基于BBS-LDA的論壇主題挖掘
2020-01-15 03:23:12
浙江工業大學學報 2020年1期
(浙江工業大學 計算機科學與技術學院,浙江 杭州 310023)
如今,互聯網正飛速地發展,網絡已成為網民接收和傳播信息的主要途徑。通過網絡,每個網民都可以在極短的時間內了解到全國各地最新的事件,并實時地對這些事件發表自己的感想,也可以把自己了解到的事件分享給其他人。在這種形勢下,網絡文本的挖掘成了如今科學研究的一大熱點。如何從海量文本中提取出有價值的信息一直是一件很有挑戰的事情。文本不同于一般的數值型數據,表示和處理都比較復雜。空間向量模型(Vector space model)把文本中的每個詞語映射到向量空間,這使得文本可以通過傳統的數值型數據挖掘算法來處理,不過對于海量數據,會面臨維度災難。TF-IDF[1]等方法利用了詞的詞頻信息和逆文檔頻信息,能夠快速提取文章的關鍵字,不過單純以詞頻度量詞的重要性不夠全面,而且不能夠處理同義詞的情況。近年來,主題模型在文本挖掘中得到了不錯的運用,其中最具有代表性的就是潛在狄利克雷分配(Latent Dirichlet allocation,LDA)。如今,已經有許多針對不同語料特點改進的LDA模型被用在了情感分析、輿情控制和個性化推薦上。
對于論壇文本,因為其本身具有一些結構化信息,使用原始的LDA模型并不能夠最大化地利用文本信息來挖掘主題。論壇里面可能會存在大量的短回復和水帖,短回復會造成詞的稀疏性,水帖會給主題挖掘帶來很多噪音,這些因素都極大地影響了LDA在論壇上的建模效果。針對論壇的這些特點,對LDA作出了改進。經真實文本數據試驗證明,改進后的主題模型能夠提升在論壇語料上的主題挖掘能力。
1 相關工作
論壇文本因為有著天然的版塊區分,很適合針對性地挖掘一些信息。目前針對論壇文本的研究比較少,不過文本挖掘是一個比較經典的研究問題,許多學者的研究都能夠很方便地應用到論壇文本上。
文本摘要是文本挖掘中一個熱門的研究方向。通過多文檔摘要,可以從大量的文本中獲取相對比較重要的文本,這使得讀者能夠更加快捷地消化這些文本數據。Slamet等[2]通過TF-IDF獲取關鍵詞和詞權重,之后借助空間向量模型獲取文本之間的關系,以實現文本的自動摘要。劉端陽等[3]在TF-IDF的基礎上引入了語義詞典和詞匯鏈,能夠緩解自動摘要中同義詞冗余表達的缺點。余珊珊等[4]結合了中文的結構特點,提出了iTextRank算法,在中文新聞的摘要上取得了不錯的效果。
對論壇進行文本摘要往往只能從大量論壇文本中抽取重要的內容,并不能對主題進行區分。論壇的主題挖掘相對而言更加困難。潛在語義索引(Latent semantic indexing, LSI)[5]是一個可以挖掘文檔主題的方法,它是主題模型的雛形,LSI通過奇異值分解(SVD)的方法對文檔進行降維,把單詞空間映射到主題空間,通過它可以獲取最有可能代表文章主題的詞語,不過LSI計算比較復雜,而且不易針對文章的特點進行修改。Hofmann[6]提出了概率潛在語義分析(Probabilistic latent semantic analysis,PLSA),通過概率統計來獲取代表文檔主題的詞語,不過PLSA比較容易過擬合,泛化能力比較差。
Blei等[7]在PLSA的基礎上加上了先驗,提出了潛在狄利克雷分布模型(Latent Dirichlet allocation, LDA),一定程度上克服了PLSA泛化能力差的問題。LDA是一種針對離散數據的概率生成模型,也是一種由文檔、主題、詞組成的3 層貝葉斯概率模型。LDA采用了詞袋(Bag of words)的方式來描述文本,這種方式把獨立的文檔轉化成了一個個詞頻向量,從而使文本信息便于建模。詞袋法沒有考慮文檔中詞的順序信息,大大降低了問題的復雜性。
對某些語料直接應用LDA效果不是很好,比如短文本,其原因是短文本中每個文本所含的信息量太少,詞袋間詞共現數太少,模型生成會遇到數據稀疏問題。有人提出了一些有效的解決方案。最簡單的方式就是把短文本拼接成長文本,Hong等[8]發現,通過把短的Tweet文本拼接成長的文本,以長文本來訓練主題模型能夠獲取更高質量的主題。Zhao等[9]在分析Twitter的時候,認為在大多數情況下,一條Tweet只包含一個主題,以此提出了Twitter-LDA,經過測試,Twitter-LDA在挖掘主題的準確性上比原始的LDA提升了31%。Balikas等[10]在分析文本的時候采用了和Twitter-LDA類似的方法,在提出的Sentense LDA中,把同一個句子中的詞語歸到同一個主題。結果表明用詞袋來表示文本會丟失詞在文本段(句子或者詞組)的共現信息。Yan等[11]用一個新的主題模型BTM(Biterm topic model)來處理短文本,BTM直接對共現詞對(biterms)進行建模,通過匯聚語料中的共現詞實現對短語建模的目的,解決了詞在文檔層面共現的稀疏性問題。BTM被廣泛用在短信、微博等短文本主題挖掘上[12]。
根據語料的結構和特點對主題模型進行合理改進,不僅能夠讓主題模型學習新的東西,也能夠提升主題模型的挖掘效果。Rosen-zvi等[13]提出的ATM(Author topic model)把作者信息加入到LDA,這使得模型不僅能夠從文本中挖掘主題,也能夠學習某個作者經常寫哪些主題的文章。Lin等[14]提出了JST(Joint sentiment/Topic model)模型,JST模型在LDA模型的基礎上加了一層情感層,通過新增的情感層,JST能夠同時挖掘文本的主題信息和情感信息。JST被用在了電影評論上,對文本的情感分類取得了不錯的效果。Xiong等[15]提出的WSTM(Word-pair sentiment-topic model)在BTM上加入了情感層,克服了JST面對短文本效果不佳的問題。Lim等[16]通過把好友關系、主題標簽、關注和被關注信息整合到LDA中,構建出TN(Twitter-network topic model)模型。TN模型被實驗證實能夠更有效地挖掘主題和用戶信息,被用于用戶推薦。
結合文本特點對主題建模已經成了主流的趨勢。論壇語料最大的特點就是存在很多水帖。如果直接對論壇文本進行建模,可能達不到比較理想的效果。筆者利用論壇帖子的用戶特征,在對主題建模的同時,能夠發現論壇語料的無意義回復以及回復中的背景詞,更加有效地挖掘論壇主題。
2 論壇主題挖掘
2.1 論壇主題挖掘難點分析
論壇一般分版塊,每個版塊有一個大主題,比如經濟、體育等。用戶發帖時,一般會先根據自己想發的內容,選擇一個版塊進行發帖。帖子的主題和版塊的主題相關。對于論壇的主題挖掘,主要研究的是同一個版塊內的主題挖掘,這樣不可避免會遇到主題相似的問題。
論壇的每個帖子包含正文和別人對帖子的一系列回復。對于一個帖子的正文和所有回復,其主題分布一致,通用的主題模型并不會考慮論壇的這些特征。
論壇文本的更新非常迅速,用戶一般喜歡用比較簡單的語言描述一件事情,很少有長篇大論,所以論壇的回復一般都比較短。直接使用LDA對短文本進行分析會遇到數據稀疏的問題,導致挖掘效果不好。
論壇的口語化現象比較嚴重,文本中濫用標點、錯別字現象比較普遍,而且有些板塊(比如金融)會存在很多專有名詞,所以對于不同的論壇版塊,應該做不同的預處理。可以把一些常用的表達整理出來,加入到分詞工具的詞典里,提高分詞準確性,這一步很難做到無監督。
論壇中存在著部分的水帖和推廣貼,這會給主題的挖掘帶來很大的噪聲。如果有一個人經常發無意義的帖子,那么這個人新發的帖子極有可能也是無意義的。可以在主題模型中引入用戶的信息,提高主題挖掘的準確性。
2.2 BBS-LDA
根據2.1節的分析,筆者提出了BBS-LDA模型。BBS-LDA的圖模型見圖1,圖模型中所用到的符號含義見表1。
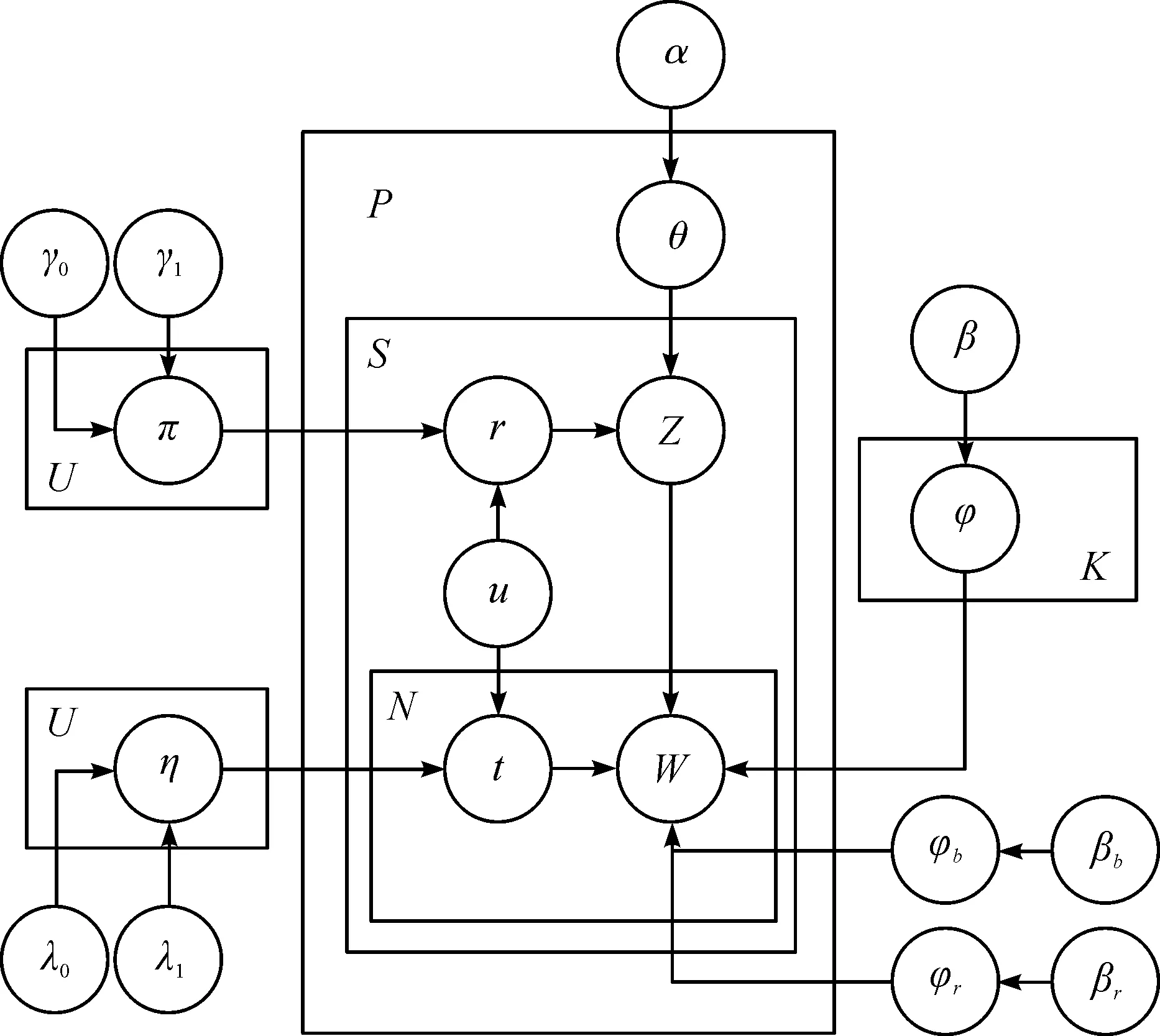
圖1 BBS-LDA的圖模型Fig.1 BBS-LDA graphical model

表1 BBS-LDA的參數含義Table 1 Parameter meaning of BBS-LDA
該模型和LDA模型一樣屬于生成模型,它假設語料是根據一定的概率分布生成的,可以據此對文本數據進行建模,得到變量之間的條件概率分布,這在此模型中具體指每個詞屬于不同主題的概率分布。圖模型表示的語料的生成過程為
1) 對于每個主題k∈[1,K]
采樣其詞分布φk~Dirichlet (β)
2) 采樣無意義的詞分布φr~Dirichlet (βr)
3) 采樣背景詞分布φb~Dirichlet (βb)
4) 對于每個用戶u∈[1,U]
采樣標記變量分布πu~Beta (γ)
采樣標記變量分布ηu~Beta (λ)
5) 對于每個帖子p∈[1,P]
采樣其主題分布θp~Dirichlet (α)
對于帖子中的每個句子s∈[1,Sp]
采樣標記變量rp,s~Bernoulli (πu)
如果rp,s=1
采樣該句子的主題zp,s~Multinomial (θp)
對于每個詞w∈[1,Ns]
采樣標記變量tp,s,w~Bernoulli (ηu)
如果tp,s,w=0
采樣詞w~Multinomial (φb)
否則如果rp,s=0
采樣詞w~Multinomial (φr)
否則
采樣詞w~Multinomial (φzp,s)
對比原始LDA,BBS-LDA主要有3點與之不同。第1點是以句子為單位,每個句子的主題只采樣一次,每個帖子中的句子具有相同的主題分布,這樣的做法考慮了論壇文本的結構特性,并且可以緩解單條回復字數少導致的稀疏性問題。第2點是句子中的詞分為兩部分,一部分屬于背景詞,一部分屬于主題詞。這個做法與Twitter-LDA的做法差不多,唯一的不同是在Twitter-LDA中,η對于所有文本都是相同的,而在BBS-LDA中,對于每個用戶,η都是不同的,因為不同的人,寫作習慣是不同的。通過這樣的做法,可以對文本中的背景詞進行建模,增加模型在相同版塊不同主題的區分能力。第3點是增加了一個標記變量r來識別句子是否有主題,這個想法是受文獻[17]啟發得到的,同樣的,對于每個不同的用戶,π的值是不同的,因為有的用戶可能會經常回水帖,而有的用戶發的回復可能基本上都是和主題相關的。
2.3 BBS-LDA的參數估計
LDA主題模型的參數都比較復雜,不能夠被精確算出,一般使用一些近似的方法估計得到。最常用的方法有變分推理(Variational inference)和塌陷吉布斯采樣(Collapsed Gibbs sampling)[18]。筆者使用塌陷吉布斯采樣估計模型中的參數。
1) 首先,需要推導每個句子屬于對應主題的概率。為了簡化這個問題,可以先忽略句子中的背景詞,因為背景詞與主題無關。根據模型的生成過程,整個文本集的生成概率為
(1)
展開式(1)第3項,即
(2)
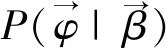
(3)
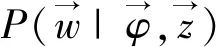
(4)
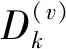
把式(3,4)代入式(2)之后,可以得到
(5)
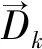
同理,可以得到
(6)
(7)
(8)
在采樣過程中,對于一個句子,先采樣r,然后根據r判斷句子是不是有意義的,如果有意義,則從以α為參數的Dirichlet分布中再采樣z,否則句子直接屬于無意義主題,無意義主題記為zr,則此時P(zr|r=0)=1,則有
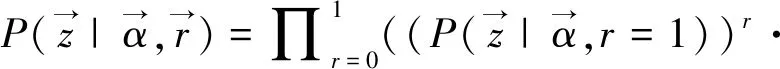
(9)
所以,整個文本集生成的概率為
(10)
由此,可以開始采樣第p個帖子中第s個句子所對應的標記變量rp,s和句子的主題zp,s。當rp,s=1時,句子主題為k的概率計算為
(11)
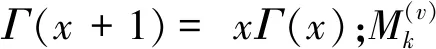
rp,s=0的概率計算為
(12)
式中:C表示當前采樣句子中無意義詞的個數;C(v)表示當前采樣句子中的詞v屬于無意義詞的個數。
之后,對句子中的每個詞進行采樣(單詞計為x,單詞的序號為i)。
2) 現在考慮文本集的時候不忽略背景詞,則文本集的生成概率為
(13)
因為此時句子的主題已采樣,所以式(13)中的前兩項與單詞是否是背景詞的概率無關,把它記為(*)。
與式(5)的推導相同,可以得到
(14)
(15)
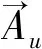
將式(5,8,14,15)代入式(13),可得
(16)
詞x屬于背景詞的概率為
(17)
如果該單詞所在的句子對應的標志變量rp,s=1,且zp,s=k,同理可得
(18)
如果該單詞所在的句子對應的標志變量rp,s=0,同理可得
(19)
等采樣收斂之后,因為Dirichlet分布和多項分布共軛,各個隱藏變量的估計值為
(20)
(21)
(22)
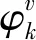
2.4 垃圾回復識別
直接使用模型對文檔進行建模,在辨別回復是否為有意義的回復上準確度不是很高。識別部分比較明顯的垃圾回復能夠為模型提供部分監督信息,有利于更好地對文本進行建模。在模型參數估計的過程中,如果該條回復已經根據監督信息被標記為無意義的回復,則直接把該條回復對應的標記變量r賦值為1。如果該條回復沒有被標記,則需要通過采樣算法來決定r的值。根據觀察發現,論壇的垃圾回復主要有兩種:第一種是一些過短回復,基本不包含什么語義,只是為了頂貼或者水帖而發表的回復;第二種是推廣。
對于第一種垃圾回復,其文本中一般會包含一些高頻率詞,比如說“頂”“紫薯補丁”。所以篩選了字數小于10的一些回復,經分詞之后統計高頻詞,經篩選形成一份詞典。對于新的文本數據,可以通過以下方式判斷是否為這一類垃圾回復:首先對文本進行分詞,根據回復的詞數篩選出過短回復;之后判斷該回復中是否包含詞典中的高頻詞,如果是,則該條回復為垃圾回復。
對于第二種推廣類型的回復,也有一個特點,就是不經過大幅度修改直接重復粘貼,且多為同一個人發出。對于這些水帖,可以在數據庫中對每個用戶的回復進行遍歷(爬取語料的時候保留用戶信息),查找文本中相似度比較高的回復,并對這些回復進行標記。計算語句的相似度主要有基于相同詞的方法、基于向量空間的方法和基于局部敏感哈希(LSH)的方法[19]。筆者使用Simhash[20]來查找重復回復,它是一種典型的基于局部敏感哈希的算法,計算效率較高,更適合處理大規模文本。對于每個用戶的所有發言,使用Simhash計算它們的哈希值,然后遍歷,尋找相似度高于一定閾值的發言,如果這些彼此相似的發言數量大于這個閾值,則標記為垃圾回復。需要注意的是,在這里尋找相似回復的范圍是一個用戶的所有回復,而不是所有用戶,因為在一個帖子中,可能會出現多個用戶因為共鳴等原因發出相似的發言,而這些發言并不一定是垃圾回復。
3 實驗與分析
3.1 數據準備
3.1.1 數據采集
為了驗證BBS-LDA的主題挖掘能力,筆者爬取了天涯論壇的百姓聲音版塊的帖子作為實驗數據。同一個版塊的不同主題可能會含有很多共用詞語,這樣的數據能夠很好地區分不同主題模型對于挖掘相同版塊近似主題的能力。筆者爬取了2018年1—6月的所有帖子,爬取的內容見表2。

表2 爬蟲爬取的內容Table 2 Content we crawl through the crawler
3.1.2 數據預處理
首先,對文本進行分詞。中文分詞主要有基于詞典匹配[21]的方法和基于統計的方法。筆者使用了開源的Jieba分詞,它結合了詞典和隱馬爾科夫模型,分詞準確度較高。分詞后根據詞的詞性保留動詞、名詞、形容詞等重要詞性的詞,刪除了數詞、介詞、量詞等不包含語義信息的詞。
分詞后對詞語進行去停用詞操作。停用詞是一些對語義沒幫助的詞。對于中文,現在已經有比較全的停用詞庫,比如“哈工大停用詞詞庫”“百度停用詞表”,筆者對這些停用詞庫進行了整合,并做了去重的工作。
之后,使用2.4節的方法進行垃圾回復的標記。對長度低于10的回復分詞之后進行了統計,高頻詞見表3(只列出前8項)。

表3 短回復高頻詞列表Table 3 High frequency word list of short response
從表3中可以憑經驗分辨出哪些詞大概率是水貼,哪些詞和板塊的大背景切合。經過篩選,把腐敗、貪官等詞移除,構建出一個詞典,根據這個詞典把所有大概率可能是水帖的短回復做好標記。隨后,通過Simhash找到每個用戶發表的相似帖子,把重復數高于5的重復帖子標記為無意義回復。最后,統計各個詞語的詞頻,把低于5的低頻詞刪除,去除低頻詞有助于提高主題模型的效率。預處理之后數據的統計信息見表4,以下實驗都是基于這些數據完成的。

表4 數據的統計信息Table 4 Data statistics
3.2 實驗結果
本次實驗將BBS-LDA和下面兩種主題模型進行對比。模型所用的語料相同,均為上述處理后的語料。不過不同模型對應的輸入不同,所以對于不同模型,需要在語料格式上做一些改動。
1) LDA:原始的LDA,因為LDA對于短文本效果不太好,這里把每個帖子的正文和回復拼成一起,當成一個單獨的文檔來進行實驗。
2) Twitter-LDA:原始的Twitter-LDA是以用戶作為聚簇,把每個用戶的發言作為一個文檔,用戶發的每條Tweet中的所有詞主題相同。這里以帖子作為聚簇,每個帖子的所有回復作為一個文檔,每條回復中的所有詞主題相同。
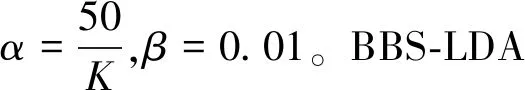
主題模型的效果一般可以使用困惑度(Perplexity)來進行評估。困惑度常用來度量概率圖模型的性能,它的值代表著預測數據時的不確定度。困惑度越小,就代表著模型的效果越好。困惑度的計算公式為
(23)
式中:Nd代表第d個文檔所包含的詞數;p(wd)代表文檔d生成的概率。
隨著迭代次數的增加,不同主題模型在同一個測試數據集上的困惑度變化如圖2所示。

圖2 不同模型困惑度隨迭代次數的變化Fig.2 The perplexity of different models changes with the number of iterations
從圖2中可以看到:3 個模型隨著迭代次數的增加,困惑度都逐漸降低,迭代500 次之后模型已經收斂,BBS-LDA的困惑度比Twitter-LDA和原始LDA的困惑度都低,說明BBS-LDA有更好的泛化能力。
主題相似度可以度量主題模型對于不同主題的區分能力,它也是主題模型的一個常用的評估手段。一般用KL散度來度量主題間的相似程度。KL距離越大,代表兩個主題間的相似度越小,不同主題間的區分度更加好。
主題k1和k2的KL距離的計算公式為
(24)
因為KL距離不是對稱的,所以這里計算兩個主題之間距離的時候對兩者的KL距離取平均,即
Distance (k1,k2)=(KL(k1,k2)+
KL(k2,k1))/2
(25)
在模型收斂之后分別計算模型的兩兩主題間的平均距離,結果如表5所示。

表5 不同模型主題間的平均距離Table 5 Average distance between different model topics
最后,直觀地對3 個主題模型挖掘的主題進行對比(隨機抽取了5 個主題),結果如表6所示。
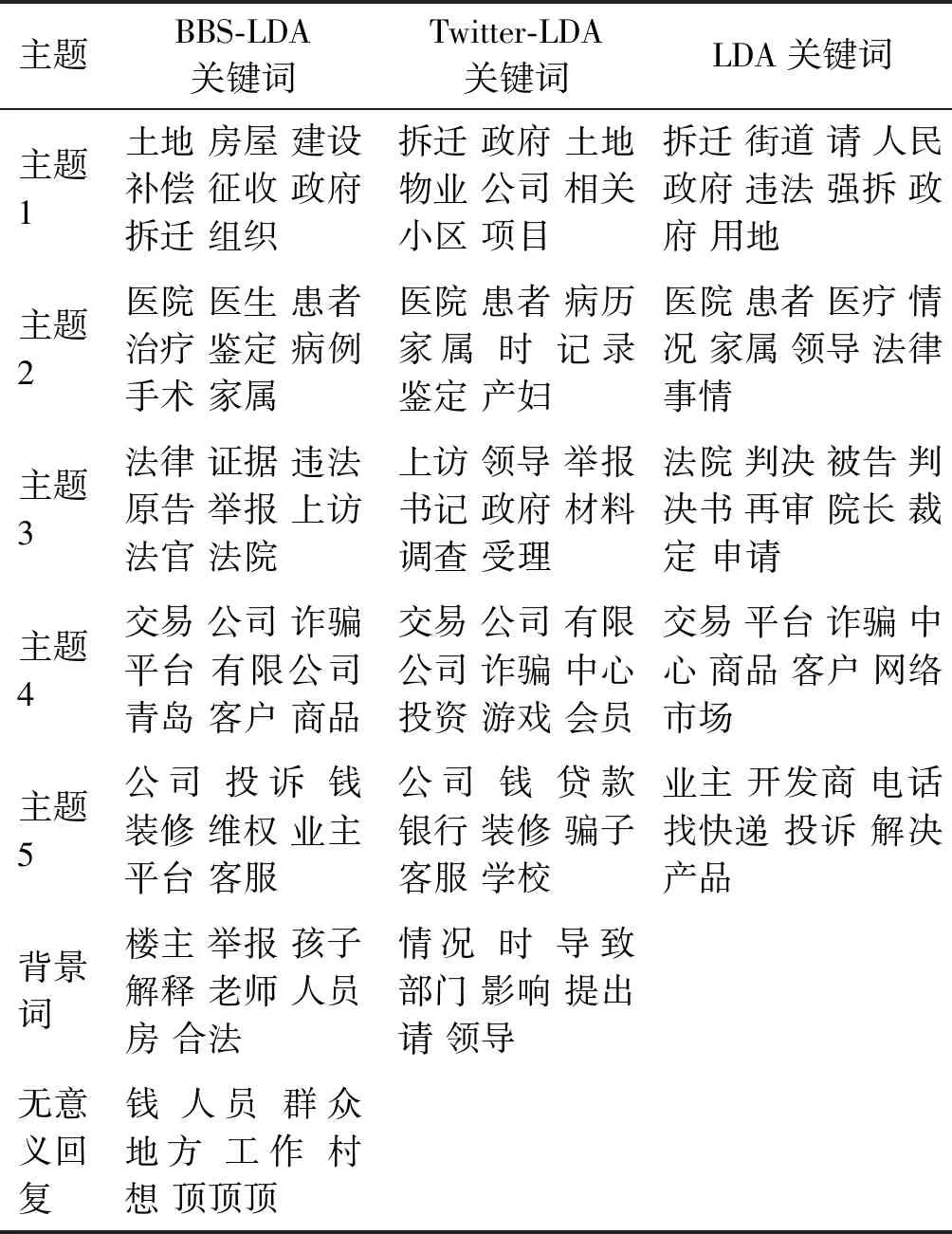
表6 不同主題模型關鍵字對比Table 6 Keyword comparison between different topic models
從表6可以看到:3 個模型都能夠比較好地挖掘文章的主題。其中,BBS-LDA因為綜合考慮了論壇的結構特性和用戶的信息,關鍵詞質量最高。同時,BBS-LDA還在一定程度上識別了背景詞和一些無意義的回復,這個是很有意義的。
4 結 論
論壇是人們獲取和發布信息的主要途徑之一,挖掘論壇的文本信息對于輿情監控、市場調研等有著重要的意義。根據論壇的一系列特點,基于LDA提出了新的BBS-LDA主題模型,并通過Gibbs sampling對模型進行推導。經過實際論壇語料試驗表明:BBS-LDA不僅具有良好的主題挖掘能力,還能夠在一定程度上識別文章的無意義回復和背景詞。下一步工作將研究如何把時間和BBS-LDA結合在一起,讓該主題模型能挖掘出更多信息,更實用。
猜你喜歡
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
小學教學參考(2015年20期)2016-01-15 08:44:38
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
