基于增量學習的RocksDB鍵值系統主動緩存機制
2020-04-09 14:48:18駱克云葉保留盧文達
計算機應用 2020年2期
駱克云,葉保留*,唐 斌,梅 峰,盧文達
(1.計算機軟件新技術國家重點實驗室(南京大學),江蘇南京210023;2.國網浙江省電力有限公司,浙江杭州310007)
0 引言
隨著數據存儲量的急劇增長,在跨區域的數據中心對海量數據的組織管理越來越困難。而隨著分布式存儲技術的日益完善,其設計思想不斷啟發著傳統關系型數據庫,出現了諸多以RocksDB[1]作為存儲引擎的新型數據庫系統。RocksDB是一種基于日志結構合并樹(Log-Structured Merge Tree)[1]的鍵值對存儲系統,它具有將隨機I/O轉化為順序I/O的優點,可以大幅度提升數據寫入時的性能,是當前絕大部分結構化大數據存儲產品的首選存儲引擎。
然而,RocksDB 系統設計的場景是面向磁盤介質的批量寫優化,通過分層結構實現批量操作,在查詢數據時,讀操作可能會在日志結構合并樹的多個層級中發生I/O,導致不可避免的性能低下問題[2]。因此,如何高效地降低磁盤I/O 訪問次數,成為優化讀性能研究中的一個關鍵問題。為了提升RocksDB 中的查詢效率,現有的系統設計大多從過濾器的角度出發,通過計算的方式減少不必要的I/O 訪問次數,如采用布隆過濾器(Bloom Filter)技術過濾那些數據一定不存在于磁盤上的請求[3],實現讀取性能的提升。除此之外,現代計算機體系結構中的緩存機制也在讀取性能優化中發揮著重要作用,通過盡可能地在內存或閃存中訪問數據,減少磁盤尋道的時間,獲得更好的查詢性能。RocksDB 中的緩存機制主要有內部精心設計的塊緩存和操作系統的通用頁緩存,適當提升緩存大小能極大地提升整體的讀取性能。
從上面兩種優化機制來看,提升過濾器和緩存效率的核心在于使用概率計算或高速設備的方式避免磁盤I/O訪問,過濾器的位數越大,緩存的空間越多,效果越好。但這兩方面的優化均需要大量的內存空間,通常內存價格比磁盤昂貴,所以并不能無限制地通過上述機制來提升查詢效率。因此,RocksDB 雖然具有顯著的寫優勢,但這些存在的問題也制約了其進一步應用。為了實現寫操作、空間占用和讀取性能之間開銷權衡,現有的工作集中于如何在特定的場景中達到最佳的配置。在理論指導部分,Dayan 等[4]提出的Monkey 系統對查詢、更新和內存占用三者中的最優平衡點進行建模,對每一層的布隆過濾器根據數據的規模差異分配不同的存儲空間,達到最小化所有層的布隆過濾器誤報率,同時顯著降低內存占用的效果。對于空間和性能的折中,Dayan 等[5]的Dostoevsky 系統進一步探索了不同的合并策略對不同操作的I/O 和空間占用的影響,并使用了一種惰性合并的方法同時為不同層的布隆過濾器配置不同大小的內存,從而在不顯著增加內存占用的情況下提升整體性能。
上述解決方案都是從結構設計的角度來解決RocksDB 中的性能問題,此外也有一些工作從數據分布和訪問模式的角度來解決這個問題。例如在Hadoop 分布式文件系統(Hadoop Distributed File System,HDFS)[6]中,為了容錯,通常使用多個副本,但多個副本會增加系統的存儲開銷,在增加并行度的同時也增加了空間占用,在熱點讀寫的場景中,很多文件并沒有發生I/O,因此無法體現多副本的優勢。針對這種默認配置不靈活的問題,Bui 等[7]提出了根據HDFS 數據塊的訪問頻率動態設置副本數加以解決。具體操作是使用高斯過程回歸及其優化技術對文件訪問塊的可能性進行預測:對于熱點塊使用多個副本,通過數據并行加快處理速度;對于冷數據塊則只用一個副本,減少空間占用,提升Hadoop 系統的整體數據處理性能。
在數據庫系統中,數據分布和訪問模式對數據庫性能的影響極大,例如在RocksDB鍵值系統中,順序讀的性能通常比隨機讀要高出一倍,因此對特定工作負載進行針對性優化可以獲得可觀的性能收益。然而,在RocksDB 中進行熱點數據主動緩存會面臨兩個挑戰:一是系統在實際運行時,數據分布會持續動態變化,導致熱點數據難以準確建模;二是如何將主動緩存機制與RocksDB 存儲結構對接起來,在盡可能不增添內存占用的情況下實現性能的提升[8-9]。
針對上述挑戰,本文以擬合熱點數據分布為思路,設計并實現了利用增量學習進行預測分析的熱點數據主動緩存機制。具體而言,本文設計了由數據采集、系統交互、系統測試等部分組成的基于熱點數據預測分析的主動緩存框架,用于與RocksDB 存儲引擎進行交互,使得熱點數據大部分存在于日志結構合并樹靠近內存等高速設備的層級中;并對數據訪問模式進行建模,設計并實現了基于增量學習的熱點數據預測分析方法,能夠有效減少存儲介質的I/O訪問次數。實驗結果表明該機制能有效提升不同動態工作負載下的數據讀取性能。
1 RocksDB鍵值系統
1.1 RocksDB基本原理
RocksDB 是日志結構合并樹的一個經典實現,由Facebook 在參考谷歌的LevelDB[10]和Apache 的HBase[11]基礎上開發而來,復用LevelDB 的大部分代碼,在此基礎上進行工業級的代碼優化和功能增強,在實際生產中已經應用在了數據庫系統、分布式文件系統以及區塊鏈系統中[9]。
日志結構合并樹是一種按照邏輯分層的有序存儲結構,保存在內存中的部件稱為Memtable(C0),其數目和大小可以分別通過max_write_buffer_number(默認為2)、write_buffer_size(默認為64 MB)設置,數據先寫入Memtable 中,當大小達到上限后變為只讀的Immutable Memtable,并使用新的Memtable繼續寫入,當總的Memtable 數目達到上限時則觸發刷盤操作,將Immutable Memtable 數據直接寫入磁盤;保存在磁盤上的部件稱為SSTable,其中SSTable 在邏輯上又分為L0(C1)層、L1(C2)層等。通常下一層的數據量是上一層的k(默認為10)倍,整體呈現出一個金字塔結構。具體結構示意圖如圖1所示。

圖1 日志結構合并樹示意圖Fig.1 Schematic diagram of log-structured merge tree
日志結構合并樹在維護有序結構的過程中主要涉及到刷盤(Flush)和合并(Compaction)兩大操作,其中刷盤操作在內存中的Memtable 個數超過設定的閾值時自動觸發,而當層級內的總數據量超過閾值時自動觸發合并操作。其原理如圖1所示,刷盤操作直接將Immutable Memtable 寫入到C1層(以L標記為L0層),形成多個SSTable文件。這些SSTable內部是有序的,但SSTable 之間存在一定的范圍重合。合并操作(Compaction)具體實施的方式與采用的合并策略有關,以默認的Level Style 合并策略為例,選擇C2和C3層中鍵有重疊的SStable 進行合并,生成新的SSTable 存放到C3層中,C1層以后的SSTable(L1,L2,…)每層的每個SSTable 鍵區間是不重疊的,這與C1層不同。
1.2 RocksDB數據讀取流程
RocksDB 中的讀取操作根據數據的版本差異分為當前讀和快照讀[12],默認為當前讀,整體的讀取步驟如下:
1)在事務對應的writebatch 中查找是否存在請求的數據。
2)在Memtable中基于跳躍表快速查找數據是否存在。
3)在L0層級中,依次遍歷每個SSTable,若SSTable 的索引和布隆過濾器數據未被加載到操作系統的頁內存中,則首先進行SSTable句柄的緩存,然后通過布隆過濾器確定鍵是否存在,若存在則檢查數據是否存在于Block Cache,若不存在發生一次I/O,并緩存至Block Cache。
4)若L0層中未查找到數據,則在L1、L2等層中接著查找。由于數據在這些層中是嚴格有序的,因此使用二分查找的技巧,根據鍵的范圍定位SSTable,然后進行步驟3)中的查找流程。
從上面的流程來看,RocksDB 讀取數據時會在多個層級中發生I/O,極端情況下的I/O 次數為N(L0)+N(L)-1,即與L0的文件數目、日志結構合并樹的層級數之和相關。這種分層結構意味著若要提升讀取性能,則必須通過一些機制避免訪問磁盤I/O。現有系統中的優化機制主要有布隆過濾器和緩存兩類,其中布隆過濾器方法可以快速判斷鍵是否一定不存在于SSTable 中,當訪問不存在于數據庫系統中的鍵時,能有效減少I/O 次數。布隆過濾器在打開SSTable文件時通常被載入到操作系統的堆內存中,除非通過配置BlockBasedTableOptions::cache_index_and_filter_blocks=true主動進行緩存,否則當關閉SSTable 文件時,系統根據max_open_files 參數所定義的文件句柄緩存數目決定是否對緩存數據進行垃圾回收。布隆過濾器的緩存位置有兩處:OS Cache[13](Page Cache,頁緩存,數據有壓縮)和Block Cache[14](塊緩存,數據無壓縮),這兩種緩存的詳情如下:
OS Cache:普通的堆內存,在Linux 系統中一般是Page Cache,對于每個文件的第一個讀請求,系統進行預讀,即會同步讀取請求的頁面及其后面的幾個文件,對于第二次讀取,如果所讀頁面不在Cache 中,則繼續同步讀取,否則請求命中,擴大此次預讀的范圍。最新進入的數據存儲在鏈表的頭部,當內存不夠時進行緩存的替換,從尾部掃描回收不活躍的內容。在RocksDB 中,處于OS Cache 的數據是壓縮過的,因此比Block Cache 節省空間,但代價是需要CPU 的參與進行數據的解壓。
Block Cache:它是RocksDB 緩存數據至內存中以提高讀取性能的一種方法,用戶通過創建指定存儲大小的Cache 對象供數據庫中同一個進程中的多個實例使用。Block Cache內部存儲的數據通常是非壓縮的數據塊,也可以存儲壓縮的數據塊。如果開啟Direct IO參數,則沒有OS Cache產生,此時數據以壓縮的形式存在。在系統實現中根據緩存的替換算法來分主要有LRU Cache 和Clock Cache 兩大類,這兩種實現為了方便鎖的控制都將Cache 分片,用戶設置的容量會平均分配至每個分片中,默認的Cache 分片數為64,每塊大小至少512 KB。Block Cache 中存儲的通常是數據塊,索引和布隆過濾器緩存在block cache的外部堆內存中。這是因為當數據很大時,索引和布隆過濾器會占用大量的空間,以10 bit 的布隆過濾器為例,其占用的空間大小是number_of_keys×10 bit,即對于一個256 MB 的SSTable 文件,索引和布隆過濾器分別需要額外占用0.5 MB 和5 MB 的空間,當數據規模較大時會占據Block Cache 的大部分乃至全部空間,由于排擠效應導致嚴重的數據命中率缺失問題。
具體體現到RocksDB 鍵值對存儲系統中,在cache_index_and_filter_blocks 設置為false 的條件下,當max_open_files 設置為-1時,默認會緩存所有數據至OS Cache中,這在一些內存空間有限的機器中特別容易造成內存不足(Out Of Memory,OOM)問題,解決的機制就是根據內存使用情況控制打開的文件數,及時清除緩存句柄,保持系統資源的合理占用。當cache_index_and_filter_blocks 設置為true 時,則布隆過濾器數據存儲在block cache中,為了避免性能下降,通常的解決方案是設置cache_index_and_filter_blocks_with_high_priority 的優先級,此時布隆過濾器和數據緩存分別位于block cache 的兩端,根據兩者實際占用內存數動態移動。另一個優化點就是設置pin_l0_filter_and_index_blocks_in_cache來固定第0 層的索引和布隆過濾器數據至block cache 中,在內存占用和布隆過濾器命中率之間取得一個較好的平衡。
由上面介紹可知,過濾器機制和緩存機制[15]是相輔相成的,過濾器數據在SSTale創建的時候生成,在調用時緩存在內存中,而熱點數據也需要緩存,因而內存空間是瓶頸。具體分析,過濾器機制可以直接減少I/O 次數,在RocksDB 中是必不可少的,因而優化的重點在于緩存機制。在查詢數據時,通過緩存機制,一方面可以減少磁盤I/O,提高讀取效率,在另一方面同時也增加了內存占用,這是一種典型的利用空間占用提升讀取性能的折中思想。如果合理地使用緩存機制,在盡量不增加空間占用的情況下,實現RocksDB讀取性能的提升,那么將具有優良的性價比。
2 熱點數據主動緩存問題描述與解決思路
2.1 問題描述
本文將熱點數據的主動緩存這一概念定義如下:在基于多個數據分布的查詢工作負載中,通過某種機制將熱點鍵值對主動緩存到內存或低層的SSTable中,同時求解一定時間內的熱點鍵值對,從而提高整個工作負載的讀取性能。
在不考慮數據分布的情況下,該問題解是一個典型的緩存控制問題。對于此問題,傳統啟發式算法的做法為先創建緩存空間,編寫最近訪問的鍵值對,在空間滿時使用消除算法,如最近最少使用(Least Recently Used,LRU)算法,替換一些已存儲數據。如果考慮數據分布背景,在概率密度分布為p的情況下,求解目標可以理解為對集合進行多次采樣操作,求下一個周期內訪問之前采樣得到的數據的概率。
本文利用概率分布信息獲取數據的訪問特性,預測這些數據被再次訪問的概率,然后篩選出概率較高的密鑰,并進行主動緩存。這其中主要有兩個難點:一是預測模型的選擇,二是活動緩存機制的建立。下面將簡要介紹這兩點:
首先,對于預測模型選擇問題,由于在通常情況下,數據訪問的概率遵循80/20 定律,即20%的數據占據了80%的訪問頻率[8],所以訪問的這些數據具有明顯的相關性特征。由此我們認為,熱點數據預測的主要難點是數據范圍會隨著數據的不斷插入和刪除而動態變化,與此同時數據形式也呈現出復雜多樣性。這種不確定性和不規則性意味著,在預測新數據時,很難直接使用預先訓練好的模型進行實時在線預測。
第二個難點是有關主動緩存機制建立的問題,即活動緩存如何適應鍵值對存儲結構。在鍵值對存儲場景中,查詢操作涉及到的數據量會非常大,如果使用特定的內存緩存結構(如Redis、Memcached),當空間設置得過小時,就會導致系統頻繁的更新,從而不可避免地帶來需要較大容量空間的問題,這樣做就失去了優化的意義。因此,我們迫切需要一種新的緩存機制,在不占用大量額外空間的情況下實現與鍵值對存儲系統的無縫對接。
2.2 解決思路
對于熱點預測問題,考慮到在短期內整個系統環境是相對穩定的,所以在一個穩定的時間段里,可使用參數模型近似擬合這種方法。隨著時間跨度增長,數據分布發生變化后,模型性能會不可避免地顯著下降,此時就需要執行在線更新模型的操作,因此整個過程可以被視為一個增量學習[16]的過程。
與傳統的批量學習技術相比,增量學習主要具有現有模型總結歷史數據隱藏規律的優點,這就帶來了無需顯式保存歷史數據、減少存儲空間的好處。此外由于新的訓練是基于歷史數據中的隱含信息,所以能顯著減少新數據的訓練時間。就現有的增量學習實現技術而言,基于參數的模型(包括感知器和邏輯回歸),通常可以很好地完成這一任務。該技術的核心是通過隨機梯度下降優化算法實現參數的增量更新。定義整個模型的輸入是一組特征,輸出為該鍵是熱點的概率,最后,根據輸出概率對模型進行排序,選擇概率較高的密鑰對進行主動緩存,同時定期驗證模型的準確性,當精度低于閾值時進行增量學習。
對于主動緩存,涉及到的機制有數據的重放操作(Splaying)和布隆過濾器等,一旦數據重放足夠準確,布隆過濾器的使用就能自然減少,內存的使用也會隨之減少,從而帶來性能的提升。下面將詳細介紹RocksDB 特有的重放操作機制[17]:
日志結構合并樹的一個特性是,頂部的數據總是比底部的數據更新,因此可以將頻繁訪問的數據“調度”到內存中,即重復寫入,確保熱點優先。在實踐中,有很多方法可以確定一個鍵是否應該重播。在文獻[17]中引入了兩種重放策略,稱之為AlwaysSplay和FlexSplay。
AlwaysSplay:這種策略的一個結果是,系統根本無法區分真實的頻繁數據和熱數據。如果鍵在很長一段時間內只有一次讀取,則根本不需要寫入,因此它不是最優的。這種方法帶來的另一個問題是,系統可以創建同一個鍵的多個副本,從而造成不必要的空間浪費,降低查詢性能。并且,當工作負載中的讀寫比發生更改時,這些熱點將不會帶來任何作用,造成更大的浪費。
FlexSplay:為了解決上述策略帶來的問題,本文引入了彈性回放策略。此策略與原始的AlwaysSplay 策略相同:put 操作都是在get操作之后觸發,但這些冗余的鍵值對被標記為重放過(通常將普通鍵分別標記為value、delete、merge、write、delete 和modify)。在每次數據刪除或合并期間,我們使用某種運行時策略來確定重新傳遞的數據是執行刪除操作還是執行保留操作。所以,現在的問題變成了如何設計一種策略,以確保保留或刪除副本的成本最小化、效益最大化和實現最簡化。當頻繁訪問密鑰集的比例超過閾值時,或者讀操作的比例降低時,逐步刪除重播數據,從而顯示出自適應性。但該方法會涉及存儲結構的修改,因此總體復雜度較高。
綜合考慮上面兩方面解決思路,本文提出的解決方案是:使用增量學習方法預測熱點鍵,對這些熱點鍵進行直接重放操作,同時依據熱點鍵的分布區間動態調整max_open_files 的大小,實現對內存占用量的精細控制等目標。
3 主動緩存框架設計
如圖2 所示,整個框架包括數據采集、系統交互和系統測試三大模塊,以客戶機-服務器的形式進行設計,同時還建立了熱點預測模型。
下面將分別介紹每個模塊的功能和設計情況。

圖2 基于預測分析的主動緩存框架Fig.2 Prediction and analysis based proactive caching framework
3.1 數據采集
在熱點預測場景中,如果所有的數據都是間隔讀取的,那么就會產生大量對模型沒有影響的冗余鍵,這將極大地增加系統的負擔。因此,在此模型中將直接忽略這些數據的讀取行為,改為主要考慮以下數據:
1)頻率統計:每個工作負載的主要記錄是讀操作下的鍵數。具體來說,每次執行get操作時,在訪問命中時,都會記錄操作的key和key的計數。具體數據格式為<key,count>。
2)分布統計:在每個工作負載啟動前記錄SSTable元數據信息,包括時間戳、層次結構、SSTable文件名、最小鍵、最大鍵等,數據格式為<timestamp,Level,SSTable,key_min,key_max>。
3)工作負載信息:記錄每個工作負載數據信息,包括工作負載標簽號、開始時間、結束時間、持續時間間隔、讀取次數、總間隔、每秒查詢、索引和布隆過濾器內存占用、Memtable內存占用和進程內存占用量等。
為了避免人為干擾,重放期間的讀和寫操作不被包括在統計數據中。
數據采集完畢后,將對數據特征進行進一步的構造。在這個步驟中,輸入數據被處理成模型可以讀取的形式。方法是將兩種頻率統計表和分布統計表的統計量進行匯總,并對其進行標記,構造正樣本和負樣本。以key 為主鍵,構造特征目前包括:時間窗內的累計訪問頻率、SSTable 的命中率、SSTable區間內key的訪問比例、key的層次結構等。系統將上述特性拼接到一行記錄中,并在一段時間后計算數據命中率;同時還會執行對標簽標注的工作,例如再次訪問的鍵被標記為1,否則被標記為0。
3.2 系統交互
該系統的通信體系結構為客戶機-服務器模式。RocksDB 數據庫實例充當客戶機,向模型服務器請求模型服務。這兩個角色所提供的功能分別為:
1)RocksDB 數據庫實例:讀寫數據,向服務器發送任務請求,獲取服務器端狀態,獲取熱點鍵集合,通過max_open_files設置打開的SSTable文件數。
2)模型服務:提供模型服務,包括加載/培訓模型、評估結果、熱鍵預測、提供max_open_files設置等。
該模型被設計為一個帶有Thread 類線程的類ModelServer。它作為守護線程在后臺運行,同時整個系統的設計風格是Restful 的。flask-Restful 輕量級框架用于封裝模型服務器的功能。其中涉及到的路由如表1所示。
RocksDB 數據庫實例與模型服務器的交互模式如圖3所示。

表1 主動緩存服務器端Rest路由Tab.1 Rest routing on server side with proactive caching

圖3 主動緩存系統時序圖Fig.3 Sequence diagram of proactive caching system
3.3 系統測試
該模塊負責模擬數據工作負載的生成和組成操作。由于生成的數據需要反映數據的分布特征,所以主要考慮在文件訪問模式下幾種典型的分布[18]:
1)正態分布:此分布由均值和標準差決定。概率密度曲線以均值為中線,形狀由標準差決定。標準差越小,曲線越接近均值。該系統計算給定數據區間的均值,并根據三標準差原理確定標準差。
2)均勻分布:該分布由最小值和最大值決定,概率密度是固定的。為了簡化系統測試,將直接選取具有特定后綴的數據進行采樣分析。
3)Zipf 分布:在Zipf 分布P(r)=C/rα中,將事件發生概率與其頻率排序優先級之間的關系視為反比,其中:C 為常數,r為根據發生頻率排序,α 為參數。在系統測試中,首先生成一個固定容量的累積概率數組,然后根據生成的隨機數遍歷數據,并取大于或等于隨機數的第一個數組下標采樣。
為了便于比較測試結果,需要將上述數據保存到一個文件中,以便工作負載讀取。對于復合工作負載,主要從上述三種分布中抽取重復樣本,形成復雜的工作流加以測試。
4 算法設計和實驗
4.1 算法實現流程
增量學習模型使用sklearn.linear_model.SGDClassifier[19]實現,利用joblib 庫[20]保存模型的二進制文件,這樣做的好處是打開數據庫時若模型存在則會自動導入,節省模型訓練時間。如果數據庫中不存在現有模型,則需要觸發模型訓練操作:數據庫端主動發送請求,啟動后臺訓練流程。訓練之后,數據庫客戶機可以通過輪詢獲得模型的輸出。
增量學習的一般過程可以理解為:流數據輸入→特征處理→partial_fit擬合→評價→應用。以下將重點介紹模型實現過程中的幾個細節:
1)評估:很明顯評估模型的學習效率是個二分類問題,所以為了直接篩選出熱點鍵,將使用F1值度量[21]的方式。F1標準會綜合考慮精確率與召回率兩方面因素。首先,定義TP代表預測結果為1,這也代表實際為1的數目;TN為預測為0,實際也為0 的數目;FP 為預測是1,實際是0 的數目;FN 為預測是0,實際是1的數目。涉及到的各種計算公式如下所示:
精確率:
Precision=TP/(TP+FP)
召回率:
Recall=TP/(TP+FN)
F1得分是精確率與召回率的幾何平均:
F1=2*TP*FN/(TP+FN)
2)應用:預測結果主要應用于兩個方面,一是篩選熱鍵,二是設置max_open_files 參數,兩者具體的處理方式如下:對于熱點鍵的篩選,先對預測概率進行排序,然后選取預測概率大于或等于0.5 的作為熱點鍵。隨后計算這些熱點鍵所覆蓋的SSTable 熱點數,選取SSTabel 覆蓋率大于100 的SSTable 熱點數作為SSTable 熱點數進行記錄。對于max_open_files 設置,會根據經驗值公式Max(min(SSTable number,2×SSTable hotspot number),SSTable number/2)來設 置,其中,SSTable number 指SSTable 文件數,SSTable hotspot number 指SSTable熱點文件數。除此之外,還可以通過控制max_open_files 來達到控制內存使用的目的。
整個算法系統的流程如圖4 所示,接下來將對圖中的部分操作細節進行簡要介紹:
1)訓練模型:獲取前一時間段各鍵的統計特征,得到當前命中的樣本X 和y_true,然后將數據放入模型partial_fit(X,y_true)中擬合。
2)模型預測:獲取當前各鍵統計特征X,調用函數predict(X)進行預測,得到預測結果y_pred。
3)模型評估:執行函數f1_score(y_true,y_pred),計算得到F1。
其中,是否重新訓練的標準為F1 的下降幅度,本文中將閾值設為10%,即如果F1 的下降幅度低于此閾值就開始使用新的數據訓練模型。
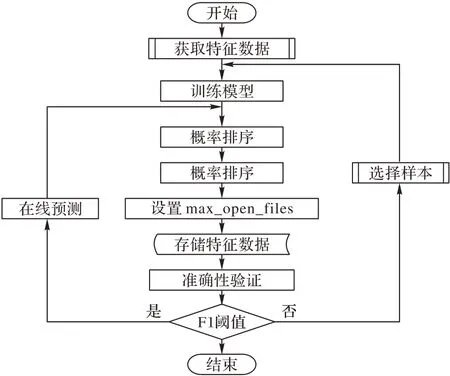
圖4 主動緩存模型訓練和預測流程Fig.4 Training and prediction process of proactive caching model
4.2 工作負載設計
本文的研究目標是面向讀操作的工作負載優化,這其中最重要的部分就是工作負載設計。
我們認為的設計目標具體有兩個:一個是模擬特定服務的讀取性能,在此之上研究數據的緩存行為;另一種是通過改變數據分布來測試算法在動態環境中的適應性。為了驗證本文設計是否符合這兩方面的要求,設計了以下兩階段工作負載:
1)數 據 準 備:啟 動RocksDB,通 過 調 用“rocksdb::NewLRUCache(4×1024*1024*1024LL)”配 置block cache 為4 GB。鍵是長度為8 的十六進制字符串,值是長度為20 的十六進制字符串。第一階段生成范圍為0x00000000~0x04ffffff的鍵值對,數量設為5 000 萬。第二階段生成范圍為0x00000000~0x04ffffff*2 的的鍵值對,數量也為5 000 萬,并且對于重復生成的鍵,使用第二階段生成的去覆蓋第一階段生成的,可將此覆蓋視為修改操作。在數據生成完畢后,還將構造符合以下條件的三個鍵集合用來執行查詢操作:
①數據分布a:鍵的區間在0x00000000~0x04ffffff,執行高斯采樣,采樣數量為500萬;
②數據分布b:鍵的區間在0x00000000~0x04ffffff,所有鍵均以4或8或f結尾;
③數 據 分 布c:構 造 近 似Zipf 分 布 模 型(1.005,1 000 000),其中rank 定義為(x+100)/100(減小數值過大的影響)。把區間0x00000000~0x04ffffff 劃分為n(n=10)份,在每份區間內選擇一個數作為基數,再按上述類Zipf分布采樣,采樣數量為100萬。
2)工作負載組合1:寫入第一階段的鍵值對,按順序依次以不同的數據分布a(10 次)→b(10 次)→c(4 組數據,每組5次)執行,其中,鍵的值以時間為隨機數種子隨機采樣80%。這種設計的目的是多次運行,模擬商業周期和數據分布的流動。
3)工作負載組合2:編寫第二階段的鍵值對,將數據分布的上限乘以2,其余的操作與工作負載組合1相同。這是為了在更大的數據集中進行模擬,并測試模型的遷移能力。
實驗總共測試80 個工作負載,前40 個數據范圍大致相同。在隨機插入或修改了一半數據之后,數據分布會發生顯著變化,實驗中將使用相同的工作負載繼續測試這種動態適應性。
重復使用10 次數據分布a 是為了測試對于高斯分布數據,隨機采樣其中的一部分,重復一定次數后,可以模擬輕度熱點讀取模式。相應地,重復使用10次數據分布b(鍵的區間在0x00000000~0x04ffffff的以4或8或f結尾的鍵)是為了驗證對于均勻分布的數據,如果順序采樣其中的一部分,一方面會破壞前面已有的分布模型,另一方面會導致模型需要進一步的訓練。最后,選取4組不同符合數據分布c的數據每組重復5 遍,是為了證明:這里每組的數據分布長尾特征明顯,每個讀取為重度熱點模式,但熱點會經常變化。
實驗記錄的數據主要有兩種類型:第一種是對系統狀態執行監測的數據,格式為<工作負載類型,開始時間和結束時間,運行時間和數量的查詢,每秒查詢數,索引和布隆過濾器,內存Memtable 內存,進程占用內存>;第二種是數據估算模型,格式為<時間,精確率,召回率,F1>。第一類數據記錄在本地和調度模型中,使用它們來分析系統性能;第二種數據則被用于分析模型性能,它只存在于調度模型實驗中。
4.3 實驗性能分析
首先分析該模型的預測性能,該部分的性能由驗證集上的測量標準F1(Precision,Recall)來測量。除了前兩個工作負載用作訓練集和標注標簽,其余工作負載皆用于訓練和預測。
接下來使用前三個工作負載作為示例進行解釋。首先模型以工作負荷0 和1 為訓練集,進行模型訓練。在0 和1 這兩個階段中預測的鍵值將會被用作熱鍵,與工作負載2 階段中實際訪問到的鍵值進行比較。其中,工作負載2 中最上方的折線代表前兩個工作負載中被訪問到的鍵在工作負載2 中再次出現的比例。將召回率定義為預測的熱鍵數和訪問的熱鍵數與所有訪問的鍵數之比,準確率定義為預測的熱鍵數和訪問的熱鍵數與總預測的熱鍵數之比。
如圖5 所示,這是其中一個組合的工作負載,可以看到精確率約為0.83,召回率約為0.62,F1 的值最大0.72。如果在此情況下突然運行負載組合b,因為b是均勻采樣數據,所以,查全率和查準率自然會急劇下降,從而超過閾值觸發訓練,最終F1 可以穩定在0.58 左右。隨后將運行工作負載組合c,此時每個數據包數據都是分離的,所以需要一些時間去改變工作狀態。如圖5 所示,模型在一段時間內相對穩定,這代表了模型處在學習訪問模式,并在工作負載發生顯著變化時進行重新訓練。第二階段的結果相似,這里不再重復。
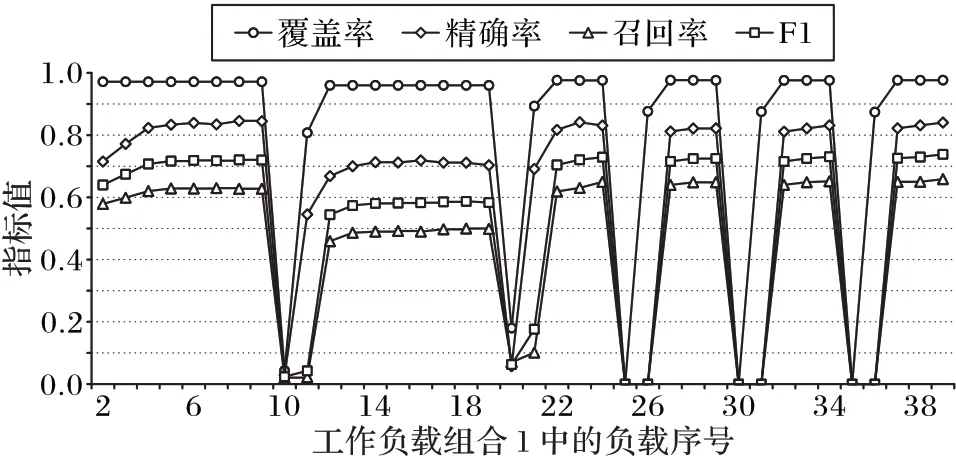
圖5 主動緩存模型性能折線圖Fig.5 Line chart of performance of proactive caching model
在系統內存性能方面,通過跟蹤進程占用的內存,可以發現原始數據庫在其峰值時會使用7.4 GB 內存,平均內存消耗則為6.6 GB,活動緩存模型在其峰值使用7.1 GB,不存在任何額外的內存使用。因此,模型本身帶來的開銷幾乎可以忽略不計,可以認為系統在內存效率上有一定程度的提高。
就系統讀取性能而言,查詢測試時的吞吐量如圖6 所示:橫軸表示運行的工作負載;左側縱軸表示每秒查詢的數量(QPS),單位為kop/s;右側縱軸表示模型QPS 相對于原始QPS改進的百分比。
從圖6 可以發現,除了工作負載切換階段吞吐量有所損失外,其余階段查詢吞吐量均提高,不同工作負載的組合帶來的提升效果不盡相同,組合a 查詢性能平均提高了約9.5%,組合b 查詢性能平均提高了約6.3%,組合c 查詢性能平均提高了約6.6%。總的來說,使用該模型能夠將總體性能提高了7.5%。因此,可以認為該模型具有一定的性能優勢。
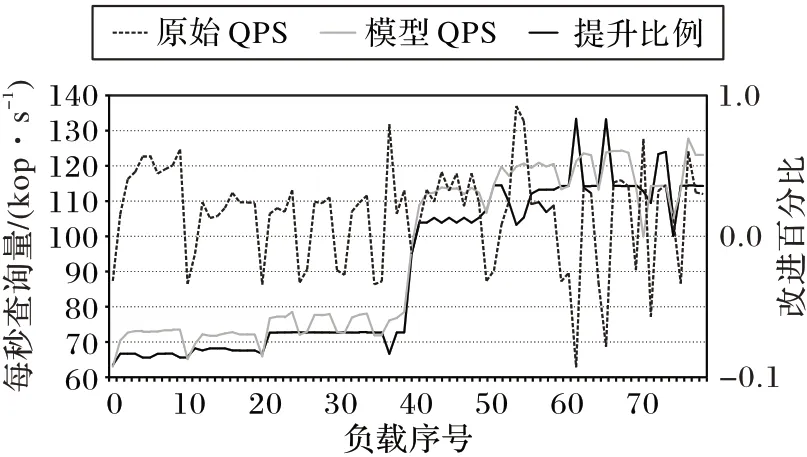
圖6 主動緩存模型每秒查詢數折線圖Fig.6 Line chart of number of queries per second of proactive caching model
5 結語
本文將機器學習技術應用于RocksDB 鍵值對存儲系統中熱點數據的主動緩存問題。整個系統不僅采用增量學習方法對熱點數據進行預測,還建立了基于預測分析的主動緩存框架。實驗結果表明,該方法能有效提高動態負載下的熱點閱讀性能。
以后,我們將針對熱點預測模型的復用問題作進一步的研究,即如何將訓練后的模型應用于其他不同鍵值分布的存儲數據庫問題。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
裝備制造技術(2019年12期)2019-12-25 03:06:46
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
家庭影院技術(2017年9期)2017-09-26 03:41:45
光學精密工程(2016年6期)2016-11-07 09:07:19
