基于隨機森林和遺傳算法的Ceph參數自動調優
2020-04-09 14:48:26毛鶯池
計算機應用 2020年2期
陳 禹,毛鶯池
(河海大學計算機與信息學院,南京211100)
0 引言
Ceph 是一個集可靠性、可擴展性、統一性的分布式存儲系統,提供對象(Object)、塊(Block)及文件系統(File System)三種訪問接口,它們都通過底層的LIBRADOS 庫與后端的對象存儲單元(Object Storage Device,OSD)交互,實現數據的存儲功能[1]。Ceph 內部包含眾多模塊,模塊之間通過隊列交換消息,相互協作共同完成IO 的處理,典型模塊有:網絡模塊(Messenger)、數 據 處 理 模 塊(FileStore)、日 志 處 理 模 塊(FileJournal)等[2]。面對眾多的模塊,Ceph提供了豐富的參數配置選項,然而由于Ceph 集群的負載情況每時每刻都在變化,加上Ceph 作業的類型繁多,不同用戶不同作業的需求也千差萬別,默認的配置參數往往不能保證集群資源的充分利用和系統的高吞吐率,因此需要調整參數配置從而提高系統在吞吐量、能耗、運行時間等方面的性能[3]。
找到最佳Ceph 參數配置的簡單方法是嘗試配置參數值的每個組合并選擇最佳配置參數值,然而在沒有深入了解Ceph 內部系統和給定應用程序的情況下手動調整這么多的參數非常繁瑣且耗時,甚至可能導致性能嚴重下降;并且Ceph參數配置的最佳性能是應用于特定Ceph應用程序的,因此將針對特定應用程序優化的一組配置應用于不同的Ceph系統會導致性能欠佳;另外大量普通Ceph 用戶缺乏對Ceph的底層實現原理的理解,對參數優化沒有經驗,導致運維人員的工作量顯著增加。現有的針對存儲系統參數調優問題研究已有一定進展,Cao等[4]提出一種黑盒自動調整存儲系統參數的方法,迭代嘗試不同的配置,測量系統的性能,并根據之前的信息,選擇下一次的參數配置。但該方法每次需要運行具有大量輸入數據集的應用程序,會耗費大量時間并且會占用大量系統資源。
針對以上問題,本文提出一種基于隨機森林(Random Forest,RF)和遺傳算法(Genetic Algorithm,GA)參數自動調優的方法,用于自動調整Ceph 參數配置,優化Ceph 系統性能。該方法通過隨機森林算法建立性能預測模型,與需要執行應用程序的方法相比,建立性能模型能夠更快地預測應用程序的性能,從而減少系統資源的占用,節省大量測試時間;之后將性能預測模型的輸出作為遺傳算法的輸入對Ceph 參數配置方案進行自動迭代優化,以找到最佳參數配置。實驗結果表明,與默認的Ceph 參數配置相比,調優后的參數配置使Ceph 文件系統讀寫性能平均提高了1.4 倍,并且尋優耗時遠低于黑盒參數調優方法。
1 相關工作
統計推理和機器學習技術[5]已經用于存儲系統參數調優的研究,如模擬退火(Simulated Annealing,SA)、貝葉斯優化(Bayesian Optimization,BO)、遺傳算法、支持向量機(Support Vector Machine,SVM)、深度Q 網絡(Deep Q Network,DQN)、隨機搜索(Random Search,RS)等被應用到參數自動調優算法中,形成了相應的參數自動調優模型。目前常用的存儲系統參數自動調優方法包括基于策略選擇的抽樣算法、基于HCOpt 系統的參數調優、TaskConfigure 服務器方法、DAC(Datasize Adjustment of Configuration,一種數據量感知自動調整方法)、自適應調優框架MrEtalon、基于遺傳算法的參數調優和黑盒參數自動調優等。黑盒自動調整存儲系統參數方法的基本機制是迭代嘗試不同的參數配置,測量出目標函數的值,并根據以前學習的信息,選擇出下一個需要嘗試的參數配置,指導搜索出最優參數配置;但是該方法優化參數配置時每次都需要運行具有大量輸入數據集的應用程序,會耗費大量時間并且會占用大量系統資源。文獻[6]提出了一種基于HCOpt 系統的參數調優,該系統采用了基于遺傳算法的參數調優算法,無需分析Hadoop 各參數間的制約關系,能夠縮短求解時間。HCOpt 系統目前針對的是用戶手動提交的Map Reduce 作業,但實際的應用環境中,有很多的Map Reduce 作業是一些高級的系統框架根據用戶命令自動生成的,該方法并沒有考慮到此問題。文獻[7]提出了一個自適應調優框架MrEtalon,可以在短時間內為新工作推薦接近最優的配置。MrEtalon 設置了一個配置存儲庫來提供候選配置,以及一個基于協作過濾的推薦引擎來加速參數的優化;但該方法在生成推薦的過程會延遲作業執行,并導致資源空閑。文獻[8]提出了基于作業資源消耗簽名的任務分類和基于遺傳算法框架的調優系統,系統依據任務的資源消耗模式為不同類型的任務分配適合的配置表,將每一次任務運行作為一次集群測試,將測試結果反饋后用以調優。文獻[9]提出的TaskConfigure服務器通過構建Hadoop 集群參數信息庫系統實現對集群參數的自動調優配置,通過對集群節點及任務的分類,提出集群按類分配配置參數及采用節點資源利用效率生成集群系統參數的優化配置值。文獻[10]提出了基于策略選擇的抽樣算法,在Hadoop 中加入了策略感知層,實驗結果表明改進的Hadoop 框架可以自動優化設置這些復雜的參數,從而提高整個系統的運行效率。這里策略感知層的思想是用一種抽樣算法來實現樣本感知總體,從而實現根據集群的運行狀況和作業的數據特點來動態選擇配置參數。但該方法在數據量比較小時,框架的運行效率反而不如以前的框架;而且海量數據的抽樣算法屬于一種隨機抽樣,所以樣本對總體的估計有很大的隨機性。
上述方法能在一定程度上解決存儲系統繁瑣的參數配置調整問題,推動存儲系統參數自動調優的研究工作,但未能考慮存儲系統參數的空間巨大性及非線性關系,不能很好地解決Ceph系統的參數調優問題。
2 Ceph配置參數
Ceph數據讀寫的基本流程:msg模塊接收到讀寫請求,通過ms_fast_dispatch 等函數的處理,添加到OSD(Object Storage Device)的op_sharedwq函數中。在op_sharedwq函數的請求下通過線程池的一系列復雜處理,最后調用FileJournal 的submit_entry 函數同時添加到FileJournal 的writeq 隊列里和completions隊列里。FileJournal的write_thread線程以aio的形式寫日志數據到磁盤,FileJournal的write_finish_thread 以線程檢查IO 請求是否完成。Finisher 的線程把請求添加到FileStore 的op_wq 隊列里,FileStore 調用write 系統,先將對象數據寫入系統的PageCache 里,然后再寫入XFS 文件系統里。當數據內容不足時,也有可能直接刷磁盤,然后向上層返回ack應答讀寫成功[11]。
上述模塊中包含大量的Ceph 參數配置,本文選取了這些模塊中能夠顯著影響Ceph 文件系統讀寫性能的一些參數進行研究,具體的參數及其取值范圍如表1所示。
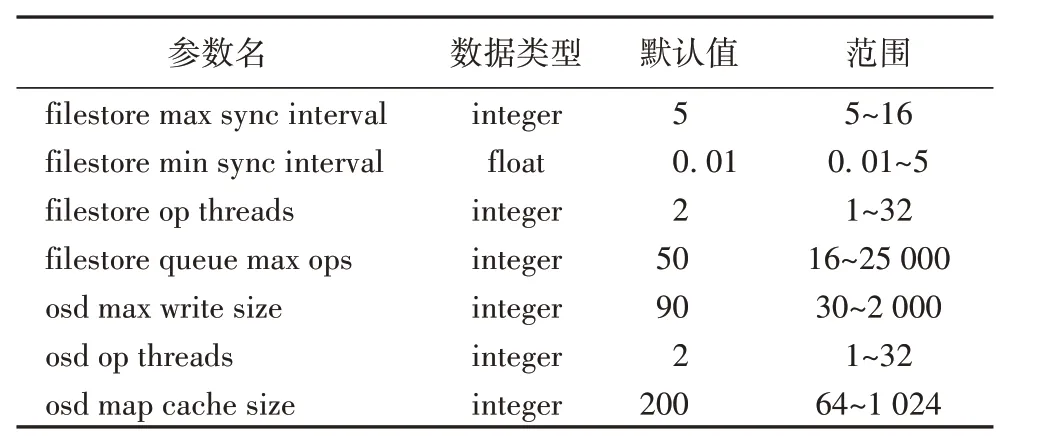
表1 Ceph配置參數說明Tab.1 Description of Ceph configuration parameters
其中不同的參數取值會對Ceph 系統性能產生不同的影響,如將osd_op_threads(處理peering 等請求的線程數)、filestore_op_threads(IO 線程數)參數設置一個較大值,能夠加快IO 處理速度,但是如果線程太多,頻繁的線程切換也會影響系統性能。為了更直觀地了解不同參數配置對Ceph 文件系統讀寫性能產生的影響,對表1中的7個參數取值進行隨機分配,形成300 組不同的Ceph 參數配置,以Ceph 文件系統每秒的讀寫次數(Input/Output Operations Per Second,IOPS)作為性能指標,通過運行相應的Ceph 集群,觀察系統的性能如何隨參數配置而變化。圖1 顯示了當Ceph 配置參數發生變化時,系統的讀寫性能發生顯著變化,并且參數配置與性能呈現出非線性關系,有些參數配置在經過調整后反而降低了系統性能。由此可見,手動調整Ceph 配置參數非常繁瑣且耗時,甚至可能導致性能嚴重下降。

圖1 不同參數配置下性能變化Fig.1 Performance changes with different parameter configurations
3 模型架構
針對上述問題,本文提出基于隨機森林和遺傳算法的參數自動調優方法,可以自動調整配置參數的值,以優化給定集群上運行的Ceph應用程序的性能。圖2顯示了該方法的總體架構,主要由生成數據、建立模型和參數尋優三個部分組成。

圖2 模型總體架構Fig.2 Overall architecture of the proposed model
主要步驟如下:
1)在Ceph 參數配置范圍內,對參數進行隨機采樣,生成一個參數集{conf1,conf2,…,onfn};
2)使用生成的參數集運行相應的Ceph 集群,以Ceph 文件系統每秒的讀寫次數作為性能指標,收集相應的性能{IOPS1,IOPS2,…,IOPSn};
3)使用步驟1)和2)中的數據集,通過隨機森林算法建立性能預測模型;
4)輸入一組配置參數的初始值到性能預測模型中,性能預測模型輸出相應的IOPS值;
5)將默認的參數配置和相應的IOPS 值作為遺傳算法輸入,執行交叉、變異操作,生成一組新的配置參數,將這些參數再次傳入性能預測模型,直到找到最優參數配置。
3.1 生成數據
生成數據模塊主要目的是收集不同的參數配置所對應的Ceph 文件系統的讀寫性能,然后,將收集的數據集用于建立性能模型。本文使用隨機采樣的方法對表1 中的參數進行采集,生成參數集confi={ci1,ci2,ci3,ci4,ci5,ci6,ci7}。confi是一組參數配置,cin是單個的參數取值。將采樣的參數集confi放入Ceph集群中運行,以Ceph文件系統每秒的讀寫次數作為性能指標,得到相應的性能 IOPSi,構造一個向量S={(conf1,IOPS1);(conf2,IOPS2);…;(confn,IOPSn)}存 儲 參數配置集和相應的性能。
3.2 建立模型
考慮到Ceph 配置參數以復雜的非線性關系相互作用,本文選取隨機森林來為Ceph 文件系統構建性能預測模型。隨機森林是一種強大的集成模型,是bagging 算法的一種擴展,該方法結合了統計推理和機器學習方法的優勢[12],基于一組回歸或分類樹而不是單一樹進行預測,并組合各個樹的輸出以得到最終輸出,這使得性能預測不僅準確而且建立的模型更加穩定。此外,該方法對過度擬合具有很強的魯棒性,并且它沒有對預測變量作出任何假設,算法1 展示了建立隨機森林模型的具體過程。
算法1 隨機森林建模過程。
輸入 訓練集S;訓練樣本B;
1) For i=1 to B{
2) Ti=bootstrap sample from S
4) }
輸出 預測性能Pre。
使用向量S 作為隨機森林的輸入,從全部樣本中選取大小為B 的bootstrap 樣本,并將它們存儲在Ti中;樣本特征數目為7,對B 個bootstrap 樣本選擇7 個特征數目中的k 個特征,用建立決策樹的方式獲得最佳分割點,重復m次,產生m棵決策樹,將它們存儲到Cx中;通過聚合B個bootstrap 樣本樹的預測來預測新數據Prei。
3.3 參數尋優
在建立完性能模型后,仍然不知道最優的參數配置,本文選取遺傳算法來搜尋最優參數配置。遺傳算法是一種通過模擬自然進化過程搜索最優解的方法[13],其主要特點是:直接對結構對象進行操作,不存在求導和函數連續性的限定;具有內在的隱并行性和更好的全局尋優能力;采用概率化的尋優方法,不需要確定的規則就能自動獲取和指導優化的搜索空間,自適應地調整搜索方向。圖3描述了參數尋優的基本框架。
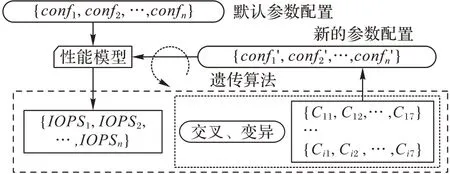
圖3 參數尋優框架Fig.3 Framework of parameter optimization
首先將默認的參數配置輸入到性能模型中,得到對應的讀寫性能;將默認配置參數及相應的讀寫性能作為GA 的輸入,讀寫性能作為GA 的適應度值;GA 將默認參數進行交叉、變異,得到一組新的參數配置;將新的參數配置傳入性能模型中。重復以上步驟,直到找到最優參數配置。
參數尋優的算法如算法2所示:
算法2 參數尋優。
輸入 初始種群p(0),迭代計數器t,交叉發生的概率Pc,變異發生的概率Pm,種群規模M,終止進化的代數T;
1) 初始化Pc、Pm、M、T參數,隨機產生第一代種群p(0)
2) do
3) 計算種群p(0)中每一個個體的適應度f(t)。
4) 初始化空種群p(t)
5) for t=0 to M
6) 根據適應度以比例選擇算法從種群p(0)中選出2個個體
7) if(random(0,1)<Pc)
8) 對2個個體按交叉概率Pc執行交叉操作
9) if(random(0,1)<Pm)
10) 對兩個個體按變異概率Pm執行變異操作
11) 將2個新個體加入種群p(t)中
12) end for
13)用p(t)取代p(0)
14)while t<T
輸出 p(t)。
算法具體流程如下:
1)初始種群生成。初始種群采用隨機的方式生成,設為p(0),設定迭代計數器t=0,p(t)表示第t代種群,p(0)中每個個體由表1中7個參數值組合。
2)計算個體適應度值。適應度值用于評價個體的優劣程度,適應度越大個體越好,反之適應度越小則個體越差。這里以Ceph文件系統每秒的讀寫次數作為遺傳算法的適應度值。
3)選擇操作。根據適應度的大小對個體進行選擇,以保證適應性能好的個體有更多的機會繁殖后代,使優良特性得以遺傳。這里采用的選擇算法為“輪盤賭算法”,即個體被選中的概率與其適應度函數值成正比。首先計算所有個體的適應度之和:

然后計算每個染色體被選擇的概率:

4)交叉操作。對配置方案參數進行二進制編碼,并采取單點交叉方式,隨機設置交叉點互換參數信息。
5)變異操作。采用基本位變異的方法,對個體編碼串以變異概率Pm隨機指定某一位或某幾位基因進行變異操作。對每一個變異點,將其按位取反或用其他等位基因來替換。操作完成后,對參數編碼進行解碼,生成新的種群p(t)。
6)更新種群。用交叉、變異后得到的新的種群p(t)取代初始種群p(0)。
7)終止條件判斷。當進化代數達到規定迭代次數T 時,輸出結果;否則轉到步驟3)。
本文將一組參數配置confi={ci1,ci2,ci3,ci4,ci5,ci6,ci7}作為遺傳算法中的一條染色體,其中的每一個參數值代表一個基因,Ceph 文件系統每秒的讀寫次數作為遺傳算法的適應度值。在遺傳算法尋優前,首先要確定Pc、Pm、M、T 的取值:變異概率Pm變異實質上是對參數配置取值空間的深度搜索,變異概率取值太大則會使遺傳算法成為隨機搜索算法,并且由于隨機性太大,GA 在搜索上會花費更多的時間[14],故Pm取值為0.01;交叉概率Pc影響了配置方案的交替速度,選取較高的交叉概率使算法效率更高,這里取為0.8;種群規模M 與迭代次數T 越大,可以增加搜索規模,提高搜索精度,但是太大會增加時間開銷,降低搜索的效率,本文將M和T設置為100。
4 實驗結果與分析
4.1 性能模型對比分析
為了利用隨機森林算法構造性能模型來自動優化Ceph程序,需要確定3.2 節中的兩個參數m 和k,其中m 代表決策樹的個數,k是決策樹參數的最大特征數。較高的m值能使隨機森林模型獲得較高的精度,但也會導致較長的模型評估時間[15]。本文選取網格搜索的方法來確定m 和k 的最優值,圖4(a)中橫坐標代表決策樹的個數,縱坐標代表模型的精度。從整體上看,隨著m值的增大,模型精度隨之上升,當m=141時,對模型精度的提高趨于平緩,綜合模型的運行成本,選取m 值為141。圖4(b)中橫縱坐標分別代表決策數的最大特征數和模型精度,當k=7時,模型精度達到最高。
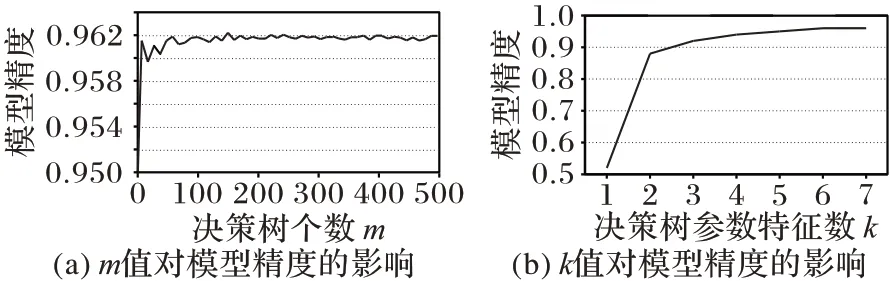
圖4 m和k值對模型精度的影響Fig.4 Influence of m and k values on model accuracy
在確定了隨機森林的參數之后,從表1 的配置參數中隨機采樣出500 組數據,在4 臺服務器上部署Ceph 文件系統讀寫性能測試集群測試它們對應的讀寫性能,構成實驗數據集S,其中80%作為訓練集,20%作為測試集。圖5 顯示了隨機森林建立的性能模型的預測效果,其中橫縱坐標分別代表不同的參數配置和Ceph 系統性能。觀察圖5 可以發現,隨機森林算法建立的性能模型能夠很好地預測Ceph 文件系統的讀寫性能,并能及時反映實測值的變化趨勢。

圖5 隨機森林預測效果圖Fig.5 Random forest prediction effect map
為了驗證隨機森林性能模型的優劣性,本文采用了隨機森林(RF)、支持向量機(SVM)、人工神經網絡(Artificial Neural Network,ANN)和K 最近鄰(K-Nearest Neighbors,KNN)算法幾種機器學習算法分別為Ceph 文件系統構建了讀寫性能模型,并分析比較了這幾種性能模型的精度。幾種機器學習算法建立的性能預測對比模型如圖6 所示,其中Real 為實際測試值,SVM、KNN、ANN、RF 分別代表支持向量機、K 最近鄰、人工神經網絡和隨機森林算法建立的性能模型預測值。從整體趨勢上看,采用隨機森林算法得到的預測值能夠及時反映實測值Real 的變化趨勢,而采用其他算法得到的預測值曲線則與實測值Real 曲線存在較明顯差異;并且當實測值Real 發生驟然改變時,隨機森林模型的預測值能夠及時跟隨Real上升或下降,而其他模型的預測值則存在明顯振蕩,且嚴重滯后于實測值的變化趨勢。

圖6 幾種模型的綜合性能對比Fig.6 Performance comparison of several models
為了更直觀地比較各模型精度,本文定義預測誤差公式為:
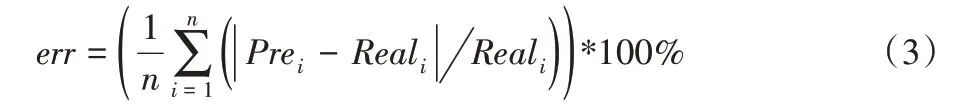
其中:Prei是Ceph 文件系統讀寫性能的預測值,Reali是測試的實際性能值。err 反映了性能模型的預測值與實際測試值之間的相對差異,并且越低越好。RF、SVM、ANN、KNN 的誤差分別為8.6%、20%、27%和49%,由此可見,隨機森林算法建立的模型性能要明顯優于其他機器學習算法。
4.2 尋優性能對比分析
使用遺傳算法迭代尋優的趨勢圖如圖7 所示,圖中橫坐標代表遺傳算法的迭代次數,縱坐標代表Ceph 文件系統的讀寫性能。為了確保實驗結果的有效性,取5 次遺傳算法尋優程序運行的平均值作為最終實驗結果。觀察圖7 可以看出,遺傳算法經過約70 次迭代之后,能夠達到平穩狀態。經過參數優化后的Ceph 文件系統讀寫性能約為3 144,而默認參數配置的性能只能達到1 300,性能提高了約1.4倍。
為了評估本文方法對Ceph 參數自動調優的效率,將黑盒參數調優法與隨機森林和遺傳算法參數調優法進行對比,圖8 顯示了在不同大小文件下,兩種方法搜索出最優參數的耗時對比。觀察圖8 可以看出,使用隨機森林和遺傳算法優化參數的耗時要明顯低于黑盒參數調優的方法;并且隨著輸入文件的變大,黑盒參數調優法的耗時顯著增加,而加入性能模型調優的方法耗時能夠穩定在一個較小的值。因為遺傳算法每次的迭代只需要對性能模型進行評估,并不需要重新運行Ceph 應用程序,而黑盒參數調優法每次需要運行具有大量輸入數據集的應用程序,會耗費相當長的時間。
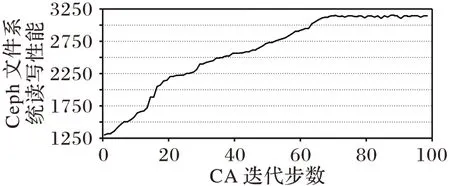
圖7 讀寫性能與GA迭代步數關系Fig.7 Relationship between read and write performance and GA iteration step
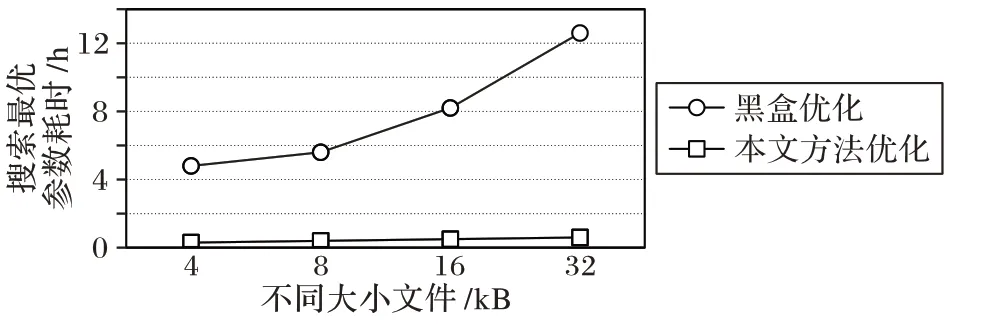
圖8 不同大小文件下尋優效率對比Fig.8 Comparison of optimization efficiency under different file sizes
5 結語
本文針對Ceph 配置參數難以手動調優的問題,提出一種基于隨機森林和遺傳算法的參數調優方法,用于自動調整Ceph配置參數,以優化Ceph系統性能。利用隨機森林建立準確和強大的性能預測模型,將模型的輸出作為遺傳算法輸入以自動搜索Ceph 參數配置空間,產生新的參數配置,優化應用程序性能。實驗結果表明,經過參數調優后的參數配置與默認參數配置相比,Ceph文件系統讀寫性能提高了約1.4倍,并且尋優耗時遠低于黑盒參數調優方法。在以后的工作中,將繼續深入對集群參數的研究,進一步了解參數之間及參數值的設定與系統資源的相關性,并增加參數的研究數量。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
兒童故事畫報(2019年5期)2019-05-26 14:26:14
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
核科學與工程(2015年4期)2015-09-26 11:59:03
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
