基于群優化擬合及臨床數據的癌癥lncRNA預測技術研究
2020-01-03 10:10:55王波李玲玲劉佰泉陶佰睿李敬有
現代信息科技 2020年16期
王波 李玲玲 劉佰泉 陶佰睿 李敬有

摘? 要:提出一種群優化擬合方法,通過測試函數和優化模型,分析驗證了其具有較好的優化能力。采用群優化擬合方法計算了關鍵特征集合,并結合臨床數據提出了一種基于群優化擬合及臨床數據的癌癥lncRNA預測方法。該方法在關鍵特征集合的基礎上采用判別分析完成預測,預測過程中采用馬氏統計距離的最小原則。實驗結果表明,該方法獲得了較好的收斂性能,在精確度、召回率和F1-Score三個指標上都達到了較好的預測結果。
關鍵詞:群優化擬合;臨床數據;lncRNA預測技術;癌癥
中圖分類號:TP391? ? ? 文獻標識碼:A 文章編號:2096-4706(2020)16-0008-05
Prediction Technology Study of Cancer lncRNA Based on Swarm Optimization Fitting and Clinical Data
WANG Bo1,2,LI Lingling3,LIU Baiquan3,TAO Bairui4,LI Jingyou4
(1.College of Computer and Control,Qiqihar University,Qiqihar? 161006,China;2.College of Computer Science and Technology,Harbin Engineering University,Harbin? 150001,China;3.Network Information Center,Qiqihar University,Qiqihar? 161006,China;4.School of Communications and Electrical Engineering,Qiqihar University,Qiqihar? 161006,China)
Abstract:In this paper,a method of swarm optimization fitting was proposed,which was proved to have good optimization ability by test function and optimization model. The pivotal feature set was calculated by the method of swarm optimization fitting,and a prediction method of cancer lncRNA based on swarm optimization fitting and clinical data was proposed in combination with clinical data. The method used discriminant analysis to complete the prediction based on pivotal feature set,and the Mahalanobis statistical distance principle was adopted in the prediction process. Experimental results show that this method achieved good convergence performance and good prediction results in accuracy,recall rate and F1-Score.
Keywords:swarm optimization fitting;clinical data;lncRNA prediction technology;cancer
0? 引? 言
lncRNA是一種不具有編碼功能且長度大于200個核苷酸的RNA。研究表明很多復雜的疾病都與lncRNA的變異或異常表達相關,在分子層面對致病lncRNA的研究可以找到致病的生物靶標和藥物靶標[1,2]。目前研究lncRNA與肺癌、乳腺癌、前列腺癌、結腸直腸癌、胃癌、膀胱癌和宮頸癌等有密切關系[3-5],各種相關數據庫也在逐步完善[6-9]。本文提出采用群優化擬合方法完成關鍵特征集合的計算,并結合臨床數據實現了lncRNA與疾病關聯的預測,實驗表明該方法有較好的預測性能。本文受黑龍江省教育廳基本科研業務專項,齊齊哈爾大學科學研究類項目的支持,目前已經完成與疾病關聯的lncRNA預測技術的相關研究,完成數據的整理和預測模型測試與調試,實驗結果良好。
1? lncRNA關鍵特征選擇
將研究對象抽象為lncRNA向量lncRNA={lncRNAi,i∈
[1,N]},N個lncRNAi中的關鍵特征選擇是進行與疾病關聯預測lncRNA的預處理過程,設每個lncRNAi的影響度為influence-degreei,influence-degreei的動態調整會得的lncRNA的不同的總體評價值ΛlncRNA,lncRNA的ΛlncRNA的計算公式如下:
當ΛlncRNA達到最大值的時候,取前Γ個lncRNAi為關鍵特征集合lncRNAiΦ(Φ表示為關鍵特性),lncRNAiΦ的總體評價值ΛlncRNAΦ的計算公式為:
這樣求解lncRNA關鍵特征選擇,抽象為一個最優化問題,求得ΛlncRNA達到最大值采用群優化擬合方法實現。
2? LncRNA預測
在進行lncRNA預測之前,要將lncRNAiΦ與臨床數據進行關聯,本文研究用到的臨床數據來自于TCGA數據。與lncRNAiΦ關聯的臨床數據為clinical-,最終預測數據集合為ΦlncRNA-clinical=lncRNAiΦ∪clinical-。
2.1? 預測數據集的平滑處理
預測數據集合ΦlncRNA-clinical的數據集中會有一些缺失或者噪聲數據,因此需要對ΦlncRNA-clinical進行數據的平滑處理,如果不對ΦlncRNA-clinical進行平滑處理,會使算法執行異常或者出現執行的結果偏差較大等情況。對數據的平滑處理可以選用均值平滑和邊界平滑。對于缺失數據和噪聲數據通過不同的方法完成平滑處理,平滑處理有兩個準則:
準則1(缺失-邊界):對于缺失數據,ΦlncRNA-clinical具有整體性和局部性,往往缺失數據的局部性可能對其真實值的影響更大,所以對于缺失數據的平滑處理選用邊界平滑。
準則2(噪聲-均值):對于噪聲數據,分析ΦlncRNA-clinical的數據分布特征發現,它的方差較大,說明數據的波動較大。此時如果選用邊界平滑,會出現如果待處理數據的邊界恰好是波動最大值,往往這樣的數值有存在異常的可能性,所以此時用邊界平滑的的方法會使這種異常的出現概率提升。所以針對噪聲數據選擇均值平滑,用噪聲異常值總體的均值對噪聲數據進行平滑處理。
上述平滑技術可以使ΦlncRNA-clinical更加完整,可提高算法的執行精度。
2.2? 群優化擬合
群優化擬合方法的目標是使擬合函數?最大或者最小,本研究擬合函數?為ΛlncRNA。通過群體的仿生運動,從而實現?的優化。群擬合優化方法有下文所述三類運動方式。
2.2.1? 方式1:散漫隨機運動
該運動方式為在進化初期為了得到全局最優值,群體執行散漫隨機運動,個體可以根據自身的方向傾向性,而自行運動,這樣也使整個群體的運動區域具有全局性,可以保證在全局范圍內尋優。
2.2.2? 方式2:原地避讓運動
由于個體在散漫隨機運動的過程中,可能會有不同的個體在某一時刻恰好運動到系統同一地點,由于某個地點只能允許一個個體占有,此時就發生了碰撞,那么需要其中一個個體執行原地避讓運動,個體中能量最高的占有這個位置,而能量較低的其他個體要原地避讓,等待下一時刻搜尋運動地點。
2.2.3? 方式3:域內群聚運動
在進化的后期,由于此時若再執行散漫隨機運動,可能會使優化趨勢被破壞,所以這個時候在選擇下一時刻運動的位置時,應該考慮此時群體聚集的趨勢中心點的位置,應該向這個中心點運動。這樣群聚的方向即為最優解的方向。
2.2.4? 強制機制
在群體的進化運動過程中會遇到個體盲選的情況,就是該個體不知道未來時刻的運動位置方向,此時我們需要執行強制機制。強制機制的原理是:個體沿著逆時針方向旋轉(1≤integer(θ)≤Ω),在所有試探的方向中選擇一個最佳的位置;設個體為ΦlncRNA-clinicali,當前位置為locationi,按角度? 旋轉的位置為locationi|。設第ω個位置為最佳位置的表示公式為:
群優化擬合算法描述如下,群優化擬合流程圖如圖1所示。
步驟1:種群的初始化,初始化迭代次數及參數,設置擬合函數?的公告板。
步驟2:判斷當前迭代次數d是否大于最大迭代次數D的1/2,如果是轉到步驟3,否則轉到步驟4。
步驟3:執行域內群聚運動,更新群體的全部個體的信息。
步驟4:執行散漫隨機運動,更新群體的全部個體的信息。
步驟5:判斷當前狀態中是否碰撞,如果是轉到步驟6,否則轉到步驟7。
步驟6:執行原地避讓運動,對碰撞個體不做更新操作,其余個體執行更新操作。
步驟7:判斷當前狀態中是否有盲選,如果是轉到步驟8,否則轉到步驟9。
步驟8:執行強制機制,個體沿著逆時針方向旋轉 (1≤integer(θ)≤Ω),在所有試探的方向中選擇一個最佳的位置。
步驟9:更新公告板,獲得當前最優值。
步驟10:判斷是否達到了最大迭代次數,如果是轉到步驟11,否則轉到步驟2。
步驟11:算法終止,輸出最優值。
2.3? 三種運動的四個機制
群優化擬合的散漫隨機運動、原地避讓運動和域內群聚運動具有不同的運動機制。
機制1:散漫隨機運動,由于其運動速度與運動方向都具有很大的隨機性,這樣可以增加解空間的基數,基數越大尋優的可能空間就越大。
機制2:散漫隨機運動還具有動態性,可在不同時刻動態變化個體的運動速度和運動方向。
機制3:原地避讓運動,在整個進化過程中加入了壓抑機制,因為種群都處于活躍狀態會使碰撞概率更大,可能算法會頻繁地解決處理碰撞,導致算法的負載過重,性能嚴重下降。引入原地避讓運動就是為了減低碰撞概率,減輕算法的負載。這里選擇原地避讓而沒有選擇變化位置的避讓,原因是在進化過程中為了保證局域尋優結果,所以選擇原地避讓是最好方案,若選擇其他位置進行避讓則無法保證當前尋優結果的準確性。
機制4:域內群聚運動,這個機制在進化的后期執行,這里采用的是聚類的思想,即往往個體運動的方向是群體選擇最多的運動方向,而這個方向可能是最優的結果方向。
2.4? 群優化擬合的實例化
群優化擬合方法用于計算關鍵特征選擇,需要將群優化擬合方法進行實例化,種群個體為lncRNA集合,在這集合中我們需要計算出關鍵特征。每一個個體就是某一個lncRNA,任意一個lncRNA執行群優化擬合方法中的三種運動。在群優化擬合方法中的lncRNA,除了本身表達值之外,還有兩個附加信息,就是lncRNA的位置和方向,此時lncRNA可以理解為是一個三維向量。其中,三維向量的位置信息用于馬氏統計距離的判定使用,在移動的過程中,下一時刻的位置發生變化,該向量的位置信息會更新變化。由于個體的周圍會存在著若干個移動中心點,那么個體需要根據方向再結合馬氏統計距離,綜合判定下一時刻要移動的位置。此外,群優化擬合的目標實例化為擬合函數?,這里要求解的是擬合函數?的最大值,在?達到最大值時,為最終的最優解。整個群優化擬合過程中都是以?最大值為目標,所以每次迭代都要更新?,每一個尋優的動作都是以?最大為準則,當算法達到了最大迭代次數后,算法結束。
2.5? lncRNA預測
本文提出了基于群優化擬合及臨床數據的癌癥lncRNA預測方法(Prediction method of cancer lncRNA based on swarm optimization fitting and clinical data,PCL-SOF-CD),PCL-SOF-CD采用群優化擬合方法計算了關鍵特征集合,在關鍵特征集合的基礎上采用判別分析完成lncRNA預測。首先根據已知預測標簽的數據,分別計算各個預測標簽的中心點;其次,對于任意一個學習數據判別它與中心點的馬氏距離;最后,根據距離最小原則完成預測。
3? 實驗性能分析與討論
3.1? 群優化擬合的進化性能
本文出的群優化擬合方法在計算關鍵特征集合lncRNAiΦ的前Γ個lncRNAi時,尋優曲線如圖2所示,該方法在150代的時候,就趨于平穩,獲得較好的收斂性能。
3.2? 群優化擬合的優化能力
為了進一步驗證群優化擬合方法的優化能力,選用了如表1所示的三個測試函數來分析優化能力,其中Griewank和Rastrigin為高維度測試函數,Rosenbrock為不確定維度測試函數,三個測試函數的最優值均為0。其中,xi為第i個變量,i為xi的個數;D為維度。
圖3顯示了三個測試函數的迭代曲線,其中Rosenbrock在迭代220次時達到收斂,Griewank在迭代580次時達到收斂,Rastrigin在迭代700次時達到收斂,這說明群優化擬合方法達到了較好的收斂性能。
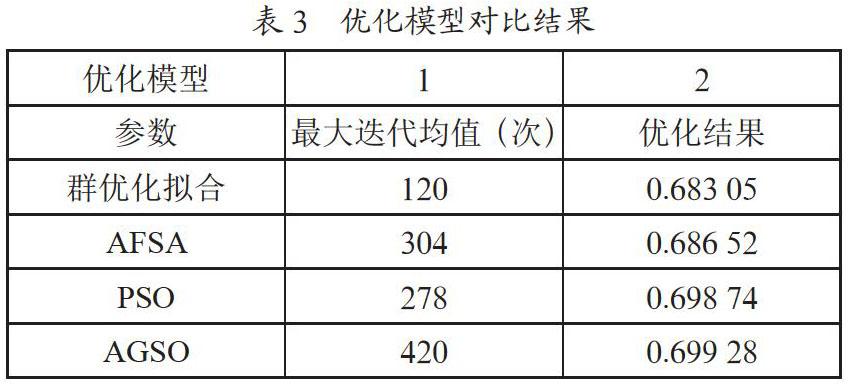
同時如表2所示,選用2個優化模型綜合分析群優化方法的優化能力(對比方法為AFSA、PSO和AGSO)。
優化結果如表3所示,對于優化模型1,群優化擬合在迭代120次時達到了最優值,AFSA在迭代304次時達到了最優值,PSO在迭代278次時達到了最優值,AGSO在迭代420次時達到了最優值,顯然群優化擬合求解速度最快。對于優化模型2,群優化擬合的優化結果為0.683 05,AFSA的優化結果為0.686 52,PSO的優化結果為0.698 74,AGSO的優化結果為0.699 28,顯然群優化擬合方法的求解精度最高。
3.3? PCL-SOF-CD算法性能
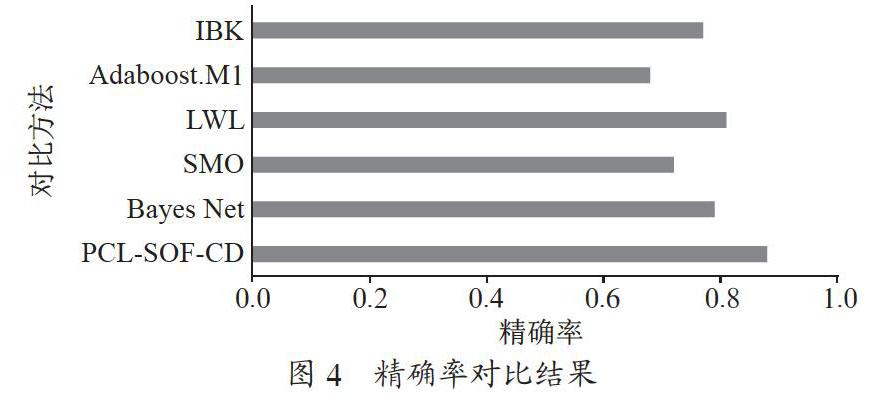
本文提出的PCL-SOF-CD與5個對比方法進行了對比分析,這5個對比方法為:Bayes Net、SMO、LWL、Adaboost.M1和IBK。實驗執行了10折交叉驗證,對比指標為精確率、召回率和F1-Score。如圖4所示,PCL-SOF-CD的精確率為0.88,Bayes Net為0.79,SMO為0.72,LWL為0.81,Adaboost.M1為0.68,IBK為0.77,綜上可見PCL-SOF-CD精確率最高。
如圖5所示,PCL-SOF-CD的召回率為0.81,Bayes Net為0.71,SMO為0.68,LWL為0.66,Adaboost.M1為0.63,IBK為0.74,綜上可見PCL-SOF-CD的召回率最高。
如圖6所示,PCL-SOF-CD的F1-Score為0.84,Bayes Net為0.75,SMO為0.70,LWL為0.73,Adaboost.M1為0.65,IBK為0.75,綜上可見PCL-SOF-CD的F1-Score最高。根據對比結果可以得知,PCL-SOF-CD在精確率、召回率和F1-Score三個指標上都達到了較好的預測性能。
4? 結? 論
本文提出一種群優化擬合方法,定義了該方法的3種運動方式:散漫隨機運動、原地避讓運動和域內群聚運動。基于群優化擬合方法計算了關鍵特征集合,并結合臨床數據采用判別分析實現了lncRNA與疾病的關聯預測,提出了一種基于群優化擬合及臨床數據的癌癥lncRNA預測方法,實驗表明該方法具有很高的推廣價值。
參考文獻:
[1] WASHIETL S,KELLIS M,GARBER M. Evolutionary dynamics and tissue specificity of human long noncoding RNAs in six mammals [J].Genome Research,2014,24(4):616-628.
[2] GUTTMAN M,RINN J L. Modular regulatory principles of large non-coding RNAs [J].Nature,2012,482(7385):339-346.
[3] HUARTE M. The emerging role of lncRNAs in cancer [J].Nature Medicine,2015,21(11):1253-1261.
[4] LI J,XUAN Z Y,LIU C N. Long Non-Coding RNAs and Complex Human Diseases [J].IJMS,2013,14(9):18790-18808.
[5] CHEN X,SUN Y Z,GUAN N N,et al. Computational models for lncRNA function prediction and functional similarity calculation [J].Briefings in functional genomics,2019,18(1):58-82.
[6] JANG S Y,KIM G,PARK S Y,et al. Clinical significance of lncRNA-ATB expression in human hepatocellular carcinoma [J].Oncotarget,2017,8(45):78588-78597.
[7] MIAO Y,SUI J,XU S Y,et al. Comprehensive analysis of a novel four-lncRNA signature as a prognostic biomarker for human gastric cancer [J].Oncotarget,2017,8(43):75007-75024.
[8] MO X B,WU L F,ZHU X W,et al. Identification and evaluation of lncRNA and mRNA integrative modules in human peripheral blood mononuclear cells [J].Epigenomics,2017,9(7):943-954.
[9] ZHANG Y L,LI X B,HOU Y X,et al. The lncRNA XIST exhibits oncogenic properties via regulation of miR-449a and Bcl-2 in human non-small cell lung cancer [J].Acta Pharmacologica Sinica,2017,38(3):371-381.
作者簡介:王波(1980—),男,漢族,黑龍江齊齊哈爾人,副教授,博士生,研究方向:與復雜疾病關聯的lncRNA預測技術。
