基于卷積神經網絡的文字識別優化方法研究
2020-01-07 07:21:18王雪冰姜道義張海洋
中國石油大學勝利學院學報 2019年4期
王雪冰,姜道義,張海洋
(中國石油大學勝利學院 基礎科學學院,山東 東營 257061)
從1958年感知器提出后,人們對于神經網絡的探索進入一個新的時代。但是感知器只能進行線性分類,不能應用于復雜的模式識別領域。1985年BP(back propagation)神經網絡的提出,系統解決了多層神經網絡隱含層連接權中的學習問題。但是在文字識別方面都沒有取得突破性的進展,直到第一個二維卷積神經網絡SIANN的出現才真正打開神經網絡在圖像識別領域的大門。文字識別的基本原理為將輸入文字與經神經網絡訓練的模型進行模式匹配,計算類似度,將具有最大類似度的文字作為識別結果[1]。計算機視覺在手寫數字識別中第一個取得巨大成就的是Yann LC等(1998)提出的LeNet-1卷積神經網絡系統,包含了兩個卷基層、兩個全連接層、六萬個學習參數。
1 人工神經網絡
人工神經網絡的發明起源于生物神經網絡,是一種模仿生物神經網絡結構及功能的數學模型和計算模型,可以根據外界的輸入信息改變內部神經節點的參數,具備學習功能。
人工神經網絡中由大量神經元相連接,能夠模仿人腦的信息處理功能對高復雜性信息進行處理,同時可以抽象出同類信息的模型,對新接收的信息進行分類。
2 卷積神經網絡
第一個卷積神經網絡是由Alexander W等(1987)提出的時間延遲網絡(time delay meural network, TDNN),主要應用于語音識別。Yann LC等(1998)提出的LeNet-5,實現手寫字體識別的功能,并且定義了現代卷積神經網絡的基本結構。CNN結構包括采樣層與卷積層,兩者交替而成[2]。
2.1 卷積神經網絡的結構
卷積神經網絡屬于前饋型神經網絡,具有平移旋轉不變性,所以非常適合圖片識別,能夠將不同方向的文字圖像準確地識別出來。使用卷積神經網絡進行識別的處理過程包括輸入、預處理、識別和后處理幾個過程[3]。
卷積神經網絡主要包含輸入層、卷積層層、Inception模塊、全連接層、輸出層。輸入層可以輸入多維數據,卷積層中包含卷積層和池化層,是進行計算的主要部分,全連接層競爭對輸出的響應機會,輸出層由邏輯函數輸出分類標簽。
2.2 輸入層
將需要識別的單字圖像輸入神經網絡,大小為64×64像素的灰度文字圖片,文字顏色為白色,文字背景為黑色。
64×64對應著神經網絡初始計算時圖像矩陣的大小;使用灰度圖是因為文字的表示不需要過多的參數,過多的顏色便會增加過多的影響因素,而灰度圖只有一個0~255的色階,大大降低了顏色給文字識別帶來的困難;本試驗只做文字的識別,所以在前期處理圖像時只將圖片中的文字凸顯出來,而其他的因素歸為噪聲全部被過濾。
2.3 隱藏層
隱藏層由3個卷積層和3個池化層交替組成,負責對圖片進行網絡計算分析。
第一層卷積層使用64個5×5的卷積核對輸入的64×64像素的圖像進行卷積運算,設輸入的圖片矩陣為A,并使用ai,j(i=0,1,…,63;j=0,1,…,63)表示A中的對應元素;設由第一層卷積層輸出的矩陣為B,并使用bi,j(i=0,1,…,59;j=0,1,…,59)表示經歷本次卷積輸出B的元素,由卷積的運算公式將A經運算轉換為B,輸入層和輸出層的各參數如表1所示,
(1)
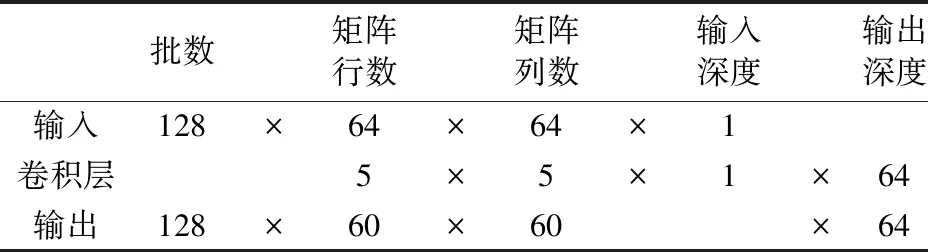
表1 第一層卷積尺寸計算
第一層池化層使用64個2×2的池化器對第一層卷積層輸出的60×60像素的圖像進行最大池化運算,輸入的是由第一層卷積后的矩陣B,設由第一層池化層輸出的矩陣為C,并使用Ci,j(i=0,1,…,29;j=0,1,…,29)表示經歷本次卷積輸出的元素。使用最大池化運算公式將計算第一次池化結果,
ci,j=max(bi+m,j+n),m=0,1;n=0,1.
(2)
池化運算各參數如表2所示。第二層卷積層使用128個5×5的卷積核對第一層池化層輸出的30×30像素的圖像進行卷積運算,第二層池化層使用128個2×2的池化器對第二層卷積層輸出的26×26像素的圖像進行最大池化運算,第三層卷積層使用256個4×4的卷積核對輸入的13×13像素的圖像進行卷積運算,第三層池化層使用256個2×2的池化器對第三層卷積層輸出的10×10像素的圖像進行最大池化運算。
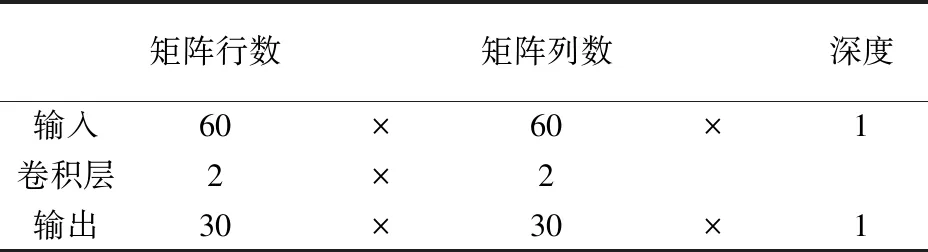
表2 第二層池化尺寸計算
2.4 全連接層
接收由隱藏層輸出的參數,并且通過ReLU函數計算神經元的興奮度。
激活函數公式為
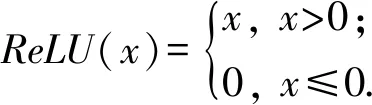
(3)
激活函數圖像[4]如圖1所示。
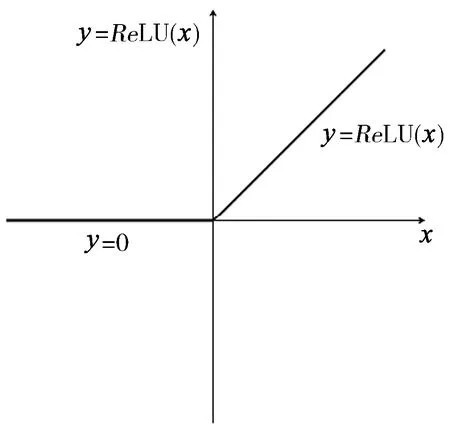
圖1 激活函數
由圖1可以看出ReLU函數是分段函數,把小于零的部分映射成為零,大于零的部分保持不變,這樣為單向抑制函數。
2.5 輸出層
輸出層一共有3 755個結點,分別對應3 755個漢字,通過分析全連接層輸入的興奮度,輸出識別出的相應漢字。
3 文字識別
3.1 數據集
3.1.1 數據集的分類
數據集包含3 755個常用漢字,每個漢字有60張不同方向并且漢字大小不一的灰度圖,每張圖片大小為64×64像素。數據集又分為訓練集和測試集,訓練集由48張圖片組成,測試集由12張圖片組成。每張圖片以.jpg形式存儲,圖片像素點為漢字筆畫則其像素為0像素值,背景圖部分為255像素值。
3.1.2 數據集的生成
數據集由自定義生成模塊生成,在生成模塊中可自動讀取不同字體的TTF文件來確定生成的字體類型,還可自定義生成數據集圖片的寬度、高度。并且默認每種字體下,每個字的數據圖片共生成不同的30張,這個生成數量限制為每個字最多45張。
每個漢字數據集圖片的數量可通過增加TTF字體文件個數來解決,本試驗默認使用方正宋體和黑體來建立數據集。
3.2 識別圖片去噪
圖像去噪是文字識別必不可少的環節,在此環節中需要將待識別圖像(圖2)轉化為計算機易于處理形式,并消除與識別內容無關的噪點(水印)。
文字識別的圖像不需要保留RGB顏色特征,灰度圖像即可以完整顯示文字特征,又能降低計算難度。在對圖片進行灰化處理的過程中,還需對顏色進行反轉,目的是使文字的顏色為淺色,背景為深色(圖3)。

圖2 待識別的文字圖像

圖3 二值化后的文字圖像
將圖片轉化為灰度圖以后,需要對圖像進行去燥處理。因為截取的圖片是文檔,所以不存在光線對文字色澤的影響,而圖片中以文字的淺色為主。灰化完成后,需要對圖片進行二值化處理,二值化的目的就是去除灰度處理后圖像殘存的模糊背景[5]。可以先對小于125以下的色階進行計數,然后取數量對多的色階為峰值,并向右取大于峰值百分之十的數值k為整個圖片進行分化的界限。以灰度像素值k為分界線,大于k的像素值轉化為255,小于k像素值轉化為0,此處理目的是增強圖像的對比度并且去除圖像噪聲對識別的影響(圖4)。

圖4 去燥后的文字圖像
3.3 文字切割及歸一化處理
(4)
M′=MG(gi∈G,gi=1).
(5)
借用光伏識別理論將圖片進行二值化,因為二值化后的圖像每個像素只包含一個灰度值,可以將圖片按照公式(4)轉化為二維矩陣M。
對矩陣依照求和公式(5)進行按行求和,因為含有漢字筆畫的每一行求和后的數值均不為零,只需確定映射后不為零的行便可以將圖片中每一行的漢字提取出來(圖5)。
同理每一行中也可以按照以上方法提取出單個文字(圖6)。但是有些漢字是左右結構,可能將一個字分成左右兩個漢字,需進一步判斷文字是否被分割成兩個。
如圖7所示,已經識別出需要分割的文字,但是可看出“別”字、“門”字被分割為兩個漢字,識別完后需要對分割出的字符進一步確認。取識別后行高的中位數為ptModeY,取識別后字寬的中位數為ptModeX。如果分割出圖片的寬度值比ptModeX大于20%,則將分割的結果舍棄;如果分割出圖片的寬度值不小于ptModeX的75%,則判斷此次分割正確,存儲分割后文字;如果分割出的圖片以及它之后圖片的寬度值的和小于ptModeX,則判斷這兩個分割圖片為一個字,并進行儲存。

圖5 提取行的文字圖像

圖6 識別出的文字
切割完的文字大小與輸入層需要的大小不一,需要經過歸一化處理。歸一化處理分為位置歸一化處理和大小歸一化,位置歸一化處理需要將文字的位置定位于圖片的中間,大小歸一化處理需要將圖像大小存儲為64×64像素[6]。
3.4 特征值提取和識別結果
特征提取是文字識別中最根本的一步,利用建立的卷積神經網絡對分割后的單字圖片做特征值提取,對已有的模型進行比對,識別出文字的結果(圖7)。
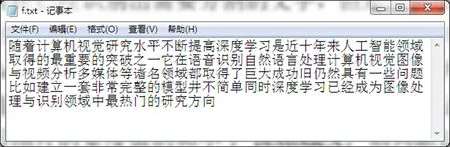
圖7 文字識別結果
4 結 論
(1)基于卷積神經網絡的漢字識別在常規理論條件下,準確率較高。但是本試驗針對數據集中每種文字圖片取樣數據偏少,圖片質量偏差的特殊情況,通過增加不同字體以增加數據集的方法研究,進一步優化識別的準確率和系統能力。
(2)文字的分割也是影響文字識別的重要因素,使用映射函數可以將排序整齊的文字切割,但對于多種復雜的情況卻束手無策。將識別-分割進行結合,針對識別相識度低,通過再將此部分文字進行組合識別模型構建研究,從而優化文字識別的等級。
