Graphcore:IPU開啟AI研發與應用的新篇章
2020-02-08 08:41:35齊健
智能制造 2020年9期
齊健
Graphcore是一家總部位于英國的創新公司,其主要業務是研發專門應用于AI技術的創新芯片——IPU(Intelligence Processing Unit)。自2016年成立以來,就受到了業界、市場和資本的高度關注。截至目前,Graphcore的總融資額超過4.5億美金,其全球辦公室遍布歐洲、亞洲和北美。
隨著Graphcore IPU(智能處理器)硬件及其開發軟件Poplar在人工智能行業的日益升溫,日前,Graphcore又發布了Graphcore IPU的第二代產品Colossus Mk2 GC200,以及可以用于大規模系統級產品的IPU- Machine: M2000(IPU-M2000)。第二代IPU具有更強的處理能力、更多的內存和內置的可擴展性,可處理龐大的機器智能工作負載。
“從單一芯片來看,Colossus Mk2 GC200處理器是目前世界上最復雜的單一處理器,基于臺積電的7納米技術,我們在一顆823平方毫米的IPU處理器中集成了將近600億個晶體管。Colossus Mk2 GC200擁有250 TFlops AI-Float的算力和900MB的處理器內存儲。處理器內核從第一代IPU的1 217個獨立的處理器內核提升到了1 472個,這樣一個IPU處理器有將近9 000個單獨的并行線程。相對于第一代產品,其系統級的性能提升了8倍以上。”Graphcore高級副總裁兼中國區總經理盧濤介紹說。
IPU處理器的顛覆性突破
相比于Graphcore的第一代IPU產品,Colossus Mk2 GC200在技術上實現了三大顛覆性的突破:計算、數據和通信。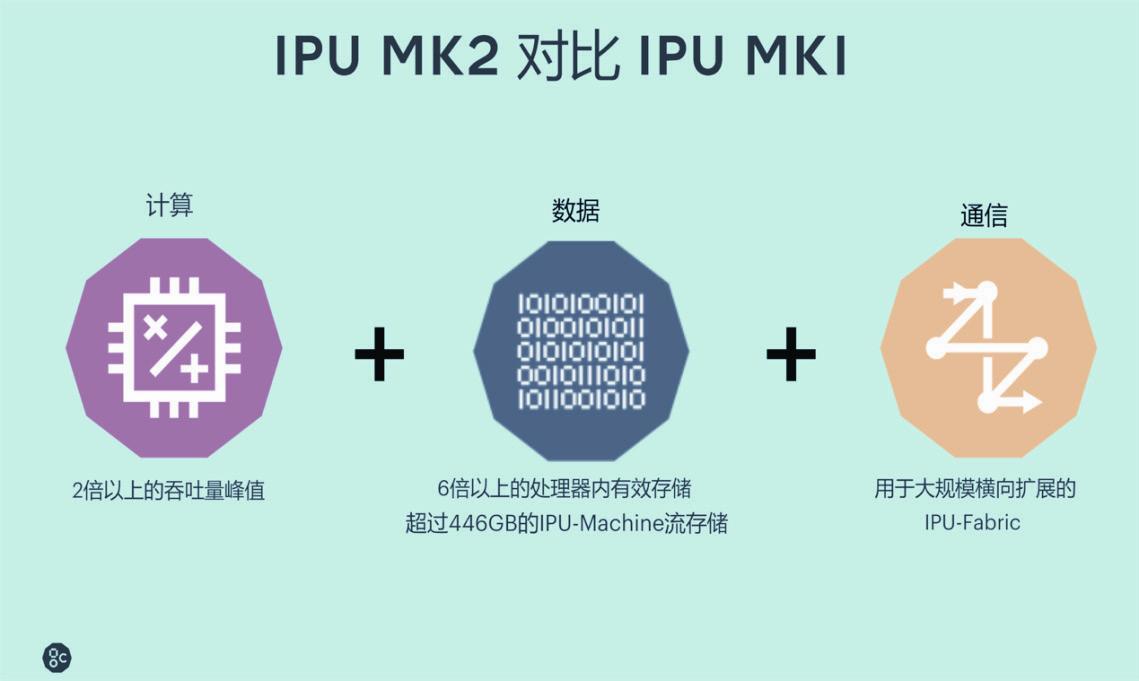
在計算方面,Colossus Mk2 GC200處理器繼承了上一代IPU的簡潔架構,在單顆芯片中集成了1 472個獨立的IPU-Tiles的單元,并設置了8 832個可并行執行線程,In-Processor-Memory從上一代的300 MB提升到900 MB,每個IPU的內存帶寬為47.5TB/s,與上一代IPU相比Colossus Mk2 GC200的峰值算力提高了兩倍。同時Colossus Mk2 GC200還包含了IPU-Exchange以及PCI Gen4跟主機的交互接口,在芯片之間具備帶寬為320 GB/s的IPU-Links互聯。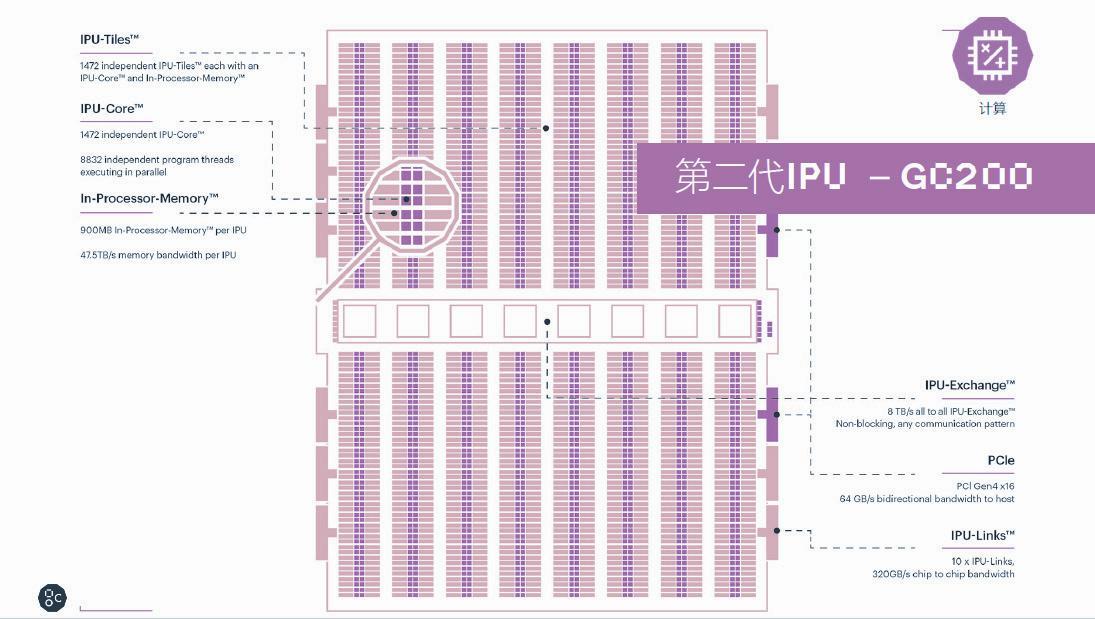
在數據處理方面,Colossus Mk2 GC200具備900 MB超高速SRAM,在每個處理器內核旁邊都設有大量RAM,以實現最低能量訪問。從數值上看,Colossus Mk2 GC200的處理器存儲容量比前代的300 MB提高了三倍,但在芯片內部,可供算法模型使用的激活、權重存儲容量比上一代提高了六倍以上,對于提升有效的運算效能大有幫助。
此外,Graphcore的Poplar軟件提出了全新的交換式存儲概念——IPUExchangeMemory。通過IPUExchangeMemory訪問Streaming Memory,可以支持具有數千億個參數的最大模型,每個IPU-M2000都可以支持密度高達450 GB的IPU ExchangeMemory,以及180 TB/s的帶寬。與采用HBM技術的芯片相比,Graphcore在每個IPU-M2000設備中通過IPU ExchangeMemory技術,可以提供近100倍的帶寬以及大約10倍的內存容量,這對于很多復雜的AI模型算法是非常有幫助的。
在通信方面,Graphcore專門為AI橫向擴展推出了全新的IPU-Fabric結構。IPU-Fabric結構主要由三種網絡IPU-Link、IPU Gateway Link和IPUoverFabric三種網絡組成,其可以實現2.8 Tbps的超低延時,并且支持AI運算中的集合通信以及全縮減(All-Reduce)操作。此外,通過IPU-Fabric技術,用戶可以通過直聯,或者以太網交換機實現IPU的橫向擴展,把設備集群從一個、幾個、幾十個、幾百個甚至幾千個無縫擴展至最高64 000個IPU。
在Colossus Mk2與Mk1的系統級對比中,Graphcore分別選擇了利用IPU-Link連接8個C2 PCIe卡的IPU服務器和利用IPU-Fabric擴展的8個IPU-M2000進行對比。在BERT-Large訓練、BERT-3Layer推理和EfficientNet-B3訓練三個典型的應用場景中,BERT-Large訓練實現了9.3倍的性能提升,BERT-3Layer推理實現了8.5倍的性能提升,EfficientNet-B3訓練實現了7.4 倍的性能提升。盧濤表示,“相較于前代產品,不管是典型的NLP應用,還是CV類的應用,在8個C2的IPU服務器和基于8個M2000的服務器的系統級性能對比中,Colossus Mk2 GC200都可以實現平均八倍左右的性能提升。”
大規模可擴展的IPU-M2000刀片卡
IPU-Machine:M2000(IPU-M2000)是一款即插即用的機器智能刀片式計算單元,采用Colossus Mk2 GC200內核,并由Poplar軟件棧提供全面支持。其設計便于部署,并支持可擴展至大規模的系統。這款纖薄的1U刀片機可提供1個PetaFlop的機器智能計算,且擁有450 GB的ExchangeMemory,以及可以為用戶提供超低延時通信的2.8 Tbps IPU-Fabric。IPU-M2000目前的建議零售價是32 450美金。


IPU-M2000有多種配置形態,用戶可以根據自己的需求利用IPU-Fabric對IPU模塊進行橫向擴展。同時,Graphcore還推出了基于IPU-M2000的全新模塊化機架規模解決方案IPU-POD64,可用于極大型機器智能橫向擴展,為用戶提供更大的AI計算可能性,以及完全的靈活性和易于部署的特性。
IPU-M2000是IPU-POD的一個基本組件,一個IPUPOD64的參考架構里支持16個IPU-M2000,可以根據不同的工作負載進行不同的配置,并且具有64顆IPU、16PFlops的算力、58GB的In-Processor-Memory,以及7TB的流存儲。此外,IPU-POD64支持2D-Torus的拓撲,最大化IPU-Link的帶寬,全縮減(All-Reduce)的效率比網狀拓撲快兩倍。
利用Graphcore最新的IPU-Fabric技術,用戶可以在整個數據中心內連接IPU,把IPU-M2000從一個機架式本地系統擴展到高度互連的超高性能AI計算設施中的1 000多個IPU-POD64系統。IPU-M2000的設計使客戶可以在IPU-POD配置中構建最多64 000個IPU的數據中心規模系統,這樣一個64 000個IPU的集群可以為用戶提供16ExaFlops的機器智能計算能力。
Graphocore在多核協同應用方面,應用了針對IPU協同的BSP(Bulk Synchronization Parallel)機制,通過軟件+硬件+編譯的協同機制,實現超大規模線程的同步。Graphcore中國區技術應用總負責人羅旭介紹說,BSP機制其實并不是一個新的概念,很早之前在超算領域就被人提出過,而Graphcore在BSP機制的基礎上把IPU芯片以及整個編譯器結合起來,利用IPU-Fabric,實現了IPU的多核協同工作,并保證大規模并行處理過程中的性能提升線性。

圍繞IPU構建的開發環境
Graphcore的IPU應用軟件Poplar包括了PopART(run time)和PopLibs(SDK)兩個部分。Poplar支持的算法框架包括PyTorch、TensorFlow1、TensorFlow2和ONNX,對百度PaddlePaddle的支持也會盡快發布。開發者通過PopART和PopLibs連接Poplar的compute graph,再通過graph compiler在整個處理器軟件跟硬件結合最緊密的地方生產計算圖,并把這個計算圖加載到對應的硬件,也就是IPU-M2000整個這一系列的產品中。
Graphcore最新發布的PoplarSDK1.2可以完全支持主流數據中心的操作系統,包括ubuntu、RedHat和CentOS等。Poplar SDK 1.2還優化了卷積庫和稀疏庫,開放了可擴展的Poplar庫,集成了很多先進的機器學習框架,進一步開放了低級別的API,為上層的算法提供低層次的API接口,并開放了Graphcore的獨特技術IPU Exchange Memory的相關API和管理功能,幫助用戶對模型性能做出最大程度的調優。
Graphcore還為用戶提供了基于圖形的分析工具Graphcore PopVisionGraph,可以做到基于算子層面檢測整個系統。以圖形界面的形式呈現內存使用、算力使用等信息,并針對IPU的特性進行性能調優。

GraphcoreIPU開發者云
目前Graphcore在中國的首款IPU 開發者云已經在金山云平臺完成了部署,其中使用的IPU產品包括三種: IPU-POD64、浪潮IPU服務器NF5568M5,以及戴爾IPU服務器DSS8440。Graphcore的IPU開發者云支持當下最先進、最復雜的AI算法模型的訓練和推理的工作,例如ResNeXt和EfficientNet等以分組卷積為代表的機器視覺應用,LSTM、RNN和GRU等基于時序分析的應用,還有自然語言、廣告推薦和金融算法等方面的模型。
Graphcore的IPU 開發者云為商業用戶提供三周左右的試用期,對于高校、研究機構和個人開發者則提供六個月左右的免費試用,Graphcore還為應用機器智能輔助人類突破人類潛力的研究者,例如針對新型冠狀病毒COVID-19的相關研究提供優先訪問使用權。
在用戶社群建設方面,Graphcore一直在努力籌備中國的創新社區,并在微信、知乎、微博,以及GitHub等平臺與開發者、創新者及研究者積極互動,Graphcore的中國官網“擬未科技”也將于近期上線。
后記
“Graphcore當下的主要工作分為三個部分:第一部分是專門為AI應用從零開始設計的IPU處理器。第二部分是基于IPU處理器以及面向AI應用的Poplar軟件棧,以及相關開發工具。第三部分是圍繞硬件和軟件共同打造IPU平臺。”盧濤介紹說,“Graphcore的愿景是在CPU和GPU之外‘畫出第三個圓,因為我們認為不管是CPU還是GPU都沒有從根本意義上解決AI的問題。AI是一個面向計算圖的計算任務,跟CPU的標量計算和GPU的矢量計算都是不一樣的。Graphcore希望IPU能夠幫助創新者在機器智能中實現下一步算法的突破。Graphcore芯片架構的特點能夠為模型開發、算法迭代帶來速度的提升,從而實現進一步的突破。”
猜你喜歡
表面工程與再制造(2019年6期)2019-08-24 06:40:04
文苑(2018年23期)2018-12-14 01:06:06
文苑(2018年19期)2018-11-09 01:30:14
文苑(2018年17期)2018-11-09 01:29:26
文苑(2018年21期)2018-11-09 01:22:32
商周刊(2018年18期)2018-09-21 09:14:46
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年10期)2015-02-27 07:55:08
