MongoDB負載均衡算法優化研究
2020-04-09 06:36:42陳敬靜馬明棟王得玉
計算機技術與發展 2020年3期
關鍵詞:數據庫
陳敬靜,馬明棟,王得玉
(1.南京郵電大學 通信與信息工程學院,江蘇 南京 210003;2.南京郵電大學 地理與生物信息學院,江蘇 南京 210003)
0 引 言
隨著通信技術、互聯網、云計算的飛速發展,互聯網浪潮已經到達,接入到互聯網中的設備呈指數增長,越來越多的數據以不同內容和形式涌現出來,大數據時代正式到來。大數據時代最主要的特征就是數據種類與數量的繁多,除了結構化數據還有半結構化數據以及非結構化數據,這要求數據存儲系統必須能夠處理高并發問題,同時還要易于擴展[1]。盡管在主流應用場景中仍然使用傳統關系型數據庫,但面對海量的數據,它很難滿足海量數據的存儲需求,已經無法滿足人們日益增長的需求。為了解決如何存儲和處理海量數據的問題,非關系型數據庫(NoSQL)應運而生[2]。MongoDB也是NoSQL的一種,因其非常適合處理海量數據和高并發而得到大量應用。文中通過研究MongoDB的自動分片原理,提出一種改進的基于節點實時負載的負載均衡算法[3],以有效解決其自身算法存在的部分問題。
1 MongoDB的自動分片
1.1 MongoDB簡介
MongoDB是10gen公司使用C++編寫開發的基于分布式文件存儲的開源NoSQL數據庫系統,由于其性能高效、功能豐富,在生產中得到了廣泛應用。MongoDB除了具有NoSQL 數據庫的相關特性外,還具有自動分片、集群擴展、單點故障自動恢復、復雜查詢等優點,非常符合存儲海量的半結構化或非結構化數據[4]。MongoDB將數據存儲為一個文檔,數據結構由鍵值對組成,其文檔的數據結構非常松散,是類似于JSON的BSON格式[5],存儲效率高。它是一個面向集合的,模式自由的文檔型數據庫,相較于傳統的關系型數據庫,在面對海量數據的挑戰時更加有優勢,其主要功能特性有:面向集合存儲、模式自由、容易擴展、支持復制和數據恢復、支持動態查詢、支持完全索引以及自動處理分片等[6]。
1.2 分片介紹
分片(Sharding)是指將內存中的數據拆分成不同的塊,分別存儲到不同機器上的過程。通過分割數據到不同的服務器,讓數據集的不同部分分別由不同的服務器負責,使得單個機器上的請求數得到減少,系統總負載得到提高,總存儲空間也得到提高[7]。分片是數據庫系統擴展的必然產物,而不是某個特定數據庫軟件附屬的功能,分片能在一定程度上決定系統性能的優劣。MongoDB采用自動分片(Auto-Sharding)機制,如圖1所示。
自動分片技術一般用于自動配置、監控和數據轉移,當數據量大到服務器的磁盤、內存難以負擔時,自動分片技術可以自動平衡負載和數據分布的變化,提升系統的擴展性能。此外,它還提供無單點故障自動恢復、自動故障轉移以及動態添加額外服務器等技術,為提升系統性能提供了很大幫助。
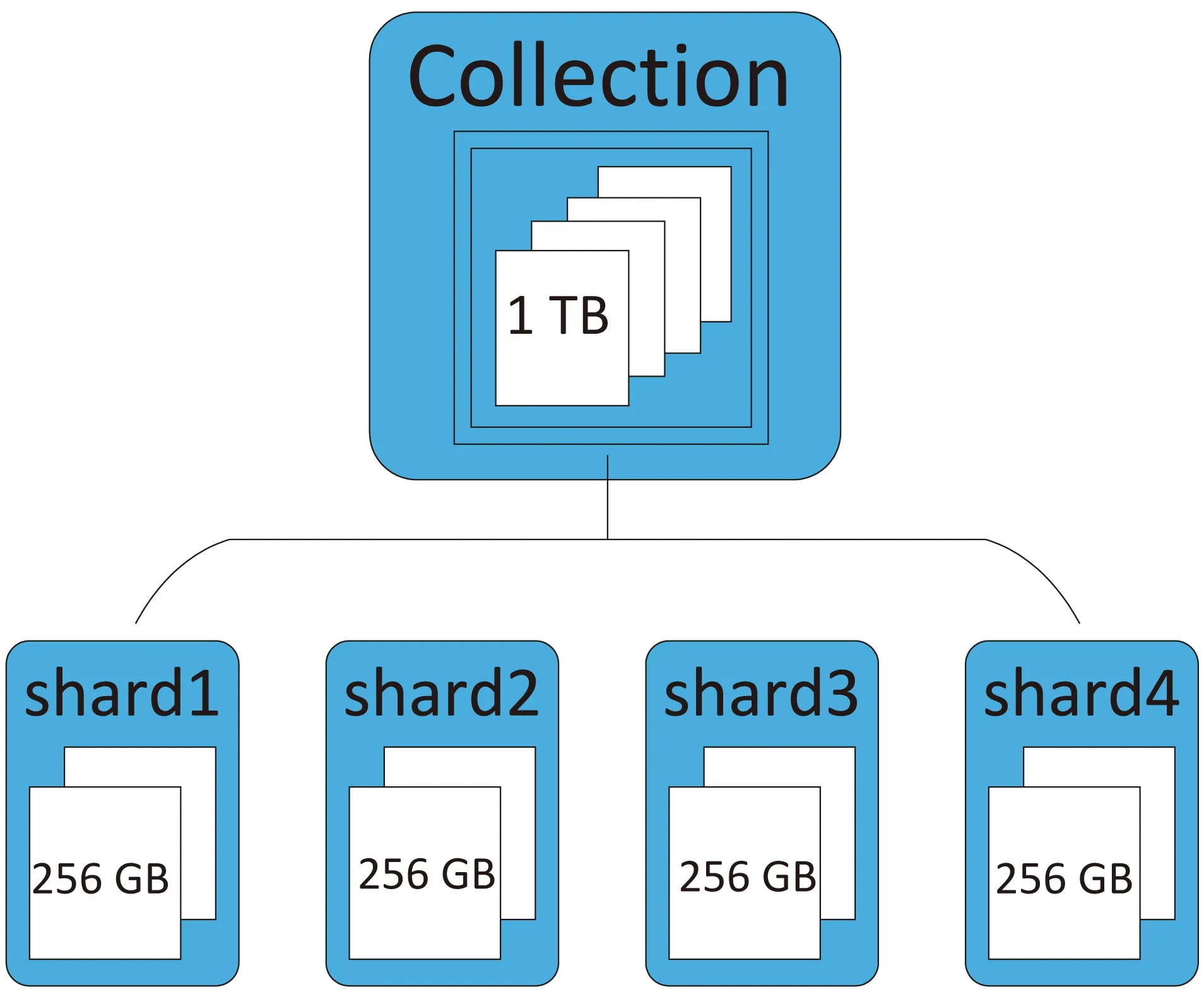
圖1 分片原理
1.3 自動分片集群架構
MongoDB的自動分片集群架構如圖2所示,主要包括分片服務器、路由服務器以及配置服務器,這三種服務器負責的功能如下:
(1)Mongos:路由服務器,負責將讀取和寫入的請求從應用程序路由到分片。集群通過Mongos連接客戶端和服務器,當客戶端向數據庫發送更新或查詢操作請求,Mongos接收請求并聚合,然后發送給分片服務器,它并不存儲數據,只傳遞請求[8]。
(2)Config Server:配置服務器,存儲集群的配置信息以及分片與數據的對應關系,運行集群時向路由服務器提供配置信息和對應關系。一般MongoDB自動分片集群中配有多個配置服務器,每個配置服務器中都保存了所有信息,防止信息丟失。
(3)Shard:分片節點,用于存儲數據。在架構中,一個片內可以有多個Mongos服務器,每個服務器中存放的數據都相同,主服務器只有一個,其他均為從服務器。存儲數據的部件是分片節點,為了獲得高擴展性和數據一致性,分片常與副本集(Replica Set)同時使用,防止該數據片單點故障[9]。
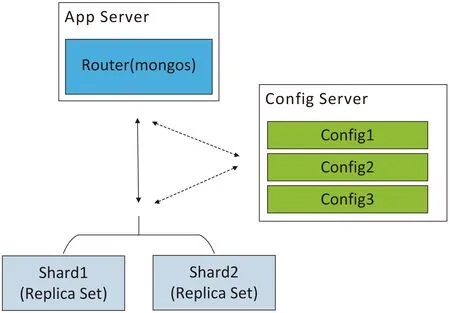
圖2 自動分片集群架構
一般情況下,當用戶向數據庫發送操作請求時,Mongos會解析數據庫的分片shard key(片鍵)規則,在存儲元數據的配置節點配置服務器中查找相關信息,找到對應的分片后將請求轉發到正確的片上,對客戶端發送來的請求進行響應,最后Mongos將獲取到的結果發送給應用程序[10]。將數據片段與應用程序分離是MongoDB分片技術中最獨特的地方,使用這種分片機制,用戶可以在不更改程序的前提下,實現對數據庫系統的擴展。
2 MongoDB負載均衡算法
2.1 Chunk塊拆分
MongoDB將分片服務器內部數據分為chunks,不同chunk塊代表這個分片服務器內部的部分數據,由指定片鍵的某一連續范圍內的文檔組成。當chunk塊過大時,MongoDB后臺進程會計算每個chunk塊的大小并選擇拆分點,根據拆分點將該chunk塊切分成更小的chunk塊,避免chunk塊過大的情況[11]。在MongoDB中,負責數據遷移的工具就是均衡器(balancer),balancer是一個后臺進程,負責chunk塊的遷移,從而均衡各個shard server的負載。拆分chunk塊最重要的兩點是選擇合適的拆分點和不同chunk塊所占用的空間基本相等。
2.2 負載均衡算法分析
隨著MongoDB中的數據越來越多,分片中chunk塊的數量也越來越多,每個分片服務器上chunk塊的個數也不相同,且差異越來越大。在MongoDB中,默認的負載均衡算法認為chunk塊數量相當即負載均衡。負載均衡的實現主要來自于其內部負載均衡器(balancer)進程的運行,均衡器周期性地檢查各分片,當分片間chunk塊的數量差到達遷移閾值(默認為8),均衡器啟動自動數據遷移,將數據從包含最多chunk塊的片上遷移到chunk塊最少的片上,直到chunk塊的數量差不大于2為止[12]。數據遷移以chunk塊為單位進行遷移,最初默認大小為64 M,但隨著數據量的逐漸增大,最終每個塊的數據量會達到200 M[13]。
通過閱讀源碼并對源碼進行分析,MongoDB負載均衡算法的流程如圖3所示。
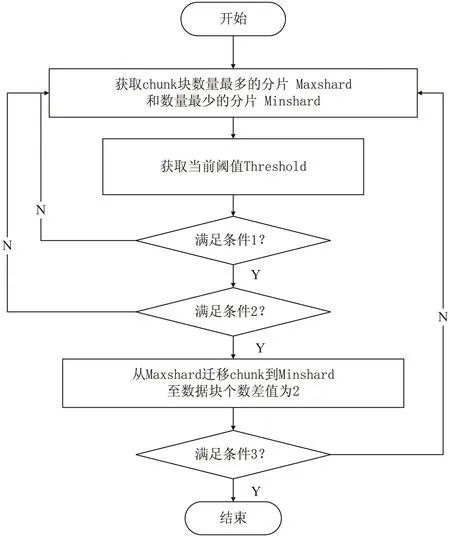
圖3 負載均衡算法流程
條件1:Minshard未達存儲上限且不存在寫回隊列;
條件2:Maxshard-Minshard>=Threshold;
條件3:負載均衡器仍然開啟。
2.3 負載均衡算法的爭議
一直以來,MongoDB的負載均衡算法在實際應用中仍然存在許多問題。這個均衡器只考慮了數據的存儲平衡,而沒有考慮負載平衡[14]。節點的負載取決于其配置及接受任務的輕重,盡管分片節點上的chunk塊數量相同,但在選擇目標分片時,沒有考慮分片節點上的負載不相同這一問題,因此得到的結果也可能不是最好的,所以很有必要對MongoDB的負載均衡算法進行改進。
3 基于節點實時負載的負載均衡算法
3.1 基于節點的均衡算法思想
通過前面的分析了解到MongoDB的負載均衡算法并不是十分完善,因此文中在原始算法的基礎上提出一種基于節點實時負載的負載均衡算法。改進的算法將節點的實時負載情況作為判斷條件,在節點上增加負載代理,在負載均衡器上增加負載監視器,通過負載代理監測各節點的負載情況并將數據發送給負載監視器,均衡器將節點負載指數作為確定源分片和目的分片的一個指標。
將節點i的負載代理檢測到的CPU占有率、內存使用率以及網絡帶寬占有率分別記為Ci、Mi以及Ni,CPU、內存和網絡帶寬的權值分別設為i1、i2和i3,則節點i的負載指數Iload可表示為:
Iload=i1×Ci+i2×Mi+i3×Ni
(1)
i1+i2+i3=1
(2)
假設自動分片集群架構中有n個分片,則平均負載Aveload為:
(3)
最大的節點負載為Maxload,設定閾值γ(一般默認為8),若
Maxload-Aveload≥γ
(4)
則此節點過載。改進的基于節點的均衡算法在均衡chunk塊數量的同時,還均衡了分片節點上的負載,可以有效提升原算法的性能,解決數據分布不均的問題[15]。
3.2 基于節點的均衡算法設計
基于節點實時負載的負載均衡算法具體設計如下:
(1)負載代理周期性地遍歷各分片,獲取節點負載信息并發送給負載監視器。
(2)負載監視器計算出平均負載,確定負載最大的分片、chunk塊數最多的分片和存儲即將超過上限的待移除分片,將既不是待移除分片且chunk塊數也不是最多的分片列入最小分片的候選列表。
(3)若分片塊數差超過設定閾值,則確定源分片為chunk塊數最多的分片;若分片塊數差滿足條件,但存在待移除分片,則確定源分片為待移除分片;若前兩個條件都不滿足但根據式(4)計算得出存在過載分片,則源分片為負載最大的分片;若以上條件都不滿足,則不需要遷移。
算法流程如圖4所示。

圖4 基于節點實時負載的負載均衡算法流程
4 算法性能評估
4.1 測試環境
測試環境基于MongoDB的自動分片集群,由3臺機器構成,每臺機器內存都為4 GB,操作系統為Linux Redhat,MongoDB版本為3.4.0。集群包含3個分片,每個分片由一個副本集組成,每個副本集包含1個primary節點,2個secondary節點和1個arbiter節點。結合實際運行情況,設置CPU占有率和內存使用率權重占比較大,網絡帶寬占有率權重較小,i1、i2和i3分別為0.2、0.7和0.1,閾值γ設置為13%。
4.2 平臺搭建
(1)配置副本集。
> cfg={_id:“shard1”,members:[{_id:0,host:“192.168.169.128:40007”},
{_id:0,host:“192.168.169.128:40007”},
{_id:0,host:“192.168.169.128:40007”}]}
> rs.initiate(cfg);
(2)配置Config Server。
mongod --configsvr --dbpath=/home/mongod/data/mongo.conf
(3)配置Mongos。
mongos -f /home/mongod/mongos/mongo.conf
(4)配置Shard。
>db.runCommand({addshard“shard1/192.168.148.61:40007,192.168.148.63:40007,192.168.148.65:40007”})
4.3 算法測試結果
首先,測試集群的并發寫入功能。為了保證數據總量相等,均插入一百萬條數據,在不同并發數下,新舊算法每秒可寫入的數據記錄如表1所示。
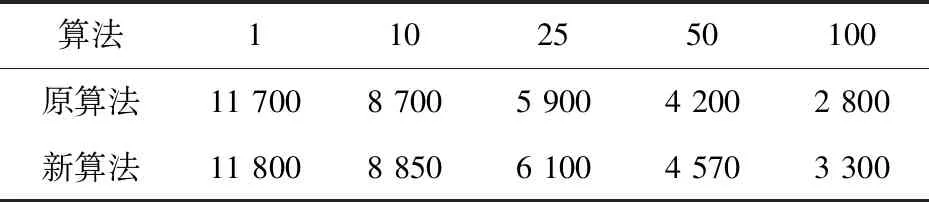
表1 新舊算法并發寫入性能數據統計
在并發數和記錄不變的情況下,測試集群的并發讀取性能,新舊算法每秒讀取的數據記錄如表2所示。
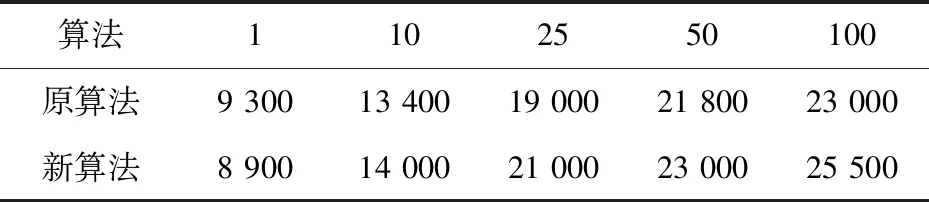
表2 新舊算法并發讀取性能數據統計
從實驗數據結果可以看出,在并發數較小的時候,新算法的讀寫性能并沒有明顯優于原算法,甚至可能會低于原算法,但隨著并發數的增加,新算法明顯優于原算法。這是因為改進的基于節點實時負載的負載均衡算法將節點負載作為一個考慮條件,當數據量不夠大時,計算節點的負載情況資源利用率低,影響了系統性能,而在大數據及大并發的情況下,應用新算法之后的讀寫性能明顯優于原算法,提高了集群的并發讀寫能力。
5 結束語
首先介紹了MongoDB自動分片的原理,然后分析了其負載均衡算法的缺點,針對分片間分配數據不均勻的問題,提出了一種基于節點實時負載的負載均衡算法。接著搭建了測試環境,針對數據的并發讀寫性能與原算法做一個對比實驗,通過實驗得出,該算法在數據的讀寫均衡上得到了明顯優化,提高了集群的并發讀寫性能,證明了算法的有效性。
猜你喜歡
財經(2017年15期)2017-07-03 22:40:49
財經(2017年2期)2017-03-10 14:35:35
華東師范大學學報(自然科學版)(2017年1期)2017-02-27 13:41:08
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
財經(2015年3期)2015-06-09 17:41:31
財經(2014年21期)2014-08-18 01:50:18
財經(2014年6期)2014-03-12 08:28:19
財經(2013年6期)2013-04-29 17:59:30
