基于E2LSH的軌跡KNN查詢算法
2020-04-09 06:36:40吳志兵
計算機技術與發展 2020年3期
邱 磊,吳志兵
(江南計算技術研究所,江蘇 無錫 214083)
0 引 言
隨著傳感器技術和定位技術的發展,基于位置的服務應用越來越廣泛。人類活動通過智能手機APP應用軟件進行位置分享、簽到等;車輛安裝GPS或北斗定位系統,周期性地上報位置信息;動物學家記錄動物的遷徙路徑等等。在這些活動中產生了一系列軌跡數據,隨著時間的推移,數據規模愈加龐大。
對于海量軌跡數據的挖掘,可以獲得大量有價值信息。例如,對車輛軌跡數據分析研究獲取駕駛行為與交通路網之間的相關性[1];對智能手機定位軌跡數據分析得到用戶的移動特點和生活規律[2];對旅行軌跡數據分析向用戶推薦滿足不同需求的路徑[3]。軌跡數據挖掘常常依賴于大量的軌跡查詢行為。軌跡查詢分為KNN(k-nearest neighbor)查詢和范圍查詢,而KNN查詢又分為軌跡點查詢和整條軌跡的查詢。查詢的第一步是定義兩條軌跡的距離,也就是軌跡之間的相似度[4]。
傳統的海量軌跡數據查詢基于樹結構進行索引,當軌跡較短,即維度較少時性能良好,但是隨著維度的增加(比如20維以上),檢索效率會急劇下降,在性能上甚至還不如對整個數據集合進行順序檢索,這就是高維空間數據處理都會遇到的“維數災難”[5]問題,從而導致難以實現軌跡的快速查詢。局部敏感哈希技術[6](locality sensitive hashing,LSH)是解決高維數據近鄰查詢的有效方法。傳統的LSH采用漢明距離來實現近鄰數據的快速查詢,所以在實際應用中需要首先將數據嵌入到漢明空間,大大增加了計算的復雜度。目前在大規模數據高維近鄰索引中,一般采用LSH在歐氏空間中的一種隨機化方法,被稱為精確局部敏感哈希(exact Euclidean locality sensitive hashing,E2LSH)[7]。LSH技術在很多領域獲得了成功應用,例如大規模網頁的去重、海量圖片搜索以及相似音視頻的檢索等等。
綜上,文中提出了一種支持海量軌跡數據的KNN查詢算法(trajectory E2LSH-based KNN query,TRA-EKNN)。首先研究軌跡大數據的向量空間建模問題,并結合特定領域的興趣點(point of interest,POI)進行了初步降維,進而采用E2LSH算法實現軌跡數據的索引構建,并在合成數據以及實際數據集上進行KNN查詢,最后對實驗結果進行了分析和總結,并展望了后續工作。
1 相關工作
對于軌跡數據的KNN查詢算法,根據查詢結果的可靠性,可以分為兩類:基于時空數據庫索引的窮舉算法和基于哈希的近似算法。
目前,對于軌跡數據的查詢研究多基于窮舉算法。時空數據庫[8](spatio-temporal databases,STDB)將時間和空間有機結合,實現對時空對象的有效管理。由于R樹以及改進樹[9]在空間索引的巨大優勢,被大多時空索引結構所采用。近似算法在允許一定誤差的前提下,可以大大提高檢索性能。在海量數據日益增多的情況下,近似算法受到研究者的廣泛關注。在近似算法中,應用最為廣泛的是基于哈希的檢索技術。Athitsos等[10]定義并實現了一種全新的基于距離的哈希算法(distance-based hashing,DBH)。Sanchez等[11]提出了一種基于LSH算法的軌跡聚類算法。這兩種算法都將軌跡視為連續的軌跡點,即一條曲線,因此計算過程中均沒有考慮時間因素,不適應于嚴格定義的軌跡數據。
國內學者對LSH技術在軌跡數據分析中的應用也做了大量相關研究。趙家石等[12]采用局部敏感哈希技術尋找在一定時間內都相似的移動對象,從而避免傳統方法的交集運算過程,實現軌跡相似度的快速估計。廖律超等[13]利用譜哈希實現對交通路網的快速聚類,挖掘出交通軌跡大數據的潛在特性,為交通規劃提供了科學依據。印桂生等[14]將文本相似領域比較廣泛應用的相似哈希(simhash)[15]技術應用到用戶軌跡的相似性比較中,取得了較好效果。
2 TRA-EKNN算法
2.1 相關定義
文中所研究的問題是在海量的軌跡大數據中,根據一條軌跡數據查詢找出距離最近,也就是最相似的k條軌跡。
定義1:軌跡是由移動對象在增量時間的一系列軌跡點組成,記為:
TR={P1,P2,…,Pn}
其中Pi是移動對象在t時刻的位置(用經緯度表示),即pi=(lat,lng,t)。
定義2:網格空間是指對參與計算的地理空間進行劃分編碼形成的網格集合,記為:
G={gid1,gid2,…,gidm}
其中gidi表示編號為i的網格。地理空間可以是一個國家、一個城市,也可以是結合特定領域知識和含義進行篩選之后區域范圍。
定義3:網格序列[16-17]是指一條軌跡將經過的網格順序排列之后的集合,記為:
GS={g1,g2,…,gm}
其中gi=(gid,t),即在網格gid停留時間為t。
2.2 算法思想
TRA-EKNN算法主要包括網格索引建立、軌跡向量建模和KNN查詢實現等過程,具體流程如圖1所示。
2.2.1 網格建立
網格索引建立是針對特定領域的POI集合計算每個地理位置的網格編號,然后合并形成一個網格空間G。
文中采用GeoHash技術實現網格的編碼。GeoHash通過使用一個字符串同時表示經度和緯度兩個坐標,是一種通用的地址編碼方案,具有如下特點:將二維空間的經緯度編碼成一個字符串,在傳統的數據庫中做到一維的高效索引;每一個GeoHash表示的不是一個點,而是一個矩形的區域;GeoHash編碼的前綴可以用來表示更大范圍的區域。
GeoHash的計算方法主要分為三步:
(1)經緯度轉換為二進制。首先將全部的緯度范圍(-90,90)平均分為區間(-90,0)和(0,90),如果目標維度位于第一個區間,則編碼為0,否則為1,例如39.923 24屬于(0,90),取編碼為1。然后再將(0,90)分為區間(0,45)和(45,90),而39.923 24位于(0,45),編碼為0。以此類推,直到精度符合要求為止,最終得到緯度的編碼1011 1000 1100 0111 1001。經度也采用同樣算法得到編碼。
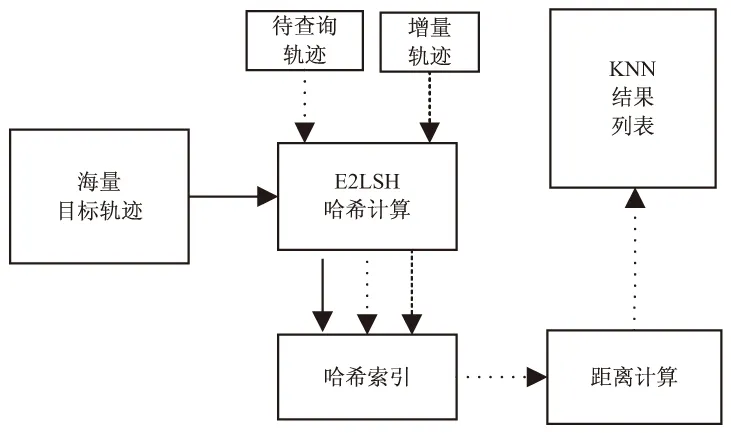
圖1 TRA-EKNN算法框架
(2)按照經緯度的二進制合并。按照緯度在奇數位,經度在偶數位的規則進行合并。
(3)進行Base32編碼。編碼字符使用0-9和b-z(其中去掉a,i,l,o四個字母)。
由以上的GeoHash計算過程,可以知道精度取決于編碼長度,根據實際需求采用不同長度的編碼,二者的對應關系如表1所示。
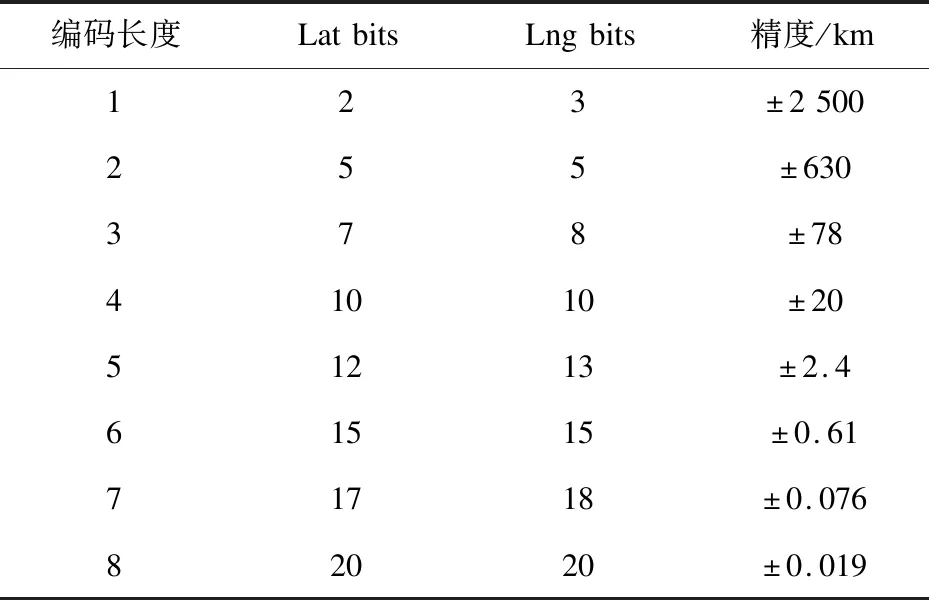
表1 GeoHash編碼長度與精度
通過將地理位置編碼,實現了對地理空間的網格索引。在此過程中,根據不同的應用場景采用不同的編碼長度,實現效率與精度的統一。將所有特定領域的POI數據經過GeoHash編碼,可以得到網格空間G,相比于直接將所有的空間都進行編碼,此方法利用了數據融合的思想,從而大大減少了網格數量,實現初步降維,在后續的計算過程中也更具實際意義。
2.2.2 軌跡向量建模
借鑒文本分類中向量空間模型(VSM)[18]的思想,將網格空間G視為n維向量的維度,本小節基于此,將軌跡向量化,然后再進行軌跡的距離計算。
軌跡網格序列化算法是向量建模的關鍵。將原始軌跡數據轉換為網格序列,可以在保證一定精度的前提下,簡化軌跡的處理過程。
算法1:軌跡網格化。
輸入:軌跡TR={P1,P2,…,Pn}
網格空間G={gid1,gid2,…,gidm}
輸出:網格序列GS={g1,g2,…,gm}
其中gi=(gid,t)
詳細過程:
1.foreachPiin TR
2.if(i==1)
3.last_time=Pi.t
4.last_geo=geohash(pi.lat,pi.lng)
5.continue
6.g.gid=geohash(Pi.lat,Pi.lng)
7.t_interval=Pi.t-last_time //時間差
8.if(g.gid inG)//只處理位于網格空間的數據
9.if(g.gid==last_geo)
10.t_stay=t_stay+t_interval
11.else//進入另一網格
12.if(g.gid in GS)
13.Break// 截斷處理
14.g.t=t_stay+t_interval/2
15.GS.append(g) //當前點加入序列
16.t_stay=t_interval/2
17.OUTPUT(GS)
算法1描述了軌跡轉換為網格序列的全過程。最終的輸出包含軌跡所經過的網格編碼和相應的停留時間。由于采樣時間的差異,導致在同一個區域可能出現多個軌跡點。停留時間的計算需要考慮兩種情況:(1)兩個軌跡點位于同一個網格時,間隔時間直接累加;(2)前后兩個軌跡點位于不同網格,則停留時間按時間間隔的一半累加。從后續工作中可以看到,軌跡的向量化意味著軌跡網格不允許出現重復,所以算法1進行了簡單處理即軌跡截斷,另外一種方法是將后續軌跡點當作另一條軌跡繼續處理。
經過算法1的處理,軌跡轉換為在選定領域(網格空間)的網格序列。基于此,可以構建軌跡的向量矩陣[13],其中矩陣的行對應于全部的網格空間,列對應于每條軌跡。假設軌跡數據經過算法1的計算,提取出了r條軌跡,相應的網格空間大小為n,則構成一個n×r的“網格-軌跡”矩陣T,每個元素的值定義為軌跡點在對應網格停留時間。
將軌跡進行以上處理之后,可以據此定義兩條軌跡向量的距離:
(1)
軌跡的網格空間可以理解為針對特定領域所關心的所有位置,也就是在軌跡的距離(相似)公式中參與計算的位置,其他非必要的位置不參與計算。相比于通過聚類方法提取POI(興趣點)的方法,大大降低了數據預處理過程的難度和時間消耗。
2.2.3 E2LSH算法索引構建
E2LSH是LSH在歐氏空間的一種隨機化實現方案。基本的思路是:采用基于p穩定分布的局部敏感函數對原始的高維數據進行降維映射。可以看出,E2LSH繼承了LSH的特點,即在原始空間相鄰的數據,經過哈希之后,在新的空間上存在很大的概率也相近,具體哈希函數如下:
(2)
其中,a是獨立隨機選擇的d維向量,b為范圍[0,w]的一個隨機數。函數h將一個d維向量映射到一個整數集,然后以w為寬度進行等距離劃分。E2LSH將k個哈希函數聯合使用,稱之為函數族:
(3)
函數族g對應于L個哈希表,隨機獨立選取的k個h函數又構成了每個g函數,函數的值對應具體的哈希桶。
從算法思想的本質上看,LSH是不確定的,概率性的,可以歸結為近似算法。隨著數據規模越來越大,數據處理的時效性要求面臨很大挑戰,這時通過犧牲一定精度以獲得更快的處理速度,在一些領域是可行而有效的。本節將此算法應用于軌跡數據索引的構建,具體過程如下:
(1)對于數據庫中的軌跡,經過算法1得到一條包含停留時間的網格序列;
(2)對于每條網格序列,由式(3)得到長度為k的哈希桶,計算L次,組成L個哈希表;
(3)對哈希表中的每個桶生成一個索引文件。
2.2.4 KNN查詢實現
KNN查詢的目標是在軌跡數據中找到與查詢軌跡TR距離最近的k條軌跡。傳統的線性算法通過計算待查詢TR與所有的軌跡的距離,然后從中選出最近的k條軌跡,顯然在這過程中計算量十分的巨大。雖然可以采用R-Tree、KD-Tree等樹結構進行優化,但是“維數災難”的問題,使得軌跡點數較多時,存在著大量的回溯計算,導致樹結構不能發揮作用,這時退化成線性運算。
本算法在上一節構建好軌跡數據的E2LSH索引的基礎上進行查詢,具體流程如下:
(1)運用算法1得到所要查詢的軌跡對應的網格序列;
(2)計算待查詢網格序列的L個哈希表索引;
(3)遍歷哈希表,找到對應的哈希桶,對桶內的軌跡,利用式(1)計算對應的距離,返回最近的k條軌跡。
本算法使用E2LSH技術,首先將所有的軌跡數據按照距離劃分到不同的哈希桶,同一個哈希桶的軌跡距離較近,所以KNN查詢只需要根據不同哈希值比較同一個或者相近桶內的軌跡,從而極大地減少了需要計算比較的軌跡數量,使得海量軌跡的KNN查詢效率得到有效提升。
3 實驗結果與分析
實驗采用兩個數據集:合成數據用來檢測算法的時間效率,并與傳統查詢算法進行對比;上海出租車軌跡數據用來證明算法在實際應用中的有效性。實驗環境為單機,處理器為Intel(R) Core(TM) i3 M 380 @ 2.53 GHz,內存6 G,操作系統為Windows7 64位 SP1,采用python語言編程實現。
3.1 合成數據實驗
本實驗的合成軌跡數據,根據網格數量和軌跡停留時間隨機生成。假設網格數量為m,軌跡數量為n,根據m和n的不同取值,查詢某條軌跡的最近10條軌跡,消耗時間如圖2所示。
其中10 000*10 000表示10 000條軌跡對應于10 000個網格空間。可以看出時間消耗與二者的乘積大致是一個線性關系,隨著網格空間的增大和軌跡數量的增多,計算所消耗的時間成線性增長。
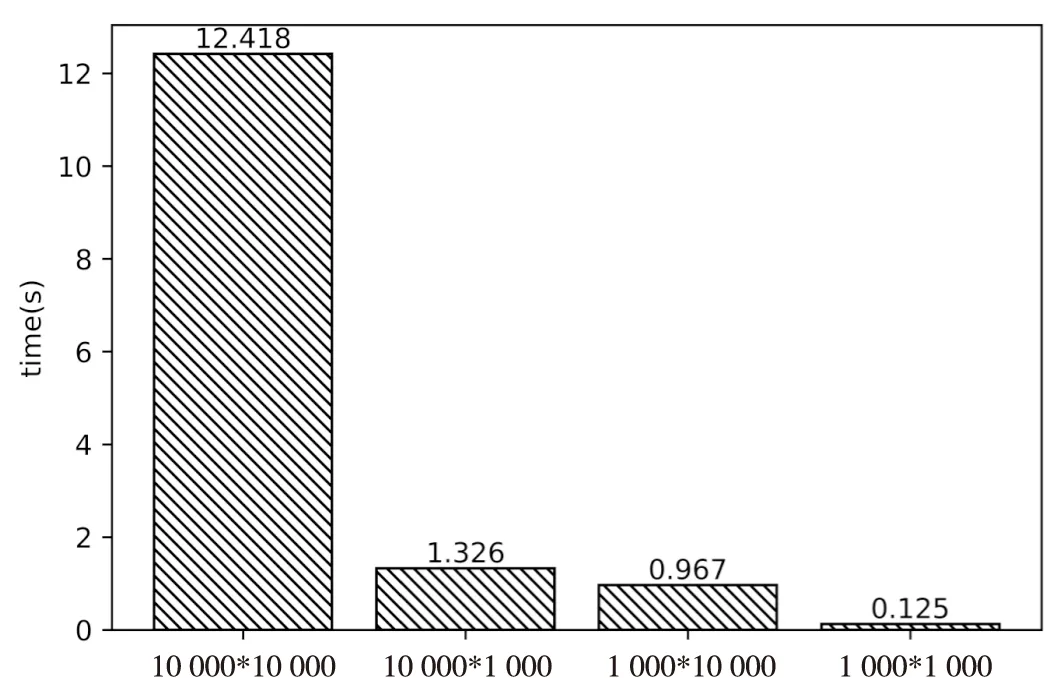
圖2 窮舉消耗時間對比
采用TRA-EKNN算法對上述數據進行KNN查詢,根據文獻[6]中的建議值,算法中w取值為4,k取80,L取10,此時獲得的準確率大于95%,時間消耗如圖3所示。
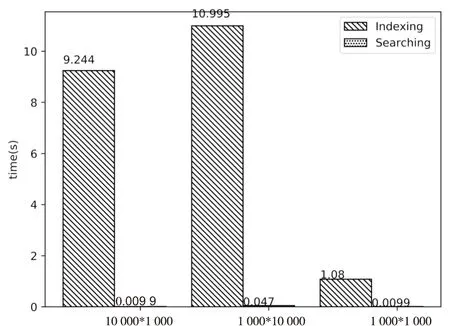
圖3 TRA-EKNN消耗時間對比
從圖3可知,TRA-EKNN算法中,時間消耗主要分索引建立和軌跡查詢兩部分,而且索引的建立時間遠大于查詢時間,而且當網格空間固定即軌跡的維度相同時,軌跡的數量只影響索引的建立時間,而查詢時間基本相同。
在實際的應用中,一般要先將海量的軌跡建立索引,圖1所示的查詢算法框架也體現了這一點。在后續的KNN查詢時間一般指的就是圖3中的查詢時間,也就是說在進行軌跡查詢之前索引已經建立完畢,查詢過程中無需關心E2LSH索引的建立時間。對比圖2可以看出,本算法的查詢時間消耗明顯小于窮舉算法。
3.2 上海出租車軌跡數據實驗
上海市出租車數據集,采集了2007年2月20日當天4 316臺出租車的GPS記錄信息,包括出租車標識、時間戳、經緯度、瞬時速度、順時針角度以及載客情況等。本實驗只取標識、時間戳和經緯度三個信息。
根據采集到的上海市交通相關的POI數據共計242 556條,考慮到實驗數據是出租車GPS軌跡結合表1的GeoHash長度與精度關系,哈希長度設定為7,誤差約為76米,將POI數據中的經緯度計算GeoHash,去重后,共計有71 495個網格。上海面積約為6 340平方公里,如果全部進行7位的GeoHash編碼,大約一百萬個網格(由于行政區劃的不規則,數據不準確,在此僅進行估算)。可以看出由于結合了交通領域的POI數據,使得網格空間大幅壓縮。
對出租車軌跡采用算法1進行處理,共提取有效軌跡對應的網格序列1 896條,由于出租車行駛過程中會出現司機休息和等待乘客等情況,停留時間會比較長,為了體現軌跡比較的實際意義,將停留時間大于二十分鐘的軌跡截斷,然后將其余軌跡的停留時間作歸一化處理。
采用TRA-EKNN算法,對所有的軌跡數據建立E2LSH索引,經過多次試驗,此算法可以在較短的時間內查詢出KNN結果,并有較高的準確率。
3.3 算法分析
正如前文所述,時空軌跡數據的KNN算法主要是基于傳統的窮舉算法,即采用一一匹配的暴力搜索的方式進行,此時時間復雜度是線性的,即○(N)。隨著數據規模越來越大,這種方式會消耗大量的時間。
文中提出的TRA-EKNN算法,首先建立了LSH索引,雖然帶來了空間消耗增加的問題,但檢索的時間復雜度降為了○(logN),這對于一些時效性要求較高的場景是完全適用的。
4 結束語
將在海量文本、音頻、視頻數據處理廣泛應用的E2LSH算法引入到軌跡數據的KNN查詢中。首先針對不同的應用場景,結合特定領域POI數據建立網格空間;然后對軌跡數據進行預處理,構造出軌跡的網格向量,利用E2LSH算法實現索引。從圖1算法的實現框架來看,對于增量的軌跡只需要計算哈希值,然后插入索引即可,計算簡單。實驗結果表明,在保證一定的準確率的情況下,該算法有效降低了軌跡KNN查詢時間。下一步將繼續對軌跡的特征提取方法進行探索,找出更適合軌跡數據處理的向量空間構建方案,使此方法能夠在海量的軌跡數據挖掘中得到更廣泛的應用。
