基于SVDD和D-S理論的曲軸軸承故障診斷
2019-12-17 09:22:12張懿,崔佳
重慶理工大學學報(自然科學) 2019年11期
張 懿,崔 佳
(1.江蘇科技大學 電子信息學院, 江蘇 鎮江 212003; 2.常熟瑞特電氣股份有限公司, 江蘇 常熟 215500)
柴油機是機械動力裝置的心臟,其健康狀態至關重要。對于柴油機故障來說,特征提取[1-2]非常困難也非常關鍵,采用適用于柴油機信號特點理論和方法是確保提取柴油機故障信號特征的首要條件。岳應娟等[3]將故障信號映射為其時頻圖像的識別問題,有效進行故障信號的分類。沈虹等[4]針對柴油機故障位置存在不確定性、時間不確定等問題,提出了一種基于時頻圖像極坐標增強的柴油機故障診斷方法。劉中磊等[5]利用階比雙譜方法有效提取滾動軸承故障振動信號的特征,對滾動軸承故障進行正確的判斷。
柴油機故障診斷技術是根據已收集的各種參數信息及狀態量,并在對信息進行優化、處理、分析后,給出最終的診斷結論。在這一過程中,信息的來源以及數據量的大小決定了診斷結果的好壞,由此看來,柴油機的故障診斷技術與信息融合技術有著相同的原理和結果,所以信息融合技術也可應用于柴油機故障診斷論域。
本文將SVDD與D-S理論相結合,應用于柴油機故障診斷,針對柴油機故障部位與故障特征之間沒有明確對應關系的問題,采用多傳感器采集信號、多故障特征提取方法、不同分類器處理結果獲得的各種冗余互補信息。使用SVDD方法改進D-S證據理論,并建立兩級融合模型進行驗證,實現多等級、多層次的診斷,且與圖像處理、階比雙譜等方法進行實驗對比。結果表明,此方法的診斷精度和穩定性優勢明顯提高。
1 信息融合理論
1.1 信息融合的依據
多源信息融合[6-7]技術研究對象為一個多傳感器的信息處理系統,其本質是:通過先進的數據處理技術依次獲取每一傳感器的觀測信息,再按照規定的算法對數據進行自動篩選、綜合,從而得到決策所需信息。
在柴油機故障診斷過程中,樣本參數非常多,如振動參數、熱力參數、燃油壓力參數、油液和其他參數等。這些參數從各個方面及不同程度折射出柴油機的運行狀況,因此可通過充分利用這些參數,從而有效地提高柴油機故障診斷的準確性。然而,僅單一的特征信息并不能充分反映其運行狀態,在實際診斷過程中,盡可能多地獲得柴油機的特征信息,能對其進行更可靠、更準確的狀態識別。另外,隨著獲取信息的增多,能對多特征信息進行更有效的綜合利用,提高柴油機故障診斷的準確性、可靠性和有效性。
1.2 信息融合的級別
多源信息融合技術可分為3種:① 數據級融合,其優點為數據量利用率較高,能夠提供數據層中細微的信息,精度最高,但由于數據量過大導致局限性也很明顯,效率低下。② 特征級融合,融合階段在特征向量提取完成之后,其優點在于簡化數據量,方便數據的實時處理,但因存在數據壓縮過程,性能依舊較低。③ 決策級融合,各傳感器收集到數據后先進行初步決策,隨后匯總于融合中心進行融合處理得到局部決策。此融合方式是三級融合的最終結果,即使部分采集點故障,系統仍可通過融合處理獲得理想結果,不過由于數據損失最多,融合精度較其他兩級融合要低。
3個融合層次各有優缺點和適用范圍,由于數據級融合運算復雜,本文將特征級融合和決策級融合相結合,在特征級通過支持向量數據描述得出局部決策,進一步采用D-S證據理論對特征級下的局部決策進行決策級融合,以獲得最終診斷結果。
2 D-S證據理論
2.1 基本概念
定義1:設θ為識別框架,若函數m:2θ→[0,1]符合下列條件:
1) 不存在概率為0事件,即:
m(φ)=0
2) 框架Θ的所有元素概率相加結果為1,即:
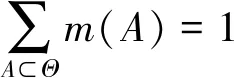
則稱m為框架Θ上基本概率分配函數,m(A)稱為A的基本可信數,表示對A的信任度。
定義2:設Θ為識別框架,若函數Bel:2θ→[0,1]符合:
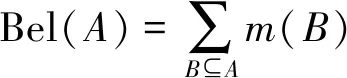
(1)
則稱Bel為信任函數,也稱作下界函數,反映對A的完全信任。
定義3:設θ為識別框架,若函數Pls:2θ→[0,1]符合:
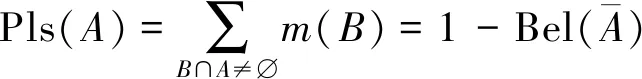
(2)
則稱Pls為似然函數,也稱為上界函數,A的隨機性由式(3)表示。
u(Θ)=Pls(A)-Bel(A)
(3)
[Bel(A), Pls(A)]稱為置信區間,表示對A的隨機性區間。
D-S證據理論[8]可以將模糊信息的狀況表示出來,如圖1所示。
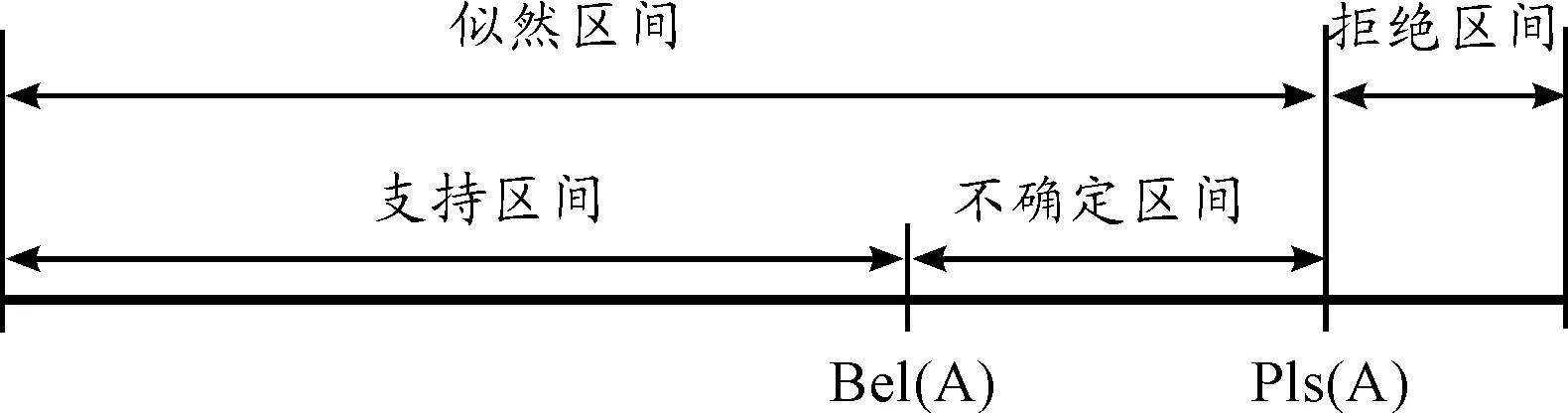
圖1 證據理論的信任區間示意圖
2.2 合成和決策規則
設Bel1和Bel2是在相同區分框架θ的2個置信函數,m1和m2是相應的可信系數,焦元分別為A1,A2,…,Ak和B1,B2,…,BL,并假設
(4)
合成后的基本概率分配函數M:2θ→[0,1]則為:
(5)
由式(5)可知,合成順序并不影響合成計算的結果,因此可采用2個基本證據合成遞推到多個。
在得到證據對識別框架中所有命題的置信區間[Bel(A),Pls(A)]和證據的隨機性u(Θ)之后,可以由以下2條規則確定最終結論F:
規則1:Bel(F)>ε;
規則2:u(θ)<γ。
式中:ε和γ均取大于零的常數,它們的值根據實際情況而定,如果上面2條規則同時滿足,則可判定該事件發生。
2.3 SVDD與證據理論的結合
支持向量機[9-10]描述在解決模式識別相關問題上具有明顯優勢,適用于高階、非線性、多維數的復雜問題。單一的決策理論可能會具備或多或少的缺陷,例如診斷決策精度不夠高。為此,可以任意選取部分決策,并將其與D-S理論進行深度融合。SVDD的概率輸出還不能直接用來進行融合,需要將其轉化為基本概率分配函數。
2.3.1SVDD的識別誤差的上界
定理:假設某個最優分類面或廣義最優分類面區分隨機測試樣本,那么訓練樣本分類錯誤概率期望的上界可用訓練樣本中支持向量平均值E(nsv)與總訓練樣本N的比值表示:
(6)
2.3.2模糊隸屬度的BPA輸出
如式(6)所示,不等式右側取等號時,可用于描述分類器SVDD對樣本x的隨機性。
所以,采用下述方法得到的分類SVDD的BPA輸出:首先求出各類支持向量個數的期望值,再由式(7)得出識別誤差最大值,最后用SVDD的精度最小值即SVDD隸屬度輸出進行加權處理,即可得到多分類SVDD證據理論識別框架下的BPA輸出。
(7)
mi(x)=fi(x)·(1-E(Perror))。其中,i=1,2,…,M。
3 基于SVDD和D-S理論的柴油機故障診斷實例
3.1 兩級信息融合的柴油機故障診斷模型
傳感器所采集信號越多,多信號處理方式的融入勢必會造成故障診斷特征參數的復雜化,訓練時間激增、學習樣本產生不可避免的矛盾,同時也提高了整個診斷計算過程的維度和階數。最終造成了SVDD模型泛化能力減弱、分類精度降低的現象。
為克服這些不足,提高故障診斷精度,本文提出基于特征級和決策級兩級融合的診斷模型進行故障診斷,其結構邏輯圖如圖2所示。首先,將各個傳感器的原始信號按照EEMD-SVD方法、階比雙譜方法、圖像處理方法等進行特征參數提取,然后對不同信號處理方法得到的特征參數進行SVDD模式識別,得到該組特征數據相對于不同SVDD分類器的模糊隸屬度輸出,再將其轉化為BPA輸出作為證據體進行決策級融合,即利用D-S證據理論,通過融合各種方法的決策信息,獲得更準確的診斷結果。
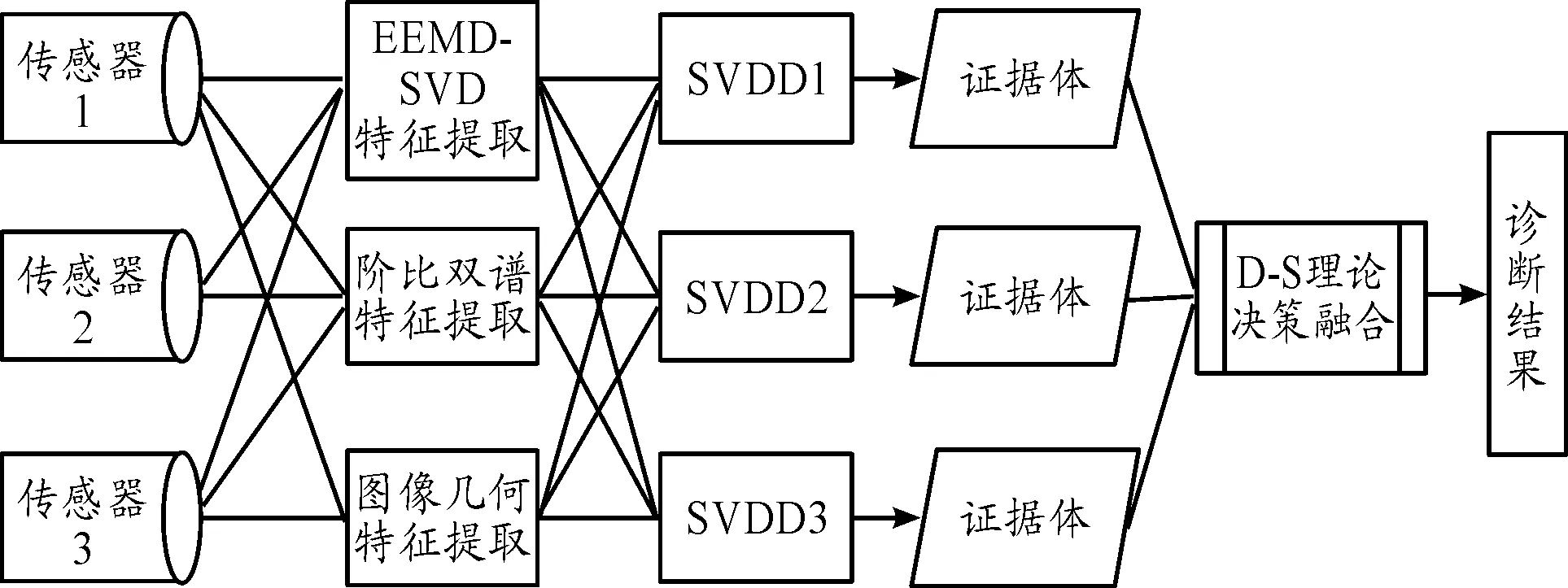
圖2 兩級信息融合診斷模型
信息融合的原理可以很好地解釋這一結論:各個傳感器將原始的裸數據不做任何處理直接進行特征提取,提取完成后輸出的特征參數傳送給相應的子模塊中,在其內部作出局部決策。子模塊的輸出則為相應的證據體子空間可作為故障樣本子空間,將這些故障樣本子空間進一步使用D-S證據理論進行決策融合,得到最終的診斷結果。在此過程中融合進行了2次,既可以高效利用大部分數據,又能解決通訊帶寬的問題,使得診斷系統的精確性和穩定性得到改善。
3.2 基于兩級信息融合技術的曲軸軸承故障診斷
采用上述方法對曲軸軸承故障進行診斷,傳感器選取601 A01型ICP工業加速度傳感器,采集相應的振動信號,安裝位置如圖3所示。
曲軸軸承配合間隙分別設置為0.08、0.1、0.2、0.4 mm(分別對應正常、輕微、中度、嚴重等不同級別的磨損),發動機轉速設為1 800 r/min,采樣頻率設為12 800 Hz,采集柴油機缸體與油底結合處左右兩側位置處(位置D、E)發動機振動信號與正常工況的振動信號進行比較分析。
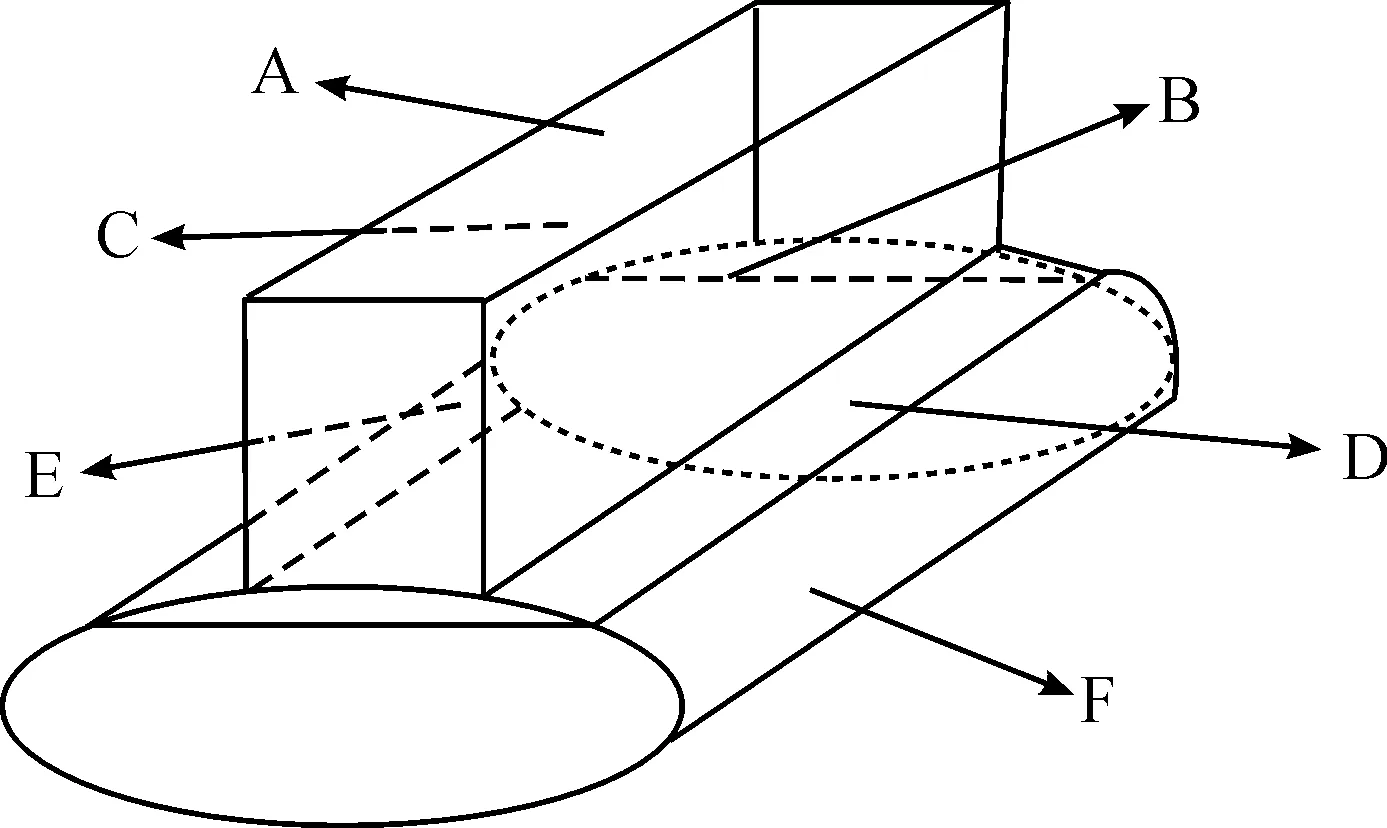
A-第三缸頂;B-缸體上部第三缸右側;C-缸體上部第三缸左側;D-油底與缸體結合處第三缸右側;E-油底與缸體結合處第三缸左側;F-第三缸油底下部
圖3 加速度振動傳感器放置位置
采用不同的特征提取方法提取出特征參數集,經過粗糙集理論優化后,與SVDD算法結合,構成一種分類器。多少組診斷數據輸入,就會得到不同分類器下的多少組證據體輸出。表1、表2和表3列出了5組樣本所構成的證據體,表中F1、F2、F3、F4分別表示相應的軸承分析對象的磨損狀態。以5組樣本說明信息融合過程及融合效果,集體步驟如下:
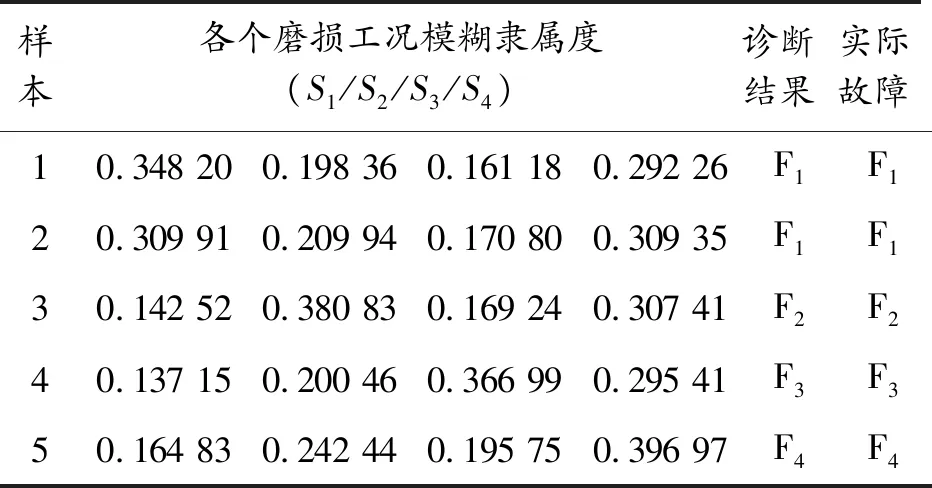
表1 EEMD-SVD方法SVDD模型的曲軸磨損診斷結果
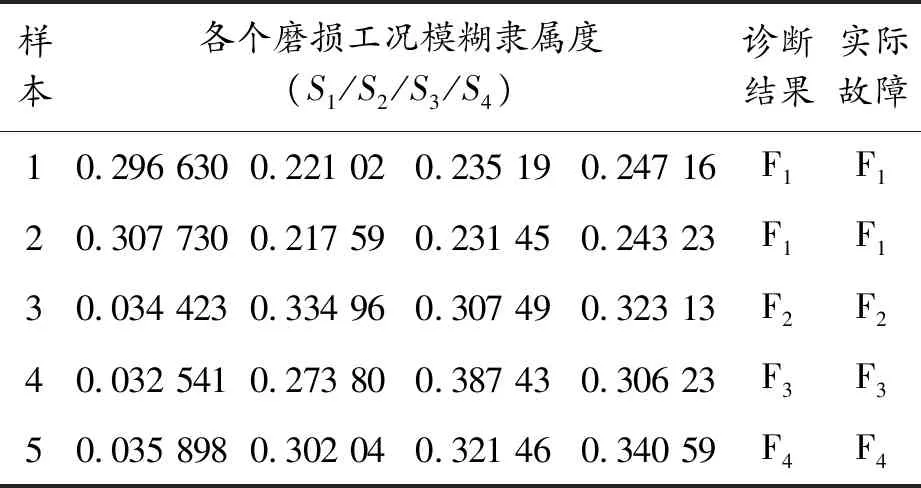
表2 階比雙譜方法SVDD模型的曲軸磨損診斷結果
1) 將3個SVDD分類器的隸屬度輸出分別轉化為不同證據體下的BPA值。首先,根據式(7)計算得到不同分類器的隨機性。例如,采用EEMD-SVD方法提起信號特征的SVDD多分類器,訓練樣本數為40組,訓練SVDD多分類器得到支持向量的個數為33個,可以計算支持向量個數均值為8.25,代入式(7),計算得到分類器SVDD1的隨機性為0.211 6;然后根據式(8)計算證據體的BPA 值,例如樣本數據1在多分類器SVDD1的隸屬度概率輸出分別為0.348 2、0.198 36、0.161 19、0.292 26,即取值為0.348 2、0.198 36、0.161 19、0.292 26,對隸屬度輸出進行加權處理后,即可得到數據1在證據體BPA值分別對0.274 5、0.156 4、0.127 1、0.230 4按照同樣的處理方法得到樣本數據1~5在3個分類器對應證據體的BPA值,如表4~6所示。
2) 得到樣本數據1~5在3個分類器對應證據體的BPA之后,按照D-S理論中合成規則公式(5)得到分類器1、分類器2對應的證據體融合后的BPA,然后再將2個證據體融合后的BPA與分類器3對應的BPA進行融合,即可得到3個分類器相應證據體合成后的BPA合成后的結果,如表7所示。

表3 圖像處理方法SVDD模型的曲軸磨損診斷結果

表4 SVDD1基本概率分配函數值

表5 SVDD2基本概率分配函數值

表6 SVDD3基本概率分配函數值

表7 決策層融合診斷結果
按照上述步驟,對其余195組測試樣本中的3個分類器隸屬度輸出分別轉化為不同證據體下的BPA值,然后按照D-S理論中的合成規則公式進行融合,可以得到全部測試樣本的診斷結果。經統計,在全部的200組測試樣本中,有186組樣本得到正確的分區,14組誤判,判斷正確率為93%。
4 結論
柴油機系統復雜且不穩定,導致了故障部位與故障特征的多樣性,對其進行精確故障診斷存在的技術難點在于:故障部位與故障特征之間沒有明確的對應關系,即一個故障部位可能產生多個故障特征,一個故障特征可能與多個故障部位相關聯。這樣采用單一傳感器獲取信息,或采用單一信號處理方法進行故障診斷的精確度將十分有限。本文充分利用多傳感器采集信號、多故障特征提取方法、不同分類器處理結果獲得各種冗余互補信息。使用SVDD方法改進D-S證據理論,并建立兩級融合模型進行驗證,實現多等級、多層次的診斷。且與圖像處理、階比雙譜等方法進行實驗對比。結果表明,此方法的診斷精度和穩定性優勢明顯提高。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
汽車維修與保養(2019年7期)2020-01-06 03:30:42
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
