基于時段-時長耦合LDA的用戶收視行為挖掘
2020-04-18 13:14:56顧軍華李曉雪
計算機應用與軟件 2020年4期
顧軍華 李曉雪 楊 亮
1(河北工業大學人工智能與數據科學學院 天津 300401)2(河北省大數據計算重點實驗室 天津 300401)3(河北工業大學電子信息工程學院 天津 300401)
0 引 言
IPTV[1]是隨著互聯網發展出現的一種嶄新技術。IPTV利用寬帶網將多媒體信息傳遞給用戶,為用戶提供包括數字電視在內的多種交互式服務。它在傳統電視的基礎上,加入點播、回看等交互功能,使得電視觀眾與電視服務提供商之間有了更好的互動。為了給用戶提供更好的收視服務,電視服務提供商可以通過大數據分析用戶行為,為用戶建模。IPTV用戶行為建模可以通過分析用戶行為來優化網絡規劃,進而提升IPTV系統的性能[2-3];可以通過挖掘用戶收視興趣,給IPTV用戶提供諸如個性化電子菜單、節目推薦[4-5]、個性化情景廣告[6]等服務,以此提升用戶收視體驗。
現有的用戶收視行為建模方法大致可以分為兩類。一類是通過適當抽象節目類別信息,將收看節目歸納為不同類型,從而建立用戶興趣模型[7]。其中,AIMED模型[8]是一種利用人工神經網絡技術結合用戶的活動、興趣和心情等屬性構建的推薦模型,該模型可以預測用戶對電視節目的偏好。另一類方法是基于主題模型LDA[9]算法的改進。例如,隱式反饋LDA模型[10]結合IPTV用戶收視過程中的點播、收藏和瀏覽等行為,采用LDA聯合建模為用戶做推薦。TMUD模型[11]將兩個LDA模型通過主題連接成為一個統一的模型,用于相似用戶群分組和電視節目推薦。考慮到一個IPTV用戶對應一個家庭,不同的家庭成員會在不同時段觀看節目,張婭等[12]提出基于時間耦合主題模型(cLDA)的IPTV用戶建模方法,該模型通過對用戶收視節目與收視時間點的聯合建模,挖掘IPTV用戶在每個時段的收視興趣主題。
以上基于LDA模型的改進算法在用戶行為建模方面取得了良好的效果,但這些方法忽略了對節目觀看時長的利用,而節目的觀看時長在很大程度上反映用戶對節目的喜愛程度。基于此,本文提出一個新的時段-時長耦合LDA(Time-Duratioan Coupled LDA)模型。TDC-LDA模型是一個概率生成模型,其中用戶興趣主題和收視時段隱變量可同時生成收視記錄中的所看節目、觀看時間點與時長。每一個IPTV用戶可以用一個時段-興趣主題的聯合分布來表示,稱之為用戶行為模式。
1 LDA模型
LDA是Blei等學者于2003年提出的一種基于概率模型的文本主題建模方法,可以識別龐大文檔集或語料庫中的隱藏主題信息,被廣泛應用于信息檢索、自然語言處理等領域[13~15]。LDA的圖模型如圖1所示,該模型假設文章是由多個主題以不同比例混合而成,每個主題可以用多個詞的概率分布表示,文章中的每一個詞都是由一個潛在主題生成。
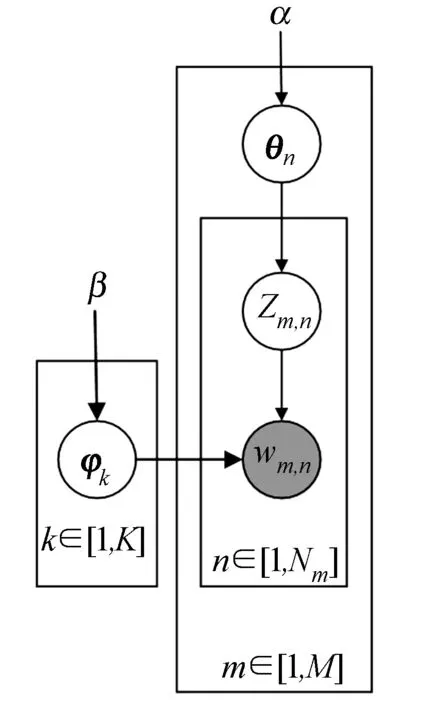
圖1 LDA概率圖模型
用LDA模型挖掘用戶收視興趣的原理如下:
將一個IPTV用戶的觀看記錄當成一篇文檔,IPTV用戶觀看的電視節目當成文檔中的詞。假設IPTV用戶在觀看節目時有多個收視興趣主題,興趣主題可以表示為一些電視節目的分布,那么用戶m從大量IPTV數據中選擇觀看節目的生成過程可以描述如下:
(3) 對于第m個用戶中的任意一個收視紀錄n,其中n∈{1,2,…,Nm}:
① 根據興趣主題的多項式分布,選擇一個主題zm,n~Multinomial(θm);
② 根據選擇出的主題對應的電視節目多項式分布,生成電視節目wm,n~Multinomial(φzm,n)。
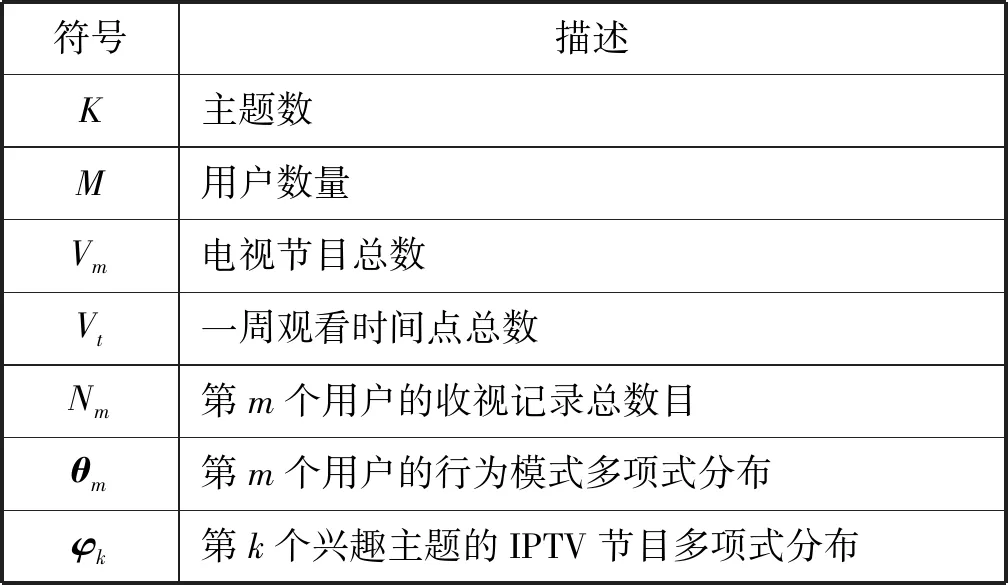
表1 論文中用到的符號
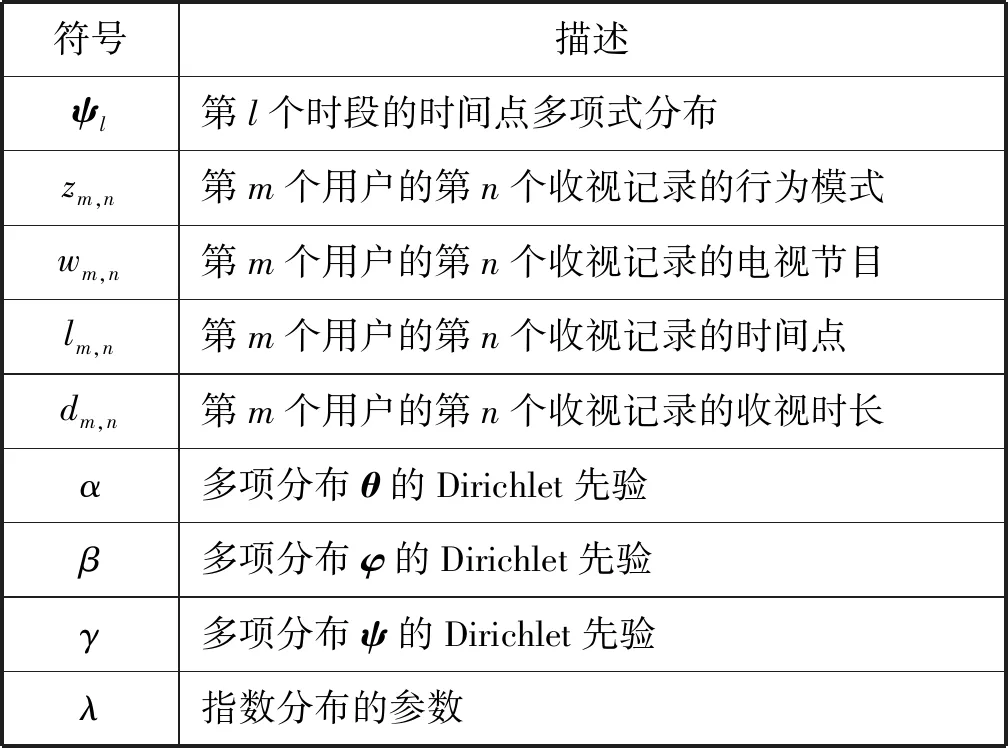
續表1
LDA模型能捕捉到IPTV用戶的收視興趣分布,但是用于IPTV用戶行為模式挖掘有較多的缺陷。第一,一個IPTV用戶對應一個家庭,一個家庭由不同的成員組成。LDA模型只能挖掘到一個家庭的收視興趣,但無法挖掘到每個家庭成員的興趣。第二,家庭成員可能選擇在不同的時段觀看電視,因此一個IPTV用戶在不同時段的興趣愛好可能會不相同。比如:兒童在放學后喜歡觀看動畫片,爺爺奶奶喜歡在下午觀看戲曲類節目,年輕人喜歡在晚上觀看各類娛樂節目。LDA模型無法挖掘到用戶在不同時段的收視興趣。第三,用戶在觀看電視節目時,對每個節目的觀看時長不盡相同,而觀看時長是體現用戶收視興趣的重要因素,LDA無法刻畫收視興趣主題隨觀看時長的變化。
2 TDC-LDA模型
為了更好地挖掘用戶行為模式,對IPTV電視節目每周的收視周期性展開研究。本文使用的IPTV數據由天津電視臺IPTV運營商提供,用戶收視歷史數據由服務器端收集用戶的操作記錄形成。圖2展示了一部動畫節目、一部愛情劇和一檔綜藝節目在兩周內的收視曲線,其中橫坐標記錄了每周周一的起始時間,觀看次數以四小時為間隔進行統計,縱坐標記錄了每個節目一小時的播放次數。該曲線有較強的周期性,其周期為一周。假設同一類節目會在固定的時段被收看,不同家庭成員看電視的時段不同,在同一時段用戶傾向于觀看同一類型的節目,用戶對節目的觀看時長體現了他對節目的喜愛程度。基于上述假設,IPTV用戶觀看行為有如下幾個特點:
(1) 一個IPTV用戶有一個或多個成員;
(2) 每個成員有多種不同的收視興趣;
(3) 每個成員傾向于在每周的特定時段看電視;
(4) 用戶對某個節目的觀看時長越長,則對這個節目的喜愛程度越高。
基于上述分析,本文將LDA模型中的興趣主題分布θm擴展為表示用戶收視興趣、時段與時長的行為模式分布,建立TDC-LDA模型。表2是LDA模型推廣到TDC-LDA模型后θm的變化。在LDA模型中,每個IPTV用戶的興趣主題分布不區分時段。而TDC-LDA模型中,每個IPTV用戶會因時段的不同而有不同的興趣主題分布,且興趣主題分布受觀看時長影響。
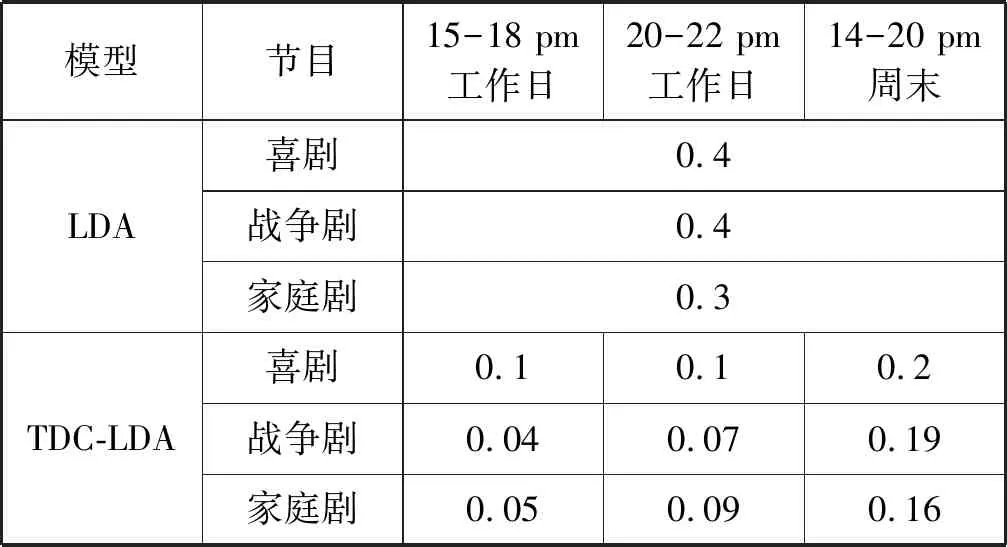
表2 主題分布向量θm
值得說明的是,本文中的時間點服從多項式分布而不是連續分布。在基于時間的主題模型TOT[16]中,時間為連續分布,它可以在很長的非周期性時間跨度內生成單峰時間分布,但很難描述如圖2所示的具有周期性和多峰的分布。多項式分布可以輕松地將時間點聚合在一起,生成時段,如“工作日早晨”、“周末午夜”等。因此,時段對應的時間點由多項式分布生成。
2.1 模型生成
TDC-LDA模型是一個概率生成模型,它是對LDA模型的拓展,模型如圖3所示。假設有K個興趣主題,Vm個不同的電視節目,興趣主題對應的電視節目多項式分布描述成K×Vm維的矩陣Φ,φk,vw是節目vm屬于主題k的概率。同樣,假設有L個時段(時段指一些特定的時間區間,例如,工作日17:00-19:00),Vt個不同的時間點。時段對應的時間點多項式分布描述成L×Vt的矩陣Ψ,ψl,vt是時間點vt屬于時段l的概率。
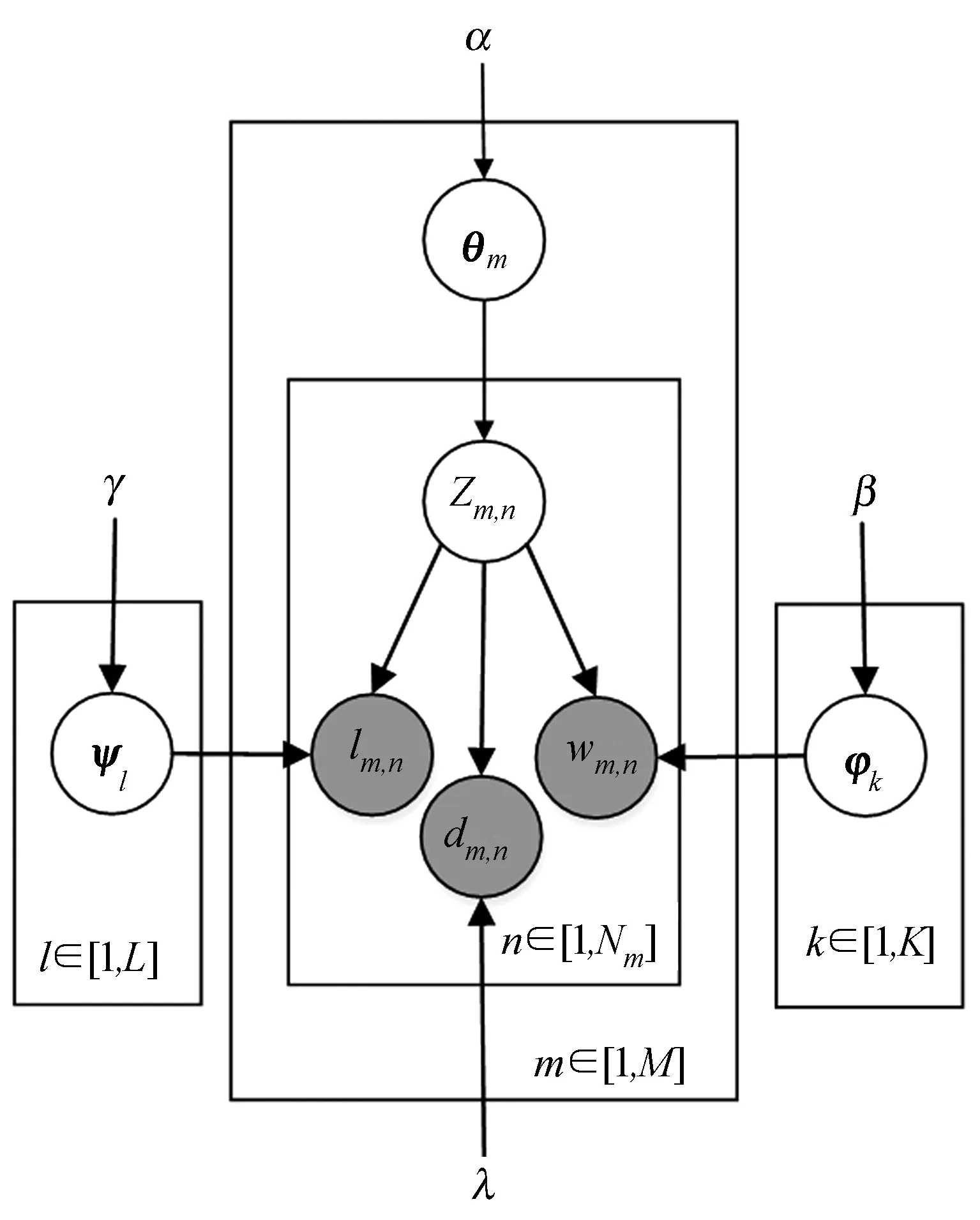
圖3 TDC-LDA概率圖模型
每一個IPTV用戶對應一個描述興趣主題、時段與觀看時長的多項式分布,用戶收看的節目、觀看時間點以及觀看時長為該用戶的行為模式。具體來講,行為模式是指用戶選擇在哪個時段收看哪種類型的節目以及其收看時長,其中用戶對節目的觀看時長體現了他對這個節目的喜愛程度。把K×L維的行為模式矩陣分解成KL維的向量θm。θm中第z項代表一個IPTV用戶在zm,n,1時段選擇興趣主題zm,n,2這個行為并且觀看時長為dm,n的概率。其中zm,n,1、zm,n,2的計算公式如下:
(1)
對于用戶m,用TDC-LDA模型選擇觀看時間點、觀看節目與觀看時長的過程如下所示:
(2) 根據Dirichlet分布選擇時段的時間點分布ψl~Dir(γ),其中l∈{1,2,…,L}:
(4) 對于m用戶中每一個收視紀錄n,其中n∈{1,2,…,Nm}:
① 根據該用戶的行為模式多項式分布,選擇一個行為模式zm,n~Multinomial(θm);
② 根據選擇的行為模式對應的時段找到這個時段生成時間點的多項式分布,然后根據時段對應的時間點分布生成時間點tm,n~Multinomial(ψzm,n,1);
③ 根據選擇的行為模式對應的興趣主題找到這個主題生成電視節目的多項式分布,然后根據主題對應的電視節目分布生成電視節目wm,n~Multinomial(φzm,n,2);
(2)
2.2 模型擬合
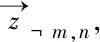
(3)
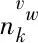

(4)
同理,對興趣主題-電視節目分布矩陣Φ和時段-時間點分布矩陣Ψ有如下公式:
p(φk|z,w,β)=Dirichlet(φk|nk+β)
(5)
p(ψl|z,t,γ)=Dirichlet(ψl|nl+γ)
(6)
通過對上述Dirichlet分布的期望求解,得到:
(7)
(8)
(9)
TDC-LDA模型的Gibbs采樣過程如算法1所示。
算法1TDC-LDA算法
輸入:用戶收視數據、K(興趣主題數)、L(時段數)、α、β、γ、Niter(迭代次數)
輸出:用戶-行為模式分布矩陣Θ、興趣主題-電視節目分布矩陣Φ和時段-時間點分布矩陣Ψ
00:%初始化
02:for 每一個用戶m∈{1,2,…,M} do
03: for 用戶m中每一個觀看行為n∈{1,2,…,Nm} do
05: 根據采樣的zm,n用式(1)求得興趣主題索引k和時段主題索引l
07: end for
08: end for
09: %Gibbs采樣
10: foriter=1 toNiterdo
11: for每一個用戶m∈{1,2,…,M} do
12: for用戶m中每一個觀看行為n∈{1,2,…,Nm} do
13: %對于當前行為模式zm,n=i
18: end for
19: end for
21: end for
22: 根據式(7)-式(9)計算Θ、Φ、Ψ
3 實 驗
本節主要介紹實驗中使用的數據集并分析TDC-LDA模型的實驗結果。實驗中,α、β、γ設置為0.1。首先,對比TDC-LDA、cLDA與LDA模型在挖掘興趣主題與時段方面的不同,驗證TDC-LDA模型的優勢。然后,對同一節目不同觀看時長的用戶群體的興趣主題分布求平均,通過對比不同用戶群體的興趣主題分布展現了TDC-LDA模型挖掘到的興趣主題隨觀看時長增加而遞增的特性。通過分析一個兒童與主婦主導型家庭的觀看數據與實驗結果的吻合度來證實該模型的有效性。最后,分別用LDA、cLDA與TDC-LDA模型為用戶推薦節目,通過計算困惑度,證明TDC-LDA在執行推薦任務上有更高的準確度。
3.1 實驗數據集
實驗中使用的IPTV數據由天津電視臺IPTV運營商提供。服務器端收集用戶的操作記錄形成IPTV用戶收視歷史數據。整個數據集包含2 480個用戶,7 857個電視節目,同一個電視節目中的不同集數視為同一個節目。本文僅提取用戶的觀看節目名稱、觀看時間點、觀看時長等信息。表3展示了一些用戶的觀看記錄樣例,每一條記錄包含用戶ID、節目的開始時間點、節目名稱和觀看時長。本文將時間點改成“星期-時”的形式,不同的時間點Vt總共是7×24個。只保留觀看時長超過3分鐘的觀看記錄(節目的平均觀看時長是35分鐘)。換句話說,如果用戶相鄰觀看記錄之間的時間間隔小于三分鐘,則刪除上一個觀看記錄。通過對數據的處理,最終得到2 447個用戶從2014年12月到2015年2月在5 925個節目上的106 599 085條觀看記錄。
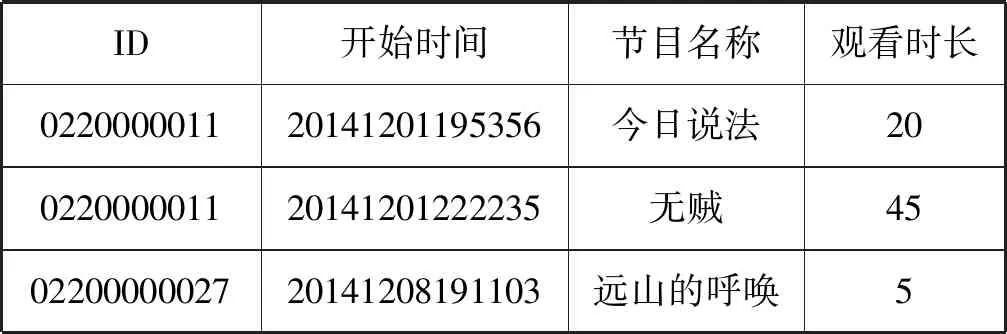
表3 IPTV用戶觀看行為記錄樣例
3.2 興趣主題與時段挖掘
本節根據LDA、cLDA、TDC-LDA模型在實驗數據集上運行的結果,分析三個不同模型在興趣主題發現與時段挖掘上的異同。實驗中根據經驗將每一個模型的興趣主題K設為50,cLDA與TDC-LDA的時段L設為8。
3.2.1興趣主題挖掘
三種模型得到的興趣主題基本都是由一些相關性比較強的節目以不同比例混合而成,如表4所示。但是不同模型中相同主題的電視節目分布不同。由于LDA與cLDA模型得到的結果基本一致,所以只分析TDC-LDA模型與cLDA模型的不同。
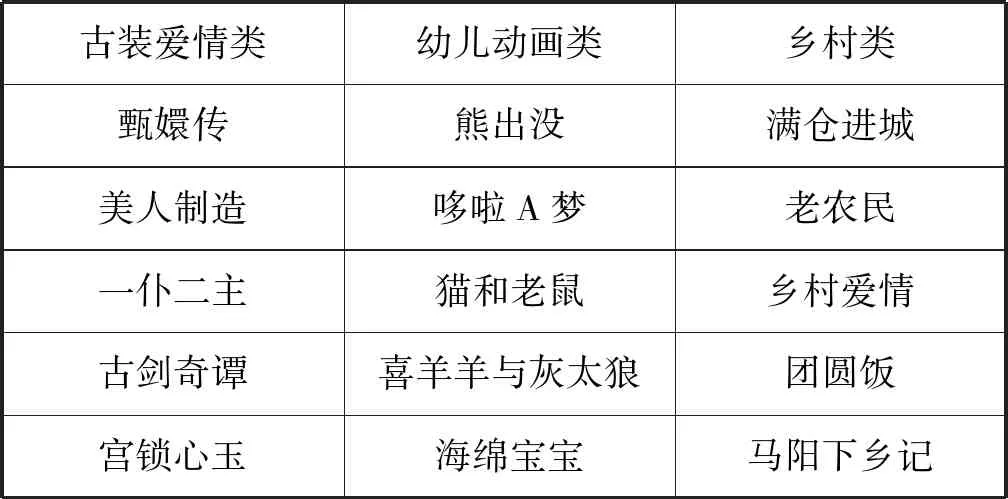
表4 興趣主題對應的節目
為了證明TDC-LDA模型加入觀看時長后挖掘到的興趣主題分布與真實情況更加接近,先對IPTV數據中所有電視節目的觀看總時長與觀看總次數做統計。然后通過古裝愛情這一興趣主題的節目分布來對比兩種模型挖掘到的興趣主題的不同。表5是一些古裝愛情類電視節目的觀看總次數與觀看總時長的統計數據,表6列出了兩個模型挖掘到的古裝愛情主題的電視節目分布。
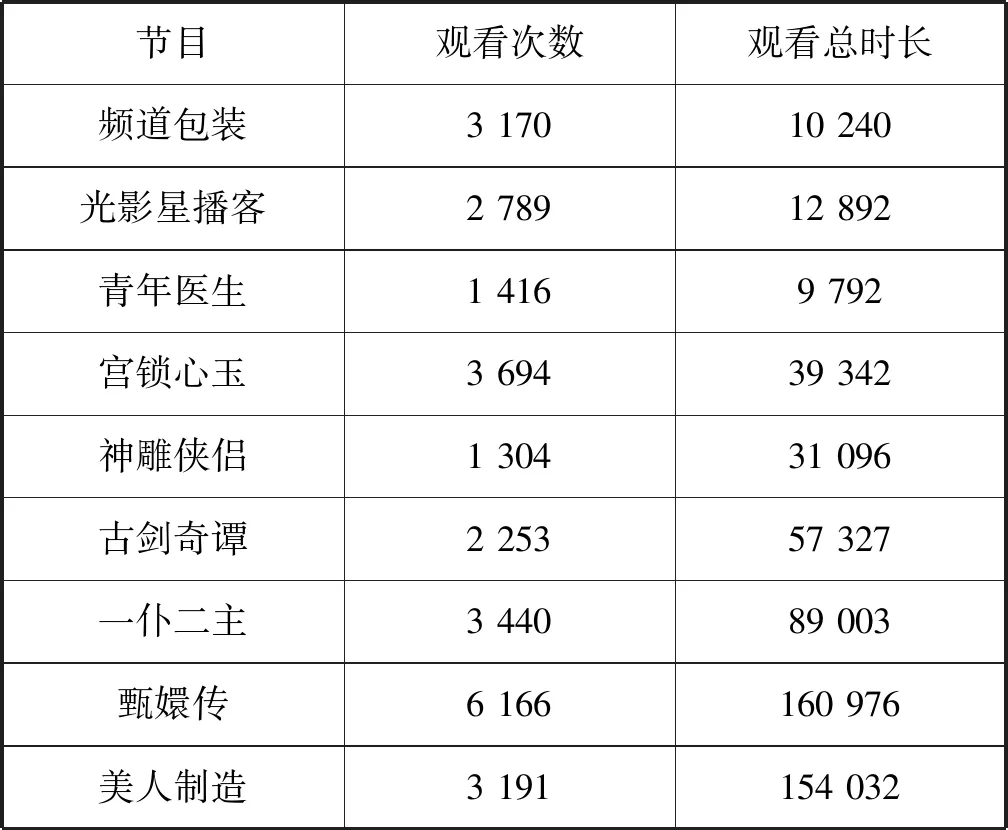
表5 電視節目的觀看總次數與觀看總時長
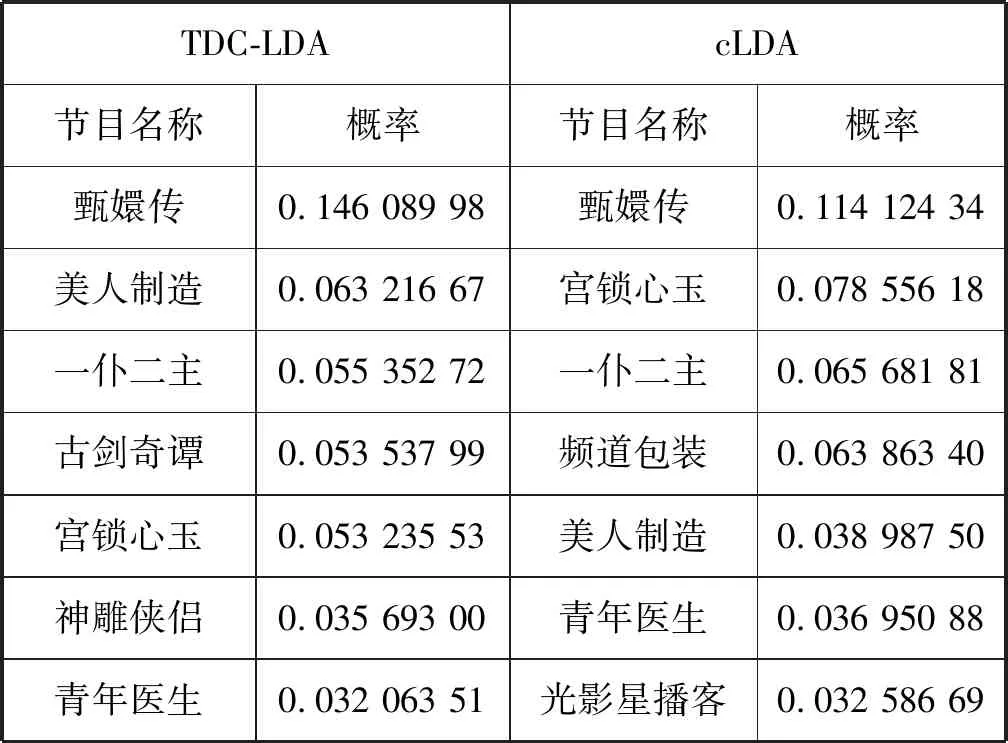
表6 兩種模型中古裝愛情主題的電視節目分布
由表6可以看出,兩個模型在古裝愛情這一興趣主題里包含的主導電視節目基本一致,但每個節目所占的比率不同。通過表5中電視節目的觀看次數與觀看時長可以看出,“甄嬛傳”“美人制造”“一仆二主”等節目更受歡迎,在該主題下應有更高的概率,這與TDC-LDA模型得出的結果基本一致。而cLDA模型本身不考慮觀看時長,興趣主題的節目分布與實際情況有出入。此外,cLDA模型在該主題下還出現一些不相關的節目,如“頻道包裝”,且占有較高的概率。
3.2.2時段的挖掘
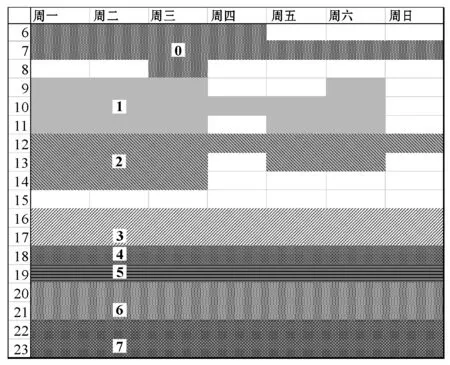
由TDC-LDA和cLDA產生的時間點信息如圖4所示。圖中將一周的時間點總共分為8個時段,用序號“0-7”來標記,相同時段的時間點用同種填充圖案標記。
(a) TDC-LDA時段行為模式

(b) cLDA時段行為模式圖4 TDC-LDA與cLDA的時段行為模式
從圖4中可以清楚地看出,一周的時間點被劃分為上午、下午、晚上等時段。時段的劃分完全由TDC-LDA與cLDA模型根據用戶收視記錄挖掘得到,沒有加入任何先驗信息。工作日的18時被單獨劃分出來,是因為通常學生在18時放學到家,開始看電視。LDA中沒有時間點因素,在此不作比較。cLDA和TDC-LDA都可以將一周中的時間點劃分為不同時段且基本合理,但是根據對IPTV數據的統計分析可以證明,TDC-LDA模型挖掘到的時段信息與實際情況更貼近一些。第一,經過統計發現,早上6時至8時之間是新聞類節目的收視高峰期,并且在周末的時候人們傾向于晚起;第二,18時是動畫類節目的收視高峰期;第三,19時也是一個看電視的高峰期,這時候用戶傾向于觀看一些新聞類的節目。
分析圖4可知,TDC-LDA對于早上新聞類節目收視高峰期的時段挖掘是準確的,而且可以將18時與19時兩個時段成功分開。cLDA對于這三個時段的挖掘并不準確,且時段2與時段1和時段3有交叉錯亂之處。
3.3 興趣主題隨觀看時長的變化
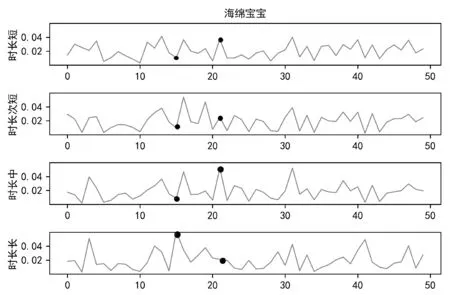
本節通過比較觀看時長不同的用戶群體的平均興趣主題分布,分析TDC-LDA與cLDA模型的興趣主題分布與觀看時長的關系。將每個電視節目的觀看用戶分為4類,分別為觀看該節目時長3~10分鐘、10~17分鐘、17~30分鐘以及觀看時長30分鐘以上的用戶,時長類別簡記為短、次短、中、長。用實驗得出的θm來描述每個用戶,通過對每類用戶的θm求平均,并用圖5所示的方式展現出來(圖中為電視節目“海綿寶寶”所對應的4類用戶的平均興趣主題分布,TDC-LDA中的θm消除時段的影響,從400維折合到50維,即50個興趣主題上。興趣主題15與興趣主題21用黑色圓點進行標記)。
(a) LDA
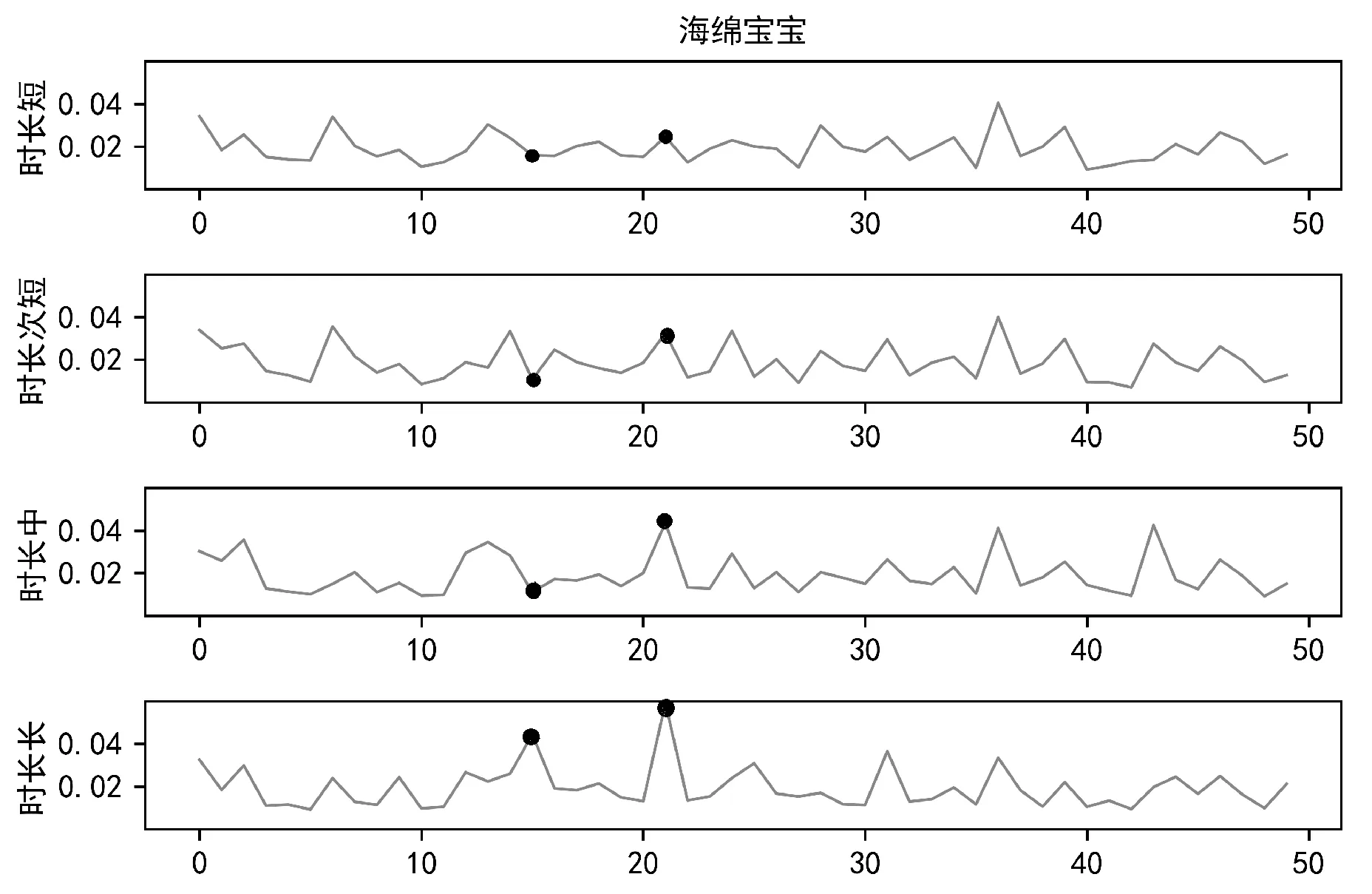
(b) TDC-LDA圖5 兩種模型中不同用戶群體的平均興趣主題分布
實驗中,僅保留滿足以下兩個條件的節目:第一,通過用戶對該節目觀看時長的不同,使用上面的分類方式將用戶分為4類群體;第二,該節目至少被20個以上的用戶收看。通過前面條件的過濾,得到899個節目中不同用戶群體的興趣主題分布。從一些節目中可以比較明顯地看出,TDC-LDA擬合效果與實際更相符。
根據圖5分析,隨著用戶對節目觀看時長的增加,其興趣主題分布的變化。假設用戶觀看某個節目的時長越長,則對這個節目的喜好程度越高,那么第四組用戶的平均興趣主題分布和真實數據應該最接近。
表7列出了興趣主題15和興趣主題21的一部分電視節目分布,由表可知,“海綿寶寶”屬于興趣主題21,是一部動畫類節目。從圖5可以看出,在LDA模型中,4類用戶在主題21上有著大小不一的概率,每一類用戶對某個興趣主題的喜愛程度沒有一個確切的規律。而在TDC-LDA模型中,隨著用戶觀看時長的增加,興趣主題21的概率逐漸增長,尤其是第4類用戶,觀看興趣比較明顯,偏向于興趣主題15與興趣主題21。興趣主題21是動畫類主題,其中“海綿寶寶”在該主題下概率最高,興趣主題15是動畫片與娛樂類主題。通過分析可知,TDC-LDA可以準確地挖掘到興趣主題分布隨觀看時長的變化,這與實際情況相符。
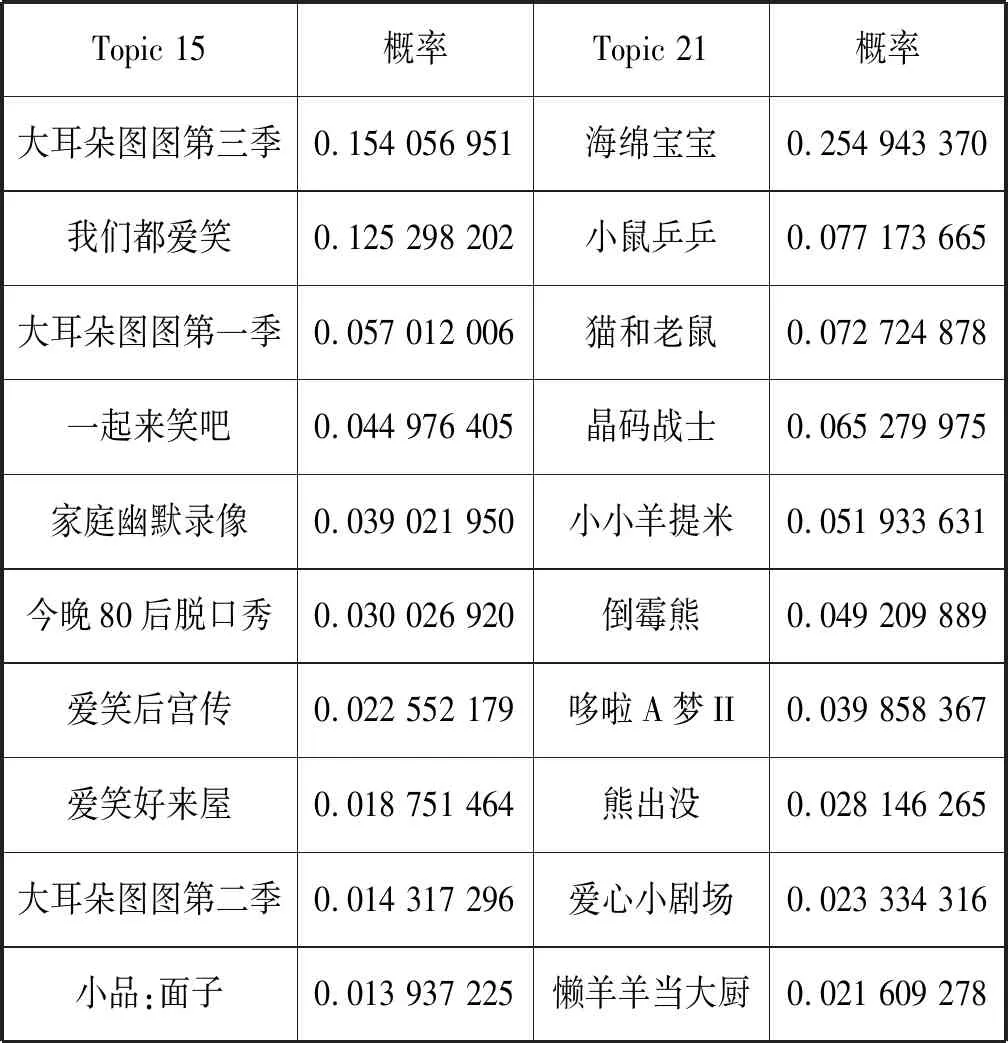
表7 兩個動畫類主題的電視節目分布
3.4 案例分析
前面已經對TDC-LDA在挖掘興趣主題與時段方面的優勢做了詳細論述。本節通過一個具體用戶(記為M)的觀看數據與模型實驗結果,對比TDC-LDA與cLDA模型在挖掘用戶行為模式上的優劣。表8列出了用戶M用TDC-LDA模型生成的用戶行為模式,表中的時段與圖3(a)中標注的時段相同,只列出了三種概率最高的行為模式。表9分別列出了用TDC-LDA與cLDA模型挖掘到的三個概率最高的興趣主題概率分布(為方便進行比較,對每個興趣主題上不同時段的概率值進行加和,得到用戶的興趣主題概率分布)。圖6展示了用戶M平時觀看最多的5個節目以及每個節目的觀看次數和觀看時長(其中時長按十分鐘一個單位統計)。
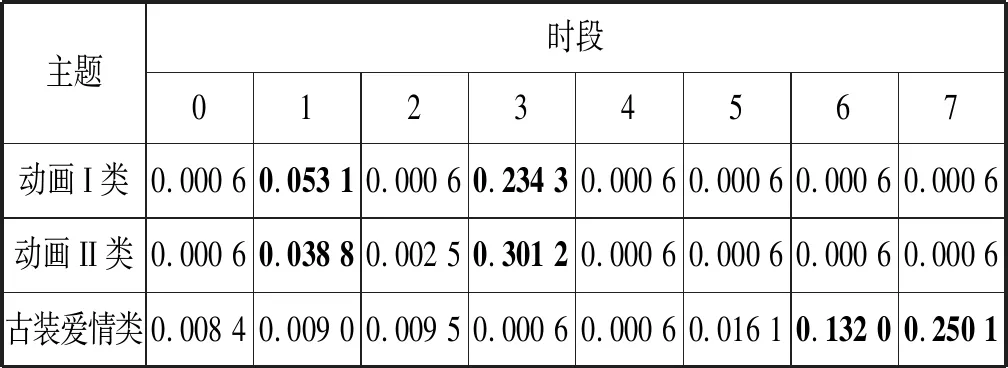
表8 TDC-LDA生成的行為模式
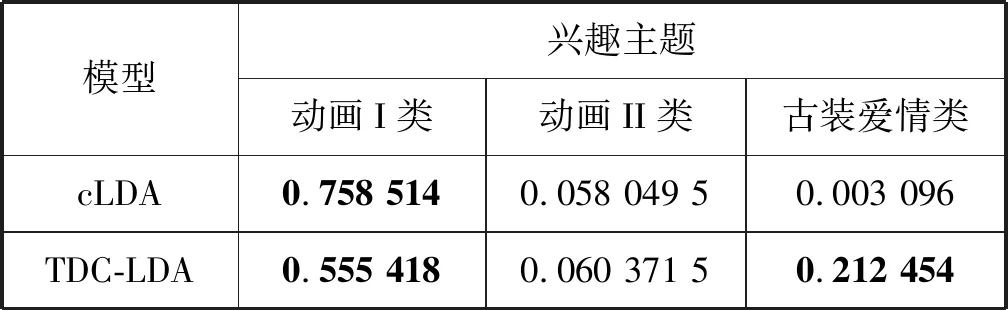
表9 用戶M的興趣主題概率分布
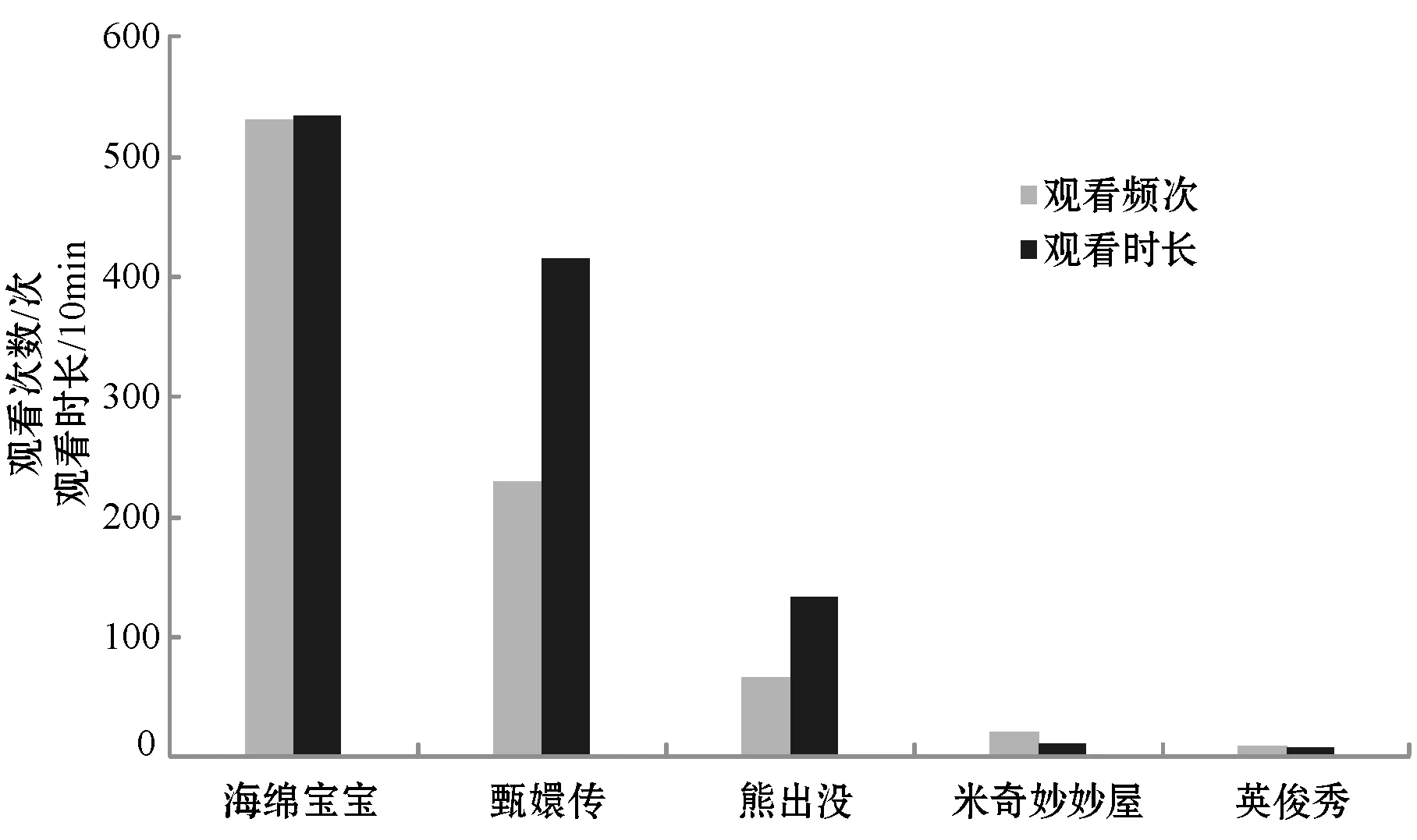
圖6 用戶M觀看最多的5個節目的觀看次數與時長
分析圖6可知用戶M是一個以兒童與家庭主婦主導收視興趣的混合型家庭,觀看的主要節目是動畫類節目與古裝愛情類節目,其中動畫類節目為主,古裝愛情類節目為輔。由表8可知,該用戶傾向于在16時至17時收看動畫類節目,在20時至23時收看古裝愛情類節目。由表9可知,cLDA只挖掘到用戶M的動畫I類興趣主題,并且該主題占有很高的概率,成為絕對主導主題。TDC-LDA模型中,用戶的收視興趣在動畫I類與古裝愛情類主題上都占有較高的概率。由圖6用戶觀看節目的統計數據可知,“甄嬛傳”這個節目有較高的收視時長,但是觀看的次數相對少一些,可能導致cLDA模型無法準確地挖掘到用戶對這一類節目主題的喜好。圖7按照觀看頻次與觀看時長分別對用戶觀看興趣分布進行研究,然后給出兩個模型的用戶興趣主題分布實驗結果。圖7(b)是通過統計得到的用戶真實的興趣主題分布,可以明顯地看出,TDC-LDA挖掘到的用戶興趣主題更接近實際情況。
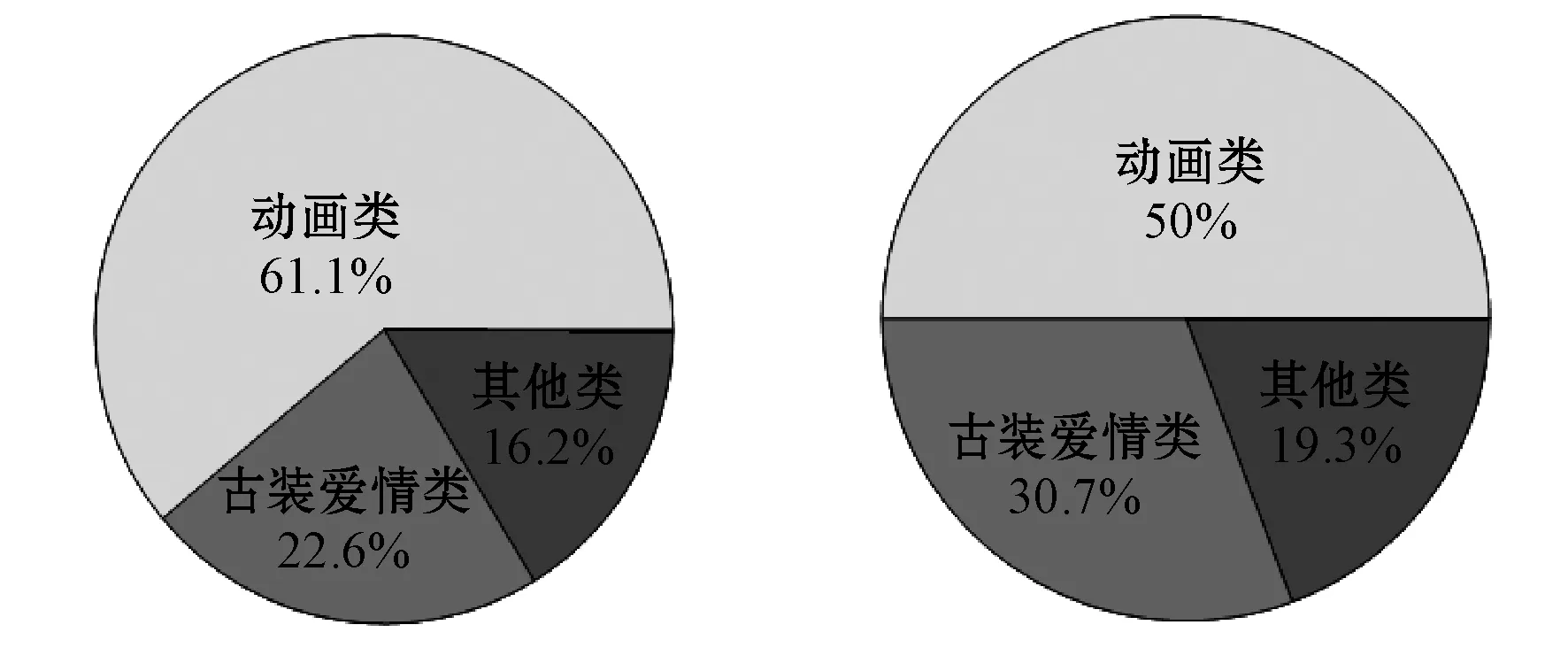
(a) 觀看頻次結果 (b) 觀看時長結果
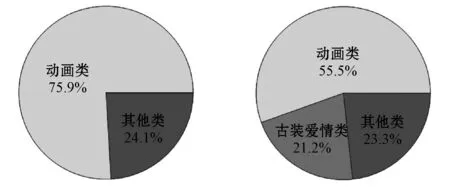
(c) cLDA模型結果 (d) TDC-LDA模型結果圖7 四種方式得到的用戶興趣主題分布
現實生活中,兒童的觀看行為與成年人不太相同。第一,兒童觀看的節目類型時長普遍較短,而成年人觀看的節目時長較長,尤其一些紀錄片、綜藝類節目。第二,兒童不太容易集中注意力去有始有終地觀看一個節目,成年人一般有自己固定的收視規律與喜好,每次觀看時長較長。根據這些分析,cLDA中單單考慮觀看次數來衡量用戶對某個興趣主題的喜好是不太準確的。由此可見,TDC-LDA模型中引入觀看時長這一項是非常必要和有效的。
3.5 困惑度分析
本節用時段-時長耦合LDA模型在數據集上執行推薦任務,并計算LDA、cLDA、TDC-LDA模型的預測困惑度(predictive-perplexity)。推薦任務的目標是預測IPTV用戶在特定的時段打開電視時會收看什么節目。實驗中,將IPTV用戶分為訓練集和測試集。訓練集包括每個用戶除最后一個收視行為記錄外的所有記錄。測試集由每個用戶的最后一個收視行為記錄構成。推薦任務要完成的是通過每一個用戶最后一個收視行為記錄的時間點來預測用戶收看的節目。預測困惑度指標定義如下:
predictive-perplexity(Dtest)=
(10)
式中:Mtest是測試集中用戶數目。困惑度越低表示模型泛化性能越好,推薦更準確。實驗中,令cLDA與TDC-LDA的時段L=8,通過將興趣主題K設置為不同的值來比較不同模型的困惑度,如表10所示。由表可知,TDC-LDA、cLDA、LDA模型的推薦效果依次降低。這說明,在挖掘用戶不同時段的收視興趣時加入用戶觀看時長信息是非常有必要的。
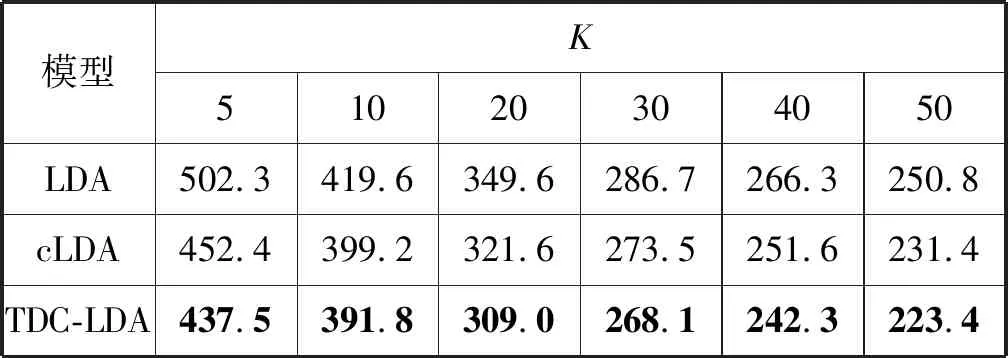
表10 預測困惑度
4 結 語
本文提出了一種全新的TDC-LDA模型。該模型的觀看節目與觀看時間點由Dirichlet分布生成,觀看時長由指數分布生成,通過Gibbs采樣對隱變量進行推斷進而得到用戶的興趣主題與收視時段分布,進而可以挖掘到用戶在不同時段的收視興趣。最后,在天津電視臺IPTV用戶數據集上進行驗證,實驗結果表明,TDC-LDA模型可以更加精確地挖掘到用戶的觀看興趣主題與收視時段信息,在IPTV節目推薦任務中,TDC-LDA模型也明顯優于cLDA模型。
雖然TDC-LDA模型考慮了用戶的觀看節目、觀看時間點、觀看時長等信息,但是IPTV用戶收視過程中還有很多其他信息,比如收藏、瀏覽、回看等。之后,我們將考慮通過融入各類用戶互動信息進一步提升模型的魯棒性和靈活性。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
商用汽車(2016年11期)2016-12-19 01:20:16
光學精密工程(2016年6期)2016-11-07 09:07:19
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
核科學與工程(2015年4期)2015-09-26 11:59:03
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
