基于多元統計分析和機器學習的驗證碼識別
2019-12-11 02:20:08虞水磊田新宇王金燕
山東理工大學學報(自然科學版) 2019年1期
關鍵詞:方法
虞水磊,田新宇,王金燕
(中南大學 數學與統計學院,湖南 長沙 410083)
隨著互聯網技術的高速發展,網絡安全問題層出不窮,驗證碼技術應運而生。 Aboufadel等[1]提出了扭曲估計的算法,并將之應用于識別 EZ-Gimpy的驗證碼。 Moy等[2]應用 Harr 小波濾波識別驗證碼。Zhang等[3]用KNN(K近鄰)算法破解了4個銀行網站的驗證碼。王曉鵬[4]針對可分離的驗證碼,采用 BP 神經網絡和遺傳算法進行了識別。王曉波等[5]利用基于 MODI(Microsoft Office Document Image,微軟辦公文檔圖像處理庫)對CSDN、QQ、Yahoo、網易等網站的驗證碼進行識別,對于具有背景噪聲、字體工整且易于分割的驗證碼如CSDN等有良好的識別效果,而對于QQ、Yahoo等加入多種干擾、字符變形大的識別率偏低。殷光等[6]對驗證碼分割后用SVM分類的識別方法。王璐[7]釆用分割后用卷積神經網絡識別驗證碼。但是帶有噪聲及粘連的驗證碼識別仍是值得深入探究的問題。本文對帶有噪聲與粘連的驗證碼進行識別技術研究。
1 數據獲取與預處理
1.1 數據獲取
利用Python爬蟲技術對某網站的驗證碼進行爬取,總共獲取350個驗證碼,其大小為70×20像素。獲取的驗證碼如圖1所示。

圖1 未處理驗證碼Fig.1 Unprocessed CAPTCHA
1.2 數據預處理
1.2.1 數據二值化
首先將圖片讀取為RGB三維數組,對圖片中背景與干擾線段取色,經過多次實驗設定閾值,將處于該閾值范圍內像素點的值設為1,其余設為0,二值化結果如圖2所示。

圖2 二值化驗證碼Fig.2 Binarization of CAPTCHA
1.2.2 數據去噪
從圖2可以明顯地看出,二值化后的數據仍包含一些噪聲點,將二值化后的數據中為0值的點取出,采用DBSCAN聚類方法將噪聲點刪去。DBSCAN[8](Density-Based Spatial Clustering of Applications with Noise)是一個典型的基于密度的聚類算法。其核心思想為:從某個選定的核心點出發,不斷向密度可達的區域擴展,從而得到一個包含核心點和邊界點的最大區域,區域中任意兩點密度相連。與層次聚類方法不同,它將簇定義為密度相連的點的最大集合,能夠把具有足夠高密度的區域劃分為簇,其優點在于事先不用給定聚類的類數,同時也可以發現任意形狀的簇類,對于去除數據中的噪聲有很好效果。其步驟是,提取值為0的點的橫縱坐標,做基于密度的聚類,將聚類結果中類別為0的點的值賦為1。DBSCAN聚類結果如圖3所示。
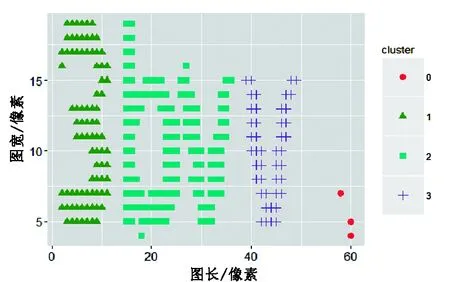
圖3 DBSCAN 聚類結果Fig.3 Results of DBSCAN cluster
圖3中cluster0即紅色圓點代表噪聲點,從圖中可以看出,四個字符的驗證碼分為了三類,由于驗證碼的粘連特征,用DBSCAN聚類可以有效地識別出噪聲,但是難以將字符完全劃分開來,僅使用該方法進行驗證碼單字符的分割,其效果并不好。
1.3 圖像分割
為獲取單字符圖像數據,采用豎直投影法對驗證碼圖像進行分割。為使所獲得的圖像規模相同,將所有驗證碼圖像二值化矩陣進行列求和,并對列和求取均值,繪制圖4所示的線圖,在波谷處選取分割橫坐標。因為進行了去噪處理,分割效果較好。如圖4所示,將原驗證碼圖像矩陣(70×20)分割為4個12×20的單字符圖像矩陣,其分割范圍分別為1~12,13~24,26~37,39~50。
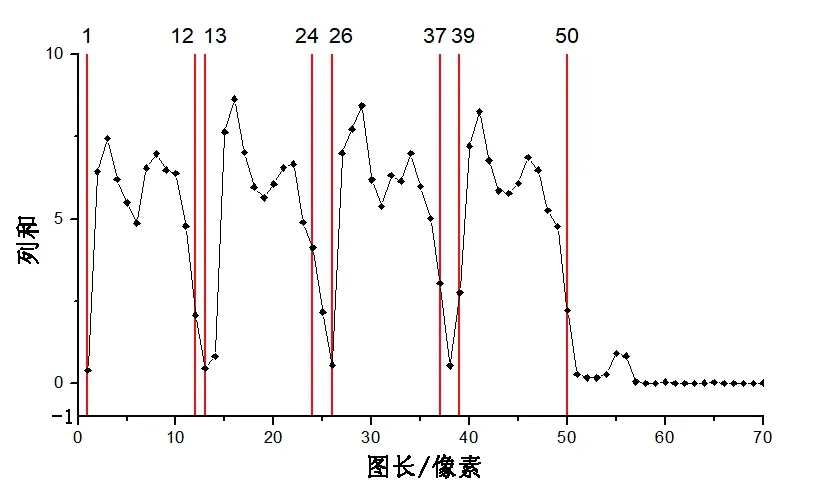
圖4 驗證碼圖像分割圖Fig.4 CAPTCHA segmentation
2 基于聚類方法的驗證碼樣本標注
為實現對驗證碼識別,需要構建帶有標簽的訓練樣本數據,而對驗證碼進行標注需要大量人力,本文提出采用半監督的聚類方法對無標簽驗證碼數據集進行標注。首先,人工標注50個驗證碼,即200個分割后的圖像樣本,并將標注后的樣本與1000個未標注的樣本進行聚類,根據聚類結果進行標注。
2.1 Kmeans聚類
通過觀察,分割后的圖像僅包含1、2、3、n、m、v、c、b、z、x 十個類別,因此從標注的樣本中隨機選取對應類別的樣本作為聚類的初始中心,進行Kmeans 聚類,其中1、2、3、v、c、b、z、x 的分類正確率為100%,而n 和m 的誤分率達到了50%以上,這是由于豎直投影法的分割方法,使得m 和n 的 樣本數據差異不大,這從相似系數的結果圖 5便可以看出。而且一般的Kmeans聚類為無監督的方式,對已標注數據的先驗信息使用較少,因此本文提出了基于AdaBoost方法的半監督Kmeans聚類算法,用少量標注樣本的信息來改善聚類結果,并用于樣本的批量標記。
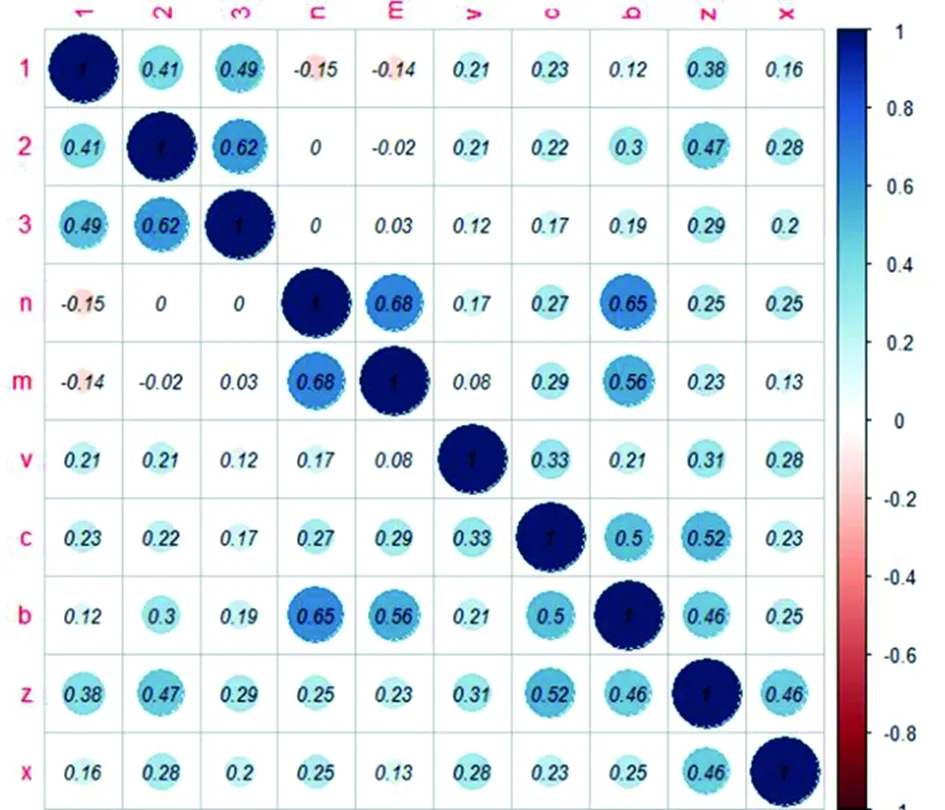
圖5 各類別相似系數圖Fig.5 Correlation coefficients of all clusters
2.2 基于AdaBoost方法的半監督Kmeans聚類
AdaBoost是一種集成學習方法,其基本思想是加權多數表決,加大分類誤差率小的弱分類器的權值,使其在表決中起較大作用,減小分類誤差率大的弱分類器的權值,使其在表決中起較小作用。
對于一個二分問題:
輸入的訓練數據集T={(x1,y1),(x2,y2),…,(xN,yN)},xi∈χ?Rn,yi∈{-1,+1},最終輸出為G(x)。
AdaBoost 算法步驟如下:
2)對第m個弱分類器,m=1,2,…,M。
a.在權值Dm下訓練數據集,得到弱分類器Gm(x):χ→{-1,+1}
b.計算Gm的訓練誤差
c.計算Gm的系數
d.更新訓練數據集的權值分布
Dm+1=(wm+1,1,…,wm+1,i,…,wm+1,N)
3)得到最終分類器。
AdaBoost算法能夠在訓練過程中不斷減小誤差,而對于無監督聚類問題來說,誤差是難以度量的。在半監督問題中,可以使用帶有標簽的部分樣本數據進行誤差度量,并賦予標簽數據新的權重進行聚類。對類別數為2的Kmeans聚類,其算法步驟如下:
2)對第m次聚類,m=1,2,…,M。
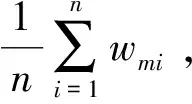
b.計算Clusterm的誤差
em=P(Clusterm(xi)≠yi)=
c.計算Clusterm的系數
d.更新訓練數據集Λ的權值分布
Dm+1=(wm+1,1,…,wm+1,i,…,wm+1,N)
3)得到最終聚類結果。
值得注意的是Kmeans 聚類并不能保證em的降低,只能將第m次聚類的劃分重心拉向錯分的樣本點。因此,可能會出現em≥0.5的情況,在此時應該停止迭代,或進行修正。
使用基于AdaBoost方法的半監督Kmeans聚類,對Kmeans無法分別的m與n類的數據重新進行聚類,其在樣本集Λ上的誤分率僅為5.56%,整體誤分率為0.015%,相比較于傳統Kmeans算法51.8%的誤分率以及10%的整體誤分率有極大的改善。
3 驗證碼識別
本部分采用聚類批量標注過的1 200個單字符樣本作為訓練數據,并對剩余的50個驗證碼(200 個單字符)進行人工標注,將其作為測試數據。分別使用線性判別法Fisher判別分析(FDA)以及K近鄰(KNN)、支持向量機(SVM)、神經網絡(NNET)、隨機森林(RF)等算法,在訓練樣本上訓練,并對測試集進行識別,以對各算法的識別效果與適用性進行比較。
由于驗證碼圖像數據相關程度很高,且部分像素點值為常數,故導致協方差矩陣奇異,不能求逆,導致判別函數無法求解。為處理協方差陣奇異的問題,可以更改優化的目標函數,從而利用優化算法迭代求解;或是應用主成分分析進行降維處理,提取對驗證碼識別影響較大的成分。本文采用的是主成分分析法進行處理。
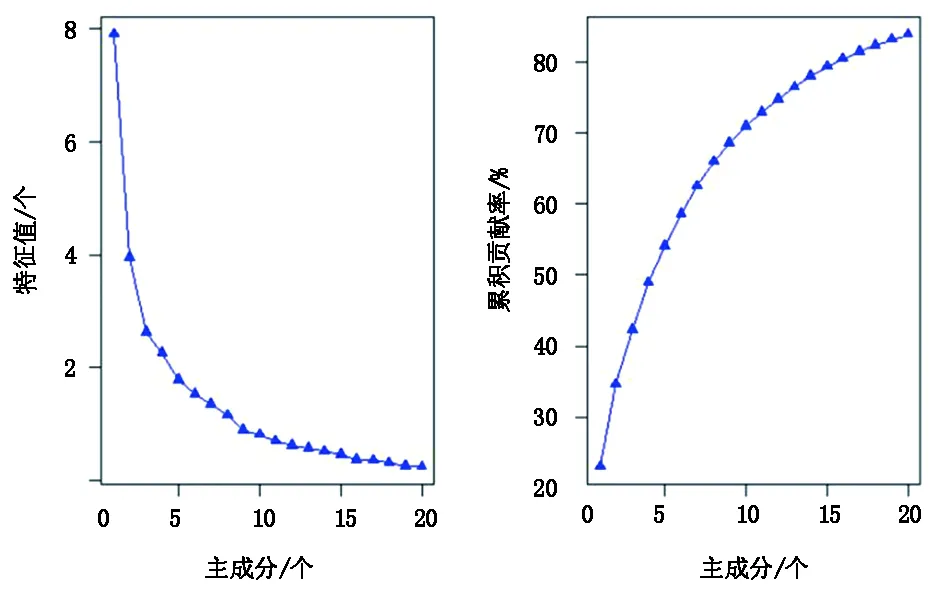
圖6 主成分碎石圖Fig.6 Scree plot of principal components
從圖6來看,當主成分個數大于15,累積貢獻率大于80%,而特征值的減小也并不顯著,因此選取15 個主成分。
對降維后的數據實施Fisher判別,原始數據實施機器學習的算法,各種方法的識別效果見表1。
表1 各算法識別效果
Tab.1 Results of different algorithms
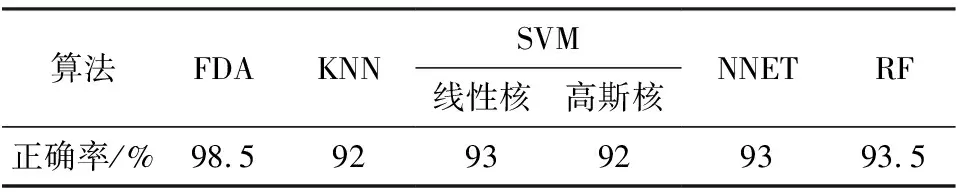
算法FDAKNNSVM線性核高斯核NNETRF正確率/%98.59293929393.5
所進行判別的樣本數據空間χ={0,1}240,即Rn空間中以零點為頂點,邊長為1 的方體的頂點,其數量為2240,而樣本類別僅有10類,所取得樣本數據僅占有樣本空間極少部分的頂點,在這種樣本數據極其稀疏情況下,樣本往往是線性可分的,即可以找到Rn中的超平面G,使得,G(x(s))*G(x(t))<0,x(s)、x(t)為類別為s、t的樣本數據。因此,Fisher 線性判別方法取得了很好的效果,而SVM 方法中線性核的判別效果也好于非線性的高斯核。同時,由于訓練樣本的標注為聚類的結果,其中可能存在錯誤標記導致的異常數據的干擾,但是從判別的結果來看,Fisher判別法在這種情形下,有更好的魯棒性,更加穩健。
從表2 Fisher 判別的識別結果來看,即使采用簡單的豎直投影分割方法,識別依然有較高的正確率,而這也反映出使用半監督Kmeans聚類進行訓練樣本標記的正確率較高。當然,識別的高準確率也表明驗證碼并不安全。
表2 Fisher 判別結果
Tab.2 Results of Fisher discrimination analysis

原始圖像識別結果原始圖像識別結果nnxvb2v2xvnzvzvb11nbxnbnx2bxvnzmz2bbzzzxnbcvncnc3v3cccb2cnvzx2czvn2vx1b1m2v23113
這種驗證碼并不是一種很好的驗證碼形式,這不僅體現在其能被較高的識別率破解,還因為它的用戶體驗較差。觀察驗證碼圖片,部分m、n粘連的字符即使人眼都難以區分。這些字符的形狀從圖片上來看大都相像,人類都很難辨別,而最終識別錯誤的大都是這些難以辨別的字符。
4 結束語
針對網站上的驗證碼數據,采用 DBSCAN 與豎直投影法對驗證碼圖像進行去噪與分割處理,具有很好去噪聲效果,而分割后的圖像也易于識別。對于分割后的單個字符圖像的樣本批量標注問題,提出了基于AdaBoost方法半監督Kmeans聚類算法,該算法的標注結果遠遠優于傳統Kmeans方法的,在樣本標注上極大節約了人力成本,具有理論與現實意義。在驗證碼的識別效果上,比較了經典的Fisher判別與隨機森林、K近鄰、神經網絡、支持向量機等機器學習方法的識別效果。實驗結果發現,這些方法都有較高的單字符識別正確率,而Fisher判別的正確率最高,可以認為在這種線性可分的數據集下,經典的多元統計方法Fisher判別可能比機器學習方法更為適合。而所識別的網站的驗證碼并不完善,其在安全性和用戶體驗上都較差,亟待改善。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
