基于“數據驅動+智能學習”的合成孔徑雷達學習成像
2020-03-18 02:24:00倪嘉成
雷達學報 2020年1期
關鍵詞:方法
羅 迎 倪嘉成 張 群③
①(空軍工程大學信息與導航學院 西安 710077)
②(信息感知技術協同創新中心 西安 710077)
③(復旦大學電磁波信息科學教育部重點實驗室 上海 200433)
1 引言
合成孔徑雷達(Synthetic Aperture Radar,SAR)作為一種利用微波進行感知的主動傳感器,能夠不受天氣、光照等條件限制,對感興趣目標進行全天候、全天時、遠距離的持續觀測,并具有識別偽裝、對光學隱蔽目標成像的能力,因而成為軍事偵察、情報獲取的主要探測手段。目前,SAR技術已經廣泛應用于機載、星載、彈載等多種平臺,成為各國爭相發展的重要偵察技術[1]。
對感興趣目標的數量、位置、型號等參數信息的精確獲取一直是SAR最為重要的研究內容之一。現階段的SAR信息處理主要分為成像和解譯兩大部分,兩者的研究之間相對獨立。成像方面,SAR成像系統發展迅速,機載SAR分辨率普遍達到亞米級,個別已經達到厘米級;成像幅寬與平臺高度和成像體制有關,最大可達上百公里;SAR數據獲取能力也得到了大幅提升,單次航過回波數據量大幅增加。然而,圖像分辨率提升和圖像整體細節的增加也使得圖像數據量大幅增加,圖像背景也更加復雜,給部分目標檢測、識別算法增加了難度。因此,SAR成像在分辨率方面的提升并未從本質上解決現階段SAR圖像解譯困難、特別是對重點目標識別率低的問題。SAR解譯方面,目前對SAR圖像中感興趣目標的解譯工作仍大量依靠人工完成,無法滿足目標信息處理的實時性需求。受SAR圖像尺寸大、相干斑噪聲嚴重、背景復雜、目標輪廓模糊等因素影響,現有的SAR圖像解譯方法在有效性、準確性和時效性方面同樣無法滿足對重點目標的信息處理需求。另外,現有SAR解譯方法主要從SAR圖像中提取目標信息,在圖像預處理、特征提取等解譯過程中丟掉了大量圖像細節信息,導致了SAR成像資源的浪費。SAR成像和解譯各自開發了大量算法,復雜度越來越高,但目標分類識別率低、目標屬性判別困難的問題依然存在。
本文針對機載SAR中存在的問題展開研究,在分析機載SAR研究現狀及存在問題的基礎上,嘗試從SAR成像解譯一體化角度出發,基于“數據驅動+智能學習”的方法,探索提升機載SAR的信息處理能力的新思路。本文分析了基于“數據驅動+智能學習”的SAR成像解譯一體化的可行性及現階段存在的主要問題,在此基礎上,以成像解譯一體化為目標,提出一種基于“數據驅動+智能學習”的SAR學習成像方法,給出了初步的仿真結果,并展望了未來需要解決的關鍵性技術問題。
2 機載SAR研究現狀及存在的主要問題
機載SAR具有機動性好、工作方式靈活、機上實時成像下傳等優勢,被廣泛應用于軍事、民用領域。近年來,中科院電子所、國防科技大學、西安電子科技大學、清華大學等國內多家單位在機載SAR研究領域取得了豐碩的研究成果,極大推動了我國機載SAR成像技術的發展[2-7]。
SAR成像方面,目前機載SAR已經向高分辨、多通道、多極化、多模式的方向發展,并在維度上由2維向3維突破。成像模式上,SAR成像已由原來的條帶、聚束、掃描模式向滑動聚束模式[8]、
TOPS(Terrain Observation by Progressive Scans)模式[9](多用于星載SAR)等高分辨率寬測繪帶成像模式擴展;成像維度方面,由早期的干涉SAR到現在的層析SAR[10](主要用于星載SAR成像)、陣列SAR[11,12]、圓跡SAR[2],以及最新提出的SAR微波視覺3維成像技術[13,14],都推動了SAR成像由2維向3維發展。成像對象方面,現有成像方法除了能獲得高分辨的靜止場景成像結果外,還逐步具備動目標檢測與動目標聚焦成像能力[15-17]。成像方法方面,現有的SAR成像方法主要有兩種,一種是基于匹配濾波的SAR成像方法,該方法不依賴任何目標的先驗信息,直接通過傅里葉變換和匹配函數進行成像,具有實現簡單、成像穩定的優點,但存在采樣要求嚴格、分辨率受限、成像結果旁瓣較高等不足;另一種是基于稀疏優化理論的SAR成像方法,該方法將SAR成像問題轉化為“反問題”(Inverse problem),通過增加目標的稀疏先驗信息對求逆模型進行約束,利用迭代優化算法求解場景的散射系數,具有采樣率低、分辨率高、成像結果旁瓣小等優勢[18-20],但目前也存在計算復雜度高、對機載平臺誤差適應能力弱、優化算法超參數選擇困難等問題。
解譯方面,現有方法主要圍繞自動目標識別(Automatic Target Recognition,ATR)的3級處理流程展開[21]。在3級流程中,對目標特征的準確提取是SAR ATR的核心,目標特征可以分為基于人工設計的特征以及高維數據特征兩種。人工設計的特征包括灰度特征、幾何特征、變換域特征、紋理特征等等[22],而高維數據特征主要包括各種深度神經網絡提取的隱藏層數據特征[23]。目前,基于智能學習方法的SAR ATR技術發展迅速,識別率相比人工特征得到了很大提升。但智能學習方法需要大量圖像數據進行網絡訓練,現階段各類型SAR傳感器雖然積累了大量SAR圖像數據,但針對特定型號目標,且帶有標記數據的SAR圖像目標數據庫還較少,樣本數據不足的問題一定程度上限制了基于智能學習的SAR ATR技術的發展。另外,現有基于智能學習的SAR目標檢測、識別方法對圖像尺寸和背景雜波有一定要求,面對大場景SAR圖像、復雜背景SAR圖像的檢測率和識別率還有待進一步提高。
雖然機載SAR技術近年來取得了飛速發展,在民用方面取得了廣泛應用,但在感興趣目標的參數獲取與屬性判別方面,現有方法距離實際應用還有較大差距。目前,受數據處理能力不足的限制,對SAR圖像中感興趣目標的解譯工作仍主要依靠人工完成。而現有SAR圖像ATR方法在有效性、準確性和時效性方面同樣無法滿足實際應用需求。具體而言,現階段機載SAR系統在感興趣目標參數獲取方面還存在以下問題:
(1)SAR成像系統與SAR圖像解譯系統互相獨立,無法共同作用提升SAR信息處理能力。SAR系統通過傳感器獲取0級數據后,需要首先利用機載實時成像系統或地面站對回波進行處理,通過各種成像算法得到SAR圖像,然后再利用解譯系統對SAR圖像進行處理,從中提取感興趣目標的特征信息,進而獲取目標的參數信息。現有SAR成像方法主要考慮如何提升分辨率、增加圖像細節,很少考慮到后續SAR圖像處理中面臨的困難。分辨率的提升一方面增加了目標的細節信息,但另一方面回波數據量也大幅增加。圖像整體細節增加的同時圖像背景也更加復雜,這也給一部分目標檢測、識別算法增加了難度。此外,圖像數據量的增大也給解譯方法增加巨大負擔,態勢獲取的時效性差。因此,現有SAR成像方法主要提升分辨率和圖像細節,無法直接提高對目標屬性的判別能力,大量成像資源在解譯過程中被浪費。同樣地,現階段SAR解譯方法只能從圖像中提取目標特征信息,為了去除背景,突出目標,需要大量預處理操作,在圖像去噪、感興趣區域提取的過程中又丟掉了大量信息,損失了圖像細節。另外,現有SAR目標解譯方法主要基于像素進行處理,面對動輒上億像素的大場景SAR圖像,圖像解譯速度無法滿足態勢獲取的實時性要求。
(2)現有方法對海量SAR數據的利用率低。SAR傳感器方面,現有SAR傳感器已經具備多波段、多通道、多極化、干涉等多類型的SAR數據獲取能力,然而現階段不同類型的SAR傳感器及獲取的SAR數據只能單獨進行處理,對如何獲取不同傳感器之間關于同類型目標的共有特征研究較少。SAR成像方面,多年來大量SAR傳感器積累了海量的SAR回波數據和SAR圖像數據,然而由于數據處理能力的不足,大量SAR數據被閑置,未得到有效利用。另外,現階段相同目標在不同雷達參數、多視角、多入射角條件下的共有特征還未得到提取與挖掘。SAR解譯方面,大量的SAR解譯方法提取了目標的幾何尺寸、結構、形狀、統計分布等多種類的特征信息,然而提取到的目標特征互相之間沒有建立聯系,無法共同作用提升目標識別性能。
(3)復雜背景下目標屬性判別困難,不同種類目標之間的識別難度差異較大。現有的SAR自動目標識別方法主要利用人工設計好的特征實現對目標的屬性判別,例如圖像灰度統計特征、結構特征、紋理特征等。上述人工特征對目標-背景差別明顯的圖像效果較好,例如空地上的坦克、航行中的艦船等簡單背景目標。當面對機庫附近的飛機、港口里的艦船等復雜場景目標時,由于背景中也包含大量人工特征,導致現有SAR目標檢測方法的準確率大幅下降。同時,人工設計的特征通用性較低,往往只適用于某些特定場景,敵方還能夠有針對性地設計滿足人工特征的假目標,使得真假目標間對應的特征差異性降低,從而提高SAR系統的戰場態勢獲取難度。
3 基于“數據驅動+智能學習”方法的SAR成像解譯一體化分析
通過第2節的分析不難看出,現階段SAR成像技術與SAR解譯技術之間相互割裂,嚴重影響了SAR感興趣目標參數獲取的準確性和時效性。如果能夠突破SAR成像與SAR解譯之間的限制,實現成像解譯的一體化,必將極大提升SAR系統的整體數據處理能力和處理時效性。下面本文從信號性質變換關系出發,對基于“數據驅動+智能學習”方法的SAR成像解譯一體化展開分析討論。
3.1 從“回波數據域”到“目標參數域”
從信號的性質變換關系來看,現階段的SAR信息處理主要涉及3個“域”的映射關系,即SAR成像通過傅里葉變換和匹配濾波方法,將單次航過的SAR回波數據從“數據域”映射到觀測場景的2維“圖像域”;而SAR圖像解譯則通過各種圖像處理方法,將SAR圖像從“圖像域”映射到“目標參數域”,其中目標參數域包含目標位置、尺寸、數量、型號、動目標速度、運動方向等多種目標特征參數。圖1給出了現階段SAR信息處理的基本流程及3個“域”的映射關系圖。
可以看出,突破SAR成像與SAR解譯之間的限制,關鍵就是要找到從“回波數據域”到“目標參數域”的映射關系。圖1中,SAR成像過程雖然可以用線性模型來表示,但機載SAR往往面臨載機運動誤差、目標非合作機動以及復雜電磁干擾等影響,因此從“回波數據域”到“圖像域”是一種非線性映射關系。在SAR解譯中,從“圖像域”到“目標參數域”包含去噪、分割、特征提取等多種圖像域操作,兩者之間的映射是一種復雜的非線性關系。因此,直接從“回波數據域”到“目標參數域”的映射關系必然是高度抽象和非線性的。
針對這一問題,基于數據驅動的智能學習方法為尋找“回波數據域”和“目標參數域”之間的復雜非線性映射關系提供了新的思路。如果從機器學習的角度來分析,那么匹配濾波SAR成像、稀疏SAR成像以及基于人工特征的SAR特征提取方法都可以歸類于模型驅動的方法。模型驅動的優點是參數少,在成像時只需要單次航過的SAR回波數據,在目標檢測、識別時對目標訓練樣本的需求也較小。而缺點則是要求模型足夠精確和簡單,因此對復雜非線性映射的擬合能力較弱。與傳統基于模型驅動的SAR成像和SAR解譯方法相比,數據驅動方法的優勢是適應力強,能夠最大限度擬合數據中的復雜非線性映射關系,而缺點則是神經網絡的拓撲結構設計難度大、網絡參數多、對數據量的需求巨大。
近年來,深度學習、強化學習、元學習等智能學習方法發展迅速,并已在多個領域展現出強大的優勢。智能學習方法以海量目標數據作為輸入,利用構建的深層非線性網絡,通過學習訓練的方法獲取海量數據中蘊含的復雜非線性映射關系。目前,智能學習類方法已經成功應用于SAR圖像解譯,能夠從海量SAR圖像數據中獲取目標的高維抽象特征,實現對目標類別的區分。然而現有方法只能夠表征SAR從圖像域到目標單一參數域的映射關系。下面以典型深層神經網絡為例,分析智能學習方法如何表征回波數據域到目標參數域的非線性映射關系。
典型深層神經網絡的某一層網絡輸出通常可以表示為
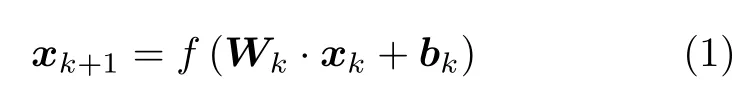
其中,xk表示網絡第k(k=1,2,···,K)層的輸入向量,Wk表示第k層的權重,bk為第k層的偏置,f()表示非線性激活函數,該函數將括號內的線性組合形式變換為非線性形式,從而能夠通過多層的網絡輸出擬合復雜的非線性映射關系。對于SAR成像而言,可以將其看作一個線性反問題,表示為矩陣和向量相乘的形式

其中,s ∈CP Q×1表示SAR回波信號的離散化向量形式,P為距離向采樣點數,Q為方位向采樣點數。σ ∈CMN×1表示觀測場景散射系數的向量形式,M,N分別為距離向和方位向離散網格數。n ∈CP Q×1為噪聲向量。Φ ∈CP Q×MN表示成像觀測矩陣,反映了觀測場景到回波信號的全部映射關系。基于“數據驅動+智能學習”方法的SAR“回波數據域”到“圖像域”映射,可以將式(2)表示為式(1)中的形式:
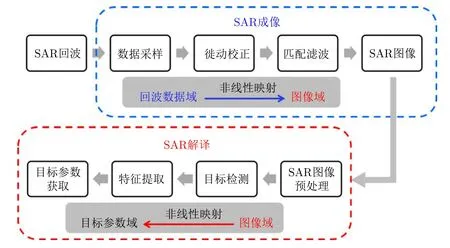
圖1 現階段SAR信息處理基本流程圖Fig.1 Basic flow chart of SAR information processing at present
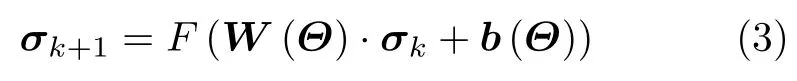
其中,W(Θ),b(Θ)分別為權重項和偏置項,Θ={Φ,σ,···}表示與觀測矩陣、成像場景有關的待學習參數,F()為非線性激活函數。對于SAR解譯,以目前廣泛應用且效果較好的卷積神經網絡為例,在得到場景散射系數σ后,目標的類別信息y可以表示為
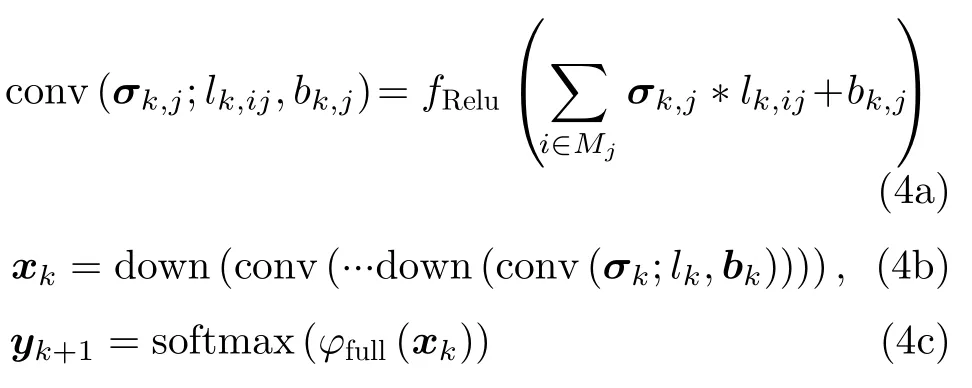
其中,conv()表示卷積層操作,Mj表示輸入圖像塊的集合,l為卷積核,b為偏置,k是層序號,i是卷積核序號,j是特征圖通道序號,fRelu()為非線性ReLU激活函數,“*”表示卷積運算。x表示網絡得到的特征圖,down()表示池化層操作,目的是對特征圖進行下采樣,φfull()表示對提取的特征圖進行全連接,即將上一層得到的特征圖進行順序排列。softmax()表示最終的分類操作,一般選用softmax分類器進行。
將式(3),式(4)對應的網絡結構合并,即能在一定程度上實現從回波數據到目標類別信息的映射。然而該網絡僅僅能夠表征含單一目標的SAR回波數據到目標類別參數的映射關系,針對包含多個目標的寬幅SAR場景,還需要在此基礎上添加多層網絡結構,例如目標檢測網絡、特征提取網絡等。圖2給出了一種基于神經網絡結構的“回波數據域”到“目標參數域”成像解譯一體化流程圖。網絡以SAR回波數據作為輸入,可以添加現有SAR目標圖像和目標先驗特征作為樣本標簽,當網絡訓練完畢后,從SAR回波到目標參數和目標類別只需要進行一次網絡正向傳遞,無需任何迭代和反向傳播,有望大幅提升SAR目標參數獲取的準確性和時效性。
3.2 現階段存在的問題分析
雖然近年來基于智能學習的數據驅動方法在信號處理,特別是圖像處理領域展現出強大的優勢,只要網絡模型足夠復雜,理論上可以擬合任意非線性函數,但現階段基于“數據驅動+智能學習”方法,直接利用海量數據學習得到“回波數據域”到“目標參數域”的映射關系還存在以下困難:
(1)觀測數據集的完備性無法保證。SAR回波中包含雷達參數、載機航跡、雷達波入照角、目標運動等多種可變參數,任何參數的變化都會影響“回波數據域”到“目標參數域”的映射關系。現階段同一目標在多航跡、多角度條件下實測數據較少,動目標成像中的目標運動軌跡、運動參數未知,成像幅寬大幅增加使得網絡異常復雜,依托現有SAR數據無法直接滿足數據集的完備性要求。
(2)對未知非合作目標的數據獲取困難,依靠數據驅動來獲得有效特征存在小樣本甚至零樣本的難題。現階段對新型未知目標的數據獲取極為困難,而仿真數據與真實數據的差異性較大,現有智能學習方法還無法直接利用。
(3)SAR回波數據標注困難。由于SAR回波數據只是觀測場景散射點后向散射回波的疊加,本身并不含任何標簽信息,因此將回波數據與目標參數對應時,必須人為添加回波數據的標簽信息,這大幅提升了智能學習方法的學習成本。
通過以上分析可以看出,從SAR“回波數據域”到“目標參數域”之間的參變量數量非常巨大,未知非合作目標數據量少,樣本標簽制作復雜耗時,因此依靠現有的數據獲取條件直接表征兩者之間的復雜非線性映射關系還存在很大難度。考慮到當前智能學習類方法在SAR圖像解譯方面(包括目標檢測、特征提取、分類識別等)已經取得了很好的應用效果,從圖2所示的成像解譯一體化流程圖可以看出,若能構造出成像網絡來實現“回波數據域”到“目標圖像域”的非線性映射,將有望通過多個網絡的級聯來實現“回波數據域”到“目標參數域”的非線性映射。因此,下面著重討論如何構造成像網絡,并給出基于“數據驅動+智能學習”的SAR學習成像方法,初步的仿真實驗表明,利用構造網絡來實現SAR成像的思路是可行的,且相比現有經典成像方法,具有更快的成像速度和成像性能。

圖2 一種SAR“回波數據域”到“目標參數域”成像解譯一體化流程圖Fig.2 An flow chart of SAR imaging &interpretation integration from“echo data domain”to“target parameter domain”
4 基于“數據驅動+智能學習”的SAR學習成像
為了簡化SAR“回波數據域”到“目標參數域”的映射關系,降低參變量數量,減少對樣本數據集的完備性需求,本節以圖2中的成像網絡為目標,提出一種基于“數據驅動+智能學習”的SAR學習成像方法。
第3節中已經提到,SAR成像問題可以轉化為一個反問題進行求解。目前,基于深度學習的數據驅動方法已經在信號恢復[24]、圖像去噪[25]、圖像復原[26]等反問題求解領域展現出優勢。文獻[27]率先將深度學習應用于SAR成像中,提出了一種基于深層展開迭代軟閾值算法(Iterative Soft Thresholding Algorithm,ISTA)的SAR成像方法,實現了含相位誤差條件下的點目標成像。文獻[27]初步驗證了深度學習方法在SAR成像中的可行性,但該方法的可學習參數較少,因此對迭代算法的依賴性更強,而對數據的“學習”能力弱,另外該方法并未解決復數信號的網絡訓練問題,對場景的重構質量有待進一步提高。
本文提出的基于“數據驅動+智能學習”的SAR學習成像網絡將非線性激活函數、損失函數等網絡參數納入可學習范圍,進一步拓展了數據在基于智能學習的SAR成像中的應用范圍。首先給出SAR學習成像網絡結構,然后詳細介紹網絡參數的選取及訓練方法,并在第5節給出仿真實驗和分析。
4.1 網絡結構
傳統神經網絡的某一層輸出可以用式(1)來表示,即在一個線性模型的基礎上增加一層非線性激活函數。該網絡結構的優勢是方便進行誤差反向傳播和參數調優。根據3.1節的分析,SAR成像同樣可以表示為一個矩陣-向量相乘的線性模型,稱為1維SAR觀測模型。圖3給出了該模型的示意圖。假設SAR發射線性調頻(Linear Frequency Modulation,LFM)信號,那么在條帶成像模式下,觀測矩陣Φ的具體表達式可以寫為

其中,rect()為矩形時間窗,γ為調頻率,Tp為發射脈沖寬度,fc為載頻,為第p=1,2,···,P個距離向采樣對應的快時間,tm,q為第q=1,2,···,Q個方位向采樣對應的慢時間,τ(x,y)q表示坐標(x,y)處的場景網格點在慢時間tm,q時刻的回波時延。可以看出,Φ中包含了雷達窗函數、載機到目標斜距、回波相位等信息,當雷達參數無誤差,且SAR平臺沿已知軌跡做勻速運動時,可以認為Φ是精確已知的。假設噪聲為加性白噪聲(Additive White Gaussian Noise,AWGN)時,該線性模型就可以通過求解最優化問題得到


圖3 1維SAR觀測模型示意圖Fig.3 One dimensional SAR observation model
本文提出的SAR學習成像網絡建立在1維SAR觀測模型基礎上,將對1維線性模型的求解過程映射到神經網絡的一層中,通過多層網絡的堆疊和展開實現對場景散射系數的求解。所提成像網絡有兩方面優勢:一是可以將原先固定的成像觀測矩陣、正則化參數、迭代步長等模型參數變為可學習的網絡參數,通過深度學習中無監督或監督的網絡訓練方式,讓網絡自主學習得到不同輸入回波數據、不同觀測場景下成像質量最優的模型參數,從而實現對線性模型中未知誤差的逼近,提升成像方法對SAR數據的普適性和泛化能力;另一方面,所提SAR學習成像網絡利用1維線性模型設計網絡結構,可以通過迭代優化算法對神經網絡結構進行約束,按照迭代優化算法的計算步驟設計網絡層級的數學表達式以及權重項、偏置項的具體形式,從而指導神經網絡的拓撲結構設計,減少網絡可學習參數,降低網絡對SAR回波的數據量需求。具體而言,單層神經網絡結構可以采用傳統神經網絡的“權重+偏置”形式,即式(3)的形式,將其重新寫為式(7)

其中,W(Θ),b(Θ)分別為網絡的權重和偏置,Θ={Φ,s,λ,···}表示與雷達回波、觀測矩陣、正則化參數有關的待學習參數,F()為非線性激活函數。圖4給出了本文提出的SAR學習成像網絡結構圖,其中藍色方框內均為可學習變量。
該網絡結構與深層展開(Deep Unfolding,DU)網絡的結構基本一致,即將多層結構相同的單層網絡進行堆疊,每一層都可以得到關于散射系數的重構結果。關于深層展開網絡,文獻[28]中已經證明,每一層網絡采用不同的權重系數僅能帶來極少的性能提升,但會極大增加網絡的訓練復雜難度和數據量需求。為了降低參變量數量,減少對樣本數據集的完備性需求,所提方法同樣令所有層中的權重和偏置相同。F()括號內的具體表達式可以應用任意迭代優化算法實現,如迭代軟閾值法(Iterative Soft Thresholding Algorithm,ISTA)、交替方向乘子法(Alternating Direction Method of Multipilers,ADMM)、近似消息傳遞(Approximate Message Passing,AMP)算法等。以ISTA算法為例,ISTA算法首先計算第k次迭代的殘差rk,再通過與正則化參數λ有關的閾值函數F(v;λ)計算第k+1步的預測值
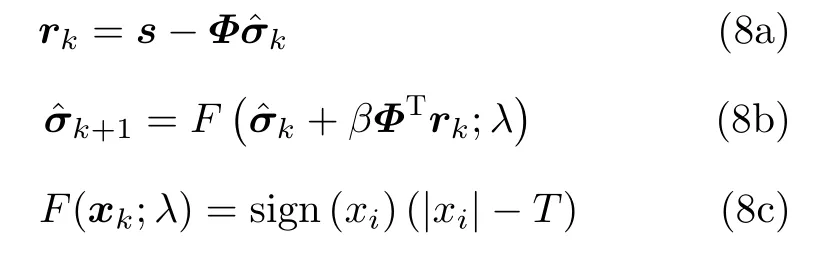
其中β為算法步長,T為迭代閾值。按照ISTA算法步驟,可以將其映射為深度神經網絡的單層拓撲結構,即:
(1)算子更新層:對場景散射系數進行更新,實現式8(a),式8(b)的功能。將式8(a)和式8(b)合并,可以轉化為
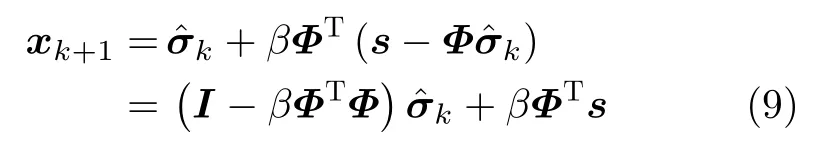
可以看出,式(9)中的W=I ?βΦTΦ,b=βΦTs;
本層包含的可學習參數:觀測矩陣Φ;算法步長β。
(2)非線性變換層:對網絡進行非線性變換,輸出下一層的場景散射系數k+1,表達式可以與式8(c)相同,也可以是其他非線性激活函數。
本層包含的可學習參數:非線性函數F,正則化參數λ。
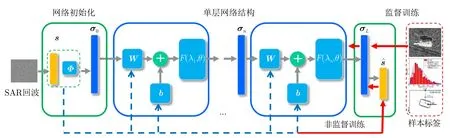
圖4 SAR學習成像網絡結構圖Fig.4 Network structure of SAR learning-imaging
算子更新層和非線性變換層共同構成了SAR成像網絡的單層拓撲結構,其中待學習參數為Θ={Φ,λ,β,F}。同樣地,其它迭代優化算法如ADMM算法、AMP算法等同樣可以表示為不同的網絡層級,對應的層級表達式和待學習參數需要根據算法的具體表達式進行改變。
4.2 網絡參數選取
在確定了網絡中權重和偏置的表達式后,另一個重要的網絡參數就是非線性激活函數。目前深度學習中常用的激活函數有sigmoid函數、tanh函數、ReLU函數等,理論上任意滿足條件的非線性激活函數都可以作為SAR學習成像的激活函數。考慮到SAR成像場景很可能滿足稀疏特性,因此一種可行的方案是使激活函數的輸出值盡可能稀疏,例如ISTA算法中的各種軟閾值函數,如
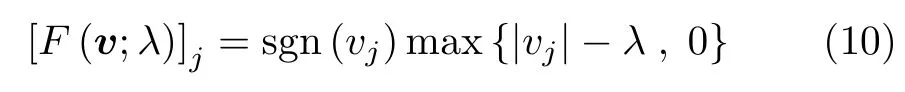
另一種方案是利用類似ReLU函數的分段線性函數。ReLU函數彌補了sigmoid函數以及tanh函數的梯度消失問題,因此得到了廣泛的應用。SAR學習成像方法同樣可以應用分段線性函數,分段過程中可以在分段點和不同線性區域增加可學習參數,從而使激活函數變為可學習函數。
除了基于現有的神經網絡激活函數外,還可以專門設計與回波數據噪聲分布和場景先驗分布有關的自適應激活函數。文獻[28]針對AMP算法設計了一種基于最小均方誤差的非線性閾值函數,利用數據本身的先驗分布計算該分布條件下的最優非線性函數。但在SAR學習成像中,回波數據與場景的先驗分布構造的激活函數能否滿足可微性、單調性等激活函數條件還需要展開進一步研究。
4.3 網絡訓練方法
(1)非監督訓練:如圖4所示,提出的SAR學習成像網絡既可以進行非監督訓練,也可以利用已知的SAR目標幾何尺寸、形狀、統計分布等特征信息進行監督訓練。由于SAR成像的場景未知,因此無法直接利用場景散射系數進行誤差反向傳播。針對這一問題,可以利用網絡最后一層得到的場景散射系數估計與觀測矩陣Φ相乘,得到SAR回波的估計值,從而與原始SAR回波數據進行對比,實現對模型的非監督訓練。在無監督樣本數據方面,可以對原始回波數據進行降采樣、增加不同信噪比的系統噪聲、增加回波相位擾動等方法實現無標記訓練樣本生成。以增加系統訓練噪聲為例,對于式(6)中的1維線性SAR成像模型,為數據擬合項,主要反映恢復信號與原始信號之間的擬合程度。該擬合項應用2范數的前提是假設噪聲n為加性白噪聲。因此,對原始回波數據增加不同輸入信噪比的高斯白噪聲,能夠在不改變稀疏SAR成像模型表達式的前提下獲取大量回波數據樣本,還能在一定程度上提高成像網絡在低信噪比條件下的魯棒性。另外,還可以在雷達回波相位中增加不同幅度的一次相位擾動和二次相位擾動來實現回波數據的樣本生成。該相位擾動模擬的是SAR平臺可能出現的運動補償誤差,因此可以提升成像網絡相對平臺相位誤差的魯棒性。假設樣本數據庫為S={s1,s2,···,sN},N為樣本數量,若采用均方誤差代價函數,則代價函數可以寫為
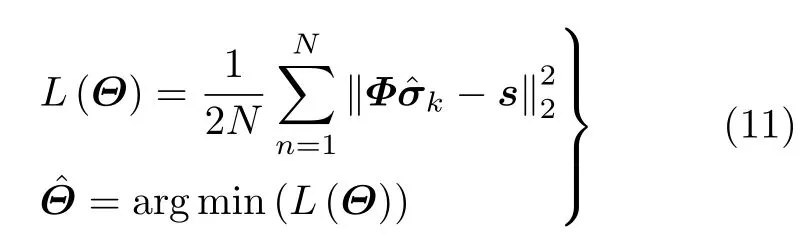
參數初始化方面,設定Φ0為式(5)獲得的觀測矩陣,,非線性激活函數為式(10)的形式。在進行回波誤差反向傳播時,為了避免梯度消失,可以設定一個較小的網絡學習率η,并隨著mini-batch的更新進一步減小。
非監督訓練的優勢是無需對SAR數據添加任何標記,從而大幅減小了SAR學習成像網絡的訓練成本。但非監督訓練的缺點也很明顯,一是對雷達回波的采樣率和信噪比有一定要求,當采樣率不足或者對回波進行壓縮采樣時,回波的數據量會大幅減少,從而影響代價函數的準確性;二是忽略了場景中目標的先驗信息和已知特征,無法進一步提升對重點目標的成像能力。
(2)監督訓練:監督訓練的一大難點是成像場景未知,無法直接制作回波中有關場景散射系數的標簽數據。但除了散射系數之外,不同SAR場景中的重點目標通常還存在一些共有的可分性特征,這些目標的可分性特征可以用來制作標記,從而提升對重點目標的成像精度。現階段SAR解譯中已經獲取了大量重點目標的幾何尺寸、形狀、統計分布等特征信息,而在SAR成像前,同樣可以設法獲取一些有關成像場景和場景中可能包含的重點目標的先驗信息。對于SAR成像場景,場景的統計分布特征,特定場景的語義特征等都可以作為觀測場景的特征標記。SAR圖像根據分辨率和場景內容可以服從G0分布、廣義Gamma分布等分布形式,將場景的統計分布函數作為標記,構造基于統計分布函數的目標函數,令SAR成像網絡輸出的SAR圖像滿足該分辨率條件下的特定統計分布,能夠進一步約束成像網絡的待學習參數范圍,提升網絡訓練速度。而SAR場景的語義特征同樣可以作為成像場景的特征標記,來約束成像網絡輸出圖像的幅值,將其對應到場景內的特定語義類別中,從而分離目標區域與背景區域,為后續SAR圖像解譯提供便利。假設χ(Θ,σ):Hσ →HD表示成像場景σ與目標可分性特征D={d1,d2,···,dk}之間的映射,k為特征數量,那么監督訓練的代價函數可以寫為

監督學習方法的優勢是能夠使散射系數估計值中包含已知的特征信息,從而更有利于下一步的SAR目標特征提取。缺點則是學習成本的大幅提升,另外,特征標記有可能與場景中的目標特征存在失配,導致對散射系數的估計出現誤差。
需要注意的是,由于SAR回波信號是復數信號,因此為了保留相位信息,在對式(11),式(12)中的網絡可學習參數進行調優時,必須利用復數進行反向傳播。目前,一些基于復數的反向傳播算法已經在神經網絡中得到應用,例如基于Wirtinger導數的反向傳播算法,可以作為SAR學習成像的網絡訓練方法。
5 仿真實驗和分析
本節通過實驗驗證提出的基于“數據驅動+智能學習”的SAR學習成像方法的可行性和有效性。為了便于生成樣本回波數據,以及測試不同噪聲環境以及不同軌跡誤差對成像性能的影響,本節采用仿真數據進行非監督訓練成像實驗驗證。
5.1 噪聲環境下點目標成像實驗
首先測試噪聲環境下所提方法對點目標的成像性能。將成像場景離散化為30×30的網格,場景內包含5個散射系數各不相同的散射點。表1給出了對應的仿真雷達參數和網絡參數。網絡結構方面,按照式(9)設計單層網絡的權重項和偏置項,按照式(10)設計非線性激活函數。網絡參數方面,按照式(5)初始化觀測矩陣Φ0,設定場景散射系數的初值。λ0=0.5,β0=0.5。為了測試所提SAR學習成像網絡在數據缺損條件下的成像能力,設定回波數據的隨機降采樣率為γ,定義為雷達實際采樣點數與按奈奎斯特采樣率采樣的點數的比值。網絡訓練方面,通過在回波數據中增加隨機加性噪聲的方式構建回波數據訓練樣本集,設定輸入信噪比為20 dB,同樣對訓練樣本進行降采樣,采樣率設定為γ。樣本集數量Ntrain=1000,回波數據中的場景同樣為點目標場景。為了減小梯度消失問題對訓練算法的影響,選取一個較小的網絡學習率η=10-6。實際成像時,直接將訓練得到的成像觀測矩陣、正則化參數、迭代步長等參數輸入成像網絡,經過網絡前向傳播后輸出成像結果。設定測試回波的輸入信噪比為20 dB,數據量Ntest=30,成像質量參數取30次的平均值。選取stOMP算法以及基于l1/2范數的ISTA算法作為對比算法,這兩種方法均屬于盲稀疏算法,在SAR稀疏成像中有成熟的應用。

表1 雷達參數和網絡參數Tab.1 Parameters of radar and network
下面給出非監督訓練的成像結果對比。由于非監督訓練需要與原始SAR回波數據進行對比,因此首先令γ=1,即數據無缺損條件下進行成像。設定訓練階段的樣本數據量Ntrain=1000,圖5給出了20 dB信噪比、不同網絡層數L對應的成像結果對比圖。
由圖5可以看出,當γ=1,即在全采樣條件下,所有方法均能正確重構出點目標的坐標位置和散射系數。所提方法當網絡層數L=3時,點目標周圍的旁瓣較高,當L=8時,可以明顯看出旁瓣得到了抑制,而當L=11時成像結果與L=8時基本相同。進一步增大噪聲能量,并對回波數據進行隨機降采樣來驗證算法性能。圖6給出了5 dB信噪比,降采樣率γ=0.1時的成像結果對比圖。
可以看出,在僅含有10%回波數據量且背景噪聲較大的條件下,所有方法的成像質量都有所下降。對于所提方法,由于非監督訓練的代價函數是利用估計的回波數據與原始回波數據進行對比,因此當原始數據大量丟失并被噪聲嚴重污染時,非監督訓練方法的成像質量無法得到進一步提升。表2給出了成像質量(峰值信噪比PSNR、均方誤差NMSE值、峰值旁瓣比PLSR)與成像時間的對比結果,實驗設定測試數據量Ntest=100次取平均值。所有實驗在一臺工作站(Intel i7 9700K,16 GB RAM)上完成,所提SAR學習成像網絡利用Python Tensor-Flow編程實現,并利用1塊英偉達GeForce RTX 2080 Ti顯卡進行GPU加速。

圖5 非監督訓練、γ=1,20 dB信噪比條件下成像結果對比Fig.5 Comparison of imaging results using unsupervised training,γ=1 and SNR=20 dB
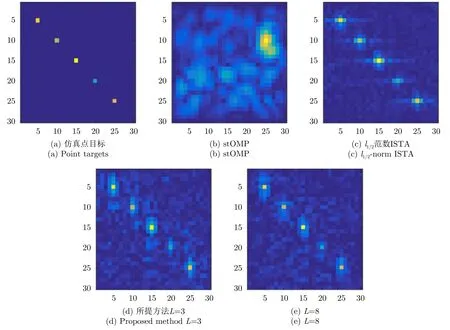
圖6 非監督訓練、γ=0.1,5 dB信噪比條件下成像結果對比Fig.6 Comparison of imaging results using unsupervised training,γ=0.1 and SNR=5 dB
表2給出的實驗結果與圖5,圖6中的視覺結果基本一致,所提方法在非監督訓練情況下,利用個位數的網絡層數取得了優于現有主流迭代優化算法上千次迭代的成像結果。相比傳統稀疏優化算法的迭代尋優,網絡的后向傳播算法是從第一層到最后一層進行全局優化,相當于應用了迭代優化算法迭代前后的所有信息,因此SAR學習成像網絡的擬合能力更強,能夠利用較少的層數達到現有迭代優化算法上千次迭代的效果。成像速度方面,SAR學習成像網絡在訓練好網絡參數后,成像過程只需要一次前饋運算,且網絡層數較少,因此成像速度極快。對于實驗中的小場景SAR成像問題,成像速度在毫秒級,明顯快于迭代優化算法。
另外,試驗還仿真了低PRF情況下所提方法的成像結果。低PRF可以看作一種回波降采樣方式,但現有稀疏SAR成像方法在降采樣過程中需要遵循一定的規則以滿足重構條件。低PRF情況下獲取的觀測矩陣可能并不滿足條件,從而導致稀疏SAR成像方法重構質量下降。圖7給出了PRF小于方位向多普勒帶寬時不同方法的成像結果對比。可以看出基于匹配濾波的RD算法和稀疏SAR成像算法均不同程度的出現了方位向模糊,產生了假目標,而所提方法仍然具有較好的成像質量。
為了對比不同樣本數據量對網絡訓練的影響,圖8給出了20 dB信噪比情況下,3種不同樣本數據量對應的訓練重構誤差結果。可以看出,在4.1節中構建的網絡結構能夠成功實現對樣本回波數據的擬合,網絡在訓練到50次左右時收斂,此后重構誤差將隨著訓練次數的增多而逐步增大,且訓練樣本越少增加的越快。通過3條不同樣本數據量的重構誤差曲線可以看出,當樣本數據量增大到一定程度后,網絡的重構誤差將趨于穩定,這也說明了所提的成像網絡能夠在一定程度上減小深度學習對樣本數據的需求。若想要進一步提升重構質量,則需要改變網絡結構或者代價函數的形式。
5.2 含軌跡誤差目標成像試驗
下面通過點目標仿真來驗證含平臺軌跡誤差時SAR學習成像網絡的成像能力。在SAR回波樣本數據中加入時變的、最大0.15 m的軌跡誤差,設定Ntrain=500,系統輸入信噪比為20 dB。圖9給出了不同算法的成像效果對比。可以看出,在含軌跡誤差的情況下,傳統迭代優化算法在方位向出現了較大程度的模糊和散焦。所提成像網絡的輸出圖像同樣出現了散焦和模糊,但實現了對主散射點位置和散射系數的重構,相比stOMP和l1/2范數ISTA算法重構精度更高。
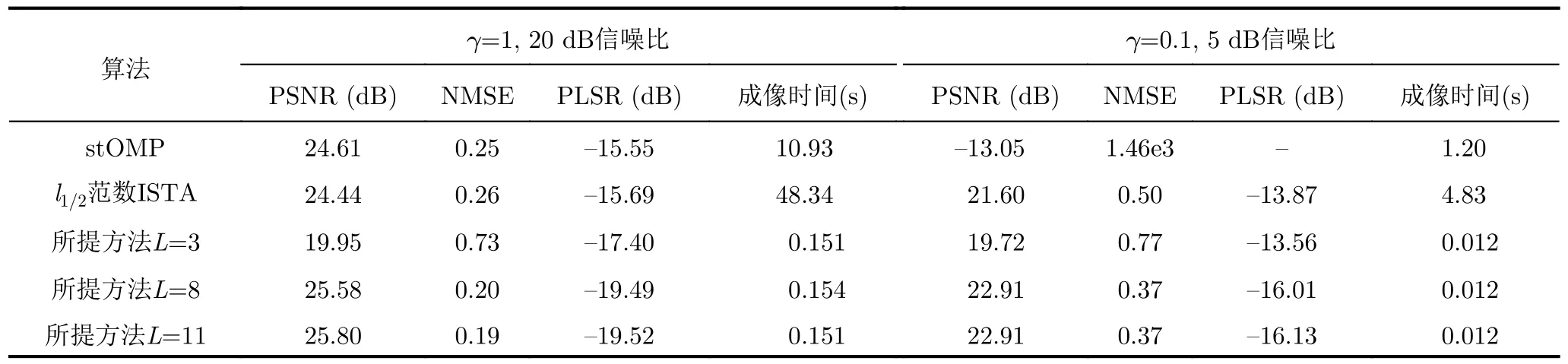
表2 成像質量與成像時間對比Tab.2 Comparison of imaging quality and imaging time

圖7 低PRF條件下成像結果對比Fig.7 Imaging results under low PRF condition
5.3 稀疏場景面目標成像試驗

圖8 不同樣本數據量對應的網絡訓練誤差Fig.8 Network training error corresponding to different number of training samples

圖9 含載機軌跡誤差條件下成像結果對比Fig.9 Imaging results with platform trajectory error
下面進一步利用包含感興趣目標的稀疏觀測場景進行成像實驗。觀測場景采用MSTAR數據集中的車輛目標進行仿真驗證。對于MSTAR數據,設定仿真回波數據的成像場景與雷達的位置關系與前述單點目標仿真實驗一致,回波數據的相位信息可以通過對復圖像數據做2D-DFT得到。為了測試所提SAR學習成像網絡的性能,在回波中增加高斯白噪聲使得輸入信噪比為10 dB。實驗采用固定參數的l1/2范數的ISTA算法作為對比算法,由于正則化參數λ需要手工設定,圖10(b)-圖10(d)分別給出了l1/2范數的ISTA算法在λ=0.5,10,100條件下的一幅2s1車輛目標成像結果。可以看出,對于傳統稀疏SAR成像方法,當存在噪聲時,成像質量有所下降,且手工設定參數將很大程度上決定最終的成像結果。對于所提方法,設定場景散射系數的初值,λ0=0.5,β0=0.5,初始網絡學習率η=10-6,并隨著mini-batch的更新逐漸減小。對回波添加高斯白噪聲構建訓練樣本數據,令Ntrain=500,圖10(e),圖10(f)給出了8層網絡和11層網絡的成像效果對比。可以看出,在10 dB輸入信噪比條件下,所提成像網絡得到的SAR圖像重構精度更高,且目標區域保留更好,背景也進一步得到抑制,其中網絡自主學習得到圖10(e)中的λ=37,圖10(f)中的λ=63。圖11給出了另外兩幅車輛目標的成像結果,利用所提成像網絡同樣得到了較好的成像結果。

圖10 MSTAR目標成像結果對比Fig.10 MSTAR target imaging results

圖11 MSTAR其它兩種目標成像結果對比Fig.11 Imaging results of two different targets in MSTAR dataset
6 結束語
現階段SAR在分辨率、幅寬等成像方面的提升并未從本質上解決SAR圖像解譯困難、重點目標識別率低的問題,而SAR成像與SAR解譯研究之間的相對獨立是導致這一問題的重要原因之一。若能實現SAR成像與SAR解譯之間的一體化處理,必將極大地提升SAR系統的整體數據處理能力和處理時效性。本文從SAR成像解譯一體化角度出發,嘗試利用“數據驅動+智能學習”的方法提升機載SAR對重點目標的參數獲取和屬性判別能力,分析表明,在現有條件下,直接利用海量數據學習得到“回波數據域”到“目標參數域”的映射關系還存在很大難度,但若能構造出成像網絡來實現“回波數據域”到“目標圖像域”的映射,再結合已有的SAR解譯網絡,將有望實現SAR成像解譯一體化。因此,本文提出了一種“數據驅動+智能學習”的SAR學習成像方法,給出了學習成像框架、網絡參數選取方法、網絡訓練方法和初步的仿真結果。然而,本文所提出的方法和開展的實驗僅僅考慮了非常簡單的成像場景,還存在大量關鍵技術需要予以研究。
(1)SAR觀測模型問題:本文提出的SAR學習成像框架基于SAR 1維觀測模型,SAR 1維觀測模型的優勢是符合現有線性求逆模型的矩陣-向量相乘形式,因此可以利用現有迭代優化算法推算得到網絡的權重項和偏置項,從而直接設計單層網絡結構,并利用現有反向傳播算法對成像網絡進行訓練。但1維觀測模型的向量化處理導致觀測矩陣的維度急劇變大,當SAR成像幅寬大、分辨率高時將極大的占用計算機內存資源。因此,有必要構建基于SAR 2維觀測模型的SAR學習成像方法,直接利用網絡找尋從距離向-方位向耦合的回波矩陣到2維SAR圖像的映射關系。針對這一問題,還需要進一步研究具體的學習成像網絡結構、對應的權重項和偏置項表達式以及最重要的反向傳播算法的設計問題。
(2)網絡結構問題:為了方便進行誤差反向傳播和參數調優,所提方法采用典型神經網絡的“權重+偏置”形式,并采用多層結構相同的單層網絡進行堆疊實現。這種網絡結構的優勢是可學習參數較少,網絡的訓練和參數調整較為簡單,但缺點是非線性擬合能力有限。因此,如何設計非線性擬合能力更強的單層學習成像網絡結構,并約束可學習參數的數量和變化范圍,是待解決的關鍵問題之一。
(3)網絡訓練問題:在網絡訓練方面,非監督訓練和監督訓練都有各自的優勢,當SAR回波數據完好,噪聲較小時,非監督訓練可以達到較好的效果。但點目標仿真數據與實測SAR數據還存在一定偏差,真實條件下SAR回波數據量非常龐大,網絡訓練面臨占用內存高、速度慢以及梯度消失問題。雖然可以對回波進行降采樣從而減小數據量,但降采樣率過高同樣會影響成像質量,能否在數據降采樣和重構精度之間找到平衡,如何加快非監督訓練的速度都是值得研究的課題。在監督訓練方面,由于點目標無法反映成像場景的幾何特性、分布特性等先驗信息,因此仿真實驗中并未給出監督訓練的試驗結果。如何選取和設計監督訓練中可添加的目標先驗特征,有哪些先驗特征能夠更好地約束SAR學習成像網絡,這些問題都值得進一步研究。
(4)動目標成像問題:與靜止場景成像不同,動目標成像中的目標運動軌跡、運動參數未知。因此在成像過程中必須對目標速度進行有效估計,由于目標運動導致觀測矩陣中參數發生很大變化,因此依靠本文提出的網絡結構對觀測矩陣進行學習優化存在欠擬合的問題,無法實現動目標精確成像。因此還需要專門設計針對動目標成像的SAR學習成像網絡。一種可行的解決方案是在成像觀測矩陣中增加基于目標運動速度的可學習參數,通過設計網絡訓練算法,在反向傳播過程中不斷優化該參數,實現對目標真實速度的逼近。
(5)成像網絡與解譯網絡的級聯問題:為了實現基于“數據驅動+智能學習”的SAR成像解譯一體化,需要將成像網絡和解譯網絡級聯到一起。在級聯過程中,一種較為簡單的方法就是直接將訓練好的成像網絡和訓練好的解譯網絡串聯起來,成像網絡輸出SAR圖像,然后裁切為尺寸較小的切片作為解譯網絡的輸入,最終由解譯網絡輸出目標參數。除此之外,還可以進一步考慮解譯網絡對輸入SAR圖像的預處理要求以及對目標的特征提取需求。例如感興趣目標往往包含直線、圓、矩形等人造結構,這些人造結構特征是解譯網絡需要重點提取的區別目標與背景的重要特征。如果已知這些特征提取需求,就可以指導成像網絡得到包含特定目標特征的SAR圖像,從而突出目標,弱化背景,進一步提升后續解譯網絡的目標分類性能。
猜你喜歡
中老年保健(2021年9期)2021-08-24 03:52:04
河北畫報(2021年2期)2021-05-25 02:07:46
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:33:04
兒童繪本(2020年5期)2020-04-07 17:46:30
兒童故事畫報(2019年5期)2019-05-26 14:26:14
Coco薇(2016年2期)2016-03-22 02:42:52
山東青年(2016年1期)2016-02-28 14:25:23
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
