基于邏輯回歸模型的校園個性化學(xué)習(xí)資源推薦系統(tǒng)
2020-01-16 07:39:48湯懷
電子技術(shù)與軟件工程 2019年22期
文/湯懷
在大學(xué)校園,通常學(xué)生利用在線學(xué)習(xí)資源的模式為:不管學(xué)生測試成績結(jié)果如何,學(xué)習(xí)資源平臺給學(xué)生的學(xué)習(xí)內(nèi)容都是一致的,這對學(xué)習(xí)基礎(chǔ)薄弱的學(xué)生,將會被打擊學(xué)習(xí)的自信心和學(xué)習(xí)動力,而基礎(chǔ)較好的學(xué)生又無法得到更加豐富的資源,無法促進(jìn)對學(xué)科的深入學(xué)習(xí)。隨著互聯(lián)網(wǎng)技術(shù)在教育領(lǐng)域應(yīng)用的深入,學(xué)習(xí)者的學(xué)習(xí)方式有很多改變。從老師面對面解惑答疑到上網(wǎng)搜索資料進(jìn)行在線學(xué)習(xí),互聯(lián)網(wǎng)+教育為學(xué)習(xí)者提供了多樣化的學(xué)習(xí)途徑。不斷快速增長的學(xué)習(xí)資源(包括線上線下資源),讓學(xué)習(xí)者面臨著“信息過載”和“信息迷航”的困惑。面對海量的學(xué)習(xí)資源,如何在有限的時間內(nèi),挖掘和推薦出與學(xué)習(xí)者自身匹配的學(xué)習(xí)資源,是教育信息化領(lǐng)域面臨的一種挑戰(zhàn)。教學(xué)資源推薦系統(tǒng)是近年來國內(nèi)外的研究熱點,在國內(nèi),學(xué)習(xí)資源的推薦系統(tǒng)也有相關(guān)的研究,例如:沈陽師范大學(xué)的鄭清雅發(fā)表的《云計算環(huán)境下基于學(xué)習(xí)風(fēng)格的教學(xué)資源推薦系統(tǒng)設(shè)計與實現(xiàn)》文章中,提出基于物品的協(xié)同過濾的推薦算法,將風(fēng)格類似的學(xué)習(xí)者分組而進(jìn)行資源推薦;云南大學(xué)的王曉康發(fā)表的《移動環(huán)境下的個性化學(xué)習(xí)資源推薦策略研究》文章中,提出學(xué)習(xí)者移動情景特征和資源特征的關(guān)聯(lián)度,采用協(xié)同過濾算法進(jìn)行推薦。基于學(xué)習(xí)風(fēng)格的推薦系統(tǒng),需要能夠采集到大量的用戶信息,若自動采集會造成千篇一律無法實現(xiàn)個性化,而讓用戶主觀提供,采集的樣本數(shù)據(jù)又而基于評分系統(tǒng)的學(xué)習(xí)者模型將學(xué)習(xí)資源進(jìn)行評分;而協(xié)同過濾推薦主要需要大量的社會化標(biāo)簽,而采集在校學(xué)生在學(xué)習(xí)方面的數(shù)據(jù)較少。然而在校學(xué)生采用測試的方式檢測學(xué)生學(xué)習(xí)成果是最多的,并產(chǎn)生大量的測試評分?jǐn)?shù)據(jù),以提升學(xué)習(xí)者的學(xué)習(xí)效率為目標(biāo),采用邏輯回歸模型不斷迭代,應(yīng)用測試結(jié)果對學(xué)生的學(xué)習(xí)情況進(jìn)行多次二分類,根據(jù)分類結(jié)果進(jìn)行學(xué)習(xí)資源主動推薦,以提高學(xué)習(xí)者測驗分?jǐn)?shù)的期望值為目標(biāo),從而構(gòu)建個性化的學(xué)習(xí)資源推薦系統(tǒng)。
1 基于評分系統(tǒng)的學(xué)習(xí)者模型
在使用協(xié)同過濾推薦算法構(gòu)建學(xué)習(xí)者模型時,主要根據(jù)學(xué)習(xí)者的社會化標(biāo)簽、學(xué)習(xí)風(fēng)格、認(rèn)知水平等因素進(jìn)行推薦,這類推薦主要應(yīng)用在廣泛互聯(lián)網(wǎng)中的學(xué)習(xí)資源平臺。而對于校園內(nèi)部的學(xué)習(xí)資源推薦,主要建立在學(xué)習(xí)者差異化的情況下進(jìn)行自主學(xué)習(xí)的方式,將可以更好利用學(xué)習(xí)者在學(xué)習(xí)平臺保存的歷史數(shù)據(jù)來客觀顯現(xiàn)評分。構(gòu)建更具個性化的學(xué)習(xí)者模型,需要對學(xué)習(xí)者賦予初始化數(shù)據(jù)、對產(chǎn)生變換的數(shù)據(jù)進(jìn)行及時變更,將學(xué)習(xí)風(fēng)格、學(xué)習(xí)行為、測試結(jié)果、自我評價等方面進(jìn)行評分而不斷迭代,從而不斷刷新推薦結(jié)果,建立基于大數(shù)據(jù)的個性化學(xué)習(xí)者模式,不斷干預(yù)和改進(jìn)學(xué)生學(xué)習(xí)路徑。例如,一位學(xué)生某門課程考試成績不及格,此時應(yīng)該推薦該學(xué)科較為基礎(chǔ)的學(xué)習(xí)資源;而當(dāng)一位學(xué)生在某門課程考試成績達(dá)到優(yōu)秀時,應(yīng)該對應(yīng)推薦進(jìn)級的學(xué)習(xí)資源,從而實現(xiàn)個性化和差異化、個性化學(xué)習(xí)路徑生成的學(xué)習(xí)資源推薦系統(tǒng),基于評分系統(tǒng)的學(xué)習(xí)者模型示例如圖1所示。
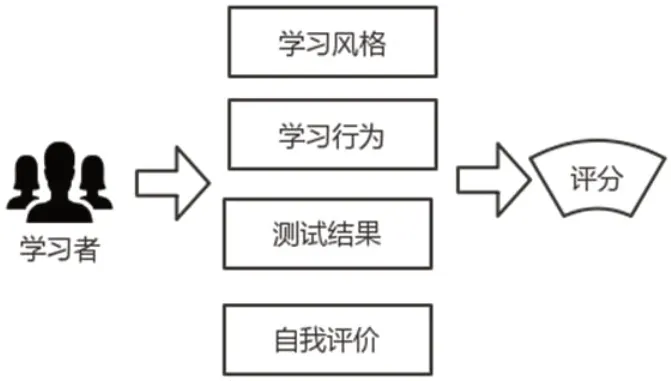
圖1:基于評分系統(tǒng)的學(xué)習(xí)者模型
2 學(xué)習(xí)資源建模
多數(shù)的學(xué)習(xí)資源都是建立在學(xué)習(xí)者的需求上,并作為學(xué)習(xí)者學(xué)習(xí)和交流的媒介,系統(tǒng)中的學(xué)習(xí)資源之間是離散的,在大數(shù)據(jù)視閾下,需要對學(xué)習(xí)資源進(jìn)行統(tǒng)一管理和歸類,進(jìn)行學(xué)習(xí)資源屬性、效能、類型的大數(shù)據(jù)分析。在統(tǒng)一化的學(xué)習(xí)資源推薦中,學(xué)習(xí)者接收到的資源都是統(tǒng)一的。而個性化學(xué)習(xí)資源平臺以學(xué)習(xí)者為中心,需要重新對學(xué)習(xí)資源進(jìn)行建模,通過社會化標(biāo)簽實現(xiàn)學(xué)習(xí)者與學(xué)習(xí)資源建立起聯(lián)系。例如,學(xué)習(xí)者通過測試成績,系統(tǒng)除了可以推斷對哪些學(xué)習(xí)資源有需求,對哪些知識點有欠缺,同時根據(jù)測試題目的水平,產(chǎn)生一個資源評分,即需求評分,從而構(gòu)建評分矩陣,累計到該用戶的學(xué)習(xí)資源評分中,再形成鄰居矩陣,產(chǎn)生相似性鄰居時,能夠產(chǎn)生更精確的數(shù)據(jù),推薦更符合目標(biāo)用戶需求的學(xué)習(xí)資源。例如用戶U 在學(xué)習(xí)完資源X 后,進(jìn)行了評分,給予該資源10 分,并瀏覽和分享了該資源,產(chǎn)生隱性評分 5 分,總分15 分。假如學(xué)習(xí)者在自我測試中,做錯了層次較難的測試題,此測試題設(shè)置的社會化標(biāo)簽匹配學(xué)習(xí)資源X,故用戶U 對資源X 的實際評分為 15+5*0.9=19.5。 在個性化學(xué)習(xí)資源推薦模塊中,根據(jù)學(xué)習(xí)資源特征以及與測試題社會化標(biāo)簽的對應(yīng)關(guān)系,形成個性化學(xué)習(xí)資源推薦學(xué)習(xí)資源模型。
3 基于邏輯回歸模型的應(yīng)用
回歸指的是在二維空間中有一些數(shù)據(jù)點,用一條直線來擬合這些數(shù)據(jù)點經(jīng)過的路徑。而邏輯回歸(Logistic Regression)是一個分類模型,需要在樣本進(jìn)入模型之后給出分類標(biāo)簽。所以邏輯回歸對于回歸得到的數(shù)值會進(jìn)行一個處理,使之變成0 和1 這樣的標(biāo)簽。這個梳理就是將得到的數(shù)值輸入到一個函數(shù)中,這個函數(shù)就是單位階躍sigmoid 函數(shù)。在學(xué)習(xí)資源推薦系統(tǒng)中,預(yù)測的過程實質(zhì)就是一個二分類的問題,主要就是判定一個學(xué)習(xí)資源對學(xué)習(xí)者學(xué)習(xí)某個知識的作用,是有用還是沒有。而這個過程是一個伯努利函數(shù),整個過程是一個伯努利分布:

而在邏輯回歸中主要是在線性回歸的基礎(chǔ)上利用了一個邏輯函數(shù)sigmoid 階躍函數(shù),當(dāng)輸入為0的時候,值為0.5,而輸入>0的部分,很快便逼近于1,輸入< 0 的部分,很快便逼近于0。其工作流程首先對數(shù)據(jù)進(jìn)行一個擬合,不管是二維空間里 y = k * x + b 這樣的直線,還是三維空間里y = a1 * x1 + b2 * x2 + c 的平面,或是更高維度需要學(xué)習(xí)更多的參數(shù)。像y = k * x + b 中的k、b,像三維空間里平面 y = a1 * x1 + b2 * x2 + c 這里面的a1、b2、c 這樣的參數(shù)都是需要學(xué)習(xí)的。學(xué)習(xí)完這些參數(shù)之后,也就得到了模型。得到模型之后,用參數(shù)與輸入的特征進(jìn)行相乘,同時將得到的數(shù)值放入單位階躍函數(shù)中得到類別。
4 個性化學(xué)習(xí)資源推薦系統(tǒng)
隨著信息技術(shù)和互聯(lián)網(wǎng)技術(shù)的發(fā)展,人們從信息匱乏時代步入了信息過載時代,在這種時代背景下,人們越來越難從大量的信息中找到自身感興趣的信息,信息也越來越難展示給可能對它感興趣的用戶,而推薦系統(tǒng)的任務(wù)就是連接用戶和信息,創(chuàng)造價值。推薦系統(tǒng)主要用來預(yù)測使用者對于他們還沒有見到或了解的事物的喜好。由于網(wǎng)絡(luò)信息的復(fù)雜性和動態(tài)性,推薦系統(tǒng)成為解決信息過載問題的有效途徑。作為一種信息過濾系統(tǒng),推薦系統(tǒng)具有以下兩個最顯著的特性:
(1)主動化。從用戶角度考慮,門戶網(wǎng)站和搜索引擎都是解決信息過載的有效方式,但它們都需要用戶提供明確需求,當(dāng)用戶無法準(zhǔn)確描述自己的需求時,這兩種方式就無法為用戶提供精確的服務(wù)。而推薦系統(tǒng)不需要用戶提供明確的需求,而是通過分析用戶和物品的數(shù)據(jù),對用戶和物品進(jìn)行建模,從而主動為用戶推薦他們感興趣的信息。
(2)個性化。推薦系統(tǒng)能夠更好的發(fā)掘長尾信息,即將修改化信息推薦給用戶。熱門信息通常代表絕大多數(shù)用戶的興趣,而冷門信息代表小部分用戶的個性化需求,在大數(shù)據(jù)火熱的時代,發(fā)掘個性化信息是推薦系統(tǒng)的重要研究方向。校園個性化學(xué)習(xí)資源推薦系統(tǒng)是一個應(yīng)用于校園內(nèi)部的教學(xué)資源的分布式資源管理與推薦系統(tǒng),主要包括用戶管理、資源管理、教學(xué)效果檢測管理、教學(xué)資源推薦等模塊,構(gòu)建個性化推薦模型主要是根據(jù)不斷迭代更新的測試評分?jǐn)?shù)據(jù),應(yīng)用邏輯回歸模型,將對知識點的掌握情況將測試者進(jìn)行二分類,而知識點事先進(jìn)行邏輯分類,并根據(jù)測試者的測試結(jié)果,再次進(jìn)行分類,同時依據(jù)個人特殊值標(biāo)簽進(jìn)行智能化的預(yù)測結(jié)果,將學(xué)習(xí)資源分類預(yù)測結(jié)果推薦給用戶。以用戶使用推薦的學(xué)習(xí)資源后進(jìn)行測試的評分結(jié)果作為輸入,系統(tǒng)對推薦的內(nèi)容與學(xué)習(xí)完后的測試結(jié)果進(jìn)行大數(shù)據(jù)分析,給推薦結(jié)果進(jìn)行評分,并結(jié)合用戶的評價進(jìn)行推薦效果的綜合檢測。
5 結(jié)束語
在大數(shù)據(jù)時代背景下,建立個性化的學(xué)習(xí)資源推薦系統(tǒng),全過程采集學(xué)習(xí)者評分測試等特征數(shù)據(jù),基于評分系統(tǒng)的學(xué)習(xí)者模型,動態(tài)分析學(xué)習(xí)者學(xué)習(xí)行為及各類評分?jǐn)?shù)據(jù),全面評價學(xué)習(xí)者學(xué)習(xí)結(jié)果,構(gòu)建學(xué)習(xí)資源系統(tǒng),采用邏輯回歸模型不斷迭代對學(xué)習(xí)者及學(xué)習(xí)資源進(jìn)行多次二分類,解決數(shù)據(jù)離散問題,根據(jù)分類結(jié)果進(jìn)行學(xué)習(xí)資源主動推薦,以提升學(xué)習(xí)者測驗分?jǐn)?shù)的期望值為目標(biāo),構(gòu)建個性化的學(xué)習(xí)資源推薦系統(tǒng)。
猜你喜歡
吉林廣播電視大學(xué)學(xué)報(2021年4期)2022-01-14 02:35:48
作文成功之路·小學(xué)版(2020年5期)2020-06-11 12:48:26
小天使·一年級語數(shù)英綜合(2018年11期)2018-11-23 09:47:26
中華手工(2017年2期)2017-06-06 23:00:31
資源再生(2017年3期)2017-06-01 12:20:59
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創(chuàng)業(yè)家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
