基于BERT的用戶畫像
2020-01-18 05:52:00翟劍鋒
電子技術與軟件工程 2019年24期
文/翟劍鋒
計算機和互聯網技術的快速發展給人們的學習、生活帶來了極大的便利的同時,也帶來了數據爆炸式的增長。面對海量數據,信息處理的效率較低,人們往往沒有辦法快速獲得精準數據。分析這些海量數據可以挖掘出用戶基本的屬性信息和潛在的興趣偏好,給人們提供重大的幫助,用戶畫像及其相關技術在這種背景下應運而生。如何從數據中抽取中所需的用戶特征,構建精準的用戶畫像值得進行深入研究。BERT模型對遮擋語言模型和下一個句子預測任務同時進行訓練,能夠更好的獲取上下文信息,學習句內和句間關系。本文研究了基于BERT預訓練模型的用戶畫像相關問題,在一定程度上能夠解決一詞多義問題,更好的抽取用戶特征并進行實驗分析。
1 相關工作
用戶畫像是指根據用戶的屬性、用戶偏好、生活習慣、用戶行為等信息而抽象出來的標簽化用戶模型。標簽通常是人為規定的高度精煉的特征標識,如年齡、性別、地域、興趣等。每個標簽分別描述了該用戶的一個維度,各個維度之間相互聯系,共同構成對用戶的整體描述,可以更容易理解用戶,并且更方便計算機處理。如何通過一定的機器學習方法從預處理的數據中抽取出所需要用戶特征,是構建用戶畫像的關鍵問題。簡而言之,創建用戶畫像的過程就是依據所構建用戶模型在用戶信息中得到特征并將特征標簽化的過程。
吳桐水和賀亮[1]基于決策樹的航空公司客戶流失分析,為航空公司客戶流失采取改進措施。Slanzi,Balazs 和 Velasquez[2]對預測Web用戶點擊意圖的方法,用邏輯回歸提升推薦能力。Torres-Valencia,álvarez 和 álvaro[3]將支持向量機作為分類器提取用戶的情感特征。Kuzma 和 Andrejková[4]使用神經網絡模型提取用戶偏好特征。蔡國永和夏彬彬[5]利用卷積神經網絡捕捉文本情感特征和圖像情感特征之間的內部聯系,更準確地實現對圖文融合媒體情感的預測。付鵬,林政和袁鳳程等[6]提出基于卷積神經網絡的方法解決短文本特征抽取及特征稀疏問題。

圖1:BERT預訓練語言模型

圖2:Transformer編碼器
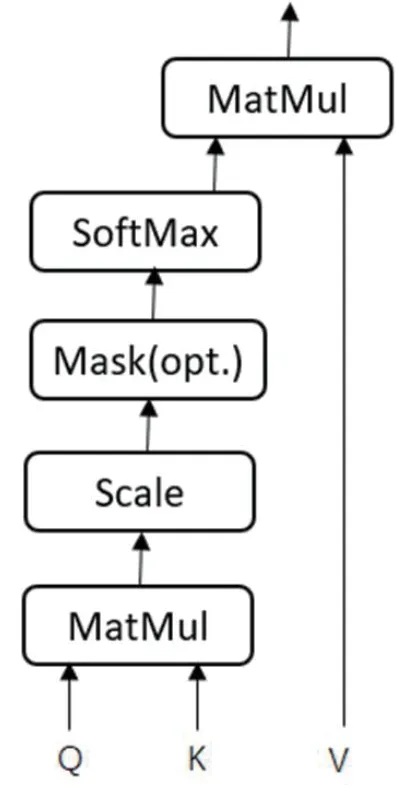
圖3:自注意力機制

圖4:流程圖
近年來,隨著深度學習在自然語言處理領域的快速發展,Bengio[7]等人提出詞向量的概念,用低維的實向量表征詞語的語義信息,并將語義相似的詞語映射到向量空間中距離相近的位置。大多數現有的詞向量已經獲得了廣泛的應用,但大多數詞嵌入方法都是假定用每個詞能夠用單個向量代表,無法解決一詞多義和同音異議的問題。多原型向量空間模型[8]是將一個單詞的上下文分成不同的組,然后為每個組生成不同的原型向量。遵循這個想法,Huang[9]等人提出了基于神經語言模型的多原型詞嵌入。Liu Y[10]等人采用潛在的主題模型為文本語料庫中的每個詞分配主題,并基于詞和主題來學習主題詞向量。李雅坤[11]引入詞向量,共同與特征向量構成文本特征向量,構建基于搜索引擎的用戶畫像。BERT[12]預訓練語言模型通常采用大規模、與特定任務無關的文本語料進行訓練,使模型輸出的詞向量表示盡可能全面、準確地刻畫輸入文本的整體信息,為后續的具體任務微調參數初始值。本文利用基于BERT預訓練語言模型來構建用戶畫像,通過TF-IDF值進行詞向量語義加權得到用戶特征,對用戶特征用隨機森林進行分類并進行實驗分析。

表1:不同算法的分類性能
2 基于BERT的用戶畫像模型描述
2.1 BERT模型
為了獲得更好的詞分布式表示,Google提出的BERT預訓練語言模型在11個NLP任務上的表現刷新了記錄,充分利用詞左右兩邊的信息,能夠更好的解決一詞多義問題,結構如圖1所示。
為了更好的獲取上下文信息,學習句內和句間關系,BERT模型對兩個任務同時進行訓練,分別是遮擋語言模型和下一個句子預測任務。遮擋語言模型不同于常見的利用上文預測下一個單詞或者利用上文和下文預測中間詞的語言模型,遮擋語言模型隨機遮擋一定比例的單詞,利用其余單詞預測這些遮擋詞,由于遮擋詞的位置是隨機的,被遮擋的詞可能是句子的任何成分,避免模型利用數據集的偏差,從而強迫模型從句子整體學習上下文的信息達到雙向編碼的效果。
為了讓模型擁有更好的語義理解能力,同時訓練下一個句子預測任務來學習句子之間的特征。下一個句子預測任務可以等效成句子級的二分類問題,輸入兩個句子,判斷第二個句子是不是第一個句子的正確合理的下一句。
BERT預訓練語言模型使用 Transformer 模型的編碼器部分,其每個單元僅由自注意力機制和前饋神經網絡構成,一次性讀取整個文本序列,而不是從左到右或從右到左地按順序讀取。這個特征使得模型能夠基于單詞的兩側學習,相當于是一個雙向的功能,可以更直接地捕捉詞與詞之間的關系,從而使序列的編碼更具整體性,更能代表整個序列的含義。其結構如圖2所示。
Transformer 中最主要模塊的是自注意力部分。注意力機制可以描述為給定一個查詢(Query)和一個鍵值表(Key-Value pairs),將Query映射到正確輸入的過程,此處的Query、Key、Value和最終輸出都是向量矩陣。輸出往往是一個加權求和的形式,而權重則由Query、Key和Value決定,其輸出向量不但包含該詞本身,還包含其它詞與這個詞的關系,自注意力機制是指使用序列自身和自身進行注意力處理,即Q=K=V,其結構如圖3所示,公式為:

其中 均是輸入字向量矩陣,dk為輸入向量維度。
BERT預訓練模型使用了由多個自注意力機制構成的多頭注意力機制,擴展模型專注于不同位置的能力,用于獲取句子級別的語義信息,如公式(2)(3)所示。

時序特征是自然語言的一個重要特征,而自注意力機制無法獲取時序特征,Transformer采用位置嵌入的方式表示時序信息,如公式(4)(5)所示。

2.2 隨機森林
隨機森林是一種基于Bagging的集成學習算法,將多棵決策樹進行整合來完成預測。對于分類問題預測結果是所有決策樹預測結果的投票;對于回歸問題,是所有決策樹預測結果的均值。訓練時,通過Bootstrap抽樣來形成每棵決策樹的訓練集,則對于一個輸入樣本,有多少棵決策樹就會有多少個分類結果,隨機森林將投票次數最多的類別指定為最終的輸出。假設N表示訓練用例(樣本)個數,M表示特征數目,隨機森林的構建過程如下:
(1)輸入特征數目m,用于確定決策樹上一個節點的決策結果;其中m應遠小于M。
(2)從N中以有放回抽樣的方式,取樣N次,形成一個訓練集,并用未抽到的用例(樣本)作預測,評估其誤差。
(3)對于每一個節點,隨機選擇m個特征,決策樹上每個節點的決定都是基于這些特征確定的。根據m個特征,計算其最佳的分裂方式。
(4)每棵樹都會完整成長而不會剪枝;
(5)將生成的多棵決策樹組成隨機森林。對于分類問題,按多棵樹分類器投票決定最終分類結果;對于回歸問題,由多棵樹預測值的均值決定最終預測結果。
2.3 基于BERT的用戶畫像模型
BERT模型主要分兩個部分,一個是訓練語言模型的預訓練部分,另一個是訓練具體任務的fine-tune部分。由于預訓練過程需要耗費大量的運算資源,直接在Google發布的BERT預訓練模型基礎上對自有的數據集進行fine-tune。本文利用基于BERT預訓練語言模型來構建用戶畫像,通過TF-IDF值進行詞向量語義加權得到用戶特征,對用戶特征用隨機森林進行分類,模型大體框架如圖4所示。
3 實驗結果與分析
實驗數據集來源于中國計算機學會組織的大數據競賽。實驗數據包括10萬條,提供用戶歷史一個月的查詢詞與用戶的人口屬性標簽(包括性別、年齡、學歷)作為訓練數據,對新增用戶的人口屬性,即年齡、性別、學歷的判斷。
Google 提供的預訓練語言模型分為兩種,兩種模型網絡結構相同,實驗中采用的是BERT-Base,默認使用12頭注意力機制的Transformer,預訓練詞向量長度為768維,最大序列長度為128,每批次大小為64,學習率為5×10-5。
評價指標采用查準率(P),用于表示模型對樣本分類的正確比率、召回率(R)用于表明模型對樣本的識別程度。將基于BERT的方法同Word2Vec詞向量、LDA+Word2Vec詞向量的方法進行比較,三種模型都使用隨機森林分類器對用戶的基本屬性進行分類,本文采用的方法的各項評價指標都要高于其它兩種方法,具體如表1所示。
4 結束語
本文研究了基于BERT預訓練模型的用戶畫像相關問題,BERT模型對遮擋語言模型和下一個句子預測任務同時進行訓練,能夠更好的獲取上下文信息,學習句內和句間關系。相比于傳統的詞向量,BERT在一定程度上能夠解決一詞多義問題,更好的抽取用戶特征。實驗表明,基于BERT預訓練模型在處理用戶畫像上能夠達到較好的效果。由于數據集中文本的內容與用戶屬性存在一定的偏差,數據中的噪聲較大,數據存在不平衡,需要進一步提高用戶畫像的分類精度。
猜你喜歡
文苑(2020年4期)2020-05-30 12:35:30
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小學生作文(中高年級適用)(2018年3期)2018-04-18 01:24:47
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
華北電力大學學報(社會科學版)(2016年4期)2016-12-01 03:59:30
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
少兒科學周刊·少年版(2015年4期)2015-07-07 21:11:17
