時空域上下文學習的視頻多幀質量增強方法
2020-01-02 09:07:54佟駿超吳熙林丁丹丹
北京航空航天大學學報 2019年12期
佟駿超,吳熙林,丁丹丹
(杭州師范大學 信息科學與工程學院,杭州311121)
過去幾年,視頻逐漸成為互聯網的主要流量,根據思科白皮書預測,到2020年,互聯網有近80%[1]流量為視頻。未經壓縮的視頻體積大,給傳輸和存儲都帶來巨大挑戰。因此,原始視頻一般都經過壓縮再進行傳輸或存儲。然而,視頻壓縮會帶來壓縮噪聲,尤其在帶寬嚴重受限的情況下,壓縮噪聲嚴重地影響了用戶的主觀體驗。這時,有必要在解碼端再次提升壓縮視頻的質量。
針對圖像或視頻質量增強,國內外已有不少研究。Dong等[2]設計了減少噪聲的卷積神經網絡(Artifacts Reduction Convolutional Neural Network,ARCNN),減少了JPEG壓縮圖像所產生的噪聲。之后,Zhang等[3]設計的去噪神經網絡(Denoising Convolutional Neural Network,DnCNN),具有較深的網絡結構,實現了圖像去噪,超分辨率和JPEG圖像質量增強。后來,Yang等[4]設計了解碼端可伸縮卷積神經網絡(Decoder-side Scalable Convolutional Neural Network,DSCNN),該結構由2個子網絡組成,分別減少了幀內編碼與幀間編碼的失真。然而,上述方法都僅利用了圖像的空域信息,沒有利用相鄰幀的時域信息,仍有提升空間。Yang等[5]嘗試了一種多幀質量增強(Multi-Frame Quality Enhancement,MFQE)方法,利用空域的低質量當前幀與時域上的高質量相鄰幀來增強當前幀。同等條件下,MFQE獲得了比空域單幀方法更好的性能。
在視頻序列中,盡管幀之間具有相似性,但仍存在一定的運動誤差。Yang等[5]所提出的MFQE做法是首先借助光流網絡,得到相鄰幀與當前待增強幀之間的光流場;然后根據該光流場對相鄰幀進行運動補償,即相鄰幀內的像素點,根據光流信息,向當前幀對齊,得到對齊幀;最后,將對齊幀與當前幀一起送入后續的質量增強網絡。上述方法能夠取得顯著增益,但也有一些不足:
1)視頻幀之間的運動位移不一定恰好是整像素,有可能是亞像素位置,一般的做法是通過插值得到亞像素位置的像素值,不可避免地會產生一定誤差。也就是說,根據光流信息進行幀間運動補償的策略存在一定的缺陷。
2)MFQE利用了當前幀前后各一幀圖像對當前幀進行增強,增強網絡對應的輸入為3幀圖像,包括當前幀與2個對齊幀。視頻序列由連貫圖像組成,推測,如果在時域采納更多幀則會達到更好效果,這就意味著需要根據光流運動補償產生更多對齊幀,神經網絡的復雜度與參數量也會急劇上升,并不利于訓練與實現。
考慮到上述問題,本文提出一種基于時空域上下文學習的多幀質量增強方法(STMVE),該方法不再從光流補償,而是從預測的角度出發,根據時域多幀得到當前幀的預測幀,繼而通過該預測幀來提升當前幀的質量。在預測時,在不增加網絡參數與復雜度的情況下,充分利用了近距離低質量的2幀圖像、遠距離高質量的2幀圖像,顯著提升了性能。
本文的主要貢獻如下:
1)在多幀關聯性挖掘方面,與傳統的基于光流進行運動補償的方法不同,STMVE方法根據當前幀的鄰近幀,得到當前幀的預測幀。具體地,使用自適應可分離的卷積神經網絡(Adaptive Separable Convolutional Neural Network,ASCNN)[6],輸入時域鄰近圖像,通過自適應卷積與運動重采樣,得到預測幀。該方法極大地縮短了預處理時間,并且預測圖像的質量也得到了明顯的改善。
2)在增強策略方面,提出多重預測的方式,充分利用當前幀的鄰近4幀圖像。將該4幀圖像分為2類:近距離低質量的2幀圖像與遠距離高質量的2幀圖像。這2類圖像對當前幀的質量提升各有優勢,設計神經網絡結構并通過學習來結合其優勢,獲得更佳性能。
3)在多幀聯合增強方面,提出了一種時空域上下文聯合的多幀卷積神經網絡(Multi-Frame CNN,MFCNN),該結構采用早期融合的方式,采用一層卷積層將時空域信息融合,而后通過迭代卷積不斷增強。整個網絡利用全局與局部殘差結構,降低了訓練難度。
1 相關工作
1.1 基于單幀的圖像質量增強
近年來,在提升壓縮圖像質量方面涌現出大量工作。比如,Park和Kim[7]使用基于卷積神經網絡(Convolutional Netural Network,CNN)的方法來替代H.265/HEVC的環路濾波。Jung等[8]使用稀疏編碼增強了JPEG壓縮圖像的質量。近年來,深度學習在提高壓縮圖像質量方面取得巨大成功。Dong等[2]提出了一個4層的ARCNN,明顯提升了JPEG壓縮圖像的質量。利用JPEG壓縮的先驗知識以及基于稀疏的雙域方法,Wang等[9]提出了深度雙域卷積神經網絡(Deep Dualdomain Convolutional netural Network,DDCN),提高了JPEG 圖像的質量。Li等[10]設計了一個20層的卷積神經網絡來提高圖像質量。最近,Lu等[11]提出了深度卡爾曼濾波網絡(Deep Kalman Filtering Network,DKFN)來減少壓縮視頻所產生的噪聲。Dai等[12]設計了一個基于可變濾波器大小的卷積神經網絡(Variable-filter-size Residuelearning Convolutional Neural Network,VRCNN),進一步提高了H.265/HEVC壓縮視頻的質量,取得了一定性能。
上述工作設計了不同的方法,在圖像內挖掘了像素之間的關聯性,完成了空域單幀的質量增強。由于沒有利用相鄰幀之間的相似性,這些方法還有進一步提升空間。
1.2 基于多幀圖像的超分辨率
基于多幀的超分辨與基于多幀的質量增強問題有相似之處。Tsai等[13]提出了開創性的多幀圖像的超分辨率工作,隨后在文獻[14]中得到了更進一步研究。同時,許多基于多幀的超分辨率方法都采用了基于深度神經網絡的方法。例如,Huang等[15]設計了一個雙向遞歸卷積神經網絡(Bidirectional Recurrent Convolution Network,BRCN),由于循環神經網絡能夠較好地對視頻序列的時域相關性進行建模,獲取了大量有用的時域信息,相較于單幀超分辨率方法,性能得到顯著提升。Li和Wang[16]提出了一種運動補償殘差網絡(Motion Compensation and Residual Net,MCRes-Net),首先使用光流法進行運動估計和運動補償,然后設計了一個深度殘差卷積神經網絡結構進行圖像質量增強。上述多幀方法所取得的性能超越了同時期的單幀方法。
Yang等[5]提出利用時域和空域信息來完成質量增強任務,設計了一種MFQE的增強策略。首先,利用光流網絡產生光流信息,相鄰幀在光流信息的引導下,得到與當前待增強幀處于同一時刻的對齊幀;然后,該對齊幀與當前待增強幀一同輸入質量增強網絡。受上述工作的啟發,本文提出了一種更加精準和有效的基于多幀的方法,以進一步提升壓縮視頻的質量。
2 時空域上下文學習多幀質量增強
如圖1所示,所提方法的整體結構包括預處理部分與質量增強網絡。其中,預處理部分采用ASCNN網絡,其輸入相近多幀重建圖像,分別生成關于當前幀的2個預測幀;然后,這2個預測幀與當前幀一起送入質量增強網絡,經過卷積神經網絡的非線性映射,得到增強后的當前幀。
2.1 光流法與ASCNN
挖掘多幀之間關聯性的關鍵是對多幀之間的運動誤差進行補償。光流法是一種常見的方法。本文對光流法與基于預測的ASCNN的計算復雜度與性能進行了對比。
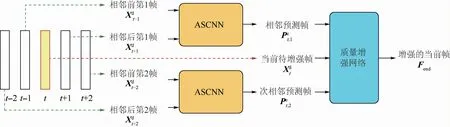
圖1 時空域上下文學習的多幀質量增強方法Fig.1 Approach for multi-frame quality enhancement using spatial-temporal context learning
1)使用光流法進行預處理
f(t-1)→t表示2幀 圖 像(、,t>1)。首先,通過光流估計網絡HFlow得到的光流;然后,對得到光流與進行WARP操作,得到對齊幀;最后,將和一起送入卷積神經網絡,可得到t時刻的質量增強幀。
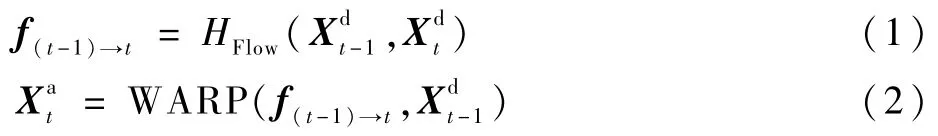
2)使用ASCNN進行預處理
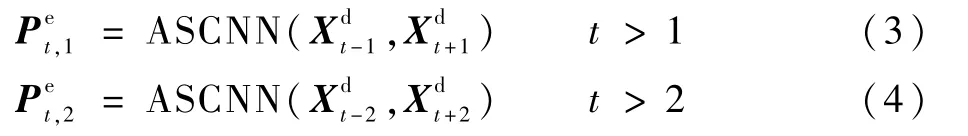
光流法的典型實現是FlowNet[17]。本文選取了4個測試序列,每個序列測試50幀,比較了FlowNet 2.0與ASCNN的時間復雜度,如表1所示。對于2個網絡,分別輸入2幀圖像,并得到各自的預處理時間。經過預處理,光流法得到2幀對齊圖像,ASCNN得到1幀預測幀。值得注意的是,由于FlowNet 2.0網絡參數量較大,當顯存不足時,每幀圖像被分成多塊進行處理。從表1可以看出,FlowNet 2.0的預處理耗時約為ASCNN的10倍。
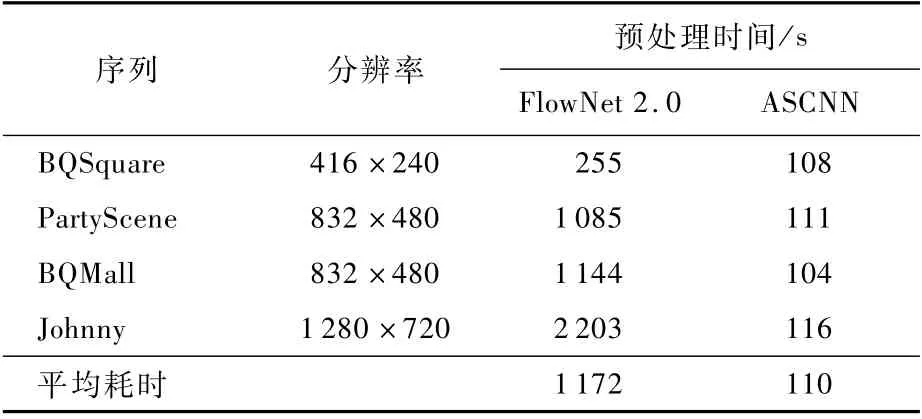
表1 光流法(Flow Net 2.0)與ASCNN預處理時間對比Table 1 Pre-processing time comparison of optical flow method(Flow Net 2.0)and ASCNN
2.2 多幀質量增強網絡
多幀質量增強網絡MFCNN的結構如圖3所示,網絡結構內部的參數配置如表2所示。在MFCNN中,HCFEN為粗特征提取網絡(Coarse Feature Extraction Network,CFEN),分別用于提取、和的空間特征:
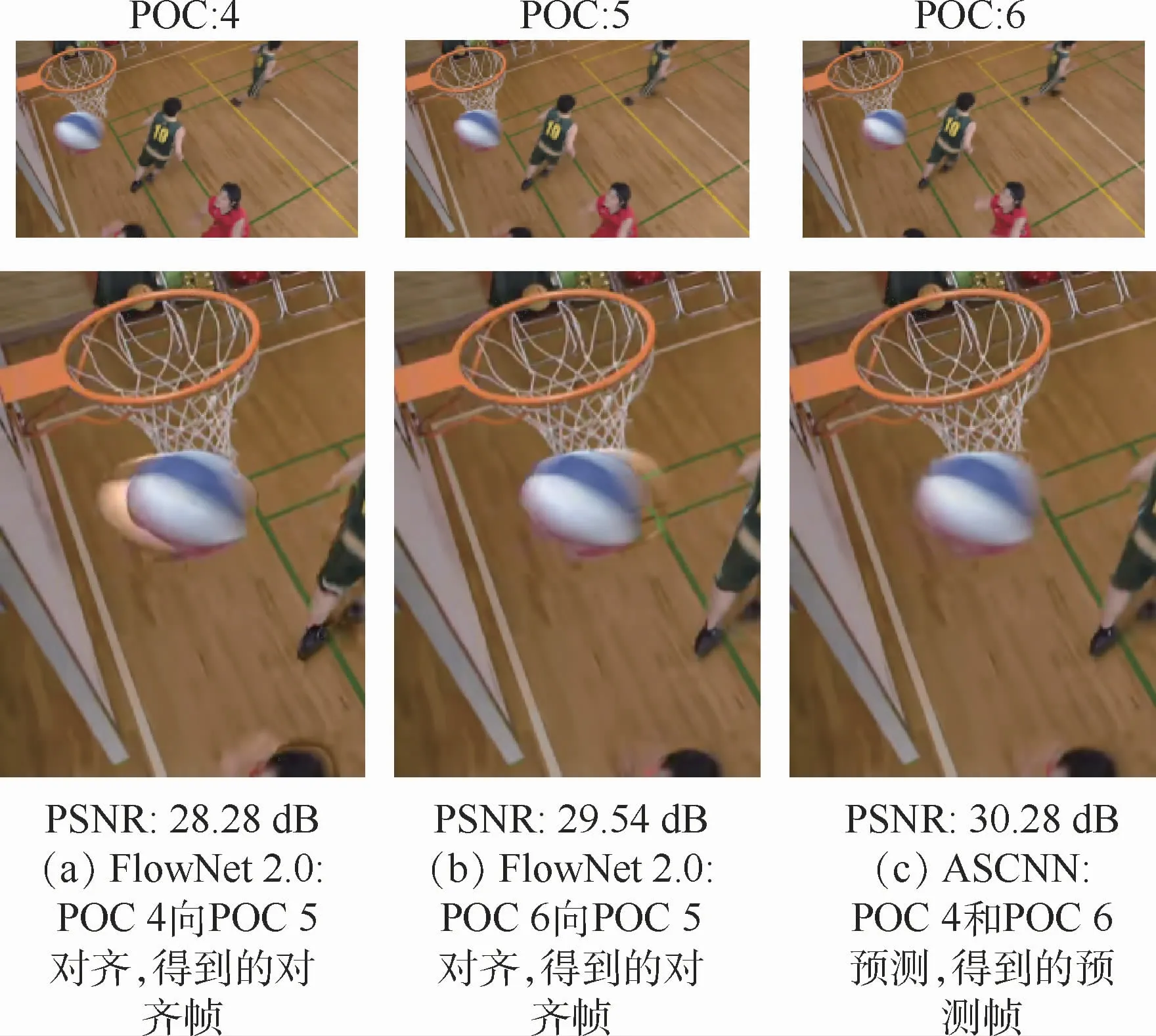
圖2 光流法(FlowNet 2.0)與ASCNN預處理得到的輸出圖像的主觀圖Fig.2 Subjective quality comparison of output image preprocessed by optical flow method(FlowNet 2.0)and ASCNN


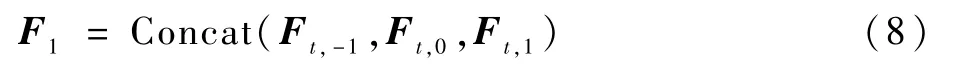
然后,送入Conv 4,將所級聯的特征進一步融合,同時使用1×1大小的卷積核來降該層的參數量:

最后,經過7個殘差網絡[18]的殘差塊,得到特征矩陣為F7。在MFCNN的最后輸出層,加入Xdt形成全局殘差學習結構:

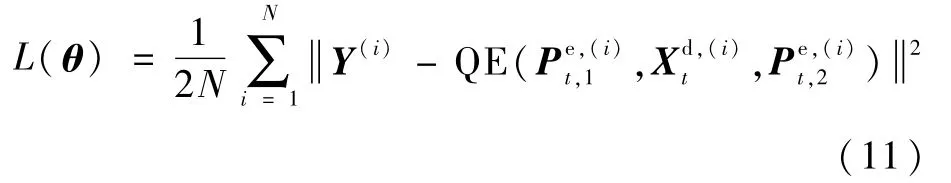
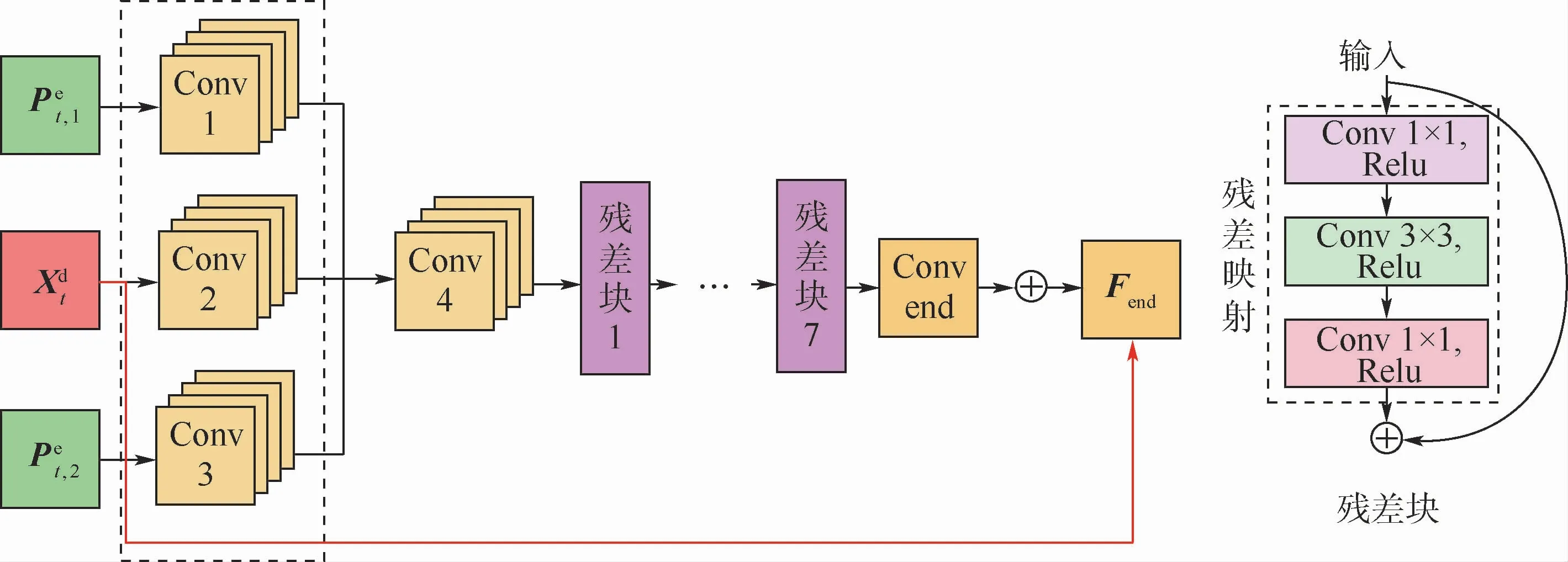
圖3 早期融合網絡結構及其內部每個殘差塊的結構Fig.3 Structure of proposed early fusion network and structure of each residual block in it
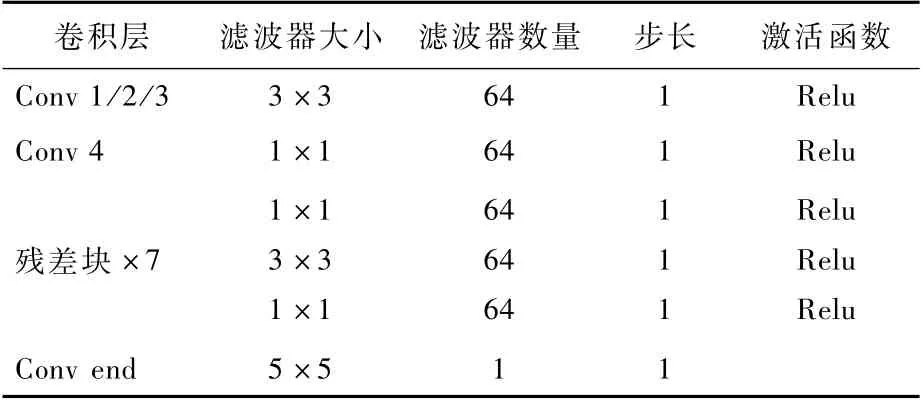
表2 多幀質量增強網絡結構Table 2 Str ucture of proposed quality enhancement network
3 實驗結果與分析
3.1 實驗條件
本文的訓練與測試環境為i7-8700K CPU和Nvidia GeForce GTX 1080 TI GPU。所有實驗都基于TensorFlow深度學習框架。本文使用118個視頻序列來訓練神經網絡,并在11個H.265/HEVC標準測試序列進行測試。每個序列都使用HM16.9在Random-Access(RA)配置下圖像組(Group of Pictures,GOP)大小設置為8,量化參數分別設置為22、27、32、37,并獲得重建視頻序列。
3.2 實驗結果比較與分析
1)與傳統光流法的對比
本文采用基于早期融合的質量增強網絡結構,對5種預處理方法的性能進行了對比,以圖4所示的第2幀圖像為例,包括:
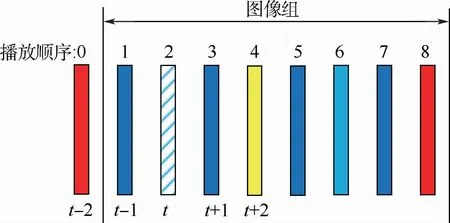
圖4 以圖像組為單位對低質量圖像進行增強Fig.4 Enhancing low-quality images for each GOP
①使用光流法對前后t±2幀進行運動補償,分別得到對齊幀,利用兩幀對齊幀對當前幀進行增強。
②使用ASCNN利用前后t±2幀預測當前幀,利用該預測幀對當前幀進行增強。
③結合①與②,利用兩幀對齊幀與一幀預測幀對當前幀進行增強。
④使用光流法對前后t±2幀進行運動補償,分別得到對齊幀,使用ASCNN利用前后t±1幀預測當前幀,利用兩幀對齊幀與一幀預測幀對當前幀進行增強。
⑤使用ASCNN,分別利用前后t±1與t±2幀預測當前幀,根據所得到的兩幀預測幀對當前幀進行增強。
表3給出了上述幾種方法的性能對比,其中t+n代表與t時刻相隔n幀。可見,使用ASCNN,將2對相鄰幀生成當前時刻的2個預測幀的方式,取得了最優的性能。
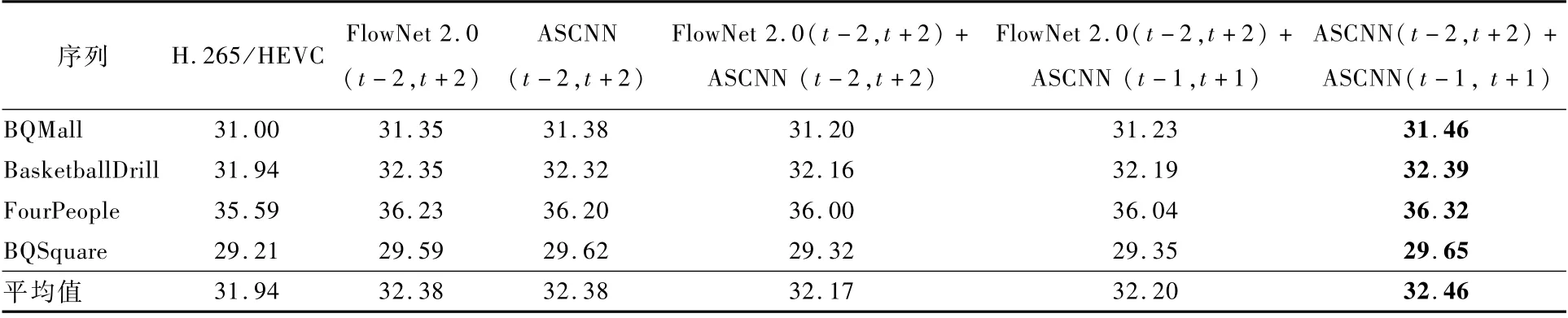
表3 5種預處理方式所獲得的PSNR性能指標對比Table 3 PSNR performance indicator comparison by five pre-processing strategies dB
2)與不同網絡結構的對比
本文設計了多種形態的網絡結構,并對其性能進行了對比。如圖5所示,分別設計了直接融合、漸進融合2種方式,并與本文的早期融合進行了對比。
3種結構的區別在于,直接融合方法直接將多幀信息級聯作為網絡輸入,漸進融合方法逐漸地級聯卷積特征圖。將這3種結構設計成具有相近的參數量,實驗結果如表4所示。可見,漸進融合比直接融合的性能平均提高了0.03 dB,而早期融合比漸進融合又能夠提升0.04 d B。
該實驗證明了對每個輸入幀使用更多獨立濾波器,可以更好地甄別當前幀與預測幀的重要性。但隨著網絡深度的增加,漸進融合方法會引入更多參數。因此,相同等參數量的情況下,與早期融合方法相比,漸進融合網絡深度較淺,很可能產生欠擬合問題,無法達到同等性能。
3)與單幀質量增強方法的對比
采用ASCNN,分別對前后幀進行預測,具體地,分別使用ASCNN利用前后距離近質量低的兩幀圖像(如圖4的第1幀與第3幀)、前后距離遠質量高的兩幀圖像(如圖4的第0幀與第4幀),得到當前幀的兩幀預測幀,這兩幀預測幀與當前幀一起送入所提出的早期融合網絡,得到最終增強的圖像。
如表5所示,本文所提出的STMVE始終優于僅使用空域信息的單幀質量增強方法。具體地,相較于H.265/HEVC,STMVE在量化參數為37、32、27、22分別取得了0.47、0.43、0.38、0.28 dB的增益,相較于單幀質量增強方法,分別獲得0.16、0.15、0.15和0.11 d B的性能增益。
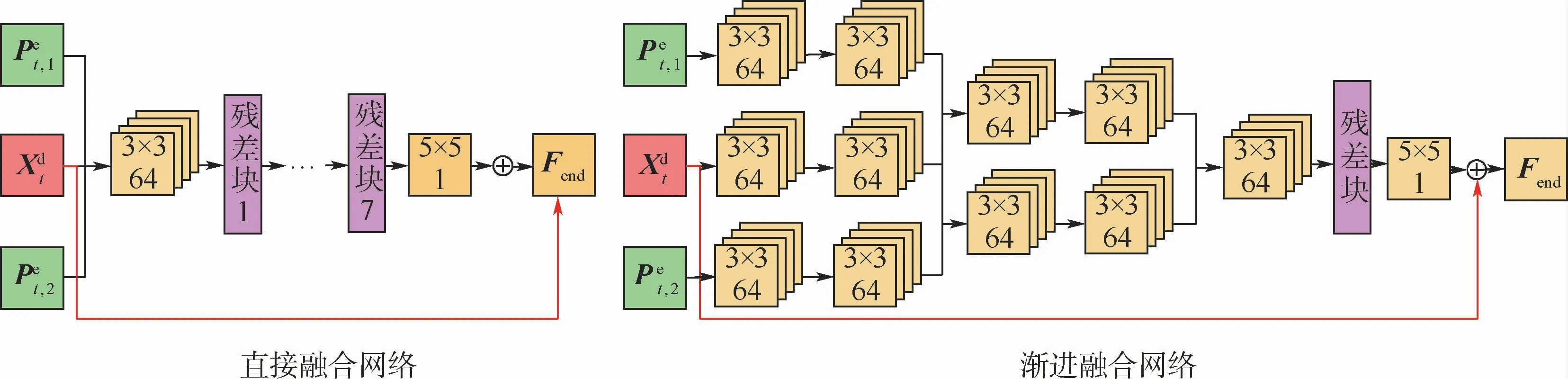
圖5 直接融合網絡和漸進融合網絡與所提出的早期融合網絡的對比Fig.5 Comparison of direct fusion networks and slow fusion networks with proposed early fusion networks
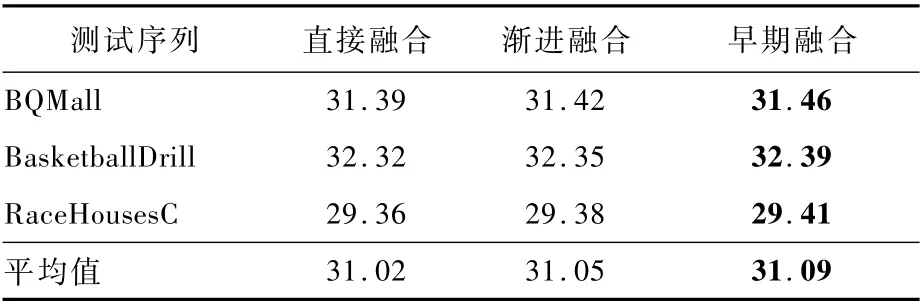
表4 三種網絡結構的PSNR性能指標對比Table 4 PSNR perfor mance indicator comparison of three network structures dB
4)與多幀質量增強方法的對比
本文也與MFQE的結果進行了對比,結果如表6所示,其中,ΔPSNR代表STMVE與MFQE的PSNR之差。隨機選取了4個測試序列,在量化參數為37時,測試其前36幀。結果表明,所提出的STMVE方法平均比MFQE高出0.17 d B。在參數數量上,MFQE的參數量約為1 715 360,而STMVE的參數量為362 176,僅為MFQE的21%。可見,所提出的網絡雖然具有較少參數,但仍獲得了較高性能。

表5 不同方法的PSNR性能指標對比Table 5 Compar ison of PSNR performance indicator among different methods dB
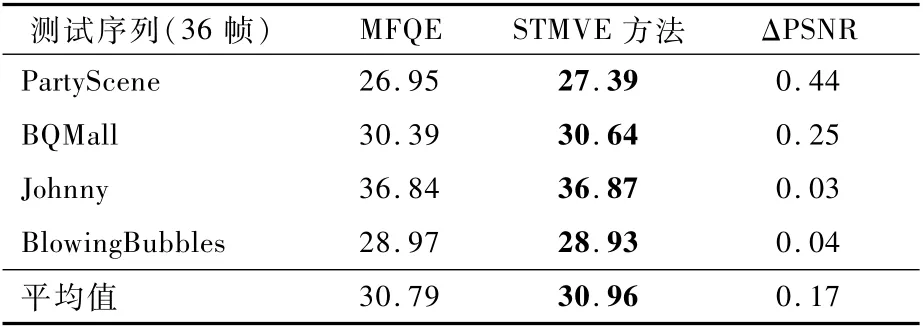
表6 STMVE方法與MFQE的PSNR性能指標對比Table 6 PSNR performance indicator comparison between proposed method and MFQE dB
5)主觀質量對比
本文還比較了經不同方法處理后得到的圖像的主觀質量,如圖6所示。經觀察可見,與H.265/HEVC和單幀質量增強方法相比,所提出的STMVE方法能夠明顯改善圖像的主觀質量,圖像的細節被更好地保留下來,主觀質量提升明顯。

圖6 不同方法獲得圖像的主觀質量對比Fig.6 Subjective quality comparison of reconstructed pictures enhanced by different methods
4 結 論
本文提出了一種時空域上下文學習的多幀質量增強方法基于STMVE。與以往基于單幀質量增強的方法不同,STMVE方法充分利用了當前幀的鄰近4幀圖像的時域信息。與傳統的基于光流法的運動補償方式不同,本文提出了利用預測幀增強當前幀的質量;為充分挖掘時域信息,提出了多幀增強的早期漸進融合式網絡結構。其次,針對所提出的STMVE方法,分別就預處理方式、網絡組合結構、質量增強方法及主觀質量進行了分析,并設計實驗與以往方法進行了對比。大量的實驗結果表明,與其他方法相比,本文所提出的STMVE方法在主觀質量與客觀質量上都有顯著優勢。
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中學生數理化·八年級物理人教版(2021年12期)2021-12-31 03:23:08
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
中學生數理化·中考版(2020年10期)2020-11-27 01:59:48
現代出版(2020年3期)2020-06-20 07:10:34
中國生殖健康(2019年2期)2019-08-23 08:12:08
Coco薇(2016年2期)2016-03-22 02:42:52
汽車觀察(2016年3期)2016-02-28 13:16:26
Coco薇(2015年1期)2015-08-13 02:47:34
