一種改進(jìn)的基于生成對抗網(wǎng)絡(luò)的信息隱藏模型
2020-01-03 10:10:55曹寅潘子宇
現(xiàn)代信息科技 2020年16期
關(guān)鍵詞:深度學(xué)習(xí)
曹寅 潘子宇
摘? 要:信息作為互聯(lián)網(wǎng)絡(luò)的基礎(chǔ),信息安全是其中的重要環(huán)節(jié)。隱寫技術(shù)將信息隱藏在圖片中,相比其他技術(shù)具有更高的隱蔽性和安全性。文章提出了一種具有抗隱寫分析、高隱寫容量的信息隱藏模型,其將神經(jīng)網(wǎng)絡(luò)與秘密信息耦合,編碼輸出隱寫圖像。在此基礎(chǔ)上又分別結(jié)合殘差網(wǎng)絡(luò)、密集連接網(wǎng)絡(luò)對編碼器進(jìn)行優(yōu)化,設(shè)計出兩種具有更優(yōu)性能的模型。實驗結(jié)果表明,本文提出的改進(jìn)模型比現(xiàn)有方法具有更高的相對載荷,同時能有效規(guī)避檢測。
關(guān)鍵詞:信息安全;信息隱藏;圖像隱寫;深度學(xué)習(xí)
中圖分類號:TP309? ? ? 文獻(xiàn)標(biāo)識碼:A 文章編號:2096-4706(2020)16-0137-05
A Modified Information Hiding Model Based on
Generative Countermeasure Network
CAO Yin,PAN Ziyu
(School of Information and Communication Engineering,Nanjing Institute of Technology,Nanjing? 211167,China)
Abstract:Information as the basis of the internet,information security is an important part. Steganography can hide information in the image,which has higher concealment and security than other technologies. In this paper,an information hiding model with anti-steganalysis and high steganalysis capacity is proposed. The neural network is coupled with secret information to encode the steganographic image. On this basis,the encoder is optimized with residual network and dense connection network,and two models with better performance are designed. The experimental results show that the improved model has higher relative load than the existing methods,and can effectively avoid detection.
Keywords:information security;information hiding;image steganography;deep learning
0? 引? 言
21世紀(jì)以來,隨著計算機(jī)網(wǎng)絡(luò)和通信技術(shù)的蓬勃發(fā)展,整個網(wǎng)絡(luò)空間環(huán)境逐漸變得復(fù)雜多樣,網(wǎng)絡(luò)空間安全問題引起越來越多專家學(xué)者的關(guān)注。實際上,網(wǎng)絡(luò)空間安全的歸根結(jié)底就是信息的安全。作為互聯(lián)網(wǎng)絡(luò)的基礎(chǔ),信息安全是網(wǎng)絡(luò)空間安全的重要一環(huán),所以信息應(yīng)該得到更多網(wǎng)絡(luò)空間安全技術(shù)、管理人員的關(guān)注。在這樣的背景下,信息隱藏技術(shù)應(yīng)運(yùn)而生。
研究人員提出了可保持圖像的特定統(tǒng)計特征無變化的信息隱藏方法,但其安全性仍不盡人意。例如,LSB匹配方法規(guī)避了基于對稱性的統(tǒng)計特征異常和直方圖異常,但檢測者可根據(jù)直方圖頻域質(zhì)心區(qū)域變化[1],基于模型的信息隱藏方法可以保持模型的原始分布[2],其本意是分布與理想模型相同以規(guī)避檢測,但卻適得其反過度相似反而會引起第三方懷疑[3]。
在理想情況下,隱寫載體被信息隱藏后在整個載體空間分布應(yīng)和原始載體分布完全相同。學(xué)界普遍采用相對熵來評價信息隱藏方案的安全性[4]。然而,在信息隱藏方案中載體空間異常巨大,通常在將數(shù)據(jù)統(tǒng)計模型簡化后再對安全性進(jìn)行討論,如將載體樣本數(shù)據(jù)理想化服從獨立同分布[5]或把載體數(shù)據(jù)映射到統(tǒng)計特征[6]。通過Fisher信息量[7]計算嵌入秘密信息的安全容量[8]并對其進(jìn)行優(yōu)化[9]。然而,信息隱藏不可避免地會在一定程度上引起載體數(shù)據(jù)層面的變化,如選用其他基于統(tǒng)計特征的隱寫分析方案進(jìn)行檢測,仍可檢測出隱寫信息的存在。
本文在深入研究基于深度學(xué)習(xí)的信息隱藏技術(shù)的基礎(chǔ)上首先提出了一種基于生成對抗網(wǎng)絡(luò)的信息隱藏模型,即高容量隱寫生成對抗網(wǎng)絡(luò)(High Capacity Steganography GAN,HCSGAN)模型。該模型相較于主流隱寫方案具有更優(yōu)的性能表現(xiàn),但其在訓(xùn)練、測試中仍存在梯度消失、退化問題以及圖片隱寫處理耗時較長、質(zhì)量較差等問題。然后具體介紹對HCSGAN模型的改進(jìn)思路及所做的改進(jìn),詳細(xì)說明所采用的變體模型,展示模型架構(gòu)并描述訓(xùn)練過程。本文對HCSGAN架構(gòu)的兩個變體進(jìn)行了實驗,結(jié)果證明了本文提出的模型比現(xiàn)有方法具有更高的相對載荷,同時仍能有效規(guī)避檢測。
1? 模型及改進(jìn)思路
1.1? HCSGAN模型
本文提出了HCSGAN模型,并將其應(yīng)用于圖像隱寫。這是一種全新的基于深度學(xué)習(xí)最新成果的端到端圖像隱寫方案。我們還在對抗訓(xùn)練框架下使用多損失函數(shù)以達(dá)到同時優(yōu)化編碼器、解碼器和指導(dǎo)網(wǎng)絡(luò)的目的。此方案能夠在多種自然場景下成功將二進(jìn)制數(shù)據(jù)嵌入載體圖像中,并能在規(guī)避標(biāo)準(zhǔn)隱寫分析工具檢測的情況下達(dá)到目前最高水平的每個像素4比特的嵌入率。
1.2? 殘差網(wǎng)絡(luò)及密集網(wǎng)絡(luò)
殘差網(wǎng)絡(luò)(ResNet)的提出是深度學(xué)習(xí)領(lǐng)域的一場革命。在2015年的ILSVRC上,來自微軟團(tuán)隊的4位學(xué)者提出了ResNet。
在深度神經(jīng)網(wǎng)絡(luò)中,單純增加網(wǎng)絡(luò)的深度會導(dǎo)致梯度消失或爆炸以及準(zhǔn)確率退化等問題。而ResNet能較好的解決這些問題。通常,構(gòu)造深層網(wǎng)絡(luò)采用通過對所增加的網(wǎng)絡(luò)進(jìn)行恒等映射的方法。該方法的前提是加深后的網(wǎng)絡(luò)模型訓(xùn)練誤差應(yīng)低于其淺層模型,然而很少能出現(xiàn)滿足這一條件的情況。
微軟團(tuán)隊提出的ResNet模型通過多層網(wǎng)絡(luò)將直接擬合復(fù)雜映射x→H(x)轉(zhuǎn)化為間接擬合簡單映射x→F(x)=H(x)-x。在這種情況下,模型學(xué)習(xí)F(x)=0相較于H(x)=0自然容易得多。當(dāng)殘差F(x)足夠小時,轉(zhuǎn)化后的映射逼近恒等映射,即解決了準(zhǔn)確率退化的問題,同時網(wǎng)絡(luò)深度增加,精度隨之提高。
部分連接前后層以優(yōu)化反向傳播,從而訓(xùn)練深層網(wǎng)絡(luò),這是ResNet模型的核心思想。DenseNet與之類似,但不同的是DenseNet通過建立全連接而非ResNet的部分連接。特征復(fù)用由特征相連接實現(xiàn),這是其另一特點。基于上述特點,DenseNet能夠?qū)崿F(xiàn)更優(yōu)性能,同時所需的參數(shù)和計算成本更少。
無論是ResNet還是DenseNet,核心的思想都是連接,不加選擇地讓某些輸入進(jìn)入之后的網(wǎng)絡(luò)層,以實現(xiàn)信息流的整合,避免了信息在層間傳遞的丟失和梯度消失的問題,同時還抑制了某些噪聲的產(chǎn)生。
2? 變體模型設(shè)計
2.1? 變體模型參數(shù)和符號
本文用C和S分別表示寬度和高度相同的RGB通道載體圖像和隱寫圖像,M∈{0,1}D×W×H代表被隱藏在載體圖像中的二進(jìn)制信息。D代表最大信息深度,W表示寬度,H表示高度,實際信息深度是能可靠解碼的比特數(shù)(1-2p)D,其中p∈[0,1]是錯誤概率。
載體圖像C是從所有自然圖像?C的概率分布中采樣得到的。隱寫圖像S由一個完成學(xué)習(xí)的編碼器ε(C,M)生成的,其中M為隱寫到載體圖像中的秘密信息。最終獲取的秘密信息的估計值? 是由一個完成學(xué)習(xí)的解碼器ζ(S)提取得到的。優(yōu)化的任務(wù)是通過一個給定的混合信息分布,來訓(xùn)練編碼器ε和解碼器ζ以使解碼錯誤率p和自然圖像與隱寫圖像間分布間的距離dis(?C,?S)最小化。因此,為了優(yōu)化編碼器和解碼器,我們也需要訓(xùn)練一個評估網(wǎng)絡(luò)C(·)來估計dis(?C,?S)。令參數(shù)X∈?D×W×H以及Y∈?D′×W×H是兩個寬度和高度相同的感知器,但深度可能是D和D′兩個不相同值,然后Cat:(X,Y)→Φ∈?(D+D′)×W×H是沿深度軸方向的兩個張量的級聯(lián)。令ConvD→D′:X∈?D×W×H→Φ∈ ?D′×W×H是將輸入?yún)?shù)X映射到寬度和高度、深度可能不同的特征圖Φ的卷積塊。這個卷積塊包含了一個內(nèi)核大小為3、步幅為1、填充為“相同”的卷積層,其后是一個leaky ReLU激活函數(shù)以及批標(biāo)準(zhǔn)化。如果卷積塊是網(wǎng)絡(luò)中的最后一個塊,則激活函數(shù)和批標(biāo)準(zhǔn)化操作可省略。
令Mean:X∈?D×W×H→?D代表表示自適應(yīng)平均空間池化操作,該操作計算張量X的每個特征圖中的W×H的平均值。
2.2? 變體模型體系結(jié)構(gòu)
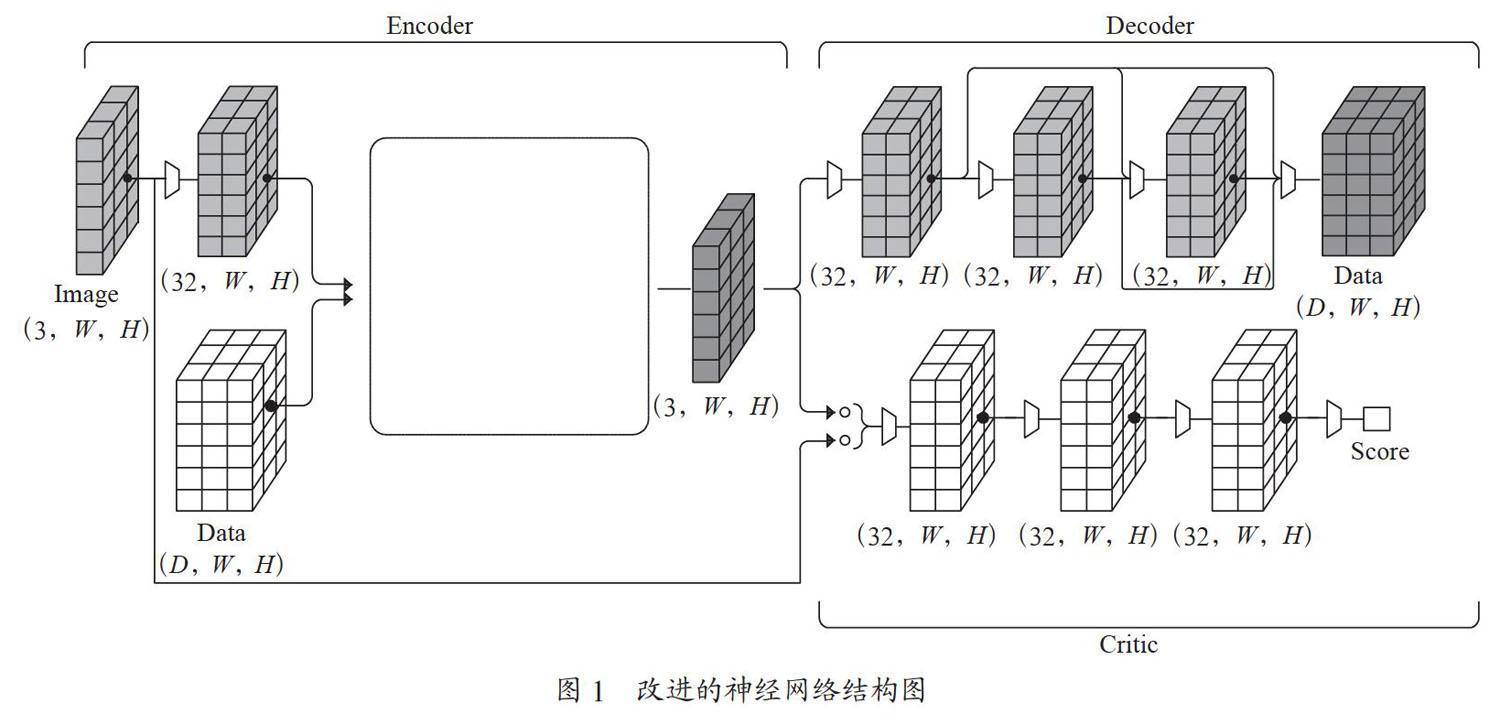
本節(jié)節(jié)展示了一種生成對抗網(wǎng)絡(luò)HCSGAN模型用以在載體圖像中隱藏任意位向量。改進(jìn)的神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)如圖1所示,包括三個模塊:
(1)一個編碼器(Encoder),用于獲取載體圖像(Image)和數(shù)據(jù)信息(Data)并生成隱寫圖像;
(2)一個解碼器(Decoder),用于獲取隱寫圖像并嘗試恢復(fù)數(shù)據(jù)信息;
(3)一個判別網(wǎng)絡(luò)(Critic),用以評估載體圖像和隱寫圖像的質(zhì)量,得出評分(Score)。
卷積運(yùn)算在圖1中以梯形圖標(biāo)表示。
2.2.1? 編碼器
編碼器網(wǎng)絡(luò)含有一張載體圖像和需要加載到載體圖像中的秘密信息M∈{0,1}D×W×H。因此,M是一個形狀為D×W×H的二進(jìn)制數(shù)據(jù)張量,其中D是我們試圖隱藏在載體圖片每個像素中的比特數(shù),即信息深度。
我們嘗試了兩種具有不同連接模式的編碼器體系結(jié)構(gòu)的變體模型。三種變體模型都采用以下操作開始:
(1)使用卷積塊處理載體圖像C以獲得張量a:
a=Conv3→32(C)
(2)將秘密信息M連接到張量a,然后用卷積塊處理結(jié)果以獲得張量b:
b=Conv32+D→32(Cat(a,M))
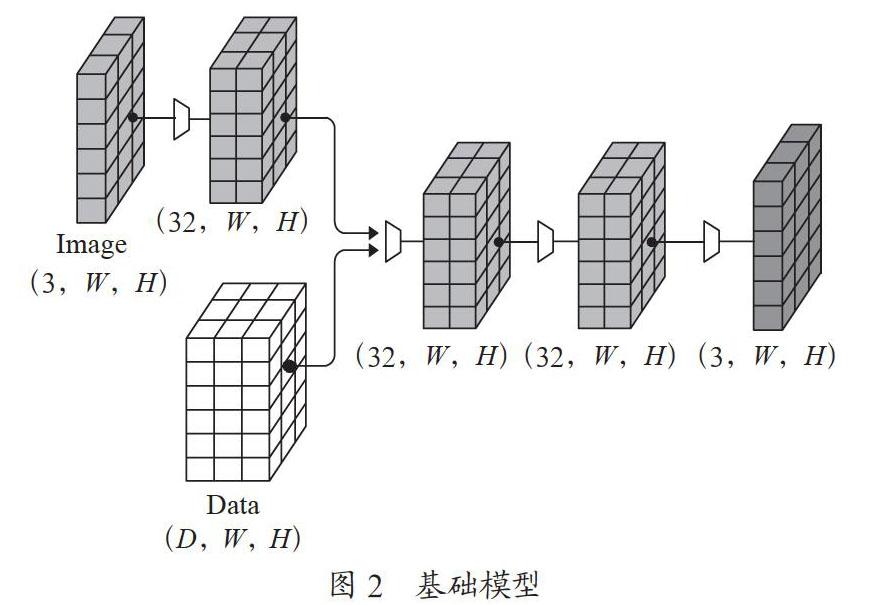
基礎(chǔ)模型(HCSGAN):我們依次將兩個卷積塊應(yīng)用于張量b并生成隱寫圖像,基礎(chǔ)模型編碼器εb如圖2所示。
其可以表示為:
εb(C,M)=Conv32+D→21(Cat(a,M))
這個方法類似于Baluja方案[1],隱寫圖像只是最后一個卷積塊的輸出。
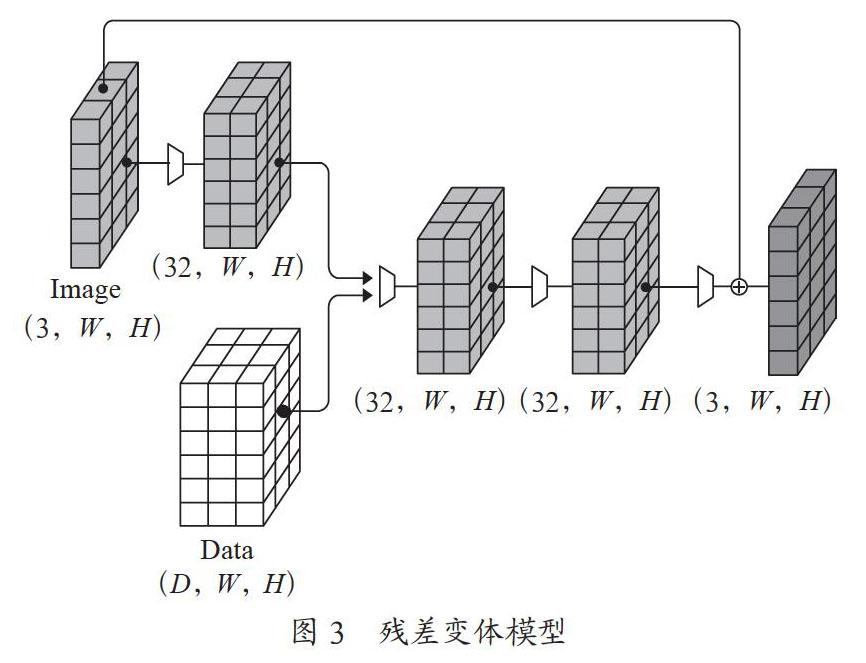
殘差變體模型(HCSGAN-ResNet):殘差網(wǎng)絡(luò)的使用已被證明可以改善模型的穩(wěn)定性和收斂性[2],因此我們嘗試使用殘差網(wǎng)絡(luò)來提高隱寫圖像的質(zhì)量。為此,我們通過將載體圖像C添加到其輸出中來修改基本模型的編碼器,以使編碼器學(xué)習(xí)生成如圖3所示的殘差圖像。
殘差變體模型編碼器εr可以表示為:
εr(C,M)=C+εb(C,M)
密集變體模型(HCSGAN-DenseNet):在密集模型變體
中,我們嘗試在卷積塊之間引入了其他連接,以便將較早的塊生成的特征圖連接到由較后的塊生成的特征圖,如圖4所示。
這種連接模式受到DenseNet網(wǎng)絡(luò)的啟發(fā),該網(wǎng)絡(luò)已被證明可以優(yōu)化功能復(fù)用和緩解消失的梯度問題[3]。因此,我們嘗試使用密集連接將提高嵌入率。它可以表示為:
最后,各種變體模型的輸出是一個與載體圖像C分辨率、和深度相同的隱寫圖像S=ε{b,r,d}(C,M)。
2.2.2? 解碼器
解碼器接收由編碼器產(chǎn)生的隱寫圖像S。它可以表示為:
解碼器生成輸出秘密信息的估計值 =ζ(S),換言之,它試圖恢復(fù)秘密信息M。
2.2.3? 判別網(wǎng)絡(luò)
為了提供有關(guān)編碼器性能的反饋并生成更逼真的圖像,我們引入了對抗性判別網(wǎng)絡(luò)。判別網(wǎng)絡(luò)由三個卷積塊組成,后接一個具有一個輸出通道的卷積層。為了生成標(biāo)量分?jǐn)?shù),我們將自適應(yīng)均值池應(yīng)用于卷積層的輸出。它可以表示為:
3? 訓(xùn)練過程
我們采用迭代的方法優(yōu)化編-解碼器網(wǎng)絡(luò)和判別網(wǎng)絡(luò)。為了優(yōu)化編-解碼器網(wǎng)絡(luò),我們聯(lián)合優(yōu)化三個損失:
(1)使用交叉熵?fù)p失的解碼精度?d:
min?d=CrossEntropy(ζ(ε(X,M)),M)
(2)均方誤差下隱寫圖像與載體圖像的相似度?S:
min?S=
(3)判別網(wǎng)絡(luò)隱寫圖像的真實性?r:
min?r=C(ε(X,M))
為了訓(xùn)練判別網(wǎng)絡(luò),要使Wasserstein損失?C最小化:
min?C=C(X)-C(ε(C,M))
上述公式中,表示數(shù)學(xué)期望。
在每次迭代中,將每一個載體圖像C與數(shù)據(jù)張量M進(jìn)行匹配,其中數(shù)據(jù)張量M是由伯努利分布M~Ber(0.5)采樣隨機(jī)生成的形狀為D×W×H比特序列。除此以外,在預(yù)處理流程中,對于載體圖像C,應(yīng)用了包括水平翻轉(zhuǎn)和隨機(jī)裁剪在內(nèi)的標(biāo)準(zhǔn)數(shù)據(jù)增強(qiáng)程序進(jìn)行優(yōu)化。本文使用了學(xué)習(xí)率為le-4的Adam優(yōu)化器,剪裁梯度均方為0.25,剪裁判別系數(shù)為[-0.1,0.1],訓(xùn)練32輪。
4? 性能評估及分析
4.1? 數(shù)據(jù)集測試
本文使用Div2k和COCO數(shù)據(jù)集對模型進(jìn)行訓(xùn)練和測試。實驗對象為第3節(jié)所述的三種模型變體,對其以六種不同深度D進(jìn)行訓(xùn)練。數(shù)據(jù)深度D代表每像素的目標(biāo)比特數(shù),則隨機(jī)生成的數(shù)據(jù)張量尺寸為D×W×H。
實驗中,使用了Div2K和COCO數(shù)據(jù)集的創(chuàng)建者提議的默認(rèn)訓(xùn)練/測試拆分方法,并且在表1中展示了該測試集的平均準(zhǔn)確率、RS-BPP、峰值信噪比和結(jié)構(gòu)相似性指數(shù)。準(zhǔn)確率表示恢復(fù)出正確隱藏信息的概率;RS-BPP表示Reed-Solomon每像素比特數(shù),體現(xiàn)了載體圖像的相對荷載;峰值信噪比用于測量圖像質(zhì)量;結(jié)構(gòu)相似性指數(shù)衡量載體圖像和隱寫圖像之間的結(jié)構(gòu)相似度,相似度越高則表明秘密信息越不容易被發(fā)現(xiàn)。本文提出的的模型在GeForce GTX 1080的GPU上進(jìn)行了訓(xùn)練。對于Div2K,每輪訓(xùn)練時間約為10分鐘;對于COCO,則為2小時。
訓(xùn)練結(jié)束模型后,在保留的測試集上計算期望的準(zhǔn)確率,并使用前文討論的Reed-Solomon編碼方案對其進(jìn)行調(diào)整,以產(chǎn)生上文所述的每像素位指標(biāo),Div2K和COCO數(shù)據(jù)集測試結(jié)果分別如表1和表2所示。
在表1和表2中,每個指標(biāo)都是根據(jù)訓(xùn)練過程中未對模型顯示的保留圖像測試集計算得出的。需要注意的是,相對載荷和圖像質(zhì)量之間不可避免地存在權(quán)衡取舍;假設(shè)我們已經(jīng)在Pareto邊界上,那么相對載荷的增加將導(dǎo)致相似度下降。可以觀察到,模型的所有變體在COCO數(shù)據(jù)集上的表現(xiàn)都優(yōu)于Div2K數(shù)據(jù)集。此現(xiàn)象可以歸因于兩個數(shù)據(jù)集內(nèi)容類型的差異。Div2K數(shù)據(jù)集中的圖像傾向于開闊的風(fēng)景,而COCO數(shù)據(jù)集中的圖像傾向于更加雜亂且包含多個對象,這種特性為本文所述的模型提供了更多的表面和紋理,從而可以成功地嵌入數(shù)據(jù)。
此外,還可以發(fā)現(xiàn),密集變體模型在相對載荷和圖像質(zhì)量上均表現(xiàn)出最佳性能,殘差變體模型排在第二位,其顯示出可較好的圖像質(zhì)量,但相對載荷較低。基本模型在所有指標(biāo)上的表現(xiàn)都最差,相對荷載和圖像質(zhì)量得分比密集模型低15%~25%。
最后,盡管本文提出的基于深度學(xué)習(xí)的信息隱藏方案的相對載荷較其他方案有所增加,但圖像相似性(根據(jù)載體圖像和隱寫圖像之間的平均峰值信噪比測得)仍與文獻(xiàn)[4]中所述方法的結(jié)果相當(dāng)。
5? 結(jié)? 論
本文提出了一種高容量隱寫生成對抗網(wǎng)絡(luò)HCSGAN模型以及兩種基于HCSGAN的變體HCSGAN-ResNet和HCSGAN- DenseNet。本文對HCSGAN架構(gòu)的兩個變體進(jìn)行了實驗,并證明了本文提出的的模型比現(xiàn)有方法具有更高的相對載荷,同時仍能有效規(guī)避檢測。
參考文獻(xiàn):
[1] XIA Z H,WANG X H,SUN X M,et al. Steganalysis of LSB Matching Using Differences Between Nonadjacent Pixels [J].Multimedia Tools and Applications,2016,75(4):1947-1962.
[2] YANG C,LUO X,LIU F. Embedding Ratio Estimating for Each Bit Plane of Image [C]//Information Hiding,11th International Workshop,IH 2009.Heidelberg:Springer-Verlag Berlin Heidelberg,2009:59-72.
[3] QIAN Y L,DONG J,WANG W,et al. Deep Learning for Steganalysis Via Convolutional Neural Networks [C]//Media Watermarking,Security,and Forensics 2015.San Francisco:Society of Photo-Optical Instrumentation Engineers(SPIE),2015.https://www.spiedigitallibrary.org/conference-proceedings-of-spie/9409.toc#FrontMatterVolume9409.DOI:10.1117/12.2083479.
[4] KER A D. The Ultimate Steganalysis Benchmark? [C]// Proceedings of the 9th workshop on Multimedia & security. New York:Association for Computing Machinery,2007:141-148.
[5] SHIH F Y. Digital Watermarking and Steganography:Fundamentals and Techniques:Second edition [M].Boca Raton:CRC press,2017.
[6] KER A D. Estimating Steganographic Fisher Information in Real Images [C]// Information Hiding,11th International Workshop,IH 2009.Heidelberg:Springer-Verlag Berlin Heidelberg,2009:73-88.
[7] KER A D. Estimating the Information Theoretic Optimal Stego Noise [C]//Proceedings of The 8th Interntaional Workshop,IWDW 2009.Heidelberg:Springer-Verlag Berlin Heidelberg 2009:184-198.
[8] OU D H,SUN W. High Payload Image Steganography With Minimum Distortion based on Absolute Moment Block Truncation Coding [J].Multimedia Tools and Applications,2015,74(21):9117-9139.
[9] CHAKRABORTY S,JALAL A S,BHATNAGAR C. LSB based Non Blind Predictive Edge Adaptive Image Steganography [J].Multimedia Tools and Applications,2017,76(6):7973-7987.
作者簡介:曹寅(1997—),男,漢族,江蘇南京人,本科,研究方向:網(wǎng)絡(luò)空間安全;潘子宇(1984—),男,漢族,江蘇姜堰人,博士,副教授,研究方向:無線通信、5G安全技術(shù)等。
猜你喜歡
中國教育技術(shù)裝備(2016年19期)2016-12-27 19:23:52
中國遠(yuǎn)程教育(2016年11期)2016-12-27 18:07:31
現(xiàn)代商貿(mào)工業(yè)(2016年25期)2016-12-26 09:58:02
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:45:08
江蘇教育·中學(xué)教學(xué)版(2016年11期)2016-12-21 11:36:29
現(xiàn)代情報(2016年10期)2016-12-15 11:50:53
考試周刊(2016年94期)2016-12-12 12:15:04
新教育時代·教師版(2016年23期)2016-12-06 06:02:38
法制與社會(2016年32期)2016-12-01 15:25:53
軟件導(dǎo)刊(2016年9期)2016-11-07 22:20:49
