方便地描繪出所需物體的外觀、特點及其輪廓.而手繪圖像檢索作為針對可觸屏設備的新興的一個科研領域,具有非常大的潛力和市場價值.如何有效地跨越手繪草圖與自然圖片之間的語義鴻溝進行檢索,是眾多研究人員面臨的難點.與此同時,當面臨高度抽象的手繪圖像的問題時,特征的選取、高效的檢索算法,成為當前的一個研究熱點.手繪草圖檢索(sketch-based image retrieval,簡稱SBIR)是指通過手繪草圖,在海量自然圖片數據庫中找到用戶想要的自然圖片的過程,如圖1 所示.

Fig.1 Sketch and sketch-based image retrieval圖1 手繪草圖及手繪草圖檢索
圖1 展示的是使用手繪草圖搜索自然圖像數據庫中的彩色自然圖片的結果.自然圖片具有豐富的紋理信息和彩色信息,同時,自然圖片對于同一物體的刻畫基本上是一致的,沒有劇烈的形變或者是抽象概括;而與自然彩色圖像相比,手繪草圖擁有高度的抽象性和概括性,由簡單的線條和點組成.所以手繪草圖與自然彩色圖片之間巨大的視覺差異和語義差距,導致了特征選擇的困難,進而導致較低的檢索準確率.
針對手繪草圖與自然彩色圖片之間的視覺差異,本文提出了“分層”跨域匹配的框架;同時,針對手繪草圖與自然圖片之間的語義差距,本文設計了多層深度融合卷積神經網絡(multi-layer deep fusion convolutional neural network)來學習手繪草圖和自然圖片的多層跨域特征.該方法還探索了對于多層深度特征的融合技術的研究.為了實現更高精度的和更高效的檢索,本文方法主要研究的是手繪草圖與自然彩色圖片之間的跨域建模(crossdomain modeling)和與模型相適應的深度特征學習.對本文的算法框架的簡介如下.
在手繪草圖檢索領域中提出了獨特的基于“層次”屬性的檢索模型.本文檢索模型旨在跨越手繪草圖和自然圖像的視覺域的差距;對于手繪草圖和自然圖片的不同層次的特征性質進行了建模;與此同時,提出了與多層模型相適應的多層深度融合卷積神經網絡,并且展示了將多層提取的特征融合成最終特征表示的過程.
本文第1 節介紹相關工作.第2 節闡述本文的核心理論.第3 節對實驗細節和實驗結果進行展示.第4 節總結本文方法,并對未來的工作進行初步的探討.
1 相關工作
目前對于手繪草圖語義的定義,有些工作給出其獨到的定義方法.Eitz 等人[1]在手繪草圖的線條長度方面,研究了人類使用手繪草圖來描述物體的過程,并且公布了一個擁有“時序”屬性的TU-Berlin 手繪草圖數據庫.Fu等人[2]提出了一項用以挖掘手繪草圖中的手繪時序屬性的工作,對手繪草圖中的線條設計了先后順序的規則,以獲得一幅手繪圖像中的每一條筆畫(stroke)的時序,再將一幅手繪圖像中的線條以動畫的形式一條一條地繪制出來,這項工作主要用來模擬動畫繪制的過程.Yu 等人[3]提及到從手繪草圖中獲取手繪草圖的時序信息,并對這些時序信息進行分離,將它們輸入到多通道多尺度的卷積神經網絡(convolutional neural network,簡稱CNN)框架中,即Sketch-A-Net.Sangkloy 等人[4]提出了一個數據量更大的手繪草圖數據庫,同時,在數據庫中為每一幅手繪草圖添加了Sketchablity 屬性,用來表明該手繪草圖在繪制時的難易程度.
在手繪草圖的圖像檢索(SBIR)中,對于將彩色自然圖片與手繪草圖映射到同一視覺域的跨域方法,主要是將自然圖片轉化成類似于手繪圖片的邊緣圖,以保證兩者在高層的視覺上的可比性.主流的邊緣檢測方法分為2 類:第1 類是基于顯著性檢測的方法,包括Canny Detector 邊緣檢測方法和Robert Detector 邊緣檢測方法等;第2 類是基于邊緣感應的方法,例如Sketch-token[5]、Berkeley detection[6]等方法.這兩類邊緣檢測方法廣泛地被研究人員所認可和使用,但是它們處理后的邊緣圖像中仍然不可避免地存在著大量的背景噪聲,所以,由這些方法得到的自然圖片的邊緣圖(edge map)的背景并不像手繪草圖圖像一樣背景純凈.
本文的深度多層卷積神經網絡主要是受到了以下工作的啟發:Yu 等人[7]在細粒度手繪草圖檢索中,將三元損失(triple loss)應用到3 層的卷積神經網絡中;Su 等人[8]提出了一種新型的組合和融合多層深度網絡學習特征的方法.
現有的手繪草圖和自然圖片的特征描述子,主要分為手工特征和深度學習特征兩類.
?第1 類:手工特征.如Sift[9]、Shape Context[10]等局部特征和近期專門為手繪草圖圖片或者邊緣圖設計的特征描述子——Cao[11]提出的binary HOG 和Gradient Field HOG(GF-HOG)[12]以及shape words[13]等手工特征.
?第2 類:深度學習特征.由于卷積神經網絡(CNN)對于數據的強大擬合能力以及對于特征提取的深度,隨著對于網絡的深度的增加,深度學習框架AlexNet[14]、LeNet[15]、VGG[16]以及它們的變體VGG-16、VGG-19 等網絡的出現,使得計算機視覺領域圖像特征的提取方式發生了巨大的變化.
本文將在第4 節實驗部分對于這些網絡的特征刻畫能力進行實驗比較和實驗驗證.
近年來,針對手繪草圖和自然圖像跨域建模的方法,大多采用了比較新型的深度學習框架及模型.如Bui 等人[17]提出的sketch-photo model、Qi 等人[18]提出的Siamese CNN 模型以及Seddati 等人[19]提出的Quardruplet network 等.現有的跨域深度模型致力于挖掘更深的網絡特征,提取更強的特征描述子.通過對現有工作進行實驗對比,我們發現,手繪草圖檢索領域的研究,從最初的淺層手工特征的研究到目前的深度學習框架的加入,盡管在檢索的精度上有了較大的提升,但對于手繪草圖本身的探究并未達到令人滿意的程度.所以本文從手繪草圖本身的繪制機制出發,進行了更深一步的探索并發現手繪草圖的層次規律,最終實現了對檢索精度的進一步提升.
2 研究框架
為了計算同一視覺域中手繪草圖與自然圖片之間的相似度,采用多層深度融合卷積神經網絡來捕捉和提取手繪草圖與自然圖片的特征.圖2 展示了多層深度融合卷積神經網絡的整個流程.
如圖2 所示.
?首先,按照分層規則(本文第2.1 節、第2.2 節詳述),同時對手繪草圖和自然圖片進行分層操作,即3 層視覺表達,使得它們之間的視覺表達在同一層次上達到統一.
?然后,基于多層視覺表達,將手繪草圖與彩色圖片的邊緣圖作為訓練圖片,分別輸入多層深度融合卷積神經網絡中,進行分層訓練.多層深度融合卷積神經網絡的框架中,手繪草圖的3 層視覺表達的特征由3個 CNN 網絡進行訓練,直至收斂.這里,3 個 CNN 網絡是相同的 Image-very-deep-19 網絡,簡稱VGG-19[16],網絡訓練是基于MatConvNet 的環境.通過將3 個網絡訓練收斂后,提取網絡的全連接層FC-7 的512 維特征向量作為學習特征.然后,把由3 層視覺表達學習到的特征向量融合成1 個特征,作為手繪草圖的特征.通過這種方式,學習到的特征就具有了比原來單層訓練學習的特征更加豐富的語義、層次、空間信息.對于自然圖片采用相同的操作,實現了更好的跨域檢索效果.
?最后,本文利用手繪草圖的特征描述子來檢索自然圖片庫中的彩色自然圖片.
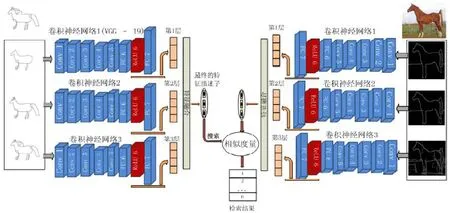
Fig.2 Cross-domain retrieval and deep fusion model圖2 跨域檢索與深度融合模型
將特征表達擴展到多層表達,是為了從手繪草圖和自然圖片的邊緣圖中獲取更多抽象性、細節性的語義信息.在特征相似度計算方面,能夠更多地考慮到語義含義.同時,對于不同層次特征的融合操作,是為了得到手繪草圖和彩色自然圖片唯一的特征表達.
2.1 手繪草圖語義的分層定義
本文將手繪草圖的“時序”特質作為分析的語義特征.時序性是手繪草圖所固有的屬性.通過調研文獻[20]并受實驗測試結果的啟發,本文通過實驗發現手繪草圖的分層屬性,并提出對手繪草圖的分層方法.我們發現,人們在創作手繪草圖時,通常通過第1 層視覺表達,人們就可以大致地繪制出該物體的類別;接下來,人們往往在第2 層視覺表達上添加一些細節信息,來具體標識出描繪的物體;最后在第3 層的視覺表達上,人們用更加具體和細節的紋理來繪制出在大腦中所認知的物體,如圖3 所示.

Fig.3 Layer-based semantic definition of the sketch圖3 手繪草圖的多層語義定義
與此同時,人們在識別手繪草圖時,也是一個由粗到細、由外至內、由輪廓至細節的過程.所以,將手繪草圖進行分層操作符合神經網絡學習的特質,即模擬人類的思維和感官感受方式來進行學習.對于這種層次性繪制和理解的手繪草圖,本文相應地使用層次視覺表達來描述這種層次性的語義.然后,使用卷積神經網絡提取出不同層次的語義特征,并加以融合.
圖3 展示的是不同的手繪草圖的多層視覺表達.手繪草圖的分層方法是將手繪草圖中的時序特質轉化為層次語義屬性,即把一幅手繪草圖轉換成一組多層的視覺表達.在本文中,手繪草圖具體的分層操作是通過獲取手繪草圖中的線條的時序信息,再按照先后順序對手繪草圖的筆畫線條進行分類,即分成前期筆畫、中期筆畫、最終筆畫這3 個視覺層次的集合.最終,筆畫的組合就是圖3 中3 個層次的手繪草圖.
圖3 中的分層算法步驟如下.
(1)對于一幅手繪草圖,本文提取草圖中筆畫的總數目N和每一筆筆畫的時序{T1,T2,…,Tn},即一幅手繪草圖中眾多筆畫的先后順序,其中,每一筆筆畫的長度是已知的.
(2)設置手繪草圖的層次,本文設置為3 層.因為在實驗測試時,當手繪草圖的多層視覺表達少于3 層時,無法顯示出分層網絡的優勢;然而,當多層視覺表達多于3 層時,對于不同人的繪制習慣就失去了普適性和統計性.在3 層的范圍內,人們的繪制習慣大致達到統一,雖然在細節上微微有些出入,但卻極大地提高了對圖像的描述力.所以,本文選擇3 層視覺表達,記為v=3,如圖3 所示.
(3)每一層的筆畫數目由筆畫總數目除以手繪草圖的層次數,并向上取整所得,即.此時,
?前期筆畫集合(第1 層視覺表達)為{T1,T2,…,Tm},因此,第1 層視覺表達繪制出來為{T1,T2,…,Tm};
?中期筆畫集合(第2 層視覺表達)為{Tm+1,Tm+2,…,T2m},因此,第2 層視覺表達繪制出來為{T1,T2,…,T2m};
?最終的筆畫集合(第3 層視覺表達)為原始的手繪草圖{Tn-2m+1,Tn-2m+2,…,Tn},因此,第3 層視覺表達繪制出來為{T1,T2,…,Tn},即包含所有筆畫的手繪草圖.
2.2 跨域建模(cross-domain modeling)
基于手繪草圖的多層視覺表達,對自然彩色圖片采用相同的分層策略,以達到更好的跨域建模(cross domain modeling)效果.首先,對傳統的邊緣檢測方法進行分析,使用如圖4 所示的Canny Detection 邊緣檢測和Robert Detection 邊緣檢測方法以及Sketch-Token 邊緣檢測方法和Berkeley 邊緣檢測方法.

Fig.4 Different methods of edge detection on natural photos圖4 不同方法對于自然圖片的邊緣提取
從圖4 中這些邊緣提取方法的表現中可以看出,基于顯著性檢測的Canny 和Robert 檢測方法對于自然圖片中的背景噪聲具有較強的抗噪能力.然而這兩種方法對于目標的邊緣感應較差,產生了較差的類手繪邊緣圖.而與前兩種方法相比,Sketch-Token 和Berkeley 邊緣檢測方法對于自然圖片中的物體具有比較令人滿意的邊緣感應能力.然而,在最后提取的邊緣圖片中卻保留了大量的背景噪音.
本文在得到手繪草圖的3 個層次的視覺表達后,也對自然圖像進行了相似的實驗探索.由于手繪草圖3 個層次的表達順序為抽象-輪廓-紋理,所以針對自然圖像也按照相同的規律和策略進行處理:首先,對于自然圖像進行邊緣提取,生成邊緣圖.實驗中發現,通過Berkeley 邊緣檢測算法提取的邊緣圖對于自然圖像的輪廓具有不同的感應能力:對于外圍的輪廓,該方法有著較強的感應能力;而對于內部的紋理的感應能力較弱.所以,本文通過調節Berkeley 邊緣感應的閾值,并通過聚類方法進行約束,最后也生成了自然圖像的3 層視覺表達,即最外圍邊緣(邊緣感應最強)-大體結構(邊緣感應中等)-細節紋理(邊緣感應最弱).這樣,本文的手繪草圖3 個層次的視覺表達與自然圖像3 個視覺表達的對應與統一,如圖5 所示.

Fig.5 Layer-based representations of edge map from the natural photo圖5 自然圖片邊緣圖的多層表達
最終,根據文獻[21,22]中Canny 檢測、Robert 檢測、Sketch-Token 與Berkeley 邊緣檢測方法的對比效果以及本文的實現效果,如圖4 所示,本文提出了一種新方法來解決跨域建模階段背景噪音和物體邊緣看似互相矛盾的問題.基于Berkeley 邊緣檢測方法的理論:邊緣圖中的每一個像素的灰度值對應的是該點被分類成邊緣的概率,即邊緣圖中的一條線灰度值越高,這條線就越容易被分類成邊緣,進而這條線的亮度也就越高.進一步來說,由Berkeley 邊緣檢測方法產生的邊緣圖闡述了一個邊緣圖的上每個點的概率分布.因此,針對Berkeley 邊緣檢測的產生的邊緣圖,根據邊緣圖上每個點的灰度值,對于自然圖像產生多層視覺表達.和手繪草圖的層次策略相同,本文的方法對于一張彩色圖片產生3 層視覺表達,對于自然圖片分層跨域方法的闡述如下.
(1)采用K-均值(K-means)方法對一張自然圖片的邊緣圖上的每個點的灰度值進行3 聚類中心的聚類.
(2)第1 層視覺表達被定義為聚類中心中最小的聚類中心所在的簇;接下來,第2 層視覺表達表示的是中層灰度值的聚類簇;最后,擁有最高的灰度值的聚類簇被定義為第3 層.方法如圖5 所示.
通過采用與處理手繪草圖相同的分層策略,獲得了自然圖片的3 層視覺表達,如圖5 所示.到目前為止,可以認為手繪草圖與彩色自然圖片是出于同一視覺域.之后,多層視覺表達就可以輸入到多層深度融合卷積神經網絡來提取特征表示.
多層深度融合卷積神經網絡中的多層框架為手繪草圖和彩色圖片的跨域建模提供了新的跨域思路,并且提供了更多的細節信息和空間信息以及多層的抽象的語義信息.在特征學習階段,這些細節信息不僅豐富了本文特征的描述力,而且保證了跨域檢索的穩定性.
2.3 深度特征融合
在多層深度融合卷積神經網絡的框架中,單一的卷積神經網絡(CNN)采用的是在MatConvNet 環境所訓練的“Image-very-deep-19”網絡結構.在訓練完Flickr15k 數據庫中手繪草圖和彩色自然圖片的多層視覺表達之后,提取每一層網絡的全連接第7 層Convfc-7(fully connected layer 7)的特征作為每一層視覺表達的特征表示.
如上所述,本文的關注點是獲取手繪草圖和彩色自然圖片基于層次的特征表示.這個層次特征是可訓練的,能夠產生語義和區分力的特征表示;同時,這種框架是保證可被高效實現的.基于層次的特征表示從跨域建模階段的多層視覺表達開始,由深度多層融合卷積神經網絡產生.但是如何融合多層特征,是手繪草圖檢索(SBIR)階段的關鍵一步,因為在最后的相似度計算過程中,需要手繪草圖和自然圖片的唯一的特征表示.
特征融合的方式有均值融合、權重融合、串聯融合.
(1)一種簡單的方式就是對不同層次的特征進行均值化,把每一層的特征的權重視為同等重要,這種方法稱為均值融合.

其中,featurefusion表示融合3 層視覺表達的最終融合特征,featurei表示第i-th 層的特征,表示對不同層次的特征進行均值化的操作.
(2)第2 種方式是使用類似于貝葉斯特征融合的方式[20],將不同層次的特征按照其不同的概率數據分布進行融合,稱為權重融合,如公式(2)和公式(3)所示.

在公式(2)中,featurefusion表示融合3 層視覺表達的最終融合特征;featurei表示第i-th 層的特征;Pi是一個依賴于不同層次的檢索表現的值,即在第i層的檢索精度越高,Pi的值越高.在本文的實驗中,Pi的值定義為0.4101、0.4582、0.5298.為了使最后的特征表達更加緊湊,對融合特征進行了L2 規范化,并使用PCA 算法對融合特征的維度進行降維,如公式(2)所示.將特征的維度減小到既能保證特征計算的高效性,又能減少特征向量中的零元素.因此PCA 的系數需要謹慎選擇,以保證融合特征的區分力和緊湊型之間的平衡.本文將融合特征的維度減小到128 維.
在公式(3)中,PCA_featurei表示的是多層融合卷積神經網絡中的第i層規范后的特征.
(3)第3 種特征融合方式就是把所有層次的特征按序排列,按照一定的順序串聯起來,這種方法稱為串聯融合.多層深度融合卷積神經網絡框架中采用的就是串聯融合方式,將第1 層直至第3 層所學習到的深度特征進行有序的串聯,得到最終的特征向量.
以上3 種特征融合方式的有效性驗證結果在第4 節展示.
3 實 驗
3.1 數據庫
本文使用Flickr15k 數據集.該數據集包含60 類,總共14 460 張彩色自然圖片;并且,該數據集還包含由非專業手繪草圖人員繪制的33 類,總共329 張手繪草圖.
3.2 數據擴增
對于訓練深度卷積神經網絡(deep CNN),關鍵的一步是提供充足的訓練數據.對于訓練數據較少的數據庫,我們需要進行數據擴增(data augment)操作.手工特征或者ImageNet[23]所訓練的數據庫基本不需要進行數據擴增.對于在手繪草圖數據集上訓練的對比深度網絡,本文使用的手繪草圖訓練庫是TU-Berlin[1].這個手繪草圖數據集是目前最大的和最通用的數據集,包含了20 000 張手繪草圖.但是,數據量不足以驅動深度卷積神經網絡,容易對數據產生過擬合現象.所以,采用與文獻[20]相同的數據擴增方式,即通過鏡像、(水平、垂直)平移、或者旋轉,將數據擴增到32×32×11×2 倍.
在本文的實驗中,訓練的實驗數據集有ImageNet、TU-Berlin 手繪數據集和Flickr15k 數據集.實驗中,本文將實驗數據集大體按照7:3 的比例進行分割.所有模型在訓練集完成訓練并收斂之后,再在測試集上進行測試,從而獲得每個模型的檢索精度.
3.3 評價標準
本文使用的評價標準是mAP、平均準確率(mean average precision).本文中對于SBIR 中的mAP 定義如下.

其中,q表示在檢索序列里面的檢索手繪草圖,Nq是檢索序列中的手繪草圖的總數,RTi是指檢索出來的正樣本的索引號,ITi表示的是在檢索序列中正樣本的排序索引,NR表示正樣本的總數.
3.4 實驗結果
本文方法與現有方法的實驗對比結果見表1.為了充分驗證本文網絡框架的有效性,對于現有的深度學習網絡,設置了3 種類型的訓練方式來使現有的CNN 網絡的學習能力達到最大化.
(1)第1 類是單獨在自然彩色圖片ImageNet 上訓練的深度卷積神經網絡特征,其中,使用LeNet 的數據集MINIST 是因為手寫數字數據集和我們的手繪草圖在視覺上有一定的相似性.
(2)第2 類是單獨在手繪草圖數據庫TU-Berlin 上訓練的深度卷積神經網絡,用所學習的特征進行檢索.
(3)第3 類是使用訓練好的深度卷積網絡,在Flickr15k 數據集上微調,然后使用再次收斂的網絡所生成的特征進行檢索.
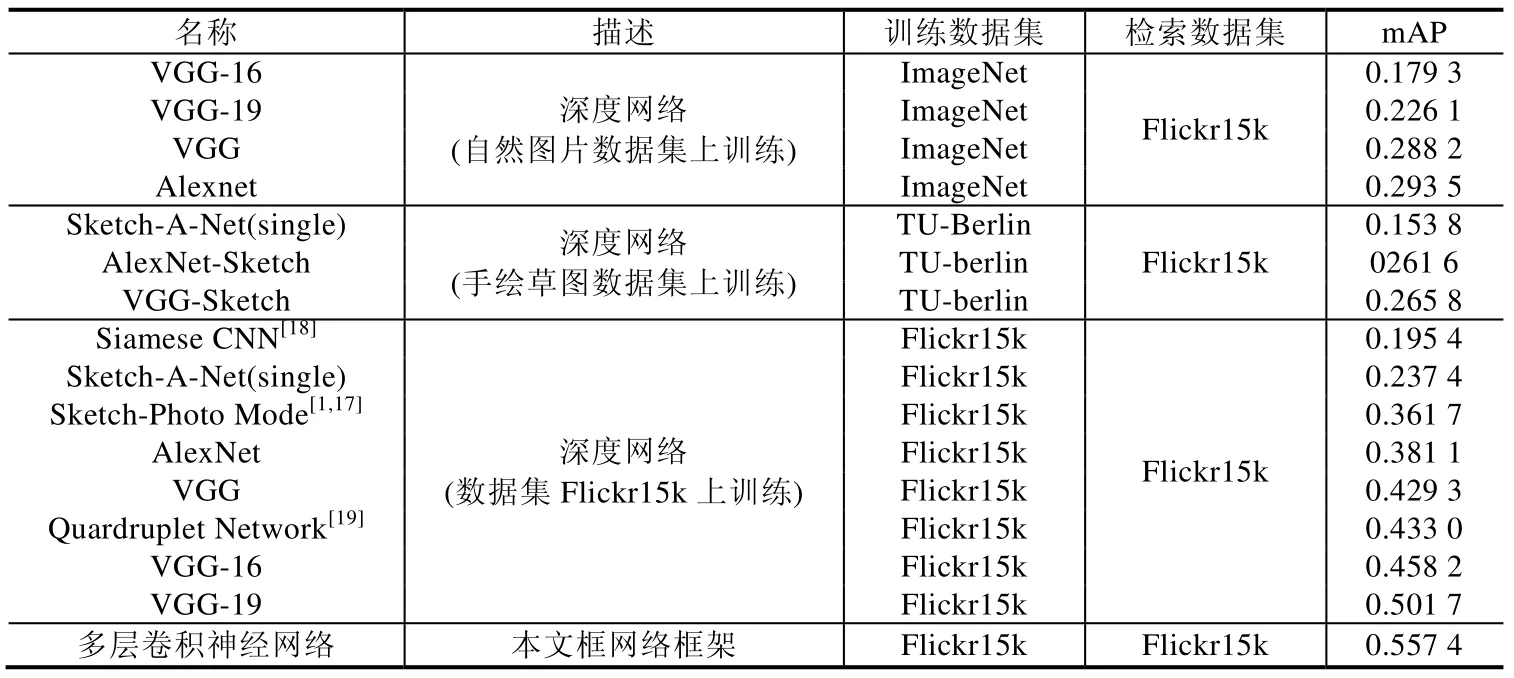
Table 1 Retrieval performance of different methods表1 不同方法的檢索表現
表1 中,Sketch-A-Net(single)網絡結構是參考引用文獻[1]中的網絡參數實現出來的單一尺度的深度網絡,其中,本文使用單一圖片尺度為256×256.
從表1 可以得到的結論如下:多層融合卷積神經網絡的跨域建模的視覺表達和多層深度融合卷積神經網絡的特征表達模型對于手繪草圖檢索(SBIR)領域中手繪草圖和自然圖片具有較強的擬合能力;本文模型所生成的特征向量的檢索準確率遠超基于自然圖片訓練的模型,如主流的Alexnet 網絡和VGG 框架等,同時,對于基于手繪草圖數據集訓練的深度卷積神經網絡的性能也有較大的提升.另外,在第3 類實驗中,本文通過與同領域基于手繪草圖跨域檢索方法進行比較,如Sketch-Photo Model[17]、Siamese CNN[18]與Quardruplet Network[19]等,實驗結果表明,本文的多層卷積神經網絡比同類方法的檢索準確率大致提升了12%~20%.從表1 的實驗結果可以看出本文方法相對于現有方法在網絡性能上的提升.
為了揭示手繪草圖和自然圖片不同層次之間的內在聯系,對不同視覺層次的檢索結果進行分析,實驗的對比結果見表2.

Table 2 Retrieval results on different layers表2 不同層次的檢索效果
在表2 中,實驗中使用的檢索特征是VGG-19 網絡FC7 的特征向量,在擁有最少的空間、語義信息的第1層,獲得了相對較低的檢索精度;而在具有最細致語義信息和空間信息的第3 層,獲得了52.9%的檢索精度,僅僅比本文的多層融合卷積神經網絡少3%的精度.同時,這也是本文的特征融合策略有效性的證明.
為了探索不同的特征融合策略對于手繪草圖檢索(SBIR)的影響,我們對不同的融合策略進行了實驗對比,實驗結果見表3.

Table 3 Impacts of different feature fusion strategies on retrieval results表3 特征融合策略對于檢索結果的影響
從表3 可知,不同的特征融合策略對于提升或者拉低本文最終的融合特征向量的辨別力產生了非常大的影響,尤其是一個較差的融合策略能夠將本文的多層特征的檢索精度從55.74%降低到36.04%.所以,一個合適的特征融合策略對于多層融合卷積神經網絡能力的提升具有非常重要的意義.
最后,多層融合卷積神經網絡對Flickr15k 數據集的檢索結果如圖6 所示.

Fig.6 Retrieval performance of multi-layer fusion CNN on Flickr15k圖6 多層融合卷積神經網絡在Flickr15k 上的檢索表現
如圖6 所示,“×”表示錯誤的檢索結果.其中最后一行展示的是多層融合卷積神經網絡最差的檢索表現,主要是因為Flickr15k 數據集中這類圖片的訓練數據遠遠不足的緣故.
4 總結與未來工作
在本文中,“多層”的概念一直是模型中至關重要的主題,而在實驗中發現,本文的多層視覺表達方法對于手繪草圖或者自然圖片具有數據擴增的潛力.與此同時,本文的理論中仍存在著一個猜想:對于手繪草圖和自然圖片的邊緣圖,是否它們的抽象層次越高,它們之間的相似度就越大?在實驗中,本文的3 層視覺表達的確顯示了這樣的趨勢.
關于設置多少層才能最佳地利用好手繪草圖和彩色自然圖片中的層次信息的問題,本文的實驗僅僅證明了多層表達能夠進一步提高檢索表現,所以仍然需要進行更多的實驗來解答這個問題.正如本文的實驗部分所示,抽象的程度越高,在自然圖片的邊緣圖中的背景噪音就越少.所以我們猜想:在某一個合適的抽象層次,能夠獲得一個最好的視覺表達和特征表示.
本文的特征采用的特征融合策略都比較簡單,與此同時,特征融合階段也是提高多層卷積神經網絡的最終特征的辨別力的關鍵環節.所以,一種更好的特征融合方法將會為手繪草圖檢索(SBIR)的檢索精度帶來巨大的提升.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
無線電工程(2020年11期)2020-10-29 01:25:46
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
