基于多層注意力機制的回指消解算法
2020-02-19 11:26:30劉雨江付立軍劉俊明呂鵬飛
計算機工程 2020年2期
劉雨江,付立軍,劉俊明,呂鵬飛
(1.中國科學院大學 計算機科學與技術學院,北京 100049; 2.中國科學院沈陽計算技術研究所 研究生部,沈陽 110168;3.中國地質圖書館信息技術研究中心,北京 100083)
0 概述
指代是常見的語言現象,在描述性語言中較為頻繁地出現,尤其是當語料篇幅較長時,極易造成信息抽取不完整的情況。指代關系既要考慮一個或多個詞對組成實體的指代,又要考慮名詞、名詞性詞組以及隱藏名詞或指代部分對上述實體的指代。根據被指代部分(或先行詞部分)與指代部分是否有語義關聯,指代現象被分為共指和回指[1]。共指表示被指代部分與指代部分均指向客觀存在的同一個實體;回指表示被指代部分與指代部分僅在特定語境下才有關系,即指代部分在某些上下文中時能指代被指代部分,當脫離這種上下文時不能表明是否存在指代關系。根據被指代部分和指代部分是否出現隱藏實詞,指代現象又被分為顯性指代和零指代。由于在數據集中顯性指代和零指代會同時出現,因此對這2種情況分別進行考慮。在具體實驗中,第1種為顯性指代和零指代混合出現的情況,第2種為僅有零指代出現的情況。本文主要研究回指關系判別,屬于回指解析。與文獻[2-3]的目的相似,通過回指消解,減少指代現象干擾,可以提高語料在后續深入研究時的可用性,為信息抽取、知識圖譜構建、人工智能對話等任務提供高質量語料。
對于回指關系判別,需要上下文與被指代部分和指代部分的詞共同構建輸入。文獻[4]基于上下文編碼思想,構建了2個多層編碼器,同時對上下文和待翻譯語料進行編碼,完成了翻譯過程中指代消解工作,而文獻[5-6]則采用基于事實方法。文獻[4]通過構建傳統規則模板實現基于全局推理的回指消解方法,提高了位置三元組信息抽取的準確率。在共指消解研究上,更多地考慮了不同表達對同一事實的不同描述方式。文獻[6]通過識別出同一個事實,再以該事實為核心尋找并抽取相關信息。另有一部分文獻的指代消解研究方法基于mention-ranking方法,即先獲取所有可能被指代的部分,再根據指代部分和這些被指代部分評分進行篩選,評分最高的就是當前指代結果。文獻[7-9]均采用此方法,區別在于文獻[7]使用RNN訓練被指代部分集合與指代部分組成序列,文獻[8]使用普通神經網絡訓練指代部分與被指代部分集合組成向量,文獻[9]使用強化學習方法使得被指代部分進行選擇時具有傾向性。在研究范疇上,文獻[7]是共指消解,文獻[8-9]均為回指消解。針對專有名詞和代詞,文獻[10]采用表述識別二次分類,提高了漢語指代消解的性能。上述研究方法均考慮到了上下文、候選集合、語義關聯等情況。
本文在研究回指消解時考慮指代部分與被指代部分周圍的信息,將這部分信息作為一種引導,使得相同代詞在嵌入周圍信息時能構建一種輸入模式,并由注意力機制實現。在模型設計上考慮多層注意力機制指代部分、被指代部分、周圍信息、原文信息的綜合處理過程,以捕捉上述信息的關聯關系。
1 相關工作
在已有的研究中,回指消解主要參考注意力機制及機器閱讀理解模型進行構建。本文模型在構建時參考了這兩部分的研究。
1.1 注意力機制
基于注意力機制的Transformer網絡結構最早由谷歌在2017年提出[11],其主要針對機器翻譯問題,認為之前機器翻譯模型大量地使用RNN及改進的RNN類網絡會導致速度下降。RNN網絡的缺點是無法實現并行計算,而Transformer網絡結構中的注意力網絡可以有效地避免該問題。注意力網絡本質上是多層的前向神經網絡,通過計算目標與來源之間的概率值作為注意力,用于增強或減弱網絡對某些詞的關注程度,并在誤差反傳中進行調整。由于注意力網絡的時間復雜度小于RNN類網絡,因此本文選擇注意力網絡結構用于模型構建。
1.2 閱讀理解模型
分析機器閱讀理解模型對研究回指消解模型具有指導性作用。在閱讀理解模型中,用于訓練的數據格式為問題集、答案集和文章集,通過對問題和文章進行編碼,并使用神經網絡進行訓練,再通過Softmax層將得到的結果映射到全部詞表中得到答案。文獻[12]使用類似方法,利用多次迭代的GRU網絡構建模型,最后通過計算候選答案的可能性實現閱讀理解任務。文獻[13]完成閱讀理解任務時將答案定位在原文中,預測的結果分別為起始答案位置和終止位置,然后分別計算誤差,再求出2個誤差的算術平均數作為訓練優化方向。而嘗試使用閱讀理解方式解決回指消解幾乎不可行,在分析訓練數據之后可以發現,在閱讀理解的每一個實例中,問題中一部分詞匯必然出現在答案周圍。結合文獻[13]中的BERT模型,可以推斷在“預訓練+微調”的訓練策略下,使用自注意力機制可令文章對問題詞匯分配更高的注意力概率值,從而找到答案。在回指消解任務中,指代部分和被指代部分周圍的詞可能完全不一致,又因為這2個部分本身有很大可能性是不同詞匯組成,所以無法構建類似于閱讀理解任務的輸入模式。根據上述分析,本文提出一種多層注意力模型,通過構建“詞/詞組-語句片段-整篇文章”的關聯注意力,并嵌入到最終需要判斷的2個部分中,再計算出是否具有關聯關系。這種過程無需考慮是否在指代部分和被指代部分有相同的詞,也不必考慮兩部分是否部分一致,通過層次映射關系即可構造出當前語境下兩部分信息的向量,進而判斷是否為指代關系。
1.3 已有指代消解方法
近年來中文零指代的研究較多,這種情況可以在Google學術搜索的返回結果中體現。文獻[14]給出基于翻譯對比的詞映射指代消解策略。這種策略通過邏輯回歸與聚類的思想為中文、英文以及中英混合文都構建了一個判別器,并給出了4種消解方法,其中有代表性的為方法2和方法4。方法2先考慮使用混合文判別器給出指代部分和被指代部分的判別概率,若大于0.5則認為是指代。如果在英文中找不到中文代詞翻譯后得到的詞,則直接采用中文判別器,這種方法得到的召回率較高。方法4同時使用了3種判別器并在訓練時調整每種判別器權重。文獻[15-16]也采用基于翻譯的方法,它們在判斷指代關系時增加了很多模板規則與模板參數,直接使用模板規則進行判斷。文獻[17]總結了5種中文指代消解模型,能夠基本涵蓋到目前為止的主流方法,其包含了3種二元分類模型、傳統規則模型和排序模型。中文零指代研究相對較新,基本采用深度學習方法。文獻[9]通過強化學習解決零指代問題,文獻[18]采用注意力機制,在構建指代對時采用了3組不同的RNN,文獻[19]采用一個BP神經網絡分別提取了距離特征、指代部分與被指代部分的前綴上下文、關鍵動詞和關鍵賓語,并將這些內容編碼通過使用LSTM進行訓練。
本文在考慮了數據集指代分布特征和當前研究熱點之后將實驗分為下列對應的兩部分:1)構建所有指代實例,并與文獻[14-15]進行對比;2)僅構建零指代實例,并與文獻[9,17-18]進行對比。
2 回指消解判別算法模型
回指消解判別算法模型主要依據多頭注意力機制進行構建。在模型構建方面,本文主要在模型結構和結果判別上進行研究與創新。
2.1 模型結構與執行過程
輸入信息分為5類,包括指代部分詞匯、指代部分周圍詞匯信息、原文信息、被指代部分詞匯和被指代部分周圍詞匯信息。輸入信息均需要進行位置信息嵌入,嵌入過程考慮隨機指定位置向量,并將得到的位置向量與詞向量相加。令vocab_size表示詞總數,dvocab表示詞向量維度,length表示當前輸入長度,vocab_slice表示嵌入位置信息之前的詞向量集合,vocabe表示嵌入位置后的結果,計算公式為:
position=random(vocab_size,dvocab)×
slice(length)
vocabe= vocab_slice+position
使用位置信息嵌入主要考慮到多頭注意力機制的計算方式,根據文獻[8],位置信息在CNN和RNN類網絡中不必要,而在多頭注意力機制中位置信息的唯一來源是外部輸入,因此必須進行計算。
在得到具有位置信息的輸入之后,構建多頭注意力機制進行指代部分與其周圍語句的映射向量,并將此法應用于被指代部分與其周圍語句、原文與指代部分、原文與被指代部分,在第2個注意力層上得到2組計算結果。最后將得到的結果在第2個維度上拼接,通過Softmax方法求出二分類概率,進而判斷是否存在指代關系。該模型與文獻[20]提出的模型思路相近,但是其在輸入構建時考慮屬性與實體對應,這里考慮指代部分/被指代部分與周圍信息的聯系。算法模型結構如圖1所示,多頭注意力機制模型結構如圖2所示。根據上述內容,算法模型過程表述如下:將指代部分信息、指代部分周圍詞信息、原文信息、被指代部分信息、被指代部分周圍詞信息進行向量化表示,分別嵌入位置信息作為輸入。依據該方法分別得到指代部分向量、指代部分周圍信息向量、原文部分向量、被指代部分向量和被指代部分周圍信息向量。將指代部分向量與指代部分周圍信息向量進行多頭注意力機制計算,再使得到的結果繼續與原文部分向量采用相同方法計算,得到指代部分在當前模型中的特征結果。該結果能夠體現多層注意力機制條件下原文和指代部分周圍詞信息對指代部分的作用,利用同樣的方式計算得到被指代部分在當前模型中的特征結果。最后,將兩組特征結果連接組成一個綜合結果,并利用Softmax層將它映射在判別空間中,進行指代與否的判斷。
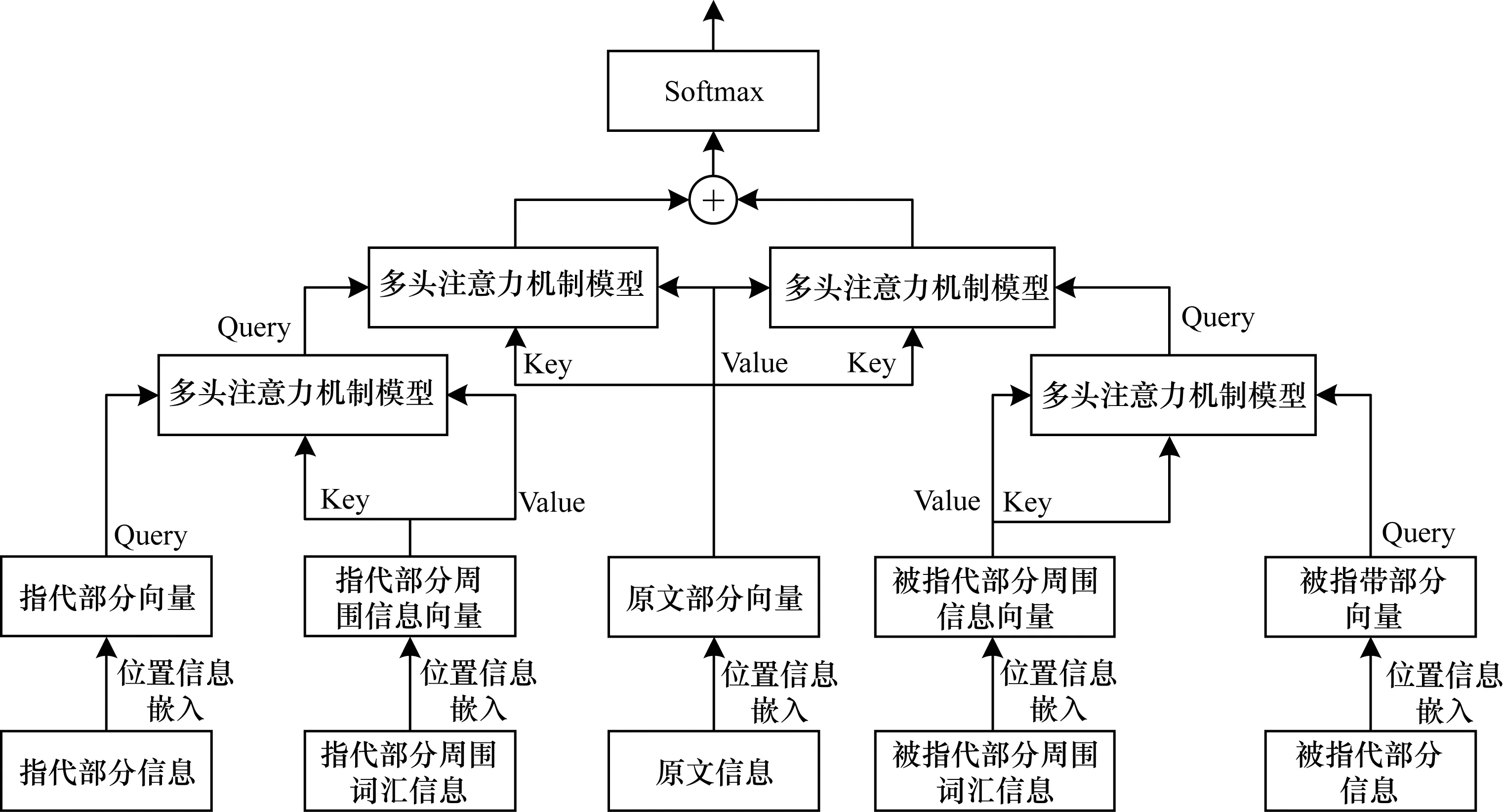
圖1 算法模型結構
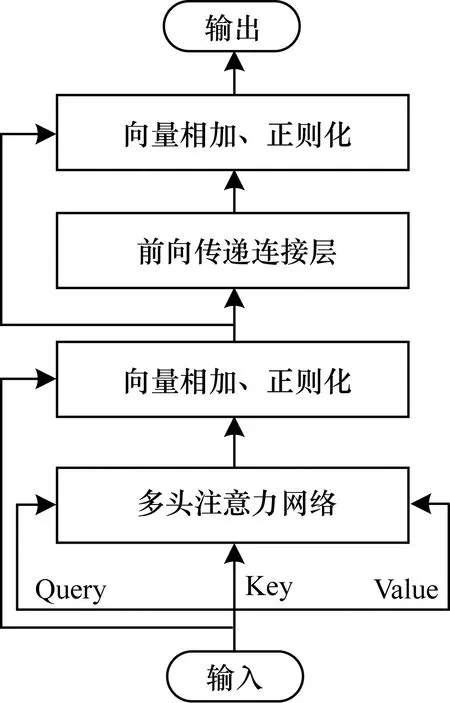
圖2 多頭注意力機制模型結構
2.2 多頭機制的具體應用
多頭注意力機制在應用于機器翻譯時,包含“編碼器-編碼器”“解碼器-解碼器”和“編碼器-解碼器”3種注意力輸入方式,文獻[11]給出了輸入方式的過程,計算公式為:
本文考慮分層次使用多頭注意力機制構建模型,將多頭注意力機制應用于分層結構中,使得相鄰層次的信息能夠獲得充分交互。指代部分周圍詞匯與指代詞/指代詞組有包含關系,因此可以通過注意力機制計算指代詞/指代詞組在其周圍詞條件下的概率,進而通過這種概率對每一個指代部分詞進行加權,獲取指代部分相對周圍信息的向量,記作指代擴展向量。同理,被指代部分采用相同方法也可以獲取這種向量,記作被指代擴展向量。通過這種方式可以構建特定語句中每一個指代部分/被指代部分唯一向量,這種唯一性體現了相同詞在不同語句中會被映射為一個僅屬于該句的向量。這避免了以下的情形:因語境不同導致無法根據相同內容的2個部分判斷指代關系。在獲取上述指代擴展向量與被指代擴展向量之后,需要與原文向量進行注意力機制計算。考慮到原有指代部分的詞匯可能在原文中出現多次,因此沒有直接用原指代部分向量與原文向量進行計算。比如代詞“它”,很可能在原文中出現不止一次,但是直接輸入這種向量會使判斷指代關系變得困難,因為在無周圍信息的情況下無法確定這個代詞指代的實體。而在經歷上述擴展過程之后,無論是指代部分還是被指代部分都能在保留自身屬性信息情況下附加周圍語句的影響,在與原文進行計算時,可以防止出現一對多映射,即相同待確定的指代關系在不同語境下出現判斷結果相反的情況。令xe、span_xe、articlee、we、span_we、attention_output分別代表位置信息嵌入之后的指代部分、指代部分周圍信息和原文信息、被指代部分、被指代部分周圍信息、用于計算概率的輸出結果,計算公式如下:
extend_xe=attention(xe,span_xe,span_xe)
extend_we=attention(we,span_we,span_we)prone=
attention(extend_xe,articlee,articlee)
anae=attention(extend_we,articlee,articlee)
attention_output=concat(prone,anae)
2.3 結果判別與算法復雜度分析
在得到指代擴展向量與被指代擴展向量被原文擴展后的結果時,可以構建模型輸出部分。由于輸入部分包含指代項和被指代項,因此輸出部分采用二分類方法直接判斷是否存在指代關系。在控制輸出向量維度為2時,采用Softmax函數構建輸出向量,用作分類的2個元素分別表示預測類別的概率值。選取這種預測策略的原因在于負例構建時具有隨機性。負例參考文獻[11]中上下句預測方法,即使用約50%正例和50%負例混合構建訓練和預測數據。在同時考慮判斷為正例或負例條件下,選擇Softmax函數進行計算。根據文獻[21],在二分類情況下,Softmax等效于Sigmoid映射,不使用Sigmoid函數的原因會在實驗部分說明。令predi表示第i次的預測結果,yi表示第i次的真實結果,則對應于n組結果,訓練過程的loss值公式如下:
predi=Softmax(attention_outputi)
算法中時間消耗最大的部分為多層注意力機制計算部分,在構建模型時對時間復雜度和空間復雜度的分析如下:
RNN類網絡:RNN類網絡需要考慮常見的LSTM與GRU。LSTM將計算4組參數,分別對應輸入門、輸出門、遺忘門和候選態。LSTM更新公式為:
yt=f(yt-1,xt)
其中,t為句子長度,若此向量維度為d,隱藏層和輸出層的維度均為h,反向傳播時時間復雜度和前向時的計算相同,一個單層LSTM處理之后的時間消耗可以表示為8×t×h×(d+h+1),而將LSTM修改為GRU之后,時間消耗表示為6×t×h×(d+h+1)。因此,采用LSTM或GRU進行一次類似本算法模型中的多頭注意力機制計算,時間復雜度為O(t×d×h2)。由于LSTM、GRU消耗空間最大的時刻是矩陣相乘計算,因此空間復雜度可表示為O(n2),其中n=max(d,h)。
多頭注意力機制:根據注意力機制計算公式,僅注意力網絡部分消耗的時間可表示為2×t×d2。若前向傳遞連接層輸出的維度不變,整體消耗的時間為8×t×d2,因此一次多頭注意力模型的時間復雜度為O(t×d2)。根據注意力機制計算過程,消耗空間最大的時刻是矩陣相乘計算,因此空間復雜度可表示為O(d2)。
因此,若LSTM或GRU的輸出維度也為d,則時間復雜度為O(t×d3),明顯高于多頭注意力機制,而空間復雜度則幾乎相同。
3 實驗與結果分析
考慮到顯性指代和零指代均存在以及僅存在零指代這2種情況,設計了4組實驗和6篇文獻進行對比,并記錄結果。
3.1 數據集與評價標準
實驗數據選擇Conll-2012分享任務中的OntoNotes5.0數據集,僅選用中文部分。中文部分數據集包含了1 391個訓練文件和172個測試文件;訓練文件包含句子總數36 487組,測試文件包含句子總數6 083組;構建顯性指代訓練例子共計133 326個,測試例子共計20 074個;構建零指代訓練例子共計20 563個,測試例子共計3 146。單個文件中可能不只包含1篇文章,回指消解結果位于單篇文章后。數據集內容與新聞報道有關,包括廣播會話、廣播新聞、雜志、通訊新聞、電話對話和博客文章共計6個類別。因此,使用這部分數據集進行實驗能夠展示通用語料環境下回指消解過程。
評價標準選擇文獻[14]給出的實驗結果。該文獻使用了相同數據集,旨在通過機器翻譯解決漢語回指消解,同時給出了文獻[15]的實驗結果。文獻[14-15]都采用了基于機器翻譯的結果,且文獻[14]的結果分為方法2和方法4兩組。
3.2 實驗過程
指代關系對構建過程參考文獻[13]中上下句預測方法,即通過模型區分原有正例和隨機負例,用于訓練和預測的正負例數量比接近1∶1。由于文獻[14]在訓練分類器時構建正例和負例的比例為1∶1且負例隨機選取,因此本文采用這種構建策略。對于單個文獻多篇文章的情況,會將每篇文章及其附帶的消解結果分開。為防止數據訓練時對GPU顯存占用過大,指代部分與被指代部分的長度限制在64,指代部分與被指代部分的周圍信息長度限制在72,單篇文獻長度限制在384。訓練時學習速率為1e-5,用于防止過擬合的dropout值為0.4。單次實驗批量大小為105,注意力機制下“注意力頭”大小為64,數量為12。訓練次數為10萬次,相當于訓練集完整循環625次。
在實驗過程中對6個類別分別進行實驗,最后將得到的6組精確率、召回率、F值求算術平均數,作為最終結果。在實驗過程中補充了2個對比實驗:1)將“注意力頭”大小由16增加為64;2)增加了僅含零指代的實驗,并與當前最新零指代數據集進行對比。
3.3 結果分析
顯性指代和零指代均存在時的實驗結果如表1所示,其中,本文方法及對比文獻的方法均是6組數組結果的均值。文獻[14]的訓練集為OntoNotes5.0,包括1 391個中文文件和1 940個英文文件,測試集為166個中文文件;文獻[15]采用相同的數據集。
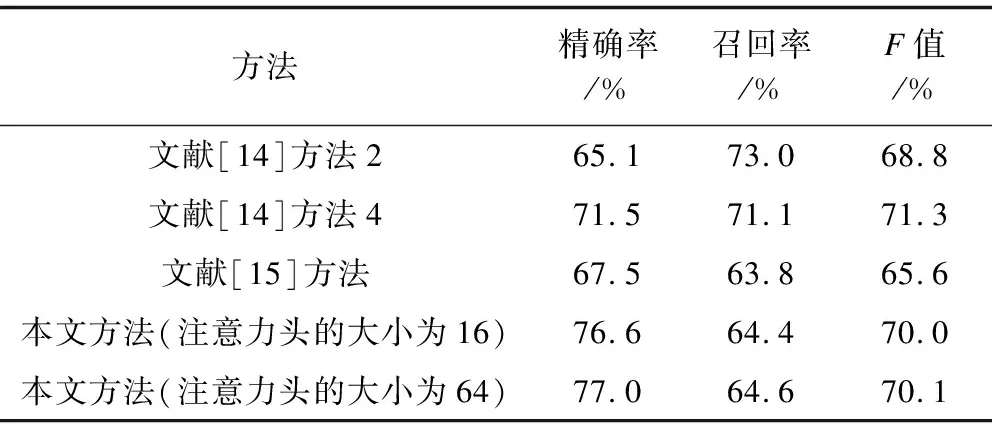
表1 顯性指代和零指代均存在時的實驗結果對比
在上述實驗結果中,模型中不同注意力頭對應的F值均超過文獻[14]的方法2以及文獻[15]的方法。文獻[14]方法4則僅有精確率被本文方法超過。對上述結果分析如下:OntoNotes5.0中文數據集既包含顯性指代消解,又包含零指代消解。文獻[14]僅研究顯性回指消解,為保持原數據集給出的指代特征,考慮顯性指代和零指代混合出現的情況。本文方法在混合了零指代數據時與文獻[14]效果相接近。相比較僅研究零指代,如文獻[9]在隨機構建一個負例僅研究零指代時,模型的精確率、召回率、F值分別為70.8%、69.8%、70.0%,其中,F值高出文獻[14]12.8%。為保證訓練過程和判別邏輯與文獻[9]一致,增加一個對比實驗,對比實驗在構建負例時不是隨機構建,而是考慮將所在文章中比當前零指代序號小的全部被指代部分都作為這個指代詞的負例,以適配模型的訓練策略。
從實驗中可以發現,當正例過少時,損失函數值在下降過程中使得正例準確率較低,因此在構建負例時通過復制正例將兩者比例調整為1∶1再進行訓練。構建的訓練集例子數增加到199 841個,測試集例子數增加到27 646個,此時,精確率、召回率、F值分別為64.9%、57.5%、60.7%,F值仍比文獻[9]高出3.2%。相比于文獻[8]使用候選集合構建的方式,這種訓練方式需要訓練的負例數量更多,因此本文的模型更具優勢。由于采用相同的數據集,文獻[9,18-19]訓練集與測試集的文件數和句子數與本文相同,構建的訓練例子數為12 111個,測試例子數為1 713個,對比結果如表2所示,其中本文方法及對比文獻的方法均是6組數組結果的均值,由于被引用文獻未給出精確率和召回率,這里僅比較F值。

表2 僅存在零指代時指代判別分析比較結果
進一步分析預測結果可以發現,OntoNotes5.0回指消解的真實結果中有一大部分為多次同詞指代。以文件cmn_0010.onf為例,Chain 1_15編號下被指代部分為“爸爸”,而對應的指代部分有16組結果,其中15組為“爸爸”。這種情況導致了模型一旦判斷一組結果錯誤,就可能連續判斷所有的這類結果錯誤。
Sigmoid函數可以將一個任意實數轉化到[0,1]上進行二分類。在實驗過程中發現若采用Sigmoid函數作為loss,會導致精確率和召回率極低。觀察輸出的倒數第2層數據可知,隨機構建的負例因為不存在規律,會嚴重壓縮正例結果空間,無法找到一個合適的概率閾值區分正例和負例。Softmax函數會同時預測正例概率和負例概率,判斷時根據概率值的大小,而不是根據一個固定閾值,因此能夠一定程度上避免Sigmoid函數的缺陷。
4 結束語
本文提出一種回指消解方法,通過構建多層注意力模型實現不同層次信息的處理。根據注意力機制計算指代部分和被指代部分在其周圍信息和原文條件下的向量表示,進而得出是否存在指代關系。該方法可使指代部分和被指代部分在當前語境下直接進行指代關系判別,對于顯性指代和零指代2種情況都有較好的效果。在測試數據集上的實驗結果表明,模型在采用隨機負例生成策略時,顯性指代和零指代均存在情況下的F值為70.4%,僅存在零指代時為70.0%,在構建全部可能的負例時,僅存在零指代時F值為60.7%。下一步將考慮適當增加詞性、語義相似度等外部信息,并通過嵌入信息的方式構建詞向量進行訓練,或采用共指解析中候選集方法,在縮小結果空間的條件下提高召回率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中華手工(2017年2期)2017-06-06 23:00:31
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
中外會展(2014年4期)2014-11-27 07:46:46
中學數學雜志(初中版)(2006年1期)2006-12-29 00:00:00
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
