基于太赫茲時域光譜的芝麻油品種識別研究
2020-04-01 10:44:56,2,*,2,2,2
食品工業科技 2020年4期
關鍵詞:分類
,2,*,2,2,2
(1.河南工業大學信息科學與工程學院,河南鄭州 450001;2.河南工業大學糧食信息處理與控制教育部重點實驗室,河南鄭州 450001)
芝麻油是通過加工芝麻得到的一種食用油,可以加入菜肴中進行調味,也可進行烹飪、煎炸,香味濃郁,并且含有豐富的微量元素以及人體所需的脂肪酸和氨基酸等,日益受到人們的廣泛關注[1-2]。由于芝麻油的良好市場價值,個別制造商為了從中牟取利益,將其它成本低的植物油摻雜到芝麻油中,有的甚至將使用剩下的油渣中提取出來的油(如地溝油等)和芝麻油進行勾兌,這不僅損害了消費者的利益,還有可能會對消費者造成一定的身體傷害[3-4]。
傳統的識別芝麻油的方法主要有電導法和色譜法,其中色譜法可以分為氣相色譜法、液相色譜法和薄層色譜法等[5],傳統方法有很多局限性,如樣品需要預處理、耗時長、操作復雜、損害樣品等。近年來光譜法成為一種新興的識別食用油的方法,光譜法可以不破壞樣品從而實現無損檢測,主要有近紅外光譜法、拉曼光譜法和熒光光譜法等[6]。馮蘇敏等[7]使用熒光光譜法結合化學計量法鑒別食用油和煎炸油,張嚴等[8]采用近紅外光譜法對花生油、芝麻油等五種油進行了定性分析,結果顯示可以很好的鑒別出不同的食用油。但由于光譜信號重疊或光譜中包含有用信息較少,這些方法有一定的局限性。
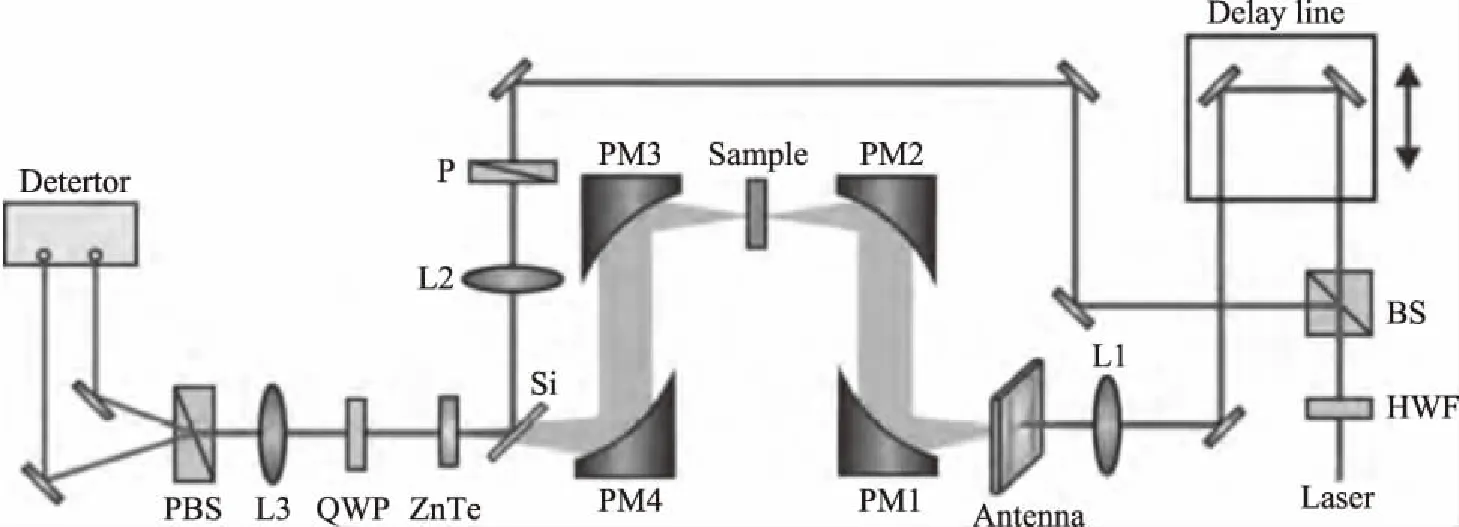
圖1 太赫茲系統結構圖Fig.1 Structure diagram of Terahertz system
太赫茲波是一種介于微波和紅外之間的電磁波,頻率范圍在0.3~10 THz,太赫茲輻射具有良好的透視性、安全性和光譜分辨率[9-10]。已經在安全檢查、對化學和生物制劑的檢測、環境控制、醫療診斷等領域得到了廣泛的應用[11-12]。目前在農產品和食品安全領域的應用也在不斷增多,如農產品和食品含水量檢測、食品內部品質檢測和種子識別等[13]。廉飛宇等[14]采用THz-TDS對4種食用油進行鑒別,結合化學計量法對太赫茲光譜進行分析,實驗結果表明太赫茲技術可以很好的應用在食用油鑒別上。李杰[15]將太赫茲技術應用于成品油的混油識別,不同混油比例的油品折射率譜和吸收系數譜有所差異。殷明[16]采用寬頻太赫茲時域光譜儀結合化學計量法對食用油進行定量和定性分析,實驗結果顯示模型分類準確率可以達到100%。余俊杰[17]利用太赫茲時域光譜技術對摻假橄欖油進行定性和定量分析,最終模型預測精度高,能夠快速檢測橄欖油的品質。太赫茲光譜技術在油類鑒別上已經有了很好的應用,因此本文選用該方法進行芝麻油的鑒別研究。
本文采用太赫茲時域光譜技術結合主成分分析和支持向量機來區分不同品種的芝麻油,分析了芝麻油在太赫茲時域光譜技術的作用下的特性,建立了一種快速鑒別芝麻油品種的定性分析模型,對比了不同核函數模型下的鑒別的準確性,為不同品種芝麻油的鑒別提供了一種快速準確的方法。
1 材料與方法
1.1 材料與儀器
本次實驗的樣品選自市面上四種不同品種芝麻油,均購于京東網上商城,其具體參數如表1所示。
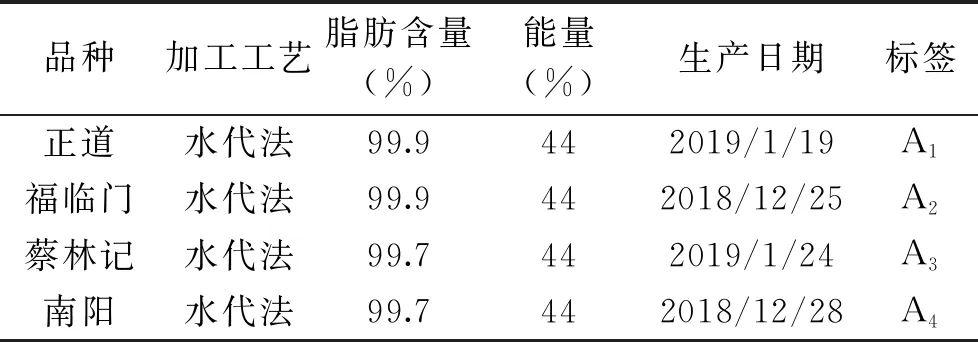
表1 樣品信息Table 1 Sample information
本實驗采用的是大恒光電的CIP-TDS時域光譜儀,系統基本光路結構如圖1所示。飛秒激光被分為兩束,一束為泵浦光,一束為探測光,泵浦光用來激發發射器產生太赫茲波,探測光則用來激發探測器來檢測太赫茲光。泵浦脈沖和探測脈沖出自于同一束激光,所以存在一定的時間關系,其中延遲線用來調節泵浦脈沖和探測脈沖之間的相對時間關系,具體實驗原理可見參考文獻[18-19]。為了防止空氣中水分含量對實驗結果的影響,測試時需要充氮氣,將儀器內部濕度保持在5%以內。
1.2 實驗方法
測量時使用光程為1 mm的標準比色皿,容量為0.35 mL,每種品種制備20組樣品。太赫茲儀器以鈦寶石飛秒激光器作為發射激光的光源,光譜范圍為0.1~3.5 THz,掃描范圍大于500 ps,掃描方式為透射式掃描。
隨機選擇樣品使用THz-TDS系統采集時域光譜,移動樣品改變測量點,重復操作三次,每個樣品得到三組光譜信息,取三次測量的平均值得到最終的樣品光譜,記為信號波形。掃描樣品之前測量不裝樣品的空比色皿的光譜作為參考信號,稱為參考波形。
對樣品信號和參考信號進行快速傅里葉變換,得到樣品的頻譜As(ω)exp[-iφs(ω)]和參考信號的頻譜Ar(ω)exp[-iφ,(ω)]。本次實驗使用的光譜儀采用的是透射式的掃描方式,樣品的吸收系數和折射率可以通過與參考光譜的比較中得出來:
式(1)
式(2)
式中:α為吸收系數;n為折射率;d為樣品厚度;c為真空中的光速。利用上述公式可以計算出樣品的吸收系數和折射率[9,20]。
1.3 模型與方法
1.3.1 主成分分析 主成分分析法(PCA)是一種常用的降維方法,可以在信息損耗很低的情況下減少數據集的維數,使用較少的數據保留最大的原始數據的特性[21]。它的目標是通過線性投影將高維數據映射到低維空間中,在高維數據中找到方差最大的方向,將數據映射到比原始數據維數低的空間中去[22]。
PCA的實現步驟包括以下幾點:
假設數據為m條n維。
a.原始數據組成矩陣X={X1,…,Xm},Xi={xi1,…,xin}∈Rn,i=1,…,m將樣本去中心化,為了方便表示仍用X表示去中心化后的矩陣。
b.計算協方差矩陣。
c.計算協方差矩陣的特征值和特征向量。
構造特征方程:
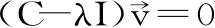
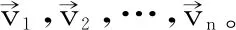
d.將特征值降序排序得:
λa>λb>…>λr
e.選擇k個最大的特征值對應的特征向量構建到新空間中。
1.3.2 支持向量機 支持向量機(SVM)是一種分類器,適合小樣本的分類,它的工作原理是找到一個超平面,這個超平面可以將數據集分隔出來,使不同類別的數據到超平面的距離最短[23]。因為支持向量機是一種典型的二分類器,而實際應用過程中遇到的問題一般都是多分類問題,因此需要使用間接的方法將支持向量機拓展應用到多分類問題上。主要的方法有一對一法,一對多法和分層支持向量機的方法[24-25]。
一對一(one versus one)主要的思想是分別在兩個不同的類別之間和建立一個分類器,n個樣本需要建立n(n-1)/2個分類器。一對多(one versus rest)主要的思想是將一個類別作為一個類,其余的類別作為另一個類,n個樣本需要n個分類器。分層支持向量機主要的思想是將所有的數據分為兩個類,然后分別對這兩個類進行二分類,直到子類中只剩下一個類為止[26-27]。
當數據集線性不可分時,需要引用核函數來進行分類。常用的核函數有線性核函數(linear)、徑向基核函數(rbf)、多項式核函數和(poly)雙曲正切核函數(sigmod),實驗時需要調節懲罰系數C和核函數系數(線性核函數只需調節懲罰系數C),使分類正確率達到最大。
1.3.3 PCA-SVM 原始數據集的維數如果很大,直接使用SVM進行分類處理的速度會比較慢,因此可以采用PCA和SVM聯用的方法,即先采用PCA進行降維,選擇前幾個基本可以代替原始數據集的主成分,使用這幾個主成分作為SVM的輸入,然后進行分類[28]。本次實驗中原始太赫茲數據的維數為580,所以選擇PCA-SVM聯用,即采用PCA將原始數據的維度降到4維,再使用前四個主成分作為SVM的輸入。
1.4 數據處理
將所有樣品使用太赫茲儀器進行檢測之后得到樣品的時域數據,選取0~2.5 THz范圍內的數據作為本次實驗的原始數據,使用Origin軟件處理原始數據,將光譜數據導入到Origin中,畫出時域圖,然后進行傅里葉變換得到頻譜圖,輸入吸收系數和折射率的公式進行計算得到相應的吸收系數和折射率;對光譜數據進行預處理,并對處理結果進行比較,選取最優的預處理方法;使用Spyder軟件進行建模分析,將Origin中處理得到的數據輸入到PCA-SVM模型中,使用網格搜索算法尋取最優參數,得到最終的最優模型。
2 結果與分析
2.1 頻譜分析
2.1.1 時域和頻域 通過太赫茲時域光譜系統獲得樣品的THz時域波形如下圖2所示。參考信號與樣品信號波形間有一定的時間延遲容易區分,但樣品信號之間的差異不明顯,樣品的太赫茲時域光譜可以反映不同的脂肪酸分子對太赫茲輻射的響應。芝麻油中一般含有6種主要的脂肪酸,包括棕擱酸、硬脂酸、油酸、亞油酸、二十碳烷酸、亞麻酸。不同品種的芝麻油中含有的6中脂肪酸的組成比例沒有太大的差別,但是含量會有差異,如正道脂肪酸的含量為99.9%,蔡林記脂肪酸含量為99.7%,福臨門的脂肪酸含量雖然與正道的含量相同,南陽脂肪酸含量與蔡林記相同,但是由于原料的來源不同,會有細微的差別,所以需要借助儀器來進行區分。
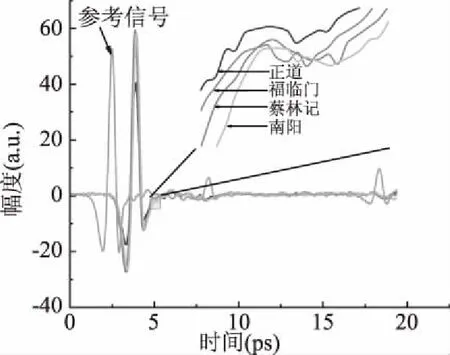
圖2 四種芝麻油的時域波形Fig.2 Time domain waveform of four kinds of sesame oil
直接觀測波形不能直接看出不同品種的差別,局部放大后可以觀測到在部分區間不同品種的波形相互分離,可以直接區分出來。
對時域數據進行傅里葉變換后得到樣品的頻譜圖如下圖3所示,因為后面波段受到的干擾較大,所以選取0~2.5 THz范圍內的波形進行觀測。正道黑芝麻油的頻譜與其它三種品種芝麻油的頻譜有明顯的區分,蔡林記芝麻油、福臨門芝麻油和南陽芝麻油三條頻譜圖混疊在一起不能明顯的區分。
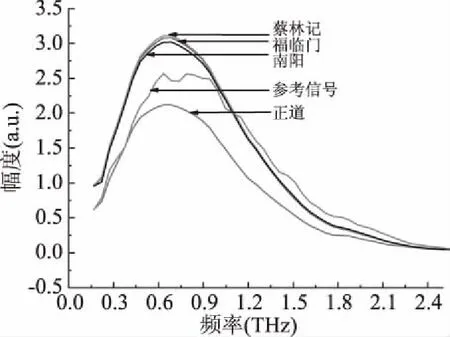
圖3 四種芝麻油的頻域波形Fig.3 Frequency domain waveform of four kinds of sesame oil
2.1.2 折射率和吸收系數 因為太赫茲時域數據中包含振幅和相位的信息,太赫茲時域光譜可以直接的計算樣品的吸收系數和折射率,不需要使用Kamers-Kroning關系進行變換得到。所以直接使用公式(1)和公式(2)進行計算得到折射率和吸收系數如下圖4和圖5所示。折射率譜在0~2.5 THz幾乎完全重疊,在2.5 THz之后開始波動分離(圖4)。吸收光譜正道與其它品種相分離,其它三個品種吸收光譜相近(圖5)。折射率與吸收系數相比,吸收系數的區分度相對較大,因此選用吸收系數作為后面分類的數據源。

圖4 四種芝麻油的折射率波形Fig.4 Refractive index waveforms for four types of sesame oil

圖5 四種芝麻油的吸收系數波形Fig.5 Absorption coefficient waveform of four sesame oils
2.1.3 數據預處理 吸收系數譜中正道可以明顯區分,其它三種接近重疊,因此為了更好的區分不同品種的芝麻油需要對數據進行預處理。本次實驗采用了微分、積分和歸一化三種方法分別對數據進行預處理,處理后的結果如圖6~圖8所示,由圖可知采用微分和積分處理后的數據依舊不容易區分,采用歸一化處理后的數據可以比較明顯的區分出不同品種的芝麻油,所以選擇歸一化處理作為最終的預處理方法,然后對預處理后的數據繼續采用機器學習的算法進一步分類。

圖6 吸收系數微分預處理Fig.6 Differential preprocessing of absorption coefficient
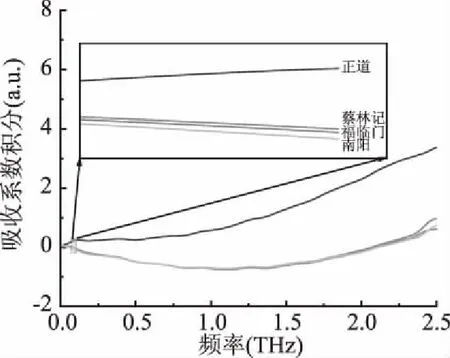
圖7 吸收系數積分預處理Fig.7 Integral preprocessing of absorption coefficient
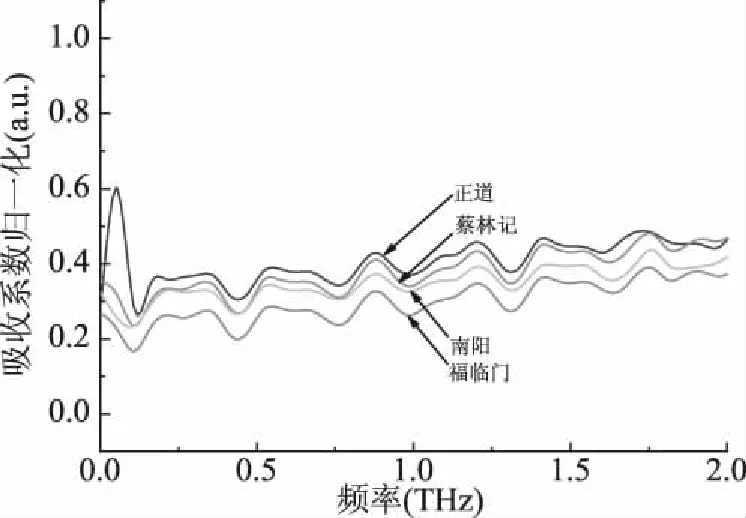
圖8 吸收系數歸一化預處理Fig.8 Normalization preprocessing of absorption coefficient
2.2 PCA分析
本次實驗原始數據為580維,直接使用SVM分類效率會比較低,所以先采用PCA降維,最終保留前4個主成分,使用前4個主成分代替原始數據集,作為SVM分類模型的輸入。保留的前4個成分對原始數據的貢獻率為99.506%,表1為各成分解釋總方差。為了直觀的觀測聚類效果,選取前兩個主成分畫出得分圖,前兩個主成分累計貢獻率為98.944%,圖9為前兩個主成分的得分圖,從圖中可以看出來四種不同品種的芝麻油有比較好的聚類作用,基本可以區分出不同品種的芝麻油。為了更加精確快速的區分,繼續采用SVM進行分類。
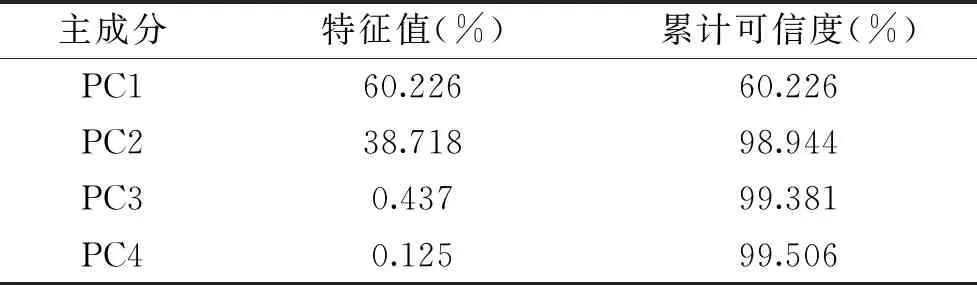
表2 各成分解釋總方差Table 2 Each component explains the total variance
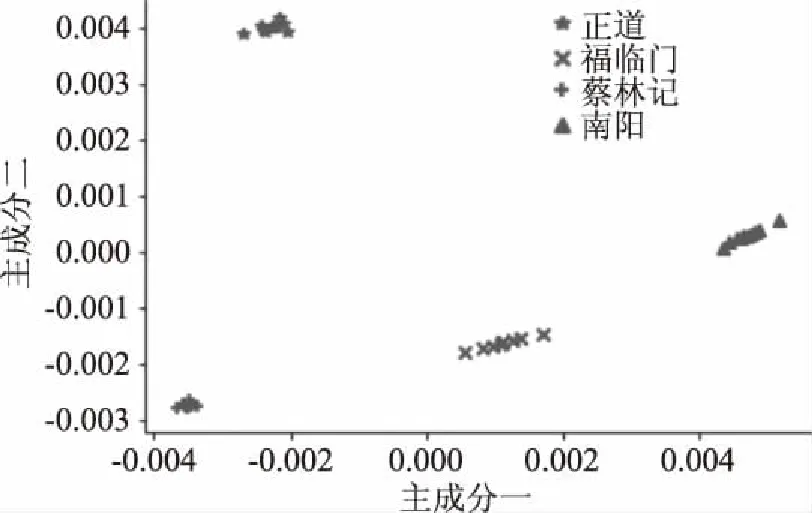
圖9 前兩個主成分得分圖Fig.9 Score charts of the first two principal components
2.3 模型分析
采用PCA-SVM聯用模型對樣品進行分類,先對原始數據集進行劃分,劃分數據集使用Python中的train_test_split()函數,其中參數stratify可以保證按照不同種類樣品的比例分配,訓練集和測試集的比例為7∶3。為了得到更好的分類效果,實驗采用網格搜索算法得出分類準確率最高的參數組合。主要對核函數(kernel)、懲罰函數(C)、核函數系數(γ)進行搜索。不同核函數的分類準確率如表3,線性核函數的總分類正確率為87.3%,分類準確率在三類核函數中最低,多項式核函數總分類正確率為91.5%,比線性核函數高,徑向基核函數分類正確率最高,最高可以達到100%,即可以將全部樣品分類正確,說明在本次實驗中徑向基核函數是最佳的分類核函數,最佳分類效果的參數為懲罰函數C為0.01,核函數系數為0.1。
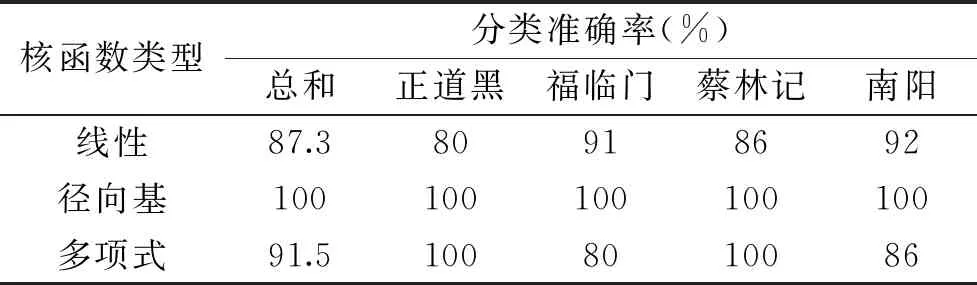
表3 不同核函數的分類準確率Table 3 Classification accuracy of different kernel functions
為了證明本文模型的性能,將本文的模型PCA-SVM與常見的分類模型隨機森林(RF)、K近鄰法(KNN)和邏輯回歸(LR)進行對比,這三種算法是常見的機器學習分類算法。如表4所示,使用PCA對數據進行預處理后,再進行使用SVM進行分類效果要優于其它三種模型。對于PCA-SVM模型不同的核函數的分類效果會有一定的差異,由表3可知選擇徑向基作為核函數,且選取參數懲罰函數C為0.01,核函數系數為0.1得到的模型分類效果最佳。總的來說,PCA-SVM模型識別性能最佳。

表4 不同模型的分類準確率Table 4 Classification accuracy of different models
3 結論
采用THz-TDS技術檢測了四種芝麻油在0~2.5 THz波段的時域和頻域譜,并計算得到折射率和吸收系數譜。實驗結果表明太赫茲時域譜結合化學計量法在不同品種芝麻油的分類上有很好的效果。不同品種的芝麻油含有不同類型的脂肪酸分子混合物,因此使用太赫茲技術進行檢測時,不同脂肪酸分子的響應反應在光譜圖上,雖然直接觀測不明顯,但是結合化學計量法,分類準確率在87%~100%。實驗同時表明太赫茲時域光譜技術在食品安全識別方面具有廣闊的應用前景。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
