面向股票交易分析場景的流式大數據系統測試框架①
2020-04-24 02:22:52史凌云鄭瑩瑩許利杰
計算機系統應用 2020年4期
關鍵詞:系統
史凌云,鄭瑩瑩,譚 勵,許利杰,王 偉,4,魏 峻,4
1(北京工商大學 計算機與信息工程學院,北京 100048)
2(中國科學院 軟件研究所,北京 100190)
3(中國科學院大學,北京 100049)
4(計算機科學國家重點實驗室,北京 100190)
引言
隨著信息時代的到來,互聯網、物聯網、云計算等技術的飛速發展和廣泛應用,數據在各個行業不斷地產生、積累并爆發式增長,已經成為一種重要的生產因素,并滲透到每一個行業和業務職能領域[1].大數據被喻為“未來的新石油”[2],已經成為社會各界關注的熱點,甚至成為各界爭奪的焦點,大數據時代已經到來.相較于傳統的數據,大數據具有數據規模大、數據類型多、數據處理速度快、數據價值密度低等特征,這些特征對大數據處理和應用提出了更高的要求和更大的挑戰.
目前對大數據處理的形式主要包括批式處理和流式處理[3].其中,批式處理是指對靜態有界數據的處理,對計算的實時性要求不高且應用場景廣泛,具有代表性的批量大數據處理系統有Apache Hadoop[4]和Apache Spark[5]等.但是,隨著社交網絡、電子商務等技術的飛速發展和應用,越來越多的應用場景要求從海量的數據中及時獲取價值,并以很低的延遲來分析實時數據.例如,以阿里巴巴為代表的電商平臺基于流式大數據處理系統實時統計和分析用戶行為,更新商品搜索引擎.因此,針對流式大數據的實時處理越來越流行,應用場景也越來越重要.流式大數據處理系統的地位日漸凸顯,在業界也已經有了非常廣泛的應用,常見的有Apache Strom[6]、Apache Flink[7]、Apache Spark Streaming[8]等.
流式數據本身的實時性、難重復以及動態變化等特性,以及流式數據計算所需的數據無限性、計算有界性、計算實時性等特征,對流式大數據處理系統的性能和可靠性提出了更高的要求.流式大數據處理系統需要提供低延遲的數據處理,同時保證計算的正確性.然而,隨著集群規模的擴大,系統發生故障的概率也會增大,無法預知的錯誤可能會隨時出現在任意一個節點.一旦大數據處理系統出現問題,可能會產生不可挽回的損失.因此,針對流式大數據處理系統及其基準測試框架的研究已經成為了一個熱點問題.
現今已有多種流式大數據基準測試框架,如Yahoo!Streaming Benchmark[9]和HiBench[10]等.但Yahoo!Streaming Benchmark 應用場景單一,覆蓋程度較低;HiBench 僅能夠支持簡單流式數據,本質仍是一個批式大數據基準測試框架.因此,現有流式大數據處理系統基準測試框架仍存在不足,比如應用場景的設計較為簡單,評價指標選取上較為單一,集中在吞吐量和延遲等.
針對現有流式大數據處理系統基準測試框架的不足和面臨的挑戰,本文設計并實現了一個股票交易場景下的流式大數據處理系統基準測試框架.該框架包括流式數據生成方法、應用場景構造和評價指標3 個部分,以Socket 作為流式數據源,選取真實的股票交易數據構造了三個數據流,具體應用覆蓋GroupBy 操作和Join 操作,并選取延遲、吞吐量、GC 時間和CPU利用率作為評價指標,構建了一個實時計算與結構化數據相結合的場景.此外,本文還針對數據輸入速率和執行器內核數量設計了兩個實驗,在Apache Spark Streaming 中對該框架進行實際的集群測試,對測試結果進行分析并得出結論,分析系統性能表現,同時發現大數據處理系統存在的問題,并分析瓶頸所在,從而盡大可能地減少實際運行過程中可能出現的故障.本文的主要貢獻如下:
(1)總結了現有流式大數據處理系統基準測試框架特點及其不足.
(2)提出了一種流式數據生成方法,并使用多種測試指標進行結果評測.
(3)設計并實現了一個基于股票交易場景的流式大數據處理系統基準測試框架.
(4)應用流式大數據處理系統基準測試框架對Apache Spark Streaming 進行性能測試,發現并分析系統的不足.
1 相關工作
不同于批式大數據處理,流式大數據處理起步較晚,目前在業內并沒有統一的基準測試標準.現有的流式大數據處理系統基準測試框架的相關研究如下.
Hesse 和Lorenz[11]從體系結構等方面對比了Apache Storm、Flink、Spark Streaming 和Samza platforms.Gradvohl 等人[12]從系統容錯方面分析對比了Google Millwheel[13]、Yahoo Apache S4[14]、Spark Streaming 和Storm.然而,這兩篇文獻僅限于概念性討論,沒有實驗性的定量性能評估.Nabi 等人[15]提出了一個基準測試,測量Apache Spark 和Apache Storm 的延遲和吞吐量,為流處理平臺的實驗比較創造了第一步.Dayarathna 和Suzumura[16]使用基準測試比較了3 個流處理系統的吞吐量、CPU 和內存消耗以及網絡使用情況.
此外,部分流式大數據處理系統的開發廠商選擇了自己認為有代表性、能驗證系統功能性的應用場景進行測試.如Yahoo!開發的分布式流計算平臺S4 選取了廣告點擊率計算(Click-Through Rate)進行性能驗證,以測試S4 處理流式數據的極限[2].Apache Storm 選取一個簡單的應用,統計了不同應用下參與的用戶數,并測試其在故障下的表現[17].Apache Spark Streaming 僅對Grep、WordCount、TopKCount 這3 個常見應用的吞吐量和故障恢復能力進行測試.應用場景簡單以及流式計算特征的覆蓋率低使得這些測試框架無法全面的剖析流式大數據處理系統所面臨的性能及可靠性問題.
現有的針對多種流式大數據處理系統的基準測試框架,其測試系統大多以Apache Storm、Apache Spark 和Apace Flink 為主.例如Lopez 等人[18]提出了一個針對Apache Storm、Apache Spark 和Apace Flink的基準測試框架,測試了3 個系統在節點故障情況下的吞吐量.Karimov 等人[19]提出了一個分布式流處理引擎基準測試框架,對Apache Storm、Apache Spark 和Apache Flink 的性能進行評估,并定義和測試流式大數據處理系統的可持續性能.由Yahoo!的一個團隊設計并實現的Yahoo! Streaming Benchmark 通過Kafka 和Redis 進行數據檢索和存儲,對Apache Storm、Apache Spark 和Apace Flink 進行實驗,測量了延遲和吞吐量[9].Perera 等人使用Yahoo! Streaming Benchmark 和Karamel[20]在云環境中提供Apache Spark 和Apache Flink 的可復制批處理和流基準[21].但Yahoo! Streaming Benchmark 在應用場景上覆蓋度較低,且只支持一個工作負載.
綜上所述,現有的流式大數據處理系統基準測試框架還存在各種不足,應用用場景設計較為簡單,評價指標選取上較為單一,集中在吞吐量和延遲.針對現有的流式大數據處理系統基準測試框架存在的不足,本文構造了股票高頻交易場景,并選擇延遲、吞吐量、GC 時間和CPU 利用率作為評價指標.
2 流式大數據系統基準測試框架設計與實現
本文基于流式大數據及其特征,設計并實現了一個流式大數據處理系統基準測試框架,包括流式數據生成方法、應用場景構造和評價指標.
通過流式數據生成方法,生成符合流式特征的股票交易數據;通過應用場景構造,構建一個股票交易場景用于系統測試;通過明確測試評價指標,收集并分析指標數據,從而分析系統性能并得出測試結論.基準測試系統架構圖如圖1 所示.
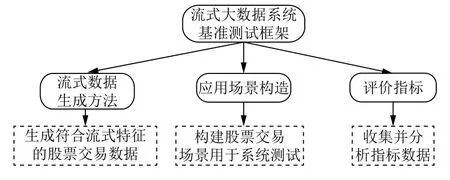
圖1 基準測試系統架構圖
2.1 流式數據生成方法
一般的批式大數據可以預先產生和存儲,使用方便.而由于流式計算的有界性和實時性等特點,數據生成需提供實時、高速的流式數據,從而通過測試發現系統的瓶頸,保證基準測試的有效性,這些都對流式大數據的生成方式提出了更為嚴格的要求.
Apache Spark Streaming 提供了兩種數據源,基礎數據源和高級數據源.基礎數據源是Streaming API 中直接提供的數據源,如socket 套接字、文件系統等.高級數據源是通過第三方類提供支持,如Kafka、Flume、Kinesis、Twitter 等.由于使用第三方工具生成數據本身會對性能有所影響[22],因此本文選用基礎的Socket傳輸方式作為Apache Spark Streaming 的數據源.Socket傳輸方式可通過程序控制向指定端口發送數據,并可以通過調節參數改變數據的傳輸速度,以生成不同流速的流式大數據.
針對股票高頻交易這一應用場景,本文選擇了現實的股票交易數據作為數據源,主要涉及的數據類型為數值型和字符型,方便進行流式SQL 的計算.
2.2 應用場景構造
流式計算的應用場景有很多,其中比較典型的是在金融銀行業的應用.在金融銀行領域的日常運營過程中往往會產生大量的實時數據,需要對這些海量數據進行實時分析處理以獲得其內在價值,從而幫助金融銀行進行分析決策[23].其中本文選取的股票的高頻交易就是流式處理系統在金融銀行業的一個應用.
(1)數據流構造
實驗構建了一個股票交易數據分析的場景,在滿足實際生產生活要求的同時,盡可能多地覆蓋流式計算特征.股票交易數據分析場景涉及3 個數據流:股票變化流、用戶交易流和用戶持倉流,如表1 所示.
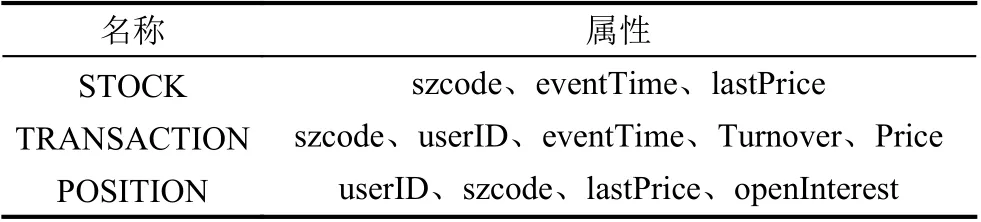
表1 數據流設計
STOCK 是股票變化流,用于描述不同時間點股票的價格情況.其中,szcode 代表股票編號,eventTime 代表當前時間,lastPrice 代表當前價格.
TRANSACTION 是股票交易流,用于描述不同時間點股票交易情況.其中,szcode 代表交易的股票編號,userID 代表用戶編號,eventTime 代表交易時間,Turnover 代表成交量,Price 代表成交價格.
POSITION 是用戶持倉流,用于描述不同時間點用戶股票持倉情況.其中,userID 代表用戶編號,szcode代表該用戶持有的股票編號,lastPrice 代表上次成交價格,openInterest 代表持倉量.
(2)具體應用構造
本文主要實現了對GroupBy 和Join 應用的覆蓋,設計如下:
1)GroupBy
GroupBy 是Apache Spark 中基本、常見的API,相當于SQL 查詢中的groupby()函數.實驗中實時獲取用戶交易流的數據,并按照股票編號這一字段進行聚合,計算每只股票在一段時間內的總成交額.
# SQL Query (GroupBy)
#實時計算n 分鐘內每只股票的成交額.
SELECT szcode,SUM(Price*Turnover)
FROM TRANSACTION [Range n,Slide s]
GROUP BY szcode
2)Join
實驗中對股票變化流和用戶持倉流進行Join 操作,按照股票編號進行連接,實現對各個用戶持倉股票市值的實時計算.
# SQL Query (Join)
#每個用戶所持股票的市值(用戶持有量*當前價格)
SELECT c.userID,SUM(lastPrice* openInterest)
FROM POSITION[Range n,Slide s] as p,STOCK[Range n,Slide s] as s,
ON p.szcode = s.szcode
GROUP BY p.userID
Join 可以建立不同數據流之間的連接,是大數據計算中的高級特性,復雜且代價大,但大多數場景都需要進行復雜的Join 操作.
Spark Streaming 會將逐條采集的數據按照事先設置好的批處理間隔匯總成一批數據進行處理,Join 操作是在每一個批數據上進行的,因此可通過對批處理間隔的合理設置避免Join 操作造成的運算復雜度較高.
2.3 評價指標
針對流式大數據處理系統基準測試中評價指標單一的問題,本文通過延遲、吞吐量、GC 時間等個方面對流式大數據處理系統進行評價.
延遲(Latency)是流式大數據處理中的一項常見且重要的指標,表示在處理過程中由于網絡或者計算產生的時間差.一般可以將延遲分為系統延遲和事件延遲[11].本文將延遲定義為數據從源段到輸出端所經歷的非計算時間.
吞吐量(Throughput)是系統在單位時間內的數據處理量.本文通過計算單位時間內數據源端輸出的數據總量作為系統的吞吐量.
GC 時間(GC time)是系統執行過程中垃圾回收機制的執行時間.垃圾回收即遍歷應用程序在Heap 上動態分配的所有對象,識別那些已經死亡即不再被引用的對象,將該對象占用的內存空間回收.垃圾回收的開銷是流式大數據處理系統內存管理需要考慮的因素之一,本文通過GC 執行時間衡量.
CPU 資源(CPU resources)即系統運行時的CPU 使用率.
Apache Spark Streaming 提供了Web UI 界面,在任務執行過程中,可以實時查詢任務運行情況,便于測試指標的查看和收集.本文借助Apache Spark Streaming提供的API 接口,實時收集運行時的延遲、吞吐量、GC 時間等評價指標數據,并以此進行實驗分析.
3 實驗驗證
本節對基于Apache Spark Streaming 實現的股票交易場景下的應用進行了以下兩組測試:(1)測試數據輸入速率對系統性能的影響;(2)測試執行器內核數量對系統性能及擴展性的影響.通過對測試結果的分析,總結了系統的在不同的測試參數下的性能表現.
3.1 實驗環境
為了模擬流式大數據處理系統在現實中的應用,提高大數據處理的效率,實驗搭建了集群,部署了分布式計算環境用于Apache Spark Streaming 測試.測試集群由五臺機器組成,包括1 臺Master 節點和4 臺Slave 節點,共20 cores,集群架構如圖2 所示,各個節點的配置信息如表2 所示.
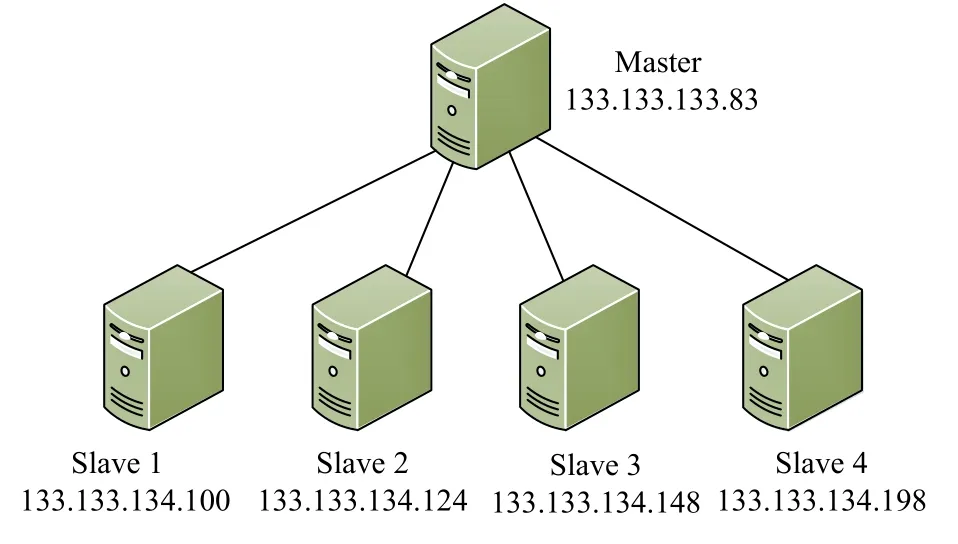
圖2 集群架構圖
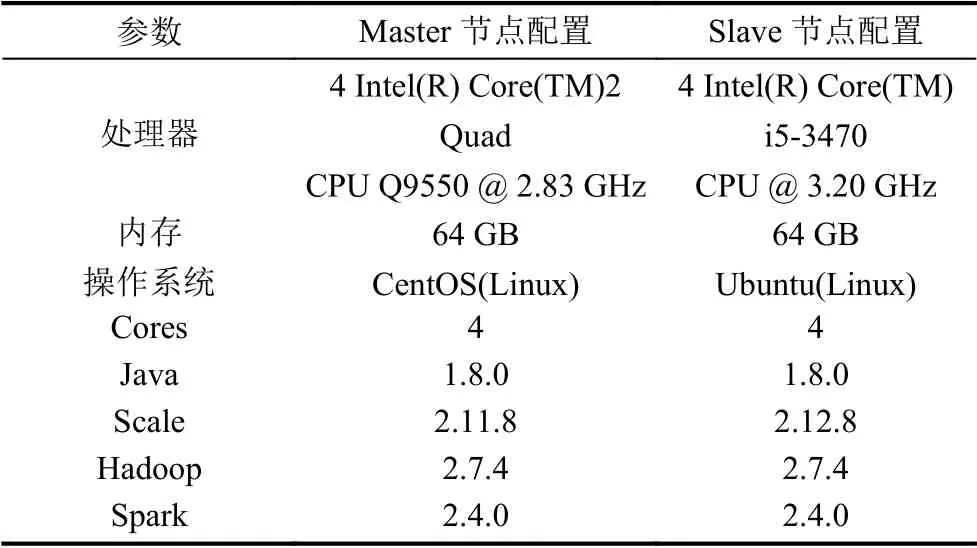
表2 測試集群配置
3.2 實驗設計
實驗采用控制變量法,每次改變單一變量測試系統在不同情況下的性能表現,每組進行五次測試,記錄平均值.本文針對Apache Spark Streaming 設計了兩個實驗,從數據輸入速率和任務并發度兩個方面考慮.
(1)通過控制socket 數據輸入端的線程休眠時間,測試系統輸入端的速率、執行時間、任務數、延遲和GC 時間.
(2)通過控制每個執行器的內核數,改變任務并發度,測試系統的擴展性,以及吞吐量、延遲和GC 時間的影響.
3.3 實驗結果及結論
(1)測試一:數據輸入速率對系統性能的影響
實驗通過Thread.sleep();函數控制socket 端向指定端口發送數據的速率,將線程的休眠時間分別設為500 毫秒,100 ms,50 ms,10 ms,1 ms 以及0,即每間隔500 ms,100 ms,50 ms,10 ms,1 ms 以及無間隔地發送數據.同時,將數據的生成時間固定為5 min,實現對輸入端數據速率的控制.測試一的實驗結果如表3 所示.
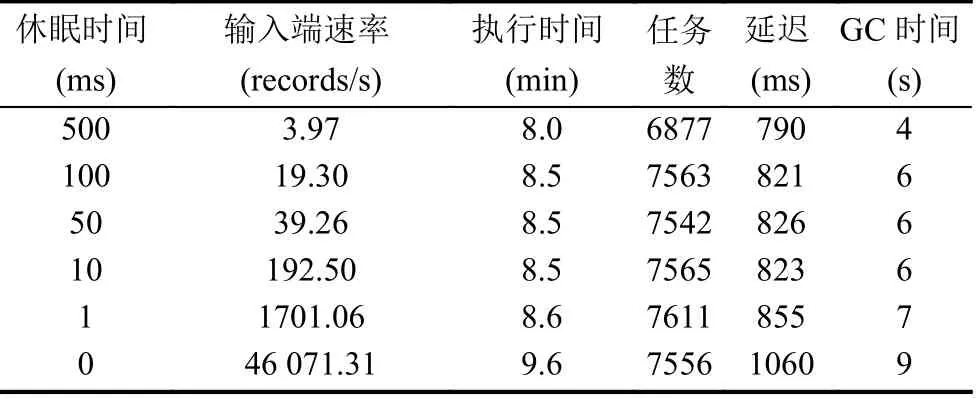
表3 測試一實驗結果
通過實驗數據分析,可得結論如下:
1)發現一:當數據輸入速率較高時,系統延遲呈現較大的增長.
實驗記錄了不同速率下的系統總延遲,如圖3 所示.可以發現隨著速率的增加,系統延遲總體呈上升趨勢的,這是符合邏輯的.但是在輸入速率較低、相差不大的情況下,系統延遲增加緩慢,控制在一定范圍之內,而當輸入速率較高時,系統延遲會呈現一個較大的增長.
2)發現二:輸入速率的提高會使系統資源利用率增加.
隨著輸入速率的提高,實驗從GC 時間和CPU 資源兩個方面分析了系統資源利用率的變化.
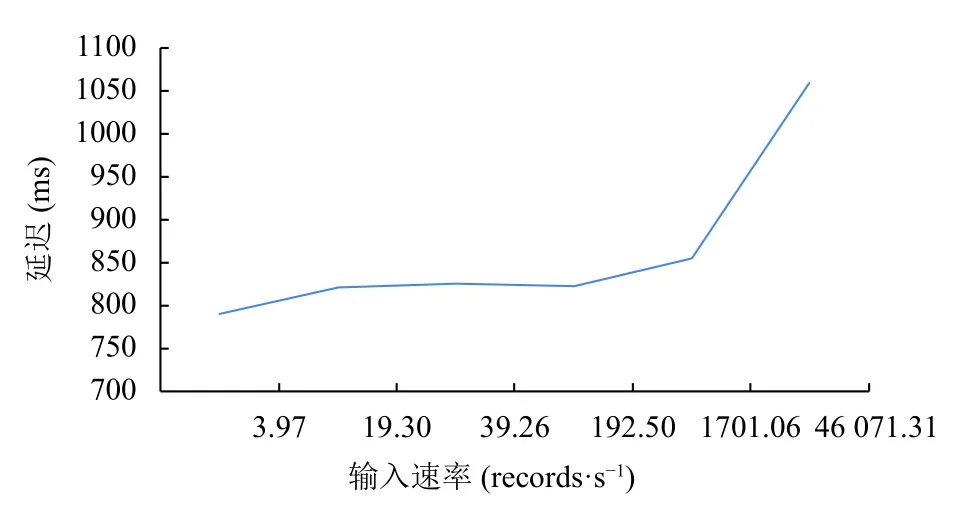
圖3 不同速率下延遲比較
Apache Spark 默認會將每個執行器的60%的內存空間用于緩存RDD,則在任務執行期間,只有40%的內存空間可以用來存放創建的對象.如果創建的對象過大,超過可用的內存空間,就會觸發java JVM 的垃圾回收機制.從圖4 中可以看到,隨著輸入速率的提高,系統的GC 執行時間也會增加,這是因為輸入速率的提高,任務數量及創建的對象也會增加,從而使GC 執行次數增加,即系統運行時的內存占用量增加.
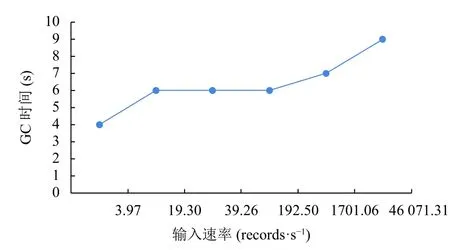
圖4 不同速率下GC 時間比較
此外,隨著輸入速率的提高,CPU 利用率呈增長趨勢,CPU 負載逐步提升.但即使在速度達到最大時,master節點CPU 利用率平均為28.71%,最大可達48.47%,CPU 資源并未得到充分利用.
綜上所述,輸入速率的提高會使系統資源利用率增加,但在Socket 輸入最大值的情況下,仍未實現系統資源的充分利用.
3)發現三:數據輸入速率在一定閾值內,系統性能相對穩定;數據輸入速率超過閾值時,系統性能下降.
通過對表3 實驗結果中的數據輸入速率與其他性能指標的關系進行分析,可以發現當數據輸入速率在19.30 records/s 到92.50 records/s 范圍內時,程序執行時間和GC 時間分別穩定在8.5 s 和6 s,任務數和延遲波動較小.當數據輸入速率提升到1701.06 records/s時,系統在執行時間、任務數、延遲、GC 等性能指標的度量上略有增長.然而,當數據輸入速率上升到46 071.31 records/s 時,系統的執行時間比數據輸入速率為1701.06 records/s 時增長了1 min,延遲增長了205 ms,執行的任務數卻有所減少.由此可以得出結論:數據輸入速率在一定閾值內時,系統的整體性能相對穩定;當數據輸入速率超過這一閾值時,系統性能會有所下降.
分析原因為隨著輸入速率的提高,系統接收的數據越來越多,系統的數據處理能力趨于飽和,甚至可能會出現計算過程中一個批次花費的時間大于系統設置的批處理間隔,這意味著數據接收速率大于數據處理速率,數據處理能力降低,系統性能也發生一定程度下降.但Spark Streaming 系統自身帶有反壓機制(Back Pressure),即使時間間隔內無法完全處理當前接收的數據,也不會導致執行器內存泄漏.
此外,從圖5 中可以看出,任務數除了在速率從3.97 records/s 上升到19.3 records/s 時出現大幅度增長外,之后不再隨著數據輸入速率的增加發生較大變化,且在速率達到最大時出現下降,可見系統的任務數隨著數據輸入速率的增加出現瓶頸.
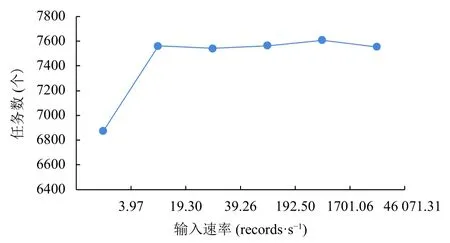
圖5 不同速率下任務數變化
(2)測試二:執行器內核數量對對系統性能及擴展性的影響
執行器(executor)是Apache Spark 任務的執行單元,運行在worker 上,是一組計算資源的集合.執行器的內核(core)數量可理解為執行器的工作線程,實驗通過改變執行器的內核數控制系統的并發度.
實驗中共系統設置了4 個執行器,將每個執行器的內核個數分別設置為2、4、8 和16,測試了2 min內數據接收情況、系統總延遲以及GC 時間.測試二實驗結果如表4 所示.
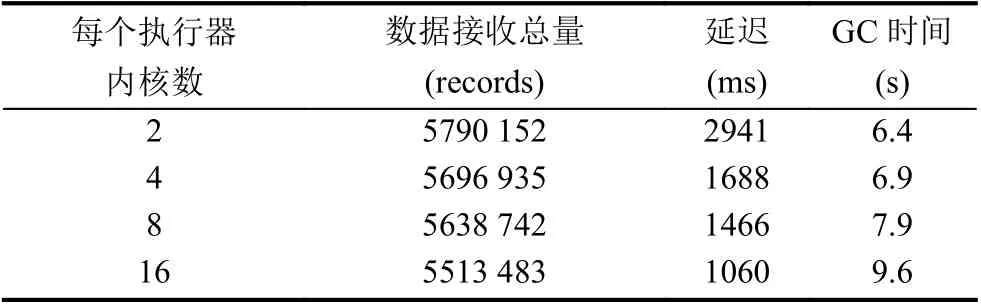
表4 測試二實驗結果
通過實驗數據分析,可得結論如下:
1)發現一:執行器的內核數對系統吞吐量影響不大.
在數據輸入速率相同的情況下,隨著每個執行器內核個數的增加,系統在2 min 內接收的數據整體呈現減少的趨勢,但從圖6 中可以看到,在考慮到網絡波動的情況下,系統接收數據的能力相似.因此,系統并發度的提升對Apache Spark Streaming 的吞吐量并沒有太大影響.
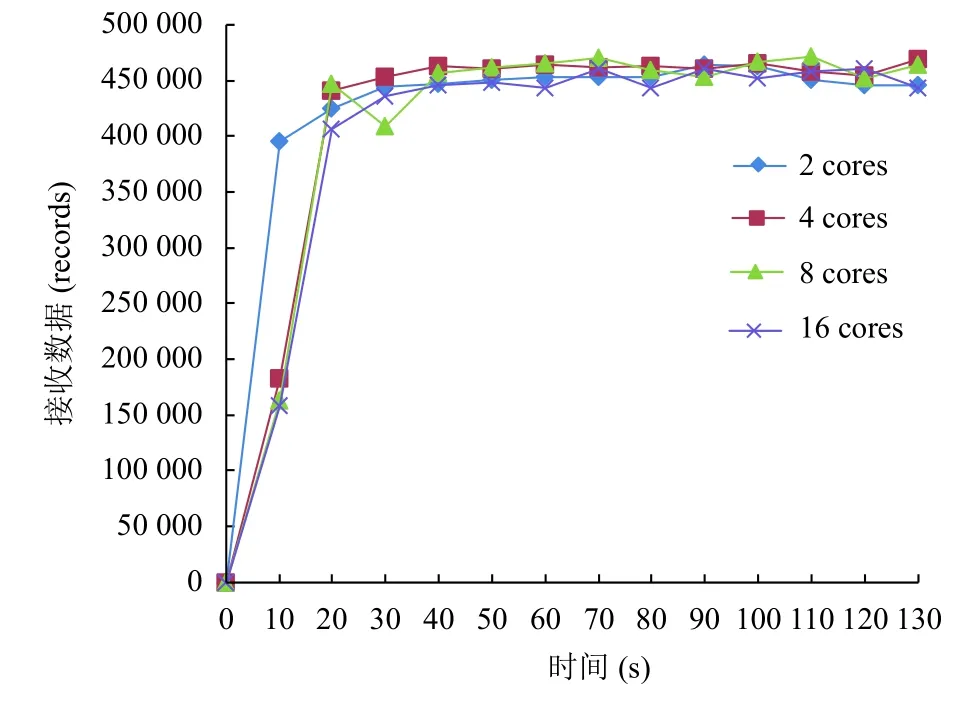
圖6 不同內核數下的數據接收情況
2)發現二:執行器內核數量的增加可降低系統延遲.
結合結論一分析,在系統接收的數據量相差不大的情況下,隨著每個執行器內核個數的增加,系統的延遲會大幅度降低,內核數為16 時的延遲只有內核數為2 時的1/3,如圖7 所示.
分析原因為{任務執行的并發度 = 執行器的總數目 * 每個執行器的內核數},當每個執行器內核數量增加時,任務并發度也會提高,多任務的并發執行使得從而使系統延遲大幅度降低.可見系統并行度的提高使得Apache Spark Streaming 系統資源的利用率也隨之提高,系統在延遲上的擴展性良好.

圖7 不同內核數下延遲比較
3)發現三:執行器內核數量的增加會造成系統資源利用率增加.
隨著內核數量的增加,任務并發度提高,導致系統GC 時間增加,如圖8 所示.
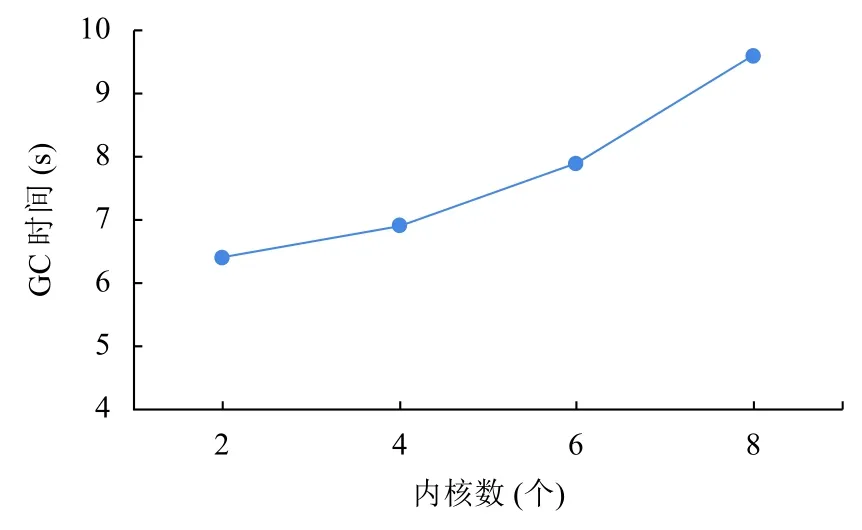
圖8 不同內核數下GC 時間比較
分析原因為內核數量的增加提高了任務并發度,使得大量的對象會被創建,出發Java 垃圾回收機制的次數也會增加,從而使GC 時間增加.因此適當減少內核個數也是降低系統GC 開銷的一種方法.
此外,系統并發度的提高也使得CPU 利用率有所提高,在16 cores 時CPU 利用率平均為31.05%,最大可達35.35%.
綜上所述,執行器內核數的增加會提高系統并發度從而增加系統資源利用率.
4 結束語
本文設計并實現了一個流式大數據處理系統基準測試框架,以Socket 作為流式數據生成,構造股票高頻交易場景,并實現了GroupBy 和Join 兩個典型應用,將實時計算與結構化數據相結合.測試框架搭建在分布式集群環境下,選取了Apache Spark Streaming 作為待測系統,從數據輸入速率和系統并行度兩個方面設計實驗,得到延遲、吞吐量、GC 時間等測試指標,以圖表的形式進行分析,發現流式大數據處理系統中出現的性能問題.實驗結果表明,隨著數據輸入速率的提高,系統性能保持相對穩定,當輸入速率達到一定閾值,系統會出現性能下降,資源利用率增加的現象;系統并行度的增加對吞吐量的影響較小,但系統延遲會大幅度降低,GC 時間有所增加,提高了系統資源的利用率.
未來將在以下幾個方面進行深入研究.一是可以將基準測試框架應用到不同的處理系統中,分析系統之間的差異,進行對比研究.二是對流式大數據處理系統的基準測試不再僅限于對獨立的系統,而是與第三方工具結合,如使用Kafka、Flume 等高級數據源產生數據,模擬現實環境下的應用.
猜你喜歡
工業設計(2022年8期)2022-09-09 07:43:20
軍民兩用技術與產品(2021年10期)2021-03-16 06:05:30
北京測繪(2020年12期)2020-12-29 01:33:58
裝備制造技術(2019年12期)2019-12-25 03:06:46
制造技術與機床(2019年10期)2019-10-26 02:47:06
中國洗滌用品工業(2019年4期)2019-05-11 09:27:34
鐵道通信信號(2018年5期)2018-06-28 03:06:24
家庭影院技術(2017年9期)2017-09-26 03:41:45
知識經濟·中國直銷(2017年5期)2017-06-15 20:28:19
通信電源技術(2016年6期)2016-04-20 06:21:32
