我國農業機械化作業水平的組合預測模型對比研究
2019-12-21 07:25:26李鵬飛呂恩利陸華忠陳明林
農機化研究 2019年3期
李鵬飛,呂恩利,陸華忠,陳明林,荀 露
(華南農業大學 工程學院/南方農業機械與裝備關鍵技術教育部重點實驗室,廣州 510642)
0 引言
農業機械化是影響我國農業現代化進程、制約農業國際競爭力提高的主要因素[1],農業機械化作業水平是衡量農業機械化發展水平的重要指標。因此,科學有效地分析我國農業機械化的發展趨勢,精準預測農業機械化作業水平的增長幅度,是合理制定農機規劃的基礎,對于保障我國農業機械化穩定有序的發展具有重要的現實意義。
目前,國內外已提出的關于農業機械化作業水平的預測方法主要有回歸分析法、指數平滑法、平滑移動法、灰色模型法,以及人工神經網絡等[2-4]。單項預測模型雖各有優勢但均有特定的適用環境,僅利用某一種預測模型,預測結果往往偏差較大。綜合考慮各單項模型預測時的局限性,Bates和Granger[5]首次提出組合預測的方法,鑒于單項預測方法各自的特點,將不同單項預測方法進行加權組合,使最終預測結果能夠包含各單項預測方法中有效的信息,具有很強的適應性和較好的穩定性[6]。
組合預測模型的權重分配對預測精度有重要的影響,合理地確定權重是構建組合預測模型的關鍵。誤差平方和最小法是一種傳統的線性加權的方法,以整體最優為目標,在實際中有廣泛的應用;Shapley法是一種基于博弈理論中利益分配機制的賦權方法,以公平性為原則,對各單項預測模型進行權重分配;IOWGA法是一種通過誘導值將決策結果進行算數加權集成的方法。目前,尚未發現有關上述3種組合預測模型對比的相關研究。因此,本文以我國農業機械化作業水平時間序列為研究對象,基于提高預測精度的目的,建立了指數曲線預測模型、三次指數平滑模型和灰色預測模型,綜合利用各單項模型所提供的有效信息,以誤差平方和最小法、Shapley法和IOWGA法建立組合預測模型,通過評價指標比較各組合預測模型的預測效果和穩定性,探討我國農業機械化作業水平較優的組合預測方法,以期為我國農業機械化發展規劃提供科學依據。
1 組合模型的構建
組合預測方法是指選取合理的權重并將多種單項模型的預測結果進行加權組合的方法[7-8],可以綜合各單項模型具有的信息,集成并優化各單項模型的預測結果,使得預測精度大大提高[9]。
1.1 誤差平方和最小法[10]
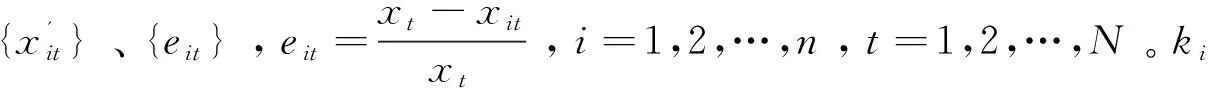
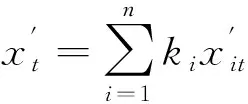
設J表示組合預測相對誤差平方和,即
由此可得到以相對誤差平方和最小為準則的組合預測模型,即
該模型可轉化為矩陣形式,作為非線性規劃問題,并且是二次凸規劃問題,具有唯一最優解[11]。
1.2 Shapley法[12]
Shapley法[13]是Shapley教授從有效性公理、對稱性公理和可加性公理出發,提出的合作對策解的概念[14],通過團隊中各成員的貢獻程度反映各成員的重要性[15],實現總利潤在團隊中各成員間的公平分配。將各單項預測模型視為合作關系,把組合預測產生的總誤差視為合作的總收益,通過Shapley值實現總收益的公平分配,利用分配的結果來確定各單項預測方法在組合預測模型中的權重[16]。
設單項預測方法共有n種,記為I=1,2,…,n;s代表集合I中的任何子集;Es為該子集組合的誤差;Ei表示第i種單項預測方法相對誤差絕對值的平均值;E表示組合預測方法的總誤差,即
其中,t為觀測樣本個數;eij為第i種單項預測方法第j個數據的相對誤差。
Shapley值和權重分配公式分別為
其中,s為集合I中的任何子集;s為單項預測模型的數量;ω|s|為權重因子;s-i為組合中除去第i種單項預測模型。
第i種單項預測模型的權重計算公式為
因此,Shapley組合預測模型為
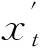
1.3 IOWGA法
目前,在大多數的組合預測模型中,一般通過各種方法計算出組合預測模型中各單項的權系數,并在預測階段,假定權系數不變[17-20]。然而,各單項預測方法對同一預測對象的預測效果往往隨時間而改變,固定權系數組合不能較好地反映各單項預測模型的時變性。針對上述問題,美國學者Yager[21]提出有序加權平均OWA的概念,即權重分配由各單項預測模型在不同時刻的預測精度決定,克服了傳統加權方法的弊端[22]。隨著相關理論研究的不斷深入,陳華友等[23]提出了誘導有序加權幾何平均(IOWGA)的概念,使得權重分配更加合理,組合模型預測精度進一步提高。
定義1:設R+為正實數集,OWGAW:R+n→R+為n元函數,W=ω1,ω2,…,ωmT是與OWGAW有關聯的指數加權向量,令
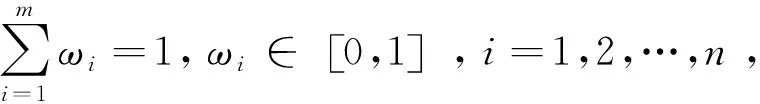
由定義1可知:權系數ωi與序列x1,x2,…,xm中數xi無關,而是與序列x1,x2,…,xm按從大到小進行排序后的第i個位置數bi密切相關。
定義2:設〈a1,x1〉,〈a2,x2〉,…,〈am,xm〉為m個二維數組,令
IOWGAW〈a1,x1〉,〈a2,x2〉,…,〈am,xm〉=
其中,a-indexi為a1,a2,…,am中從大到小的順序排列的第i個大的數的下標。
稱函數IOWGAW是由a1,a2,…,am所產生的n維誘導有序加權集合平均算子,簡記為IOWGA,ai成為xi的誘導值。

定義3:表明權系數ωi與序列x1,x2,…,xm中數xi的大小和位置無關,而是與其誘導值按從大到小進行排序后的第i個位置有關。
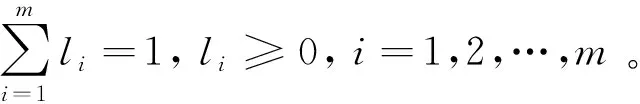
i=1,2,…,m;t=1,2,…,N
其中,pit為第i種單項預測方法在第t時刻的預測精度,pit∈0,1。與預測值xit對應的預測精度pit視為其誘導值,則m種單項預測方法在第t時刻的預測精度和其對應樣本區間的預測值就構成了m個二維數組,即
〈pit,x1t〉,〈p2t,x2t〉,…,〈pmt,xmt〉。
設L=l1,l2,…,lmT為單項預測方法在組合預測中的OWGA的加權向量,將m種單項預測方法在t時刻的預測精度序列p1t,p2t,…,pmt按從大到小的順序進行排列,設p-indexi是第i個大的預測精度的下標,令
IOWGAL〈p1t,x1t〉,〈p2t,x2t〉,…,〈pmt,xtm〉=
i=1,2,…,m;t=1,2,…,N
由上式可知:IOWGA組合模型將各單項模型在不同時刻的預測精度作為誘導值進行賦權,使得單項模型各時刻的權重與其該時刻的擬合精度相關聯,更具有實際意義。
為了簡化計算,將取對數誤差平方和作為優化準則,令ea-indexit=lnxt-lnxp-indexit。
N期總的組合預測對數誤差平方和S為
基于對數誤差平方和最小的準則,IOWGA算子組合預測模型為
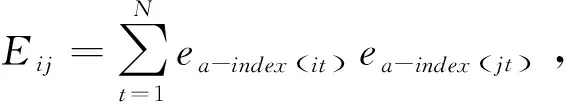
minSL=LTEL
2 算例分析
2.1 數據來源
本文采用的是2000-2015年我國農業機械化作業水平的年度數據,數據來源于《中國農業機械化年鑒》,如表1所示。各單項預測模型均以2001-2012年的數據作為訓練樣本,對2013-2015年的數據進行預測檢驗。
2.2 評價指標
為了對組合預測模型給予有效的評價,本文采用平均相對誤差MAPE和均方根誤差RMSE為評價指標。則
2.3 單項預測模型的建立
我國農業機械化作業水平是一個時間序列,其數值的變化具有波動性,以增長為主要趨勢。選擇指數曲線法、三次指數平滑法和灰色預測法建立我國農業機械化作業水平單項預測模型。
2.3.1 指數曲線模型
由于社會的進步與科技的發展,我國農業機械化作業水平隨著時間的推移呈現明顯的快速增長趨勢。由表1可知:我國農業機械化作業水平與時間近似滿足指數關系,通過SPSS軟件對2001-2012年的歷史數據進行指數曲線擬合,得到預測模型如下,相關系數R為0.955,表明我國農業機械化作業水平與時間具有較強的相關性,即
y=2.788×10-47e0.053x
其中,x為時間變量;y為對應年份的農業機械化作業水平預測值。
2.3.2 三次指數平滑模型[24]
指數平滑預測法可細分為一次、二次、三次指數平滑預測法,綜合考慮歷史數據的變化趨勢,本文采用三次指數平滑法。
設原始數據所組成的時間序列為X=x1,x2,…,xn,則三次指數平滑模型為
yt+T=at+bt·T+ct·T2
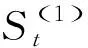
平滑系數的計算公式為
其中,α代表模型對時序變化的反應速度[25]。本文經反復測算和比較后,綜合考慮評價指標,選取α=0.8。
本文建模數據量較小,初始值對預測效果影響較大,所以采用平均數法求平滑初始值,即
將2001-2012年,農業機械化作業水平歷史數據代入,求得at、bt、ct的值及2001-2012的預測值。此外,令t=2012,得到公式如下,求得2013-2015年的預測值如表1所示。
y2012+T=0.5717+0.0218T-0.0016T2
2.3.3 灰色模型[26]
灰色預測是對原始序列發展變化進行深入探索,生成有較強規律性的數據序列,建立微分方程模型,預測時序未來發展趨勢[27]。灰色模型適用于樣本量較少情況下的時序預測。
設原始灰色時間序列為x0,則
x0=x01,x02,…,x0n
對其進行一次累加得到新序列x1,即
對新序列x1建立白化微分方程,得
其中,a、b為待估計參數;t為時間。
求解上式得到時間響應模型為
i=1,2,…,n-1
按最小二乘法求解參數a和b,則有
由此得到模型還原值為
i=1,2,…,n
將2001-2012年農業機械化作業水平歷史數據代入上述預測模型,求解待估計參數a、b,得到灰色預測模型為
i=1,2,…,n-1
通過上式對2013-2015年我國農業機械化作業水平進行擬合,并得到還原值,結果如表1所示。
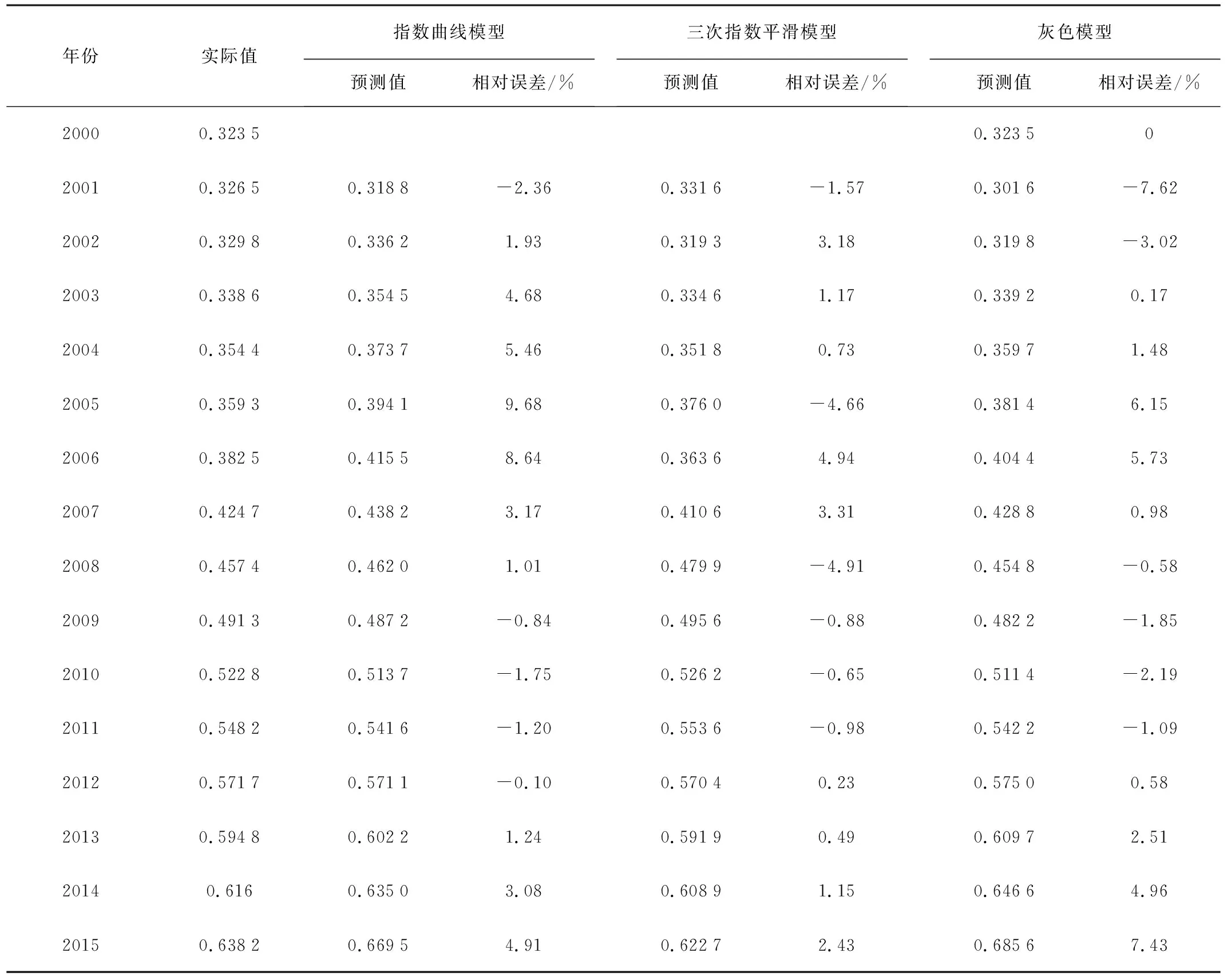
表1 3種單項模型的預測結果
2.4 組合預測模型的建立
2.4.1 誤差平方和最小模型
通過MatLab平臺計算得到基于誤差平方和最小的組合預測模型為
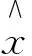
2.4.2Shapley模型
根據Shapley概念,參與組合預測模型總誤差分配的成員為I=1,2,3,它所有子集的組合誤差分別為E1、E2、E3、E1,2、E1,3、E2,3、E1,2,3。
求得各成員的Shapley值,并計算各單項預測模型的權重,Shapley值組合預測模型為
2.4.3 IWOGA模型
按照表1中的預測結果,計算出各單項模型在各時刻所對應的預測精度,并視為誘導值,利用MatLab解得最優權系數為l1=0.6352,l2=0.3648,l3=0。
其中,l1、l2、l3為3個單項模型預測精度從高到低的單項模型賦權重。
根據表1的數據,通過預測連貫性的原則,即各個單項預測模型在未來的第N+T年的預測精度與其過去的T年內的平均預測精度保持一致[28],推測出各單項預測模型2013-2015年可能的預測精度狀態,從高到低進行排序,排序結果如表2所示。

表2 2013-2015年各單項模型預測精度的排序結果
2.5 結果與分析
誤差平方和最小、Shapley、IWOGA3種組合預測模型對2013-2015年農業機械化作業水平進行預測,預測結果如表3所示。
由表3可以看出:組合預測模型對我國農業機械化作業水平的總體預測精度較高,觀測值與預測值吻合性較好,相對誤差均在3%范圍內。IOWGA組合模型的預測精度較高,平均相對誤差僅為0.003 9,誤差平方和最小模型次之,Shapley模型的預測性能較低。通過均方根誤差的結果可知,IOWGA組合預測模型不僅誤差較小,誤差分布也較集中。
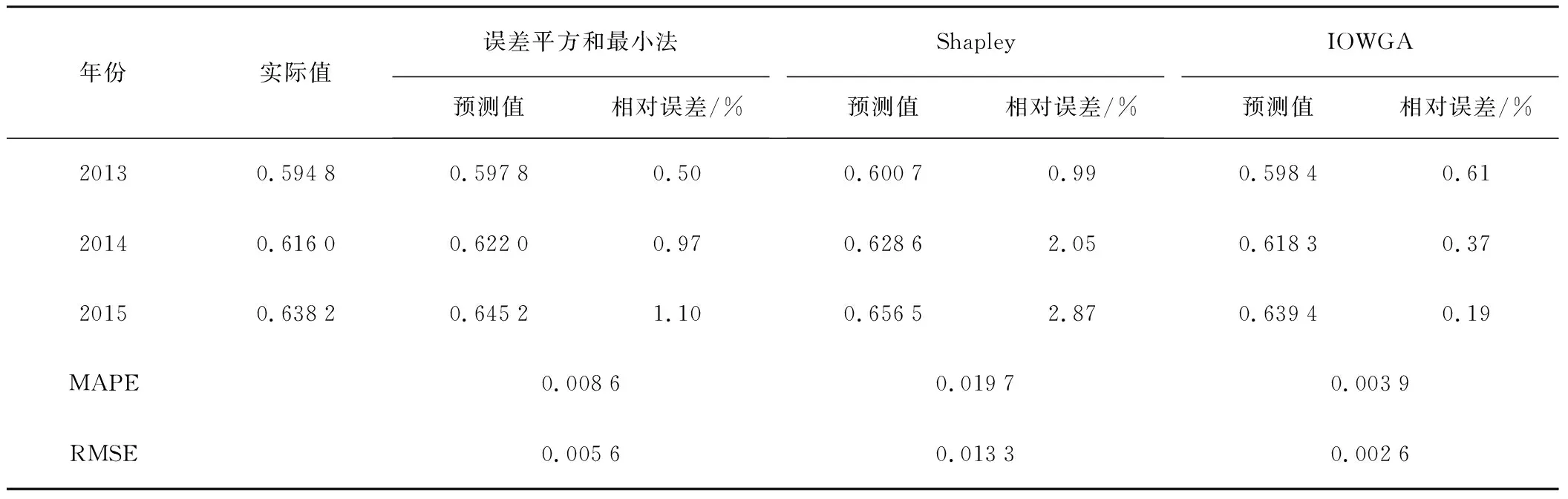
表3 2013-2015年各組合模型的預測結果
3 結論
1) 組合模型可以綜合利用3個單項模型的有效信息,適用于我國農業機械化作業水平的預測。
2) 利用評價指標對3種組合預測模型的預測精度進行對比,IOWGA組合預測模型精度最高,誤差平方和最小,預測模型次之,Shapley組合預測模型精度較低。
3) IOWGA組合模型按照各單項模型各時刻的擬合精度的高低進行有序賦權,克服了傳統賦權方法的弊端,能較好地模擬農業機械化作業水平的發展情況,具有較強的可靠性和較高的實用價值。
猜你喜歡
今日農業(2022年1期)2022-11-16 21:20:05
今日農業(2022年3期)2022-11-16 13:13:50
今日農業(2022年2期)2022-11-16 12:29:47
美與時代·美術學刊(2022年3期)2022-04-27 01:18:15
今日農業(2021年14期)2021-11-25 23:57:29
少年博覽·初中版(2020年6期)2020-06-12 11:42:23
人大建設(2019年12期)2019-05-21 02:55:32
故事大王(2016年7期)2016-09-22 17:30:08
兒童故事畫報(2013年3期)2013-06-24 05:40:30
中國火炬(2010年8期)2010-07-25 11:34:30
