基于改進BIRCH聚類算法的評價對象挖掘
2019-12-19 02:07:13王夢遙王曉曄洪睿琪
軟件 2019年11期
王夢遙 王曉曄 洪睿琪

摘? 要: 本文對于意見挖掘領域中的評價對象的修剪和聚類問題,提出使用K-means聚類算法和BIRCH聚類算法相結合的方式來進行評價對象的修剪和聚類。利用BIRCH算法類別聚類的功能對評價對象進行聚類,并刪除包含較少數據的簇來實現修剪評價對象;再通過對于剩下的簇使用K-means聚類算法來獲得最優評價對象。這種修剪聚類方法與以往的基于PMI算法修剪然后基于K-means聚類算法相比,減少了評價對象修剪時對語料庫的依賴,最終聚類的結果更加精準,而且BIRCH算法采用一次掃描數據庫的策略,可以有效提高速度。
關鍵詞: 名詞詞組模式;BIRCH聚類算法;K-means聚類算法;PMI算法
【Abstract】: For the pruning and clustering evaluation objects in opinion mining, this paper proposes a method that combines BIRCH clustering and K-means clustering algorithm to prune and cluster evaluation objects. Firstly, utilizing BIRCH algorithm of self-learning cluster category, after clustering by BIRCH algorithm, delete the clusters containing few data so that we can prune the evaluation objects. Then use K-means clustering algorithm to make global cluster for the remaining clusters. Compared with pruning using PMI algorithm and clustering using K-means clustering algorithm, our method eliminates the dependency on the corpus. And the cluster result is more accurate. Also BIRCH algorithm scans the database one time, so it can increase the speed greatly.
【Key words】: Noun phrase pattern; BIRCH clustering algorithm; K-means clustering algorithm; PMI algorithm
0? 引言
隨著電子商務行業的發展,網購在人們生活中起到越來越重要的作用,用戶通過查看購物網站的評論信息來對商品有更加全面的了解。但同一產品在網絡中的評論可能會達到成千上萬條,給用戶全部逐條查看帶來了極大的麻煩,這基本是不可能實現的。而且評價信息數據量雖然極大,但信息量稀疏,也就是說不是所有的句子都是有用的,這又使得用戶評論的參考價值大大降低。因此,挖掘用戶評論提取出有用信息供給用戶查看就顯得十分必要了。
評論信息的意見挖掘是從評論信息中提取主題詞的過程,主題詞包括評價對象,然后對評價對象進行處理分析。目前對評價對象處理的方法有很多,比如,張俊飛[1]等人,通過改進PMI算法實現特征值提取,利用TF-IDF函數實現特征值權重計算,實現基于PMI特征值TF-IDF加權樸素貝葉斯算法;陳海紅等人[2],利用信息增益法進行文本特征選取,運用TF-IDF進行特征權重設置,對支持向量機使用不同核函數,通過網格與交叉驗證組合法優化參數選擇,比較支持向量機在不同核函數下文本分類性能;為了減少數據集和訓練方法對詞向量質量的影響,王子牛、吳建華、高建瓴等人[3]提出了深度神經網絡結合LSTM模型來實現情感分析;林欽、劉鋼[4]等人采用關聯算法挖掘商品特征的算法實現領域詞典的半自動更新;孟鑫[5]等人在通用領域詞典的基礎上,增添領域情感詞及其情感強度值,通過計算詞語相似度,構建專用領域情感詞典;李春婷[6]等人將模糊認知圖理論應用于詞語聚類,實際上屬于基于神經網絡的聚類方法。
在前人研究的基礎上,本文采用名詞詞組模式來提取主題詞,然后使用BIRCH算法[7]與K-means聚類算法[8]相結合的方法對評價對象進行修剪和聚類[9]。
1? 主題詞的抽取
主題詞抽取首先對評論信息進行預先處理。處理工作主要分兩個部分:評論中經常會包含明顯的無效信息,比如,QQ號、電話號碼或網址的句子有做廣告的嫌疑,重復出現的句子沒有意義,首先將這類評論刪除。之后是對句子進行分詞和詞性標注,由于我們主要依靠形容詞判斷句子情感,所以刪除不含有形容詞的評論。分詞采用中科院的分詞工具ICTCLAS2015[10]。
抽取主題詞[11]的關鍵在于評價詞和評價對象的抽取。對于評價對象的抽取,總結為對名詞、動名詞、名詞短語的抽取,本文通過分析句式,構建了以下四種名詞詞組形式:n和n和n、n和n、n的n、nn或n,進而對句子進行匹配并抽取主題詞。具體抽取步驟如下:
(1)使用上面幾種名詞詞組對于評論中的分句進行匹配,根據此來確定評價對象,并同時匹配形容詞或其他詞性來抽取評論信息;
(2)若分句中只有評價詞而沒有評價對象,則將其前面分句中的評價對象作為該分句的評價對象;若前面分句也沒有評價對象,則該分句中的評價對象為隱式的,此時通過創建評價詞和評價對象的語義集的方法來確定隱式評價對象。
(3)若分句中只有評價對象沒有評價詞,則保存,如果后續沒有評價對象,則將其作為此分句中評價詞的評價對象;
(4)本文采取建立語義相關集的方法來抽取隱式評價對象,如下:
1)統計已抽取出的評價詞和評價對象在評論中出現的次數,選取出現次數最高的90個評價詞和45個評價對象;
2)統計每一對評價詞和評價對象共同出現的次數;
3)對于每一個評價對象,選擇其對應的出現次數最高的45個評價詞,以它們的組合詞對組成語義相關集,對應的評價對象通過使用已抽取出的評價詞搜索語義相關集來確定。
2? 主題詞的修剪及聚類
有些抽取出的評價對象與商品無關,需要去掉。比如“淘寶網很棒”這句話,雖然評價詞“棒”被抽取出來,“淘寶網”也被作為評價對象提取,但這一分句并未對商品的屬性做出評價。所以需要去掉這些冗余數據后,再對剩下的數據聚類以得到最終評價對象。
2.1? BIRCH算法的預聚類
BIRCH(Balanced Iterative Reducing and Clustering using Hierarchies)利用層次方法的平衡迭代規約和聚類。它使用聚類特征(Clustering Feature, CF)和聚類特征樹(CF Tree)兩個概念,用于概述聚類。聚類特征樹概括了聚類的使用信息,并且占用空間較原來數據集小得多,可以存儲在內存中,從而可以提高算法在大型數據集上的速度及伸縮性。關于BIRCH聚類算法,數據的插入順序對聚類特征樹的構建影響很大,所以本文通過對初始數據集進行預聚類的方法,首先已知數據集合插入順序,再將數據按照順序插入來構造聚類特征樹。在預聚類階段采用的算法是K-means算法,因為該算法效率高、實規定現簡單、復雜度較低,不會在初始階段增加BIRCH算法的復雜度。
為了將語言數學化,首先將所有評價對象轉化為詞向量,具體步驟如下:選取提取到的最高頻次的15個評價詞,該評價對象與這15個評價詞在評論中出現的次數即可用向量中的元素值來表示。比如,本文針對“手機”評論挑選的評價詞包括:“流暢”、“使用穩定”、“操作方便”、“美觀”、“速度快”等共15個評價詞,而“攝像頭”這個評價對象表示成向量為[443, 227, 201, 145, 88, 129, 49, 55, 60, 41, 38, 42, 53, 44, 95],向量中的元素代表“攝像頭”與評論中15個評價詞共同出現的次數。
對于K-means聚類算法的初始質心如何選擇的問題,采用最大距離法[12],保證各質心不屬于同一類并且之間的距離盡量大。在計算各數據點之間的距離時,采用歐幾里得距離的方法。算法的具體細節見文獻[13]。
2.2? BIRCH聚類算法
關于BIRCH聚類算法中的幾個閾值[14,15],直徑閾值T的確定如下:從數據集里選取N個數據,分別計算每兩個數據之間的距離,計算這些距離的方差值DX和期望值EX,則閾值T = EX + 0.25 × DX。對于確定葉子節點的子節點個數L以及非葉子結點的子節點個數B,通過抽取部分數據作為測試集,反復實驗,得到實驗結果最好時的L和B值。
CF樹建完以后,每個葉節點包含的數據點就是一個簇,刪除所含節點數很少的簇,因為這些數據很可能是抽取出來的與商品無關的特征。由于BIRCH算法中閾值的限制,CF樹每個節點只能包含一定數量的子節點,最后得出來的簇可能和真實結果差別很大,所以需要對BIRCH聚類算法得出的聚類的結果進行全局聚類。本文采用K-means聚類算法進行全局聚類。
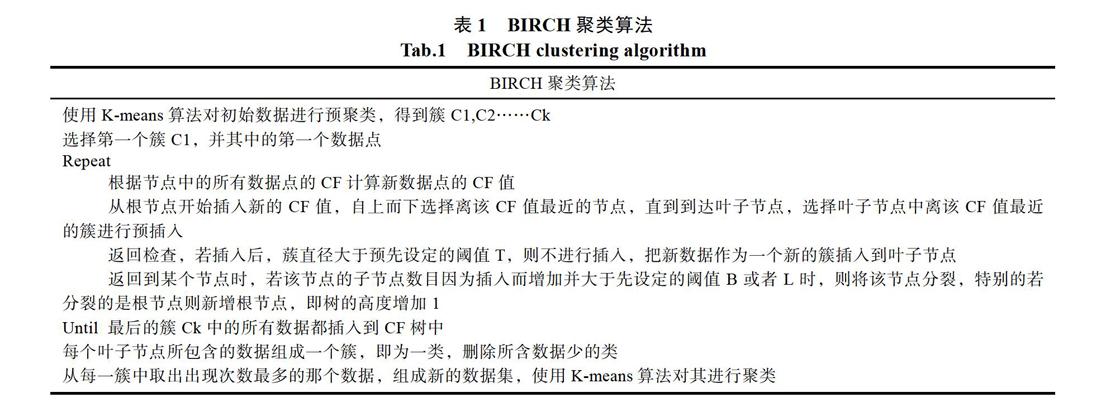
BIRCH算法步驟如表1所示。
3? 實驗分析
3.1? BIRCH算法與PMI算法修剪評價對象實驗對比分析
本文使用的實驗數據是京東商城上手機的評論信息,共計1萬條數據。
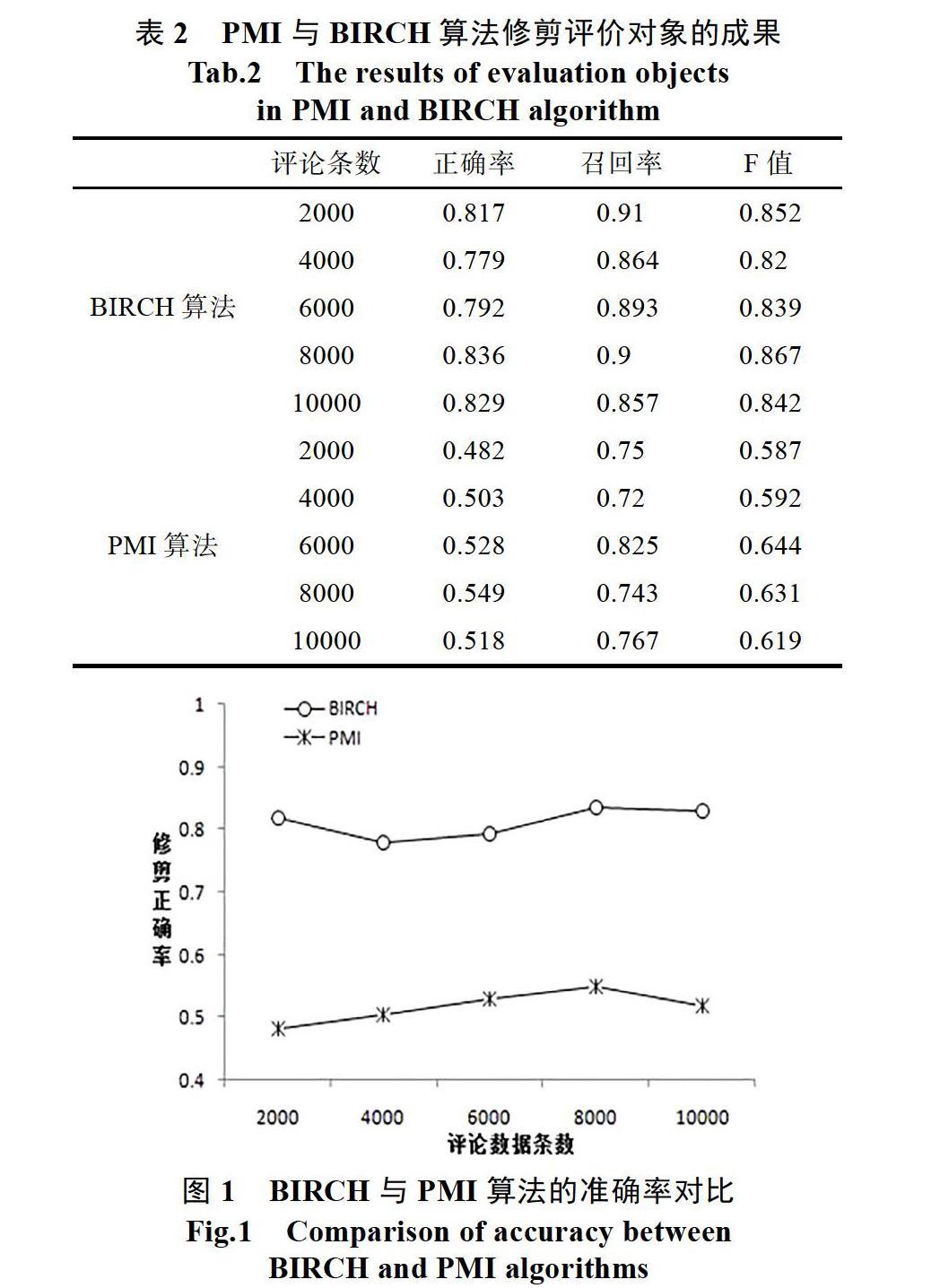
為了驗證BIRCH算法修整評價對象的效果,本文用它和常用的PMI算法修剪評價對象的結果進行對比,通過分析兩種方法的準確率、F值和召回率,進而判定本文方法的效果。正確率就是對于操作出來的數據中正確操作的數據所占的比例,召回率是對于總樣本數據中正確操作的數據所占的比例,F值是二者的綜合指標。
實驗中BIRCH聚類算法中不是葉子結點的子結點個數B為10,簇的直徑閾值T為3.9,葉子節點的子結點個數設定為15,將PMI算法中的修剪閾值設為0.3。將1萬條數據分為五個數據部分:2000條、4000條、6000條、8000條、10000條,上述兩種方法在不同數據段上的實驗結果如表2和圖所示,使用BIRCH算法的修剪準確率明顯高于PMI算法,因為PMI算法對閾值和語料庫有非常大的依賴,需要綜合的語料庫作支撐,本實驗選取的是微軟開發的必應搜索引擎的語料庫,但如果同時增大語料庫,時間復雜度將會增加。
3.2? BIRCH聚類算法實驗分析
以往對評價對象進行聚類采用的方法主要是兩種:一種是通過創建商品屬性集合以及屬性常用的表達方式來組成映射集,然后對每個評價對象確定最終評價對象時,搜尋映射集來確定;另一種方法也是使用聚類算法,比如K均值聚類算法。本文為了驗證將BIRCH聚類算法應用于評價對象聚類方面的有效性,將其與上述兩種方法的正確率進行實驗對比分析。
首先是映射集方法,實驗建立的映射集部分如表2。
使用K-means算法進行屬性統一時,將評價對象聚為13類,然后選擇相對較集中的簇并且簇中數量較多的作為最終評價對象,結果為“手機”、“性價比”、“快遞速度”、“使用感受”、“散熱”、“聲音”、“外觀”、“服務”。
在對上節的BIRCH算法得出的每一簇,選擇出現頻率最高的數據來組成數據集,使用K-means算法進行聚類,即完成了本文中方法的實驗。最后,對這三種方法的結果進行對比,圖1展示了三種方法在評論數據集分別在2000、4000、6000、8000和10000條時的正確率。
