基于核極限學習機自編碼多標記學習
2020-01-14 01:07:28李存志孟金彪
數字通信世界 2019年12期
李存志,錢 萌,孟金彪
(安慶師范大學計算機與信息學院,安慶 246133)
1 引言
近年來多標記學習逐漸成為數據挖掘和信息檢索的重要主題,是機器學習的熱點之一。多標記學習任務的步驟為:每個樣本都有對應的訓練集數據,使用一定的算法可以在訓練集數據的基礎上獲得有效的模型,通過模型進而推斷甚至預測未知新樣本所屬的類別,得到其所在的標記集合。
自編碼神經網絡類似無監督學習范式,可以從大規模數據中提取有效特征。為此不斷有學者對自編碼神經網絡進行了改進,例如:黃廣斌等提出的ELM 算法因為它沒有迭代過程,這是與傳統的神經網絡算法最大的不同,因此相比較而言ELM 的訓練速度更加快,空間代替時間的思想使它的泛化能力更強。分析可得,基于特征以及標記關系結合重新分析得到的結果能夠一定程度提升算法的分類能力。基于此本文提出一種核極限學習機自編碼多標記學習算法,在輸入層中加入標記節點信息,輸出帶有特征與標記關系的特征。在分類過程中使用奇異值分解作為線性分類器。
2 相關理論介紹
2.1 多標記學習理論

目前算法基于思想上的區別可分為:算法適應型和問題轉化型。
2.2 核極限學習機理論
ELM 作為一種快速的前饋單隱藏層神經網絡學習算法,隱藏層的參數并不是固定的,因此算法只需要設置合適的神經元的個數,使用指定的算法實現求出輸出權重值,此過程一直到結束不需要做任何的調整。因此,與傳統的神經網絡算法相比,在訓練速度和準確性上都有一定的優勢,但結果較為不穩定。
在傳統的ELM 算法中計算結果容易受到隱藏層個數和隨機權重和偏置的影響,而核矩陣可以解決這一問題,則核ELM 神經網絡f(x)可以表示為:
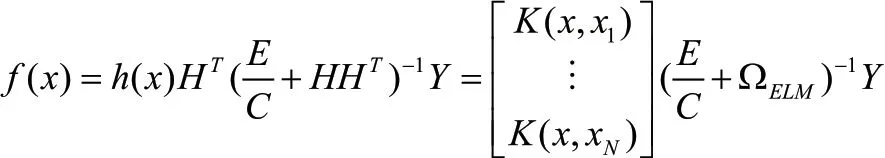
3 核極限學習機自編碼多標記算法
3.1 自編碼神經網絡
自編碼網絡由三部分構成(輸入層、輸出層、輸出重構),自編碼器由編碼器(encoder)部分和解碼器(decoder)部分構成,其將輸入樣本數據進行壓縮操作之后到隱藏層之后重新解壓映射回輸出層。作為深度學習學習中一種無需標記的無監督特征學習方法,自編碼器能夠有效地提取數據特征內在的聯系。
3.2 學習算法建模
本文提出的核極限學習機自編碼算法是一種半監督學習范式,我們在輸入層特征集中加入標記信息為標記空間計算每個標記樣本集合值的求和結果,這樣避免了標記節點加入導致維度過高帶來的維度災難問題。此時輸入的特征X 表示為:,其中把Xi作為輸入特征,則極限學習機模型可表示為:

將這種轉化特征作線性分類器的特征輸入可以表示為:
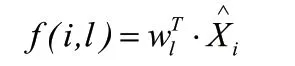
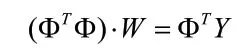

4 實驗及其結果分析
4.1 實驗數據集描述
本 文 選 取Emotions,Natural scene 和Yeast 共 3 個Mulan 數據集以及Yahoo Web Pages 的5個數據集一共8個數據集。
4.2 實驗環境及評價指標
實驗代碼均在Matlab2016a 中運行。本文選取了Average Precision,Coverage,Hamming Loss 等幾種評價準則對標記學習算法進行結果評測,用來檢驗算法的性能。為方便,分別簡寫為:AP ↑、CV ↓、HL ↓。(備注↑字符標識代表此標準數據越大越好,↓字符標識次標準數據越小越好)。設多標記分類器,預測函數,排序函數,多標記數據集
4.3 算法選擇與相關參數設置
將本文算法與4 個多標記分類算法做對比實驗,分別是MLKNN,IMLLA,RankSVM 和MLFE。在ML-KELMAE 算法中正則項系數C=1,核函數選擇RBF 核,核參數σ 選自{0.2,0.5,1,2}之間。在ML-KNN 算法中近鄰個數k 和平滑參數s 分別設為10和1。在RankSVM 算法中,其代價損失參數設為1,核函數選擇RBF 核。在IMMLA 算法中平滑參數s 設為1,近鄰空間數k 設為10。在MLFE 算法中,核函數選擇RBF,核參數β1,β2和β3選自{1,2,…,10},{1,10,15}和{1,10}之間分別在訓練集上進行交叉驗證。
4.4 實驗結果與分析
下表給出了本文算法和其他4種算法在本文使用數據集上實驗結果。其中下標表示的是各個算法在實驗數據結果上的排序,其中得分越高算法性能越優。
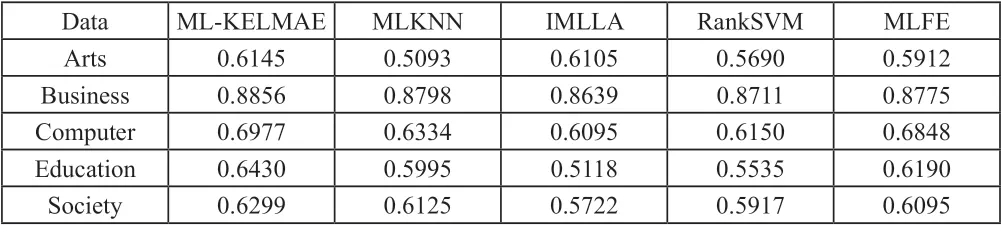
表1 分類算法在本文使用數據集上的平均精度結果對比

表2 分類算法在本文使用數據集上的覆蓋率結果對比

表3 分類算法在本文使用數據集上的海明損失結果對比(↓)
5 結束語
多標記分類學習中關于特征信息與標記相關性的研究非常重要。本文提出一種新的多標記學習算法,在輸入層中加入標記節點信息,輸出帶有特征與標記關系特征的半監督學習。多個多標記基準數據集上的結果顯示,本文的方法具有一定的優勢。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
