基于GRU和LightGBM特征選擇的水位時間序列預測模型
2020-03-11 12:50:52許國艷周星熠司存友胡文斌
計算機應用與軟件 2020年2期
關鍵詞:模型
許國艷 周星熠 司存友 胡文斌 劉 凡
1(河海大學計算機與信息學院 江蘇 南京 211100)2(江蘇省水文水資源勘測局信息應用科 江蘇 南京 210000)
0 引 言
水文時間序列是指水文信息中水位、降雨量等因素隨著時間變化產生的序列。其中水位時間序列的研究是數據挖掘領域的重點研究方向,通過對水位的預測分析,不僅可以準確地對水資源進行調度管理更能即時預報洪澇災害,對于防災減災有著至關重要的作用。
水位時間序列的預測在近十多年取得了較大的進展,中外學者都對其做出一定的研究。在數據量較小,且特征豐富時機器學習模型甚至傳統的數學模型也能取得較為良好的效果。商其亞等[1]利用ARIMA(自回歸綜合移動平均)對民勤綠洲水位進行預測,提取了人口、耕地面積等多個影響因素,較為準確地預測了上游水位的變化趨勢。黃發明、殷坤龍[2]等使用SVM模型對水位進行預測,并采用了混沌理論的粒子群算法克服了支持向量機中存在的參數選擇困難的特點,以此預測水位系統發展演化的過程。隨著水位時間序列預測的處理越發復雜化,對于預測的精度要求也隨之提高,采用深度學習的方式能夠建立更高效的模型,提高預測精度。孫菊秋等[3]將人工神經網絡中的BP算法應用到秦皇島地區的水位預測中,模擬出未來2年的水位情況,表現出精準、快速的優勢。馮鈞等[4]提出了一種基于LSTM-BP的組合模型預測方法,通過兩個模型的組合降低了誤差,提高了預測的準確度。隨著數據量的增大,對于數據的真實性判斷成了預測中不可或缺的一環。花青等[5]提出了一種基于多滑窗的異常數據檢測方法,能夠及時對預測值進行處理,避免因為誤差造成的錯誤報警。對于預測殘差等其他影響因素的處理,王華勇等[6]提出了一種基于lightGBM改進的梯度提升算法,能高效并行地處理更多的實驗樣本,通過增加決策樹的方法減少了過擬合的出現,使得預測精度更高。
水文數據有著強烈的季節性和復雜性,在非汛期水位時間序列的影響因素較少,預測結果較為精確;而汛期時降雨量對水位的影響較大,因此需要將其作為輸出的另一項特征進行建模。單一的GRU模型對于水文數據的復雜性及其非線性部分處理存在不足,為了優化模型,更好地處理、分析預測殘差及其他影響因子對結果的影響,本文將LightGBM梯度提升算法用來處理殘差及降雨量數據,與GRU建立基于GRU-LightGBM的組合模型。
1 相關研究
1.1 GRU
GRU(Gated Recurrent Unit)是一種改進的循環神經網絡,比起原始的RNN模型具有更遠的傳播距離,并且能解決梯度消失的問題。與循環神經網絡的另一個變種LSTM[7](長短期記憶網絡)相比減少了一個遺忘門,且其單元中的細胞沒有狀態,因此該模型網絡結構更易被理解,可以減少過擬合且訓練更為簡單。GRU[8]的一大特點是可以基于歷史值和當前值來預測未來某個時刻的值,所以用來處理時間序列比較合適。GRU預測的原理是利用門單元控制歷史和當前信息,并在當前步作出預測。GRU的一次前向傳播過程如下:
1) 更新門對t-1時刻的隱藏狀態ht-1做線性變換,并通過激活函數壓縮結果到[0,1]區間。在生成記憶內容過程中,重置門應用于t-1時刻的信息上,來存儲t-1時間的隱藏狀態ht-1的狀態信息。
2) 將重置門和前一時刻的隱藏狀態做乘積,再將此結果和當前時刻的輸入值xt做線性變換,通過tanh將結果映射到[-1,1]區間內,得到當前記憶內容;(1-Zt)×ht-1表示前一刻隱藏狀態保存到當前的值,將其與t時刻的記憶內容保存到現在的記憶量相加得到最終的值ht。
1.2 LightGBM
LightGBM(Light Gradient Boosting Machine)[9]是于2016年提出的一種基于決策樹的梯度提升算法。
作為GBDT[10]的一種,LightGBM的設計主要是為了提高對大規模數據的處理速度和精度。傳統GBDT算法的缺陷在于:一方面,在單機上處理大規模數據的時候,為了保證速率往往會導致精度的丟失;另一方面,在分布式處理時,各機器之間的通信損失,也在一定程度上降低了數據的處理效率。
LightGBM的核心思想是基于histogram[11](直方圖)的決策樹算法,將樣本中連續的浮點特征值離散化成K個整數并構造與之長度相等的直方圖。遍歷時,將離散化后的值作為索引在直方圖中累計統計量,然后根據直方圖的離散值,遍歷尋找最優的分割點。這樣可以有效地降低內存消耗,同時達到降低時間復雜度的目的。此外,LightGBM采用了區別于傳統Level-wise方法的Leaf-wise葉生長策略,即每輪迭代都從現有的葉子中找到最大增益的分裂方法,如此循環直至達到給定的最大深度,此方法有效避免了不必要的開銷,提高了計算速率。LightGBM的建模過程如圖1所示。
圖1 LightGBM決策樹算法
基于LightGBM算法能夠并行處理海量數據的特性,將該算法用于對時間序列的殘差和降雨量進行多特征并行處理,能夠更好地降低模型計算的時間復雜度,提高預測的效率和精度。
2 水位數據組合預測模型
2.1 預測模型架構
基于GRU-LightGBM的水位數據組合預測模型架構總體分為三個模塊:
模塊一:從數據源獲取水文信息,將其分解為水位數據和降雨量數據。將水位數據進行差分和歸一化[12]處理。
模塊二:構建GRU模型,求出水位的預測序列并根據水文信息將其分為汛期預測序列和非汛期預測序列。
模塊三:將非汛期的預測殘差與原始水位序列構建lightGBM模型,求出非汛期的最終預測序列;將汛期的降雨量序列與原始水位序列構建lightGBM,計算汛期的最終預測序列。
組合模型的建模整體架構圖如圖2所示。
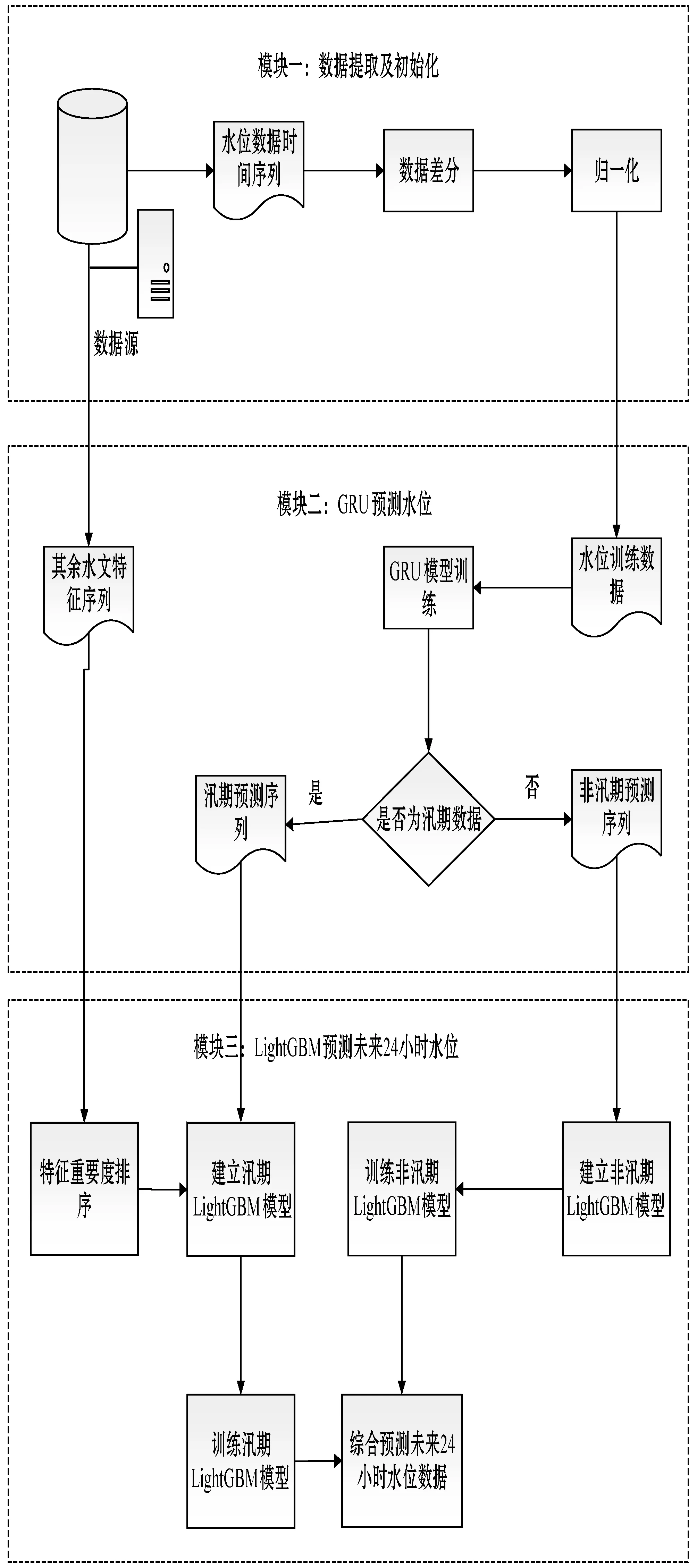
圖2 組合模型架構圖
2.2 數值預處理
對于給定的水文數據我們進行數據處理,使之具有規范的格式,便于后續處理分析。本文對于時間序列的預處理主要是填充空缺值以及歸一化。
歸一化旨在消除不同量綱之間的相互影響,解決指標之間的可比性。通常數據量、數據范圍較大時,模型的收斂速度和精度會下降,為了解決此類問題,我們通常將數據按比例縮放,本文采用較為常用的(0,1)歸一化,將數據映射到(0,1)區間內。歸一化公式如下:
(1)
式(1)中數據取自待預測站點的水位數據,ti為待處理水位數據,tmin為水位數據中的最小值,tmax為水位數據中最大值。通過數值歸一化[13]的處理,使得數據梯度變化時由原來的窄而長的橢圓形之字走向優化為直接沿著圓心最短路徑的走向,大大提高了迭代速度。同時,歸一化的處理還能消除樣本奇異值帶來的計算精度的影響。
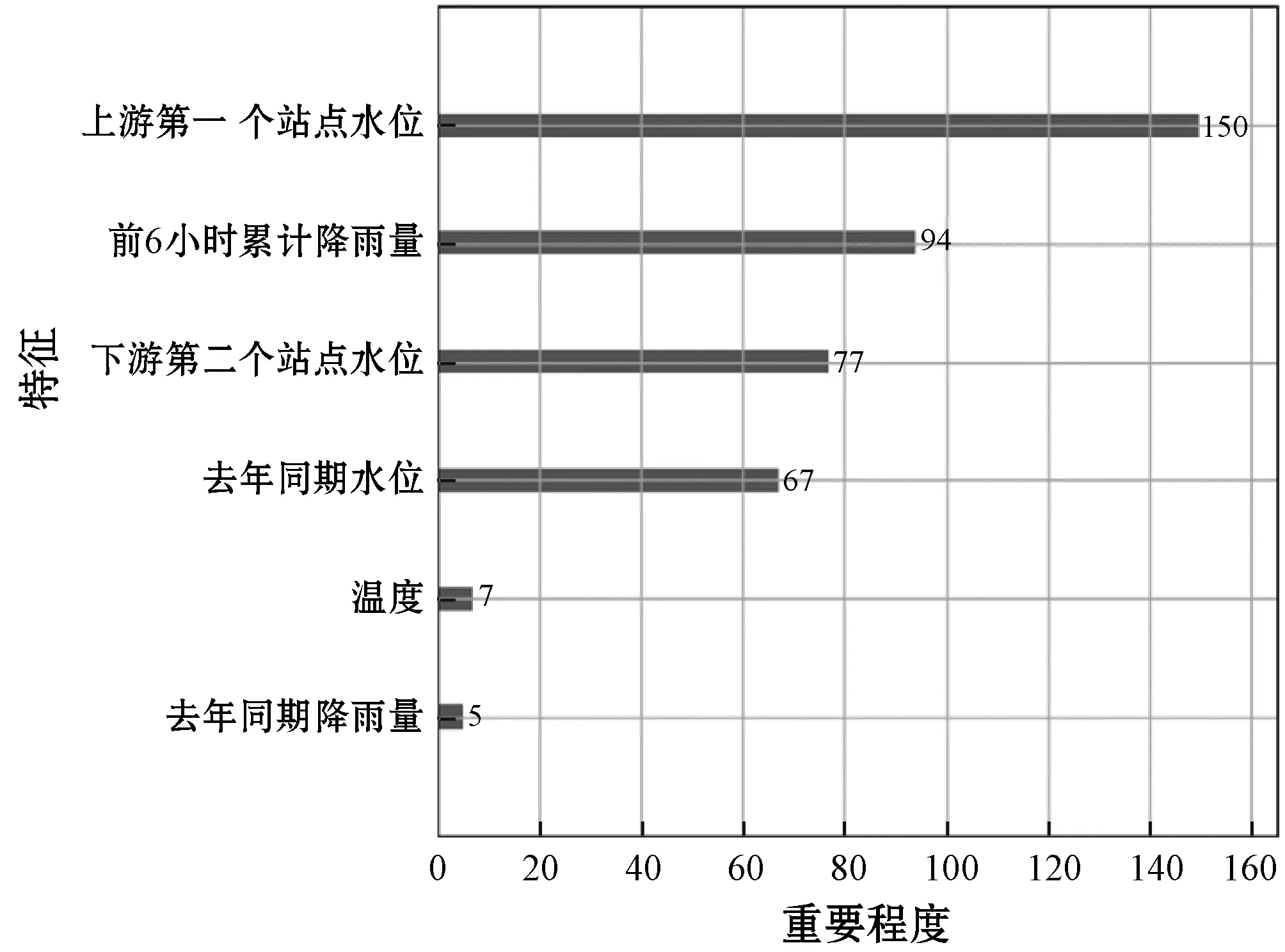
對于本文所用模型,在數值預處理上還需對特征值的重要程度進行排序。汛期的水位受到了諸多環境因素的影響,但是對于此類影響因素,傳統方法的單個遍歷嘗試或者組合篩選效率較低,因此本文選取LightGBM將各類環境變量對于水位的影響程度進行排序,選取重要程度較高的多種特征,將水位初步預測值與這些特征組合進行梯度提升建模。
2.3 組合模型原理
組合模型是指針對某一類問題采用了兩種或者兩種以上的模型進行處理的方法。針對連續型數值的特性,水位數據與前幾個時間點的觀測值有較強相關性,可以利用改進的神經網絡GRU對于歷史時刻的數據進行分析預測,初步建立一個較強的預測器。在強預測器的基礎上,傳統bagging算法的提升較小。可將水文數據中降雨量時間序列以及GRU建模時預測殘差進行boosting[9]操作,在強預測器的基礎上進行并行計算,再進行水位預測。
區別于傳統的組合模型,對于時間序列中的線性和非線性成分并不是簡單相加,而且采用線性預測與非線性捕捉分離的方式分別處理。此外,對于傳統模型中未能考慮到的季節性因素,基于GRU-LightGBM的模型也做到了分時段處理,針對不同環境細化建模流程。
組合模型的建模流程如下:
(1) 提取歸一化后的水位數據Xi將其分成非汛期數據X1i和汛期X2i建立GRU網絡模型,得到預測序列值Ti,通過與水位數據作差可得殘差序列Li,將所得殘差序列按照汛期和非汛期分解成L1i和L2i,表達式如下:
Li=Xi-Ti
(2)
(2) 依據水文數據指定的時間,5月至9月為汛期,其余為非汛期,提取殘差序列:
(3)
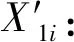
(4)
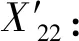
[X2i,L2i,D2i])
(5)
組合模型的網絡結構如圖3所示。
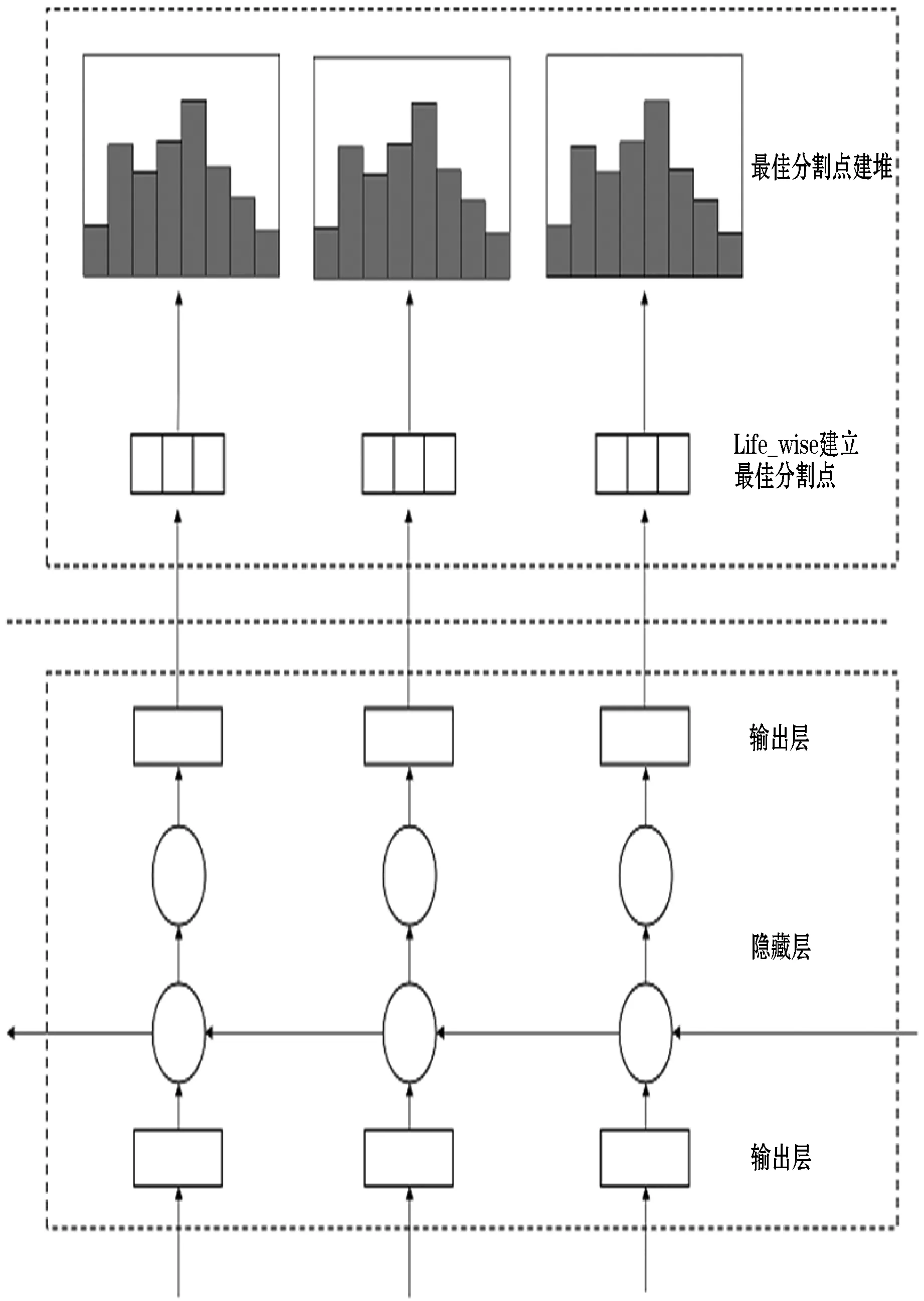
圖3 網絡結構圖
組合模型將GRU網絡預測所得非線性殘差與其他影響因素輸入梯度提升LightGBM模型中并行計算,有效降低了精度丟失,并提升了計算速率。
2.4 組合模型算法與分析
總體思想:本文中提出的組合模型主要由一個GRU模型和兩個LightGBM模型結合而成。GRU模型僅對水位時間序列信息進行相空間重構,求出待預測站點的水位預測序列Ti及預測的殘差序列Li;第一個LightGBM將非線性的水位預測殘差L1i與原始序列結合,利用梯度提升的原理計算最終的水位預測序列T1i。第二個LightGBM模型利用梯度提升的原理將汛期影響因素重要程度前四的環境變量與汛期水位預測殘差L2i組成綜合特征矩陣作為輸入數據,得到最終的水位預測序列T2i。水位時間序列預測的具體算法如下:
Step1對從數據源得到的數據進行分析,通過檢查數據的平穩性和季節性分析其差分次數并剔除其趨勢因素。
Step2對處理后的水位數據進行(0,1)歸一化。利用相空間重構的方法將一維的水位數據序列以三位步長處理成高維的矩陣Xi,通過reshape變換將矩陣Xi轉換成GRU所能識別的維度即[sample,step,feature],sample代表樣本值,step為設置的步長,feature為特征。輸入層有1個input,隱藏層有32個神經元,模型中利用滑動窗口的原理將每次輸出層預測一個值作為下一次預測的輸入值進行計算,重復n-3次直至預測結束,對應的輸入矩陣Xi以及輸出向量Ti關系如下:
(6)
輸入矩陣Xi輸出向量Ti
Step3將所得預測序列ti的值與原始數據xi相減,計算出殘差序列li。
Step4根據水文數據指定時間,將殘差序列分為非汛期殘差序列l1i以及汛期殘差序列l2i。
Step5將非汛期的非線性殘差序列l1i與原始序列x1i相結合形成LightGBM的輸入矩陣gbm_train1,通過梯度提升的處理方法再度進行預測,得出預測序列t1i,對應的輸入矩陣gbm_train1和輸出向量T1i關系如下:
(7)
輸入矩陣gbm_train1輸出向量T1i
(8)
輸入矩陣gbm_train2輸出向量T2i。
將所得預測序列t1i以及t2i逆歸一化得到最終輸出結果。具體實現過程的算法1所示。
算法1:
輸入:水位時間序列訓練數據集dataset_Xi,預測步長step以及特征features;
輸出:未來24小時的預測值Predict_24;
c為隱藏門;
inp為隱藏狀態的線性變換;
本文根據河北某新區的地理和降雨特點,在保證雨水調蓄池儲存雨水功能基礎上,研究調蓄系統在無人參與情況下實現自治理功能,主要內容包括:① 雨水收集;② 浮渣隔離;③ 調蓄池蓄水狀態下淤泥清除;④ 雨水分級利用;⑤ 污泥分級處理等.
l為輸入數據的長度;
s為葉節點寬度;
//訓練GRU模型
1. 將輸入步長step與特征值feature相結合
/*本實驗設置步長為3*/
2. c=inp(feature)+step;
3. 將結合后的數據放入遺忘層,保存狀態到候選者層
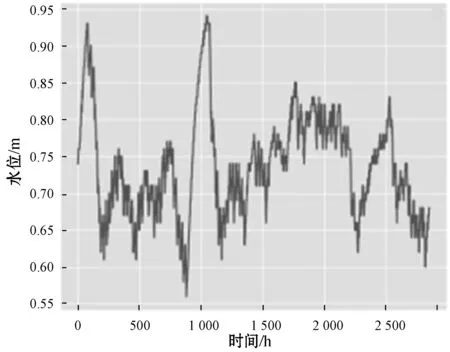
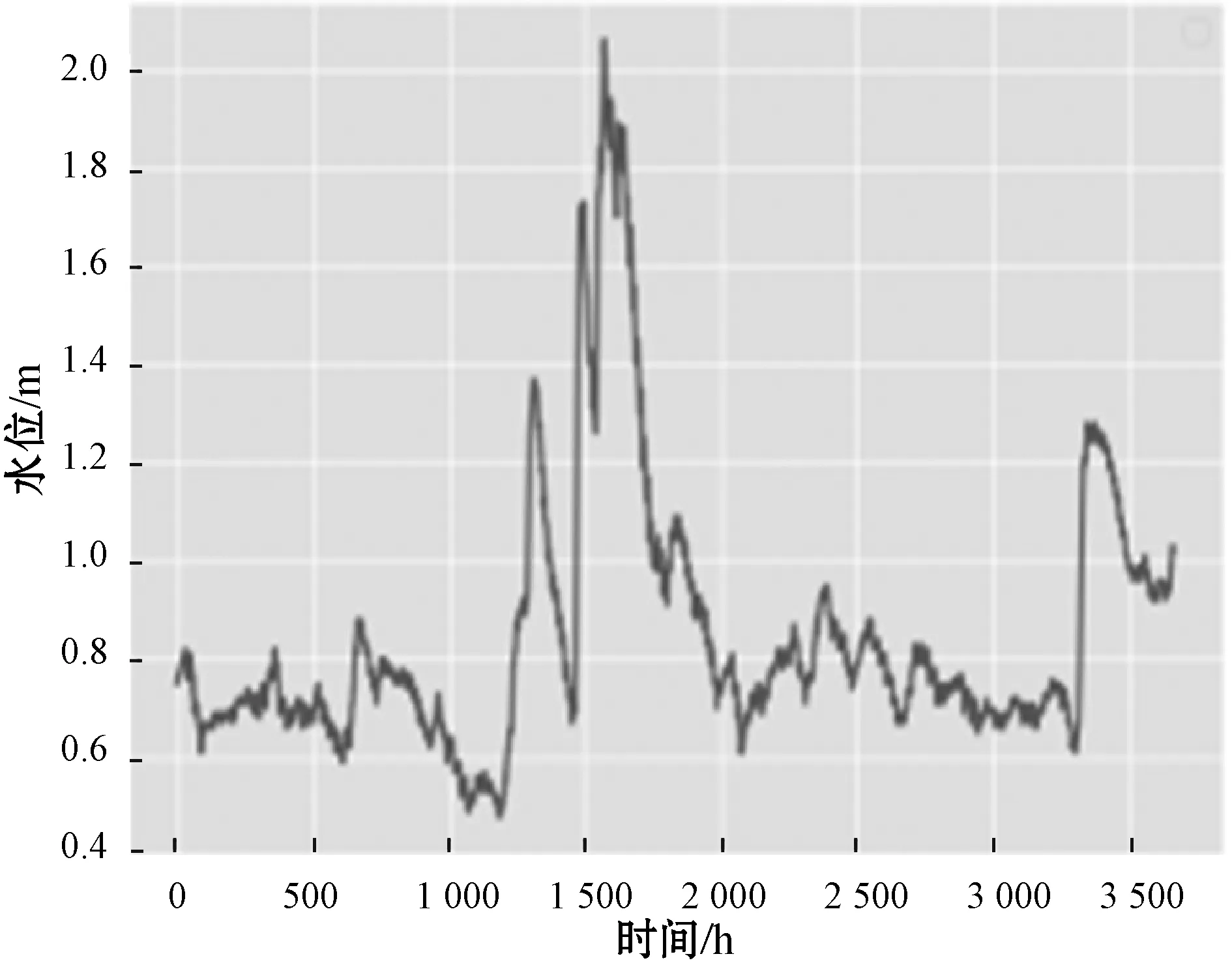
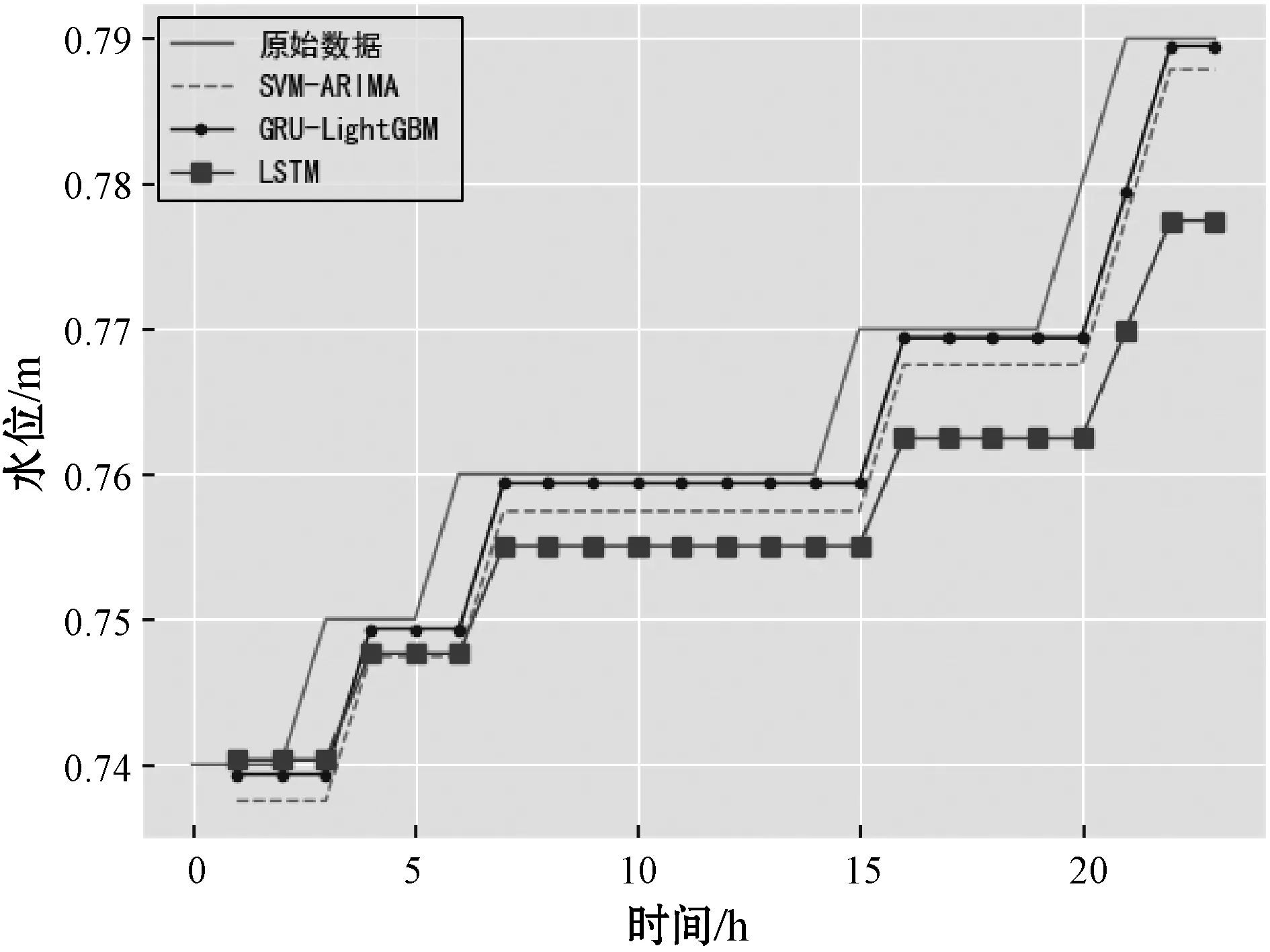
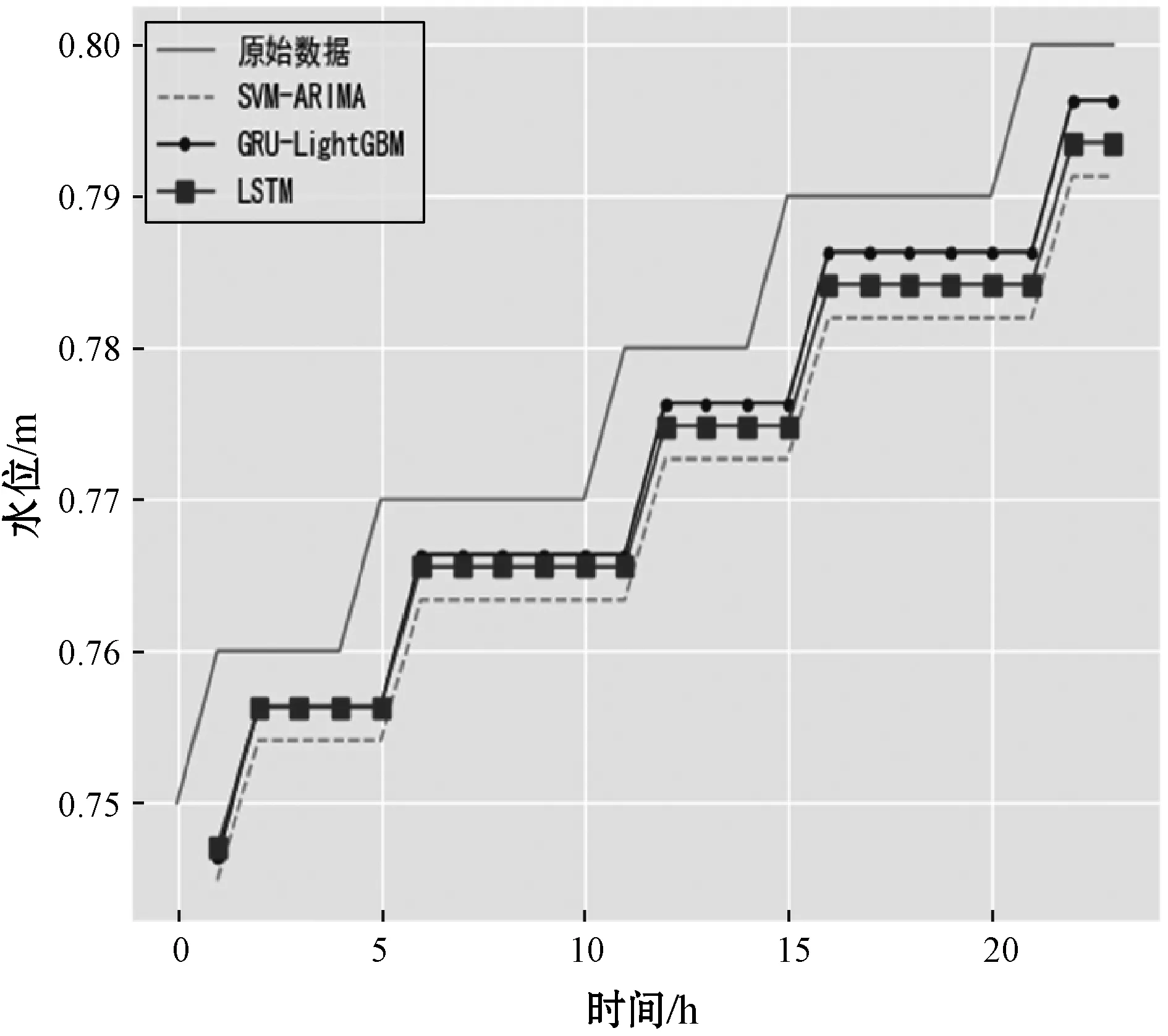
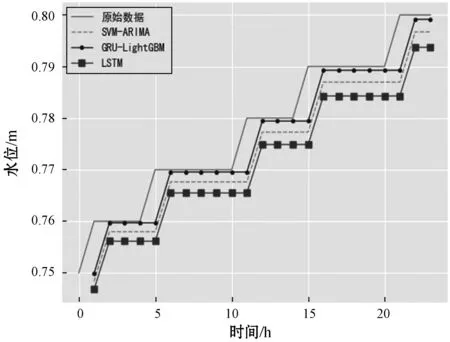
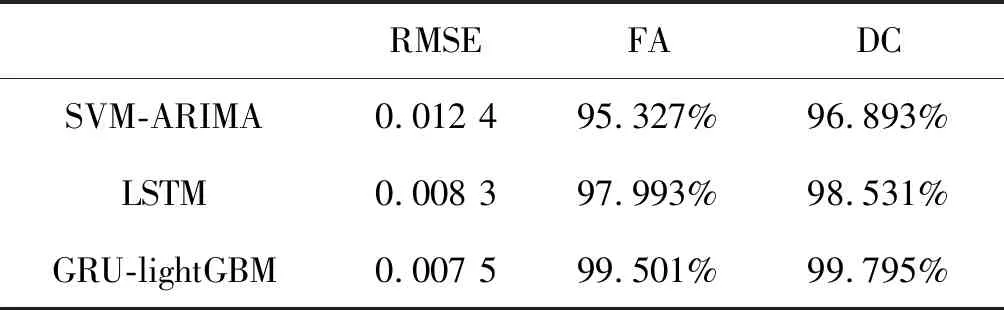
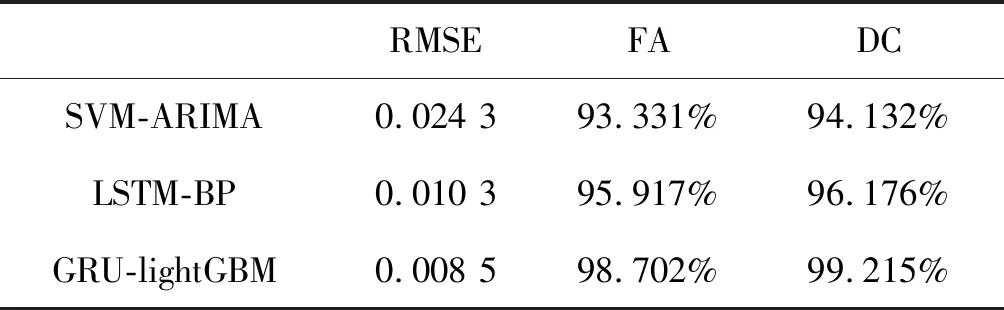
4. if(c.val) /*max_bin為預設的根堆大小*/ 5. for i=0 to l do val.put(bin); /*用leave_wise算法建立樹模型*/ 6. endif 7. return arg(max(max(bin))) //特征篩選并進行LightGBM建模 8. while bin /*Leave_size為葉節點寬度*/ 9. 計算特征重要度; 10. end while 11. for i=0 to l 12. lgb建模; 13. i++; 14. end for 實驗平臺為PyCharm2017.3 x64,Windows 7所搭載的操作系統,使用基于TensorFlow的keras框架進行編碼,數據集來源于江蘇省水利廳信息科,選用數據集為淮河流域射陽河某站點2016年1月1日0點至2016年5月1日0點的2 864條非汛期數據以及2018年5月1日0點至2018年9月30日12時的3 669條汛期數據。數據集被分為兩部分,67%為訓練集,33%為測試集,實驗采用了對比的方法,將GRU-LightGBM綜合模型的預測效果分為非汛期和汛期分別同GRU、ARIMA單個模型相比較。具體的實驗步驟如下:1) 定義模型;2) 添加GRU層數;3) 根據數據情況添加dropout層;4) 定義輸出層神經元個數為1;5) 添加激活函數進行模型優化;6) 運行模型并保存結果。圖4、圖5為射陽河流域每小時水位的時間序列圖。 圖4 非汛期水位數 圖5 汛期水位數據 為了綜合考量實驗模型的效果,本文使用多個參數對實驗的結果進行分析,分別為均方根誤差(RMSE)[15]、預報準確率(FA)[16]以及決定系數(DC)。 (9) (10) 這兩個公式在各大深度學習算法[17]中均有介紹。式中:(pred)表示預測值,y(raw)表示實際值。此外,針對水位時間序列的特殊性,為了比較模型的擬合效果,本文增加了一個指標即為決定系數: (11) 式中:SSE為所有觀測點的殘差和,SST為所有點和均值差的總和,DC值越接近一代表預測準確率越高。 對于非汛期和汛期的水位數據分別進行預測其接下來的24個點的數據,效果如圖6、圖7所示。 圖6 非汛期水位預測效果對比 圖7 汛期水位預測效果對比 對比圖6、圖7可以看出,非汛期的總體預測效果較好,基本與原始數據重合,而汛期的預測效果較差,三種模型都偏離了原始數據。 針對汛期水位受多重因素影響[20]從而導致精度不足的情況,采用lightGBM進行特征篩選[18]。 在分析水位數據及其影響后,得出了影響水位的九種環境因素,分別是:1) 上游第一個水位數據;2) 上游第二個站點水位數據;3) 下游第一個水位數據;4) 下游第二個水位數據;5) 溫度;6) 降雨量;7) 去年同期水位;8) 前6小時降雨量總和;9) 去年同期降雨量。使用LightGBM評估環境因素重要性,結果如圖8所示。 圖8 環境因素重要程度排序 可以看出,重要程度前四的特征相關度[19]更高,從特征“溫度”往后的特征對預測結果幾乎不產生影響。因此,將這四類特征與預測值再度建立LightGBM模型進行預測,所得預測結果如圖9所示。 圖9 加入環境因素后汛期預測對比 通過實驗驗證,隨著時間的推移,SVM-ARIMA模型以及LSTM循環神經網絡網絡模型在擬合程度上漸漸偏離原始數據,而經過改進的GRU和lightGBM組合模型在預測效果上表現得更加優秀,預測值更接近實際值。非汛期的總體預測效果較好,基本與原始數據重合,而經過特征選擇的汛期的預測效果比最初模型的效果更好。實驗證明了GRU和lightGBM組合模型相較于其他算法在預測精度有了提高。 通過實驗驗證,隨著時間的推移,SVM-ARIMA[21]模型以及LSTM循環神經網絡模型在擬合程度上漸漸偏離原始數據,而經過改進的GRU-lightGBM在預測效果上表現地更加優秀,預測值更接近實際值。實驗證明了GRU-lightGBM組合模型相較于其他算法在預測精度有了提高。 非汛期以及非汛期預測效果對比的實驗結果如表1、表2所示。 表1 非汛期預測效果對比表 表2 汛期預測效果對比表 通過分析表1、表2可知,在非汛期時,基于GRU-lightGBM的組合預測模型無論是在預報準確率還是決定系數上表現均為最佳,而汛期的水位由于受到降雨量的影響,預測準確率較之非汛期稍低。但綜合各項指標,組合模型的預測值更接近實踐值,體現出了模型的合理性和優越性,總體來說GRU-lightGBM組合模型在水文數據的預測上優于單一模型。 針對單一模型對于具有季節性、復雜性的水文數據預測精度不足,本文提出了一種基于GRU和lightGBM的組合預測模型,將其應用于射陽河的小時預測。為了驗證方法的有效性,將組合模型和傳統機器學習模型SVM-ARIMA及LSTM模型進行對比,經實驗驗證組合模型預測準確率和效率均高于單一模型。但水文數據信息影響因素較多,本文所用模型未考慮一些特殊的變化因素,有待進一步的改進。未來將在單節點預測水位時間序列的基礎上將模型推廣至多個空間節點,建立上下游的對應關系,真正體現出組合模型的優勢。3 實 驗
3.1 實驗準備
3.2 評價指標
3.3 實驗結果與分析
4 結 語
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38網絡安全與數據管理(2022年1期)2022-08-29 03:15:20導航定位學報(2022年4期)2022-08-15 08:27:00中學生數理化·中考版(2022年8期)2022-06-14 06:55:24新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36成都醫學院學報(2021年2期)2021-07-19 08:35:14新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50數學物理學報(2020年2期)2020-06-02 11:29:24光學精密工程(2016年6期)2016-11-07 09:07:19
