基于小波包與自適應維納濾波的語音增強算法
2020-01-10 06:38:30徐雨明馬振中李列文
計算機技術與發展 2020年1期
關鍵詞:信號
董 胡,徐雨明,馬振中,李列文,任 可
(1.長沙師范學院 信息科學與工程學院,湖南 長沙 410100;2.湖南師范大學 物理與電子科學學院,湖南 長沙 410181)
0 引 言
語音增強是語音和信號處理領域的一個重要問題,它對許多基于計算機的語音識別、編碼和通信應用都有一定的影響。語音增強的根本目標是提高語音質量和清晰度以被人類監聽者感知到。語音增強算法包含傳統的譜減法[1-3]、維納濾波法[4-6]、小波系數閾值法[7-9]、子空間法[10-11]及近年來提出的深度神經網絡法[12]等。這些語音增強算法或是基于統計模型或基于語音與噪聲的先驗信息,在一定程度上改善了含噪語音的質量。然而,在復雜噪聲環境下,尤其是在非平穩噪聲環境下它們的語音增強性能出現下降。針對上述問題,文中提出了一種基于小波包和自適應維納濾波的語音增強算法。
1 小波包變換
小波包變換是一種直觀且有效的語音增強方法。語音與噪聲的小波包變換所表現的特性截然相反,語音信號小波包變換的模值隨小波尺度的增加而遞增,但噪聲的模值卻隨小波包尺度的增加而遞減。這樣,接連多次小波包變換后,噪聲對應的小波包系數基本被去除或者幅值非常小,剩余系數主要由語音信號控制。利用較顯著的語音小波包系數來重構語音信號,進而較好地去除噪聲。
小波包由兩組正交小波基濾波器系數生成。若{hk}k∈z和{gk}k∈z是一組共軛鏡像濾波器(QMF),滿足:
(1)
gk=(-1)kh1-k,l,k∈z
(2)
小波包與小波分解不同,它不僅對低頻信號部分作分解,還對高頻信號部分作分解,因此小波包是一種比小波更加精細的分解算法[13]。圖1為小波包對一維時間序列分解特性圖,其中A代表低頻,D代表高頻,末尾下標序號代表小波包分解的層數。三層小波包分解關系為:
S=AAA3+DAA3+ADA3+DDA3+AAD3+DAD3+ADD3+DDD3
(3)
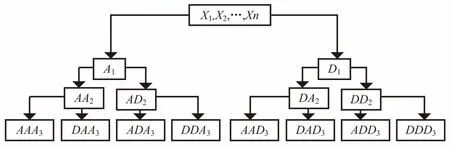
圖1 小波包時間序列分解
2 自適應維納濾波


圖2 自適應維納濾波語音增強

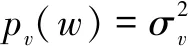
(4)
考慮到x(n)中一小段語音信號是平穩的,則x(n)可表達如下:
x(n)=mx+σxw(n)
(5)
其中,mx和σx分別表示x(n)的局部均值和標準偏差;w(n)表示零均值的單位噪聲變量。
采用“直接判別”算法來預估當前幀的先驗信息[14]。在一小段語音中,維納濾波轉換方程可近似作如下表達:
(6)
由式6可得維納濾波脈沖響應:
(7)
由式7可知,局部增強的語音信號可表達如下:
(8)
假設每一幀語音信號的mx和σs都得到更新,增強的信號可表達如下:
(9)
由式9可得,x(n)的局部均值變量mx為:
(10)

(11)

(12)
3 小波包與自適應維納濾波語音增強算法
小波包變換具有能量集中特性,文中采用db10小波包進行多尺度分解。含噪語音信號經過小波包變換時,噪聲的能量集中在高頻部分且幅值較小的小波包系數上,而語音信號的能量則集中分布在低頻部分且幅值較大的小波包系數上。語音信號的小波包系數值大于噪聲的小波包系數值,因此通過小波包變換能夠實現語音與噪聲的分離。通過db10小波包的分解將含噪信號作頻率譜劃分得到不同尺度的小波包系數,然后對各個尺度的系數作自適應維納濾波增強,最后將增強后的小波包系數進行重構即可得增強后的語音信號。整個語音增強算法的流程見圖3。
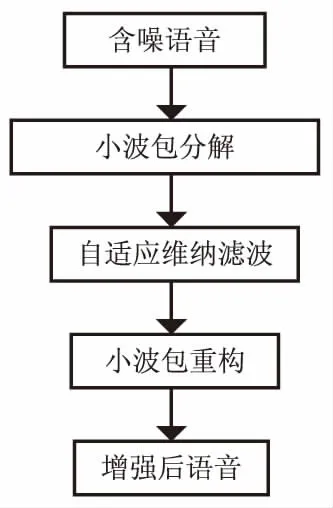
圖3 小波包與自適應維納濾波語音增強算法流程
4 仿真實驗與分析
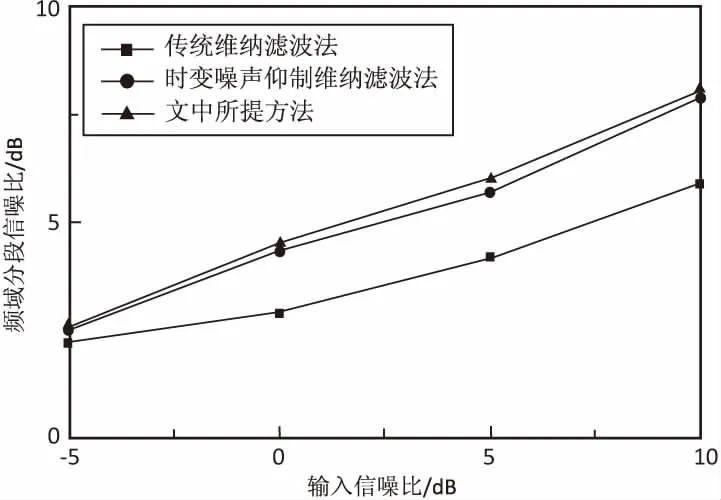
為驗證所提算法的增強效果,利用MATLAB軟件開展仿真實驗。實驗中使用錄制的語音作為純凈語音樣本。噪聲信號取自NOISEX-92數據庫中的白噪聲、babble噪聲、pink噪聲和factory噪聲。純凈語音和噪聲的采樣頻率都為16 kHz,16 bit量化,將純凈語音與上述不同類型的噪聲進行混合,合成信噪比不同的含噪信號。每幀信號幀長為15 ms,幀移為50%。為突出所提語音增強算法的有效性,分別將其與傳統維納濾波、文獻[15]提出的時變噪聲抑制維納濾波進行比較,計算增強后語音的頻域分段信噪比及客觀語音質量評估(PESQ)。3種語音增強算法的頻域分段信噪比如圖4所示,圖4(a)~圖4(d)分別為白噪聲、babble噪聲、pink噪聲和factory噪聲條件下,3種語音增強算法的頻域分段信噪比圖。
(a)白噪聲

(b)babble噪聲

(c)pink噪聲

(d)factory噪聲
從圖4可知,與傳統維納濾波算法比較,所提語音增強算法及文獻[15]提出的時變噪聲抑制維納濾波算法頻域分段信噪比較高,在低信噪比情況下尤為明顯。文獻[15]與所提語音增強算法相比,在白噪聲和pink噪聲條件下,其分段信噪比效果較接近,然而在babble和factory的非平穩噪聲條件下,所提語音增強算法的分段信噪比較高,平均約高出0.5 dB。
3種不同算法語音增強后的PESQ如表1所示。由于傳統維納濾波在非平穩的噪聲(factory、babble噪聲)環境下會對含噪語音產生過分抑制,容易造成語音失真和產生音樂噪聲,在表1中也分別給出了其他兩種語音增強算法的PESQ值。經主觀聽測表明,采用傳統維納濾波語音增強后有較明顯的音樂噪聲,而采用文中算法和文獻[15]算法后都能較好地抑制音樂噪聲,其PESQ均高于傳統的維納濾波。其中,文中的語音增強算法的PESQ亦高于文獻[15]提出的語音增強算法。
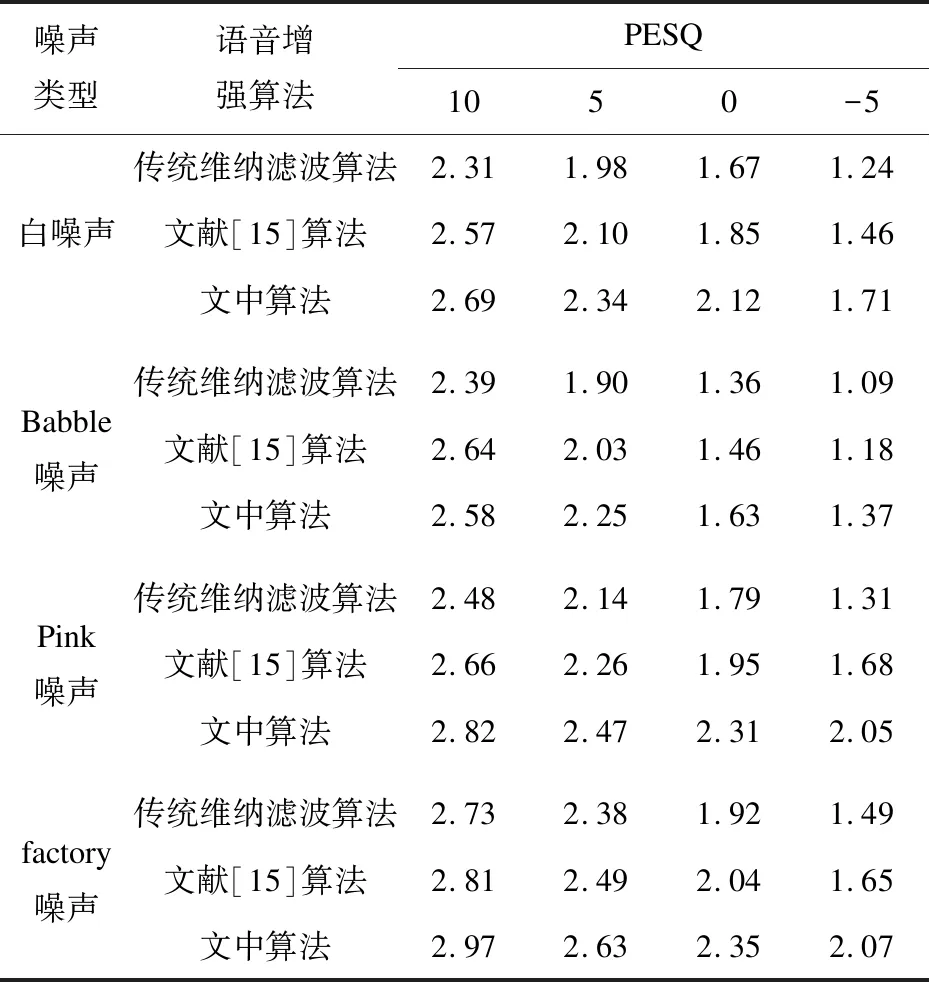
表1 3種語音增強算法PSEQ比較
圖5比較了3種語音增強算法的語譜圖。其中,圖5(a)是含pink噪聲(SNR=-5 dB)語譜圖,圖5(b)、圖5(c)和圖5(d)分別為經過傳統維納濾波、文獻[15]算法及文中算法的語音增強語譜圖。

(a)含-5 dB pink噪聲語譜圖
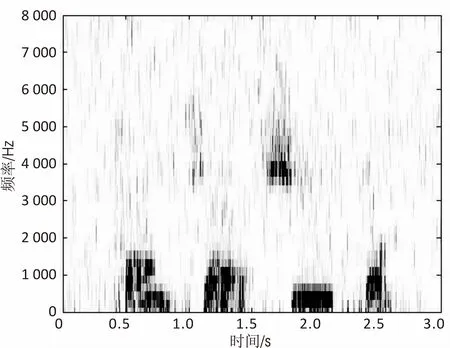
(b)傳統維納濾波算法

(c)文獻[15]算法

(d)文中算法
從圖5可知,與圖5(b)相比較,圖5(c)與圖5(d)在較好地去除背景pink噪聲的同時,更好地保留了語音的諧波成分,而圖5(b)則有較明顯的語音失真。圖5(d)與圖5(c)相比,圖5(d)保留了較弱的語音部分的譜特征,提高了增強后的語音質量。
5 結束語
提出的小波包和自適應維納濾波算法結合了小波包和自適應維納濾波兩種算法的優點,利用小波包變換對非平穩的含噪信號作分解處理從而實現噪聲和語音的初級分離,然后利用自適應維納濾波作進一步降噪處理,在較低信噪比的非平穩噪聲環境下,對語音的損傷相對較小,較好地抑制了音樂噪聲的產生,語音增強效果較明顯。文中算法比傳統維納濾波算法、文獻[15]算法具有更高頻域分段信噪比及PESQ,且主觀試聽上也無明顯的音樂噪聲。因此,該算法在降低音樂噪聲的基礎上提升了語音增強效果。
猜你喜歡
鴨綠江(2021年35期)2021-04-19 12:24:18
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
媽媽寶寶(2019年10期)2019-10-26 02:45:34
中國生殖健康(2019年3期)2019-02-01 06:12:26
鐵道通信信號(2018年11期)2019-01-19 01:15:08
電子制作(2018年11期)2018-08-04 03:25:42
鐵道通信信號(2018年2期)2018-04-18 12:18:10
鐵道通信信號(2016年11期)2016-06-01 12:11:32
鑿巖機械氣動工具(2016年3期)2016-03-01 04:00:25
中國病理生理雜志(2015年8期)2015-12-21 12:38:06
