基于加權K近鄰的特征選擇方法
2020-04-27 05:22:26李雙杰張開翔王士棟王淑琴
天津師范大學學報(自然科學版) 2020年2期
李雙杰,張開翔,王士棟,王淑琴
(天津師范大學 計算機與信息工程學院,天津 300387)
在當今大數據時代,很多應用中數據集的維度很高,尤其在DNA 微序列分析、圖像處理、模式識別和文本分類等領域,數據具有極高的維度[1-3],然而,在分類任務中,過高維度造成的“維度詛咒”現象會導致過擬合,從而降低學習模型的泛化能力[4],而且許多特征都是不相關或者冗余特征,它們在分類學習過程中毫無用處.特征選擇是機器學習的一個重要的數據預處理過程[5-6], 其目標就是剔除不相關和冗余特征,以減少學習維度,并在可接受的時間內獲得高準確率,同時降低訓練模型所用的時間和存儲空間[7].
在過去幾年里,各種各樣的特征選擇算法被相繼提出[8].根據分類器是否獨立,特征選擇方法可以分為Filter、Wrapper 和 Embedded 3 類.由于在選擇候選特征子集時,Filter 方法與分類器相分離[9-11],因此Filter方法相對簡單,時間復雜度較低,可以和多種分類器結合.Wrapper 方法通常以分類器的性能作為候選特征子集的評價準則[12], 因此它具有較好的分類性能,但其計算開銷通常比Filter 方法大很多.Embedded 方法結合了Filter 方法和Wrapper 方法的優點,在學習算法訓練過程中可以自動進行特征選擇[13],因此它通常優于Filter 方法和Wrapper 方法.
在模式識別中,K 近鄰算法經常用于分類和回歸任務[14-15].K 近鄰的優勢是算法簡單且對異常值不敏感.近年來,它也被用于特征選擇方法的研究.文獻[16]提出了一種基于KNN 的加權策略(MKNN)方法,它使用傳統的信息增益作為特征選擇方法,MKNN 作為分析基因表達數據的分類器,該方法根據數據集中每一類別中樣本到該類中心點的距離對樣本進行加權,從而使K 個近鄰樣本對判定測試樣本類別的貢獻不同,但該方法在計算距離時沒有考慮特征的重要性.文獻[17]將KNN 作為一個基本單元集成到特征選擇框架中,用以評價候選特征子集的優劣,該方法通過隨機選擇多個特征子集,用KNN 評價特征子集的分類準確率,最后將相應準確率的平均值作為特征的支持度,支持度越高表示特征與類別的相關性越大, 該方法將KNN 視為一個黑盒子, 沒有對KNN 算法展開研究.在對測試樣本的類別進行判定時,一方面,應依據其K 個近鄰樣本與其距離的大小不同來決定每個近鄰樣本對類別的貢獻,距離越小的貢獻也應越大;另一方面,由于每個特征對樣本類別的重要程度是不同的,所以在計算樣本間距離時,還應考慮每個特征的重要程度.為此,本文提出了一種基于加權K 近鄰的特征選擇算法,該算法在計算樣本類別時既考慮每個特征的重要程度,又考慮近鄰樣本的距離,并使用遺傳算法搜索最優特征權重向量,最后按最優特征權重向量對所有特征降序排序,依次選出對應的前N 個特征組成特征子集,并用分類器評價其質量,本文方法屬于Filter 方法.使用6 個真實數據集,將本文方法與現有的 3 種特征選擇方法 MIFS[18]、DISR[19]和 CIFE[20]進行比較, 并使用 K 近鄰(KNN)、隨機森林(random forest)、樸素貝葉斯(NB)、決策樹(decision tree)和支持向量機(SVM)5 種分類器對每個方法所選擇的特征進行分類預測,實驗結果表明本文方法具有較好的分類性能.
1 基于加權K近鄰的特征選擇方法
本文提出的基于加權K 近鄰的特征選擇方法,簡記為 WKNNFS(feature selection based on weighted K-nearest neighbors).首先初始化一個種群,種群中每個個體代表一個特征權重向量;然后用加權K 近鄰預測樣本類別,并設計合適的適應度函數;最后用遺傳算法搜索最優特征權重向量.
1.1 相關定義
對于分類任務,測試樣本的類別由K 個近鄰投票決定,將測試樣本歸為票數最多的類別.對于回歸任務,測試樣本的類別由K 個近鄰的目標值的算術平均值決定.以下若無特殊說明均為處理回歸任務.給定一個回歸問題 D=(F,X,Y), F={f1, f2,…, fm}為特征集合, X={x1,x2,…,xn}為包含 n 個樣本的數據集,xi=(xi1,xi2,…,xim)(1≤i≤n)為樣本 xi的觀測值, Y={y1,y2,…,yn}為目標變量集合,則測試樣本 xi的預測值Pi為

其中:K 為KNN 中選擇的近鄰個數;yj為K 個近鄰樣本的目標變量.
定義一個特征權重向量 wf=(wf1,wf2,…,wfm), 則對特征加權后的樣本觀測值用Hadamard 積表示為
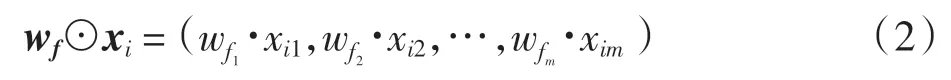
使用特征加權后樣本xi與xj的歐幾里得距離為
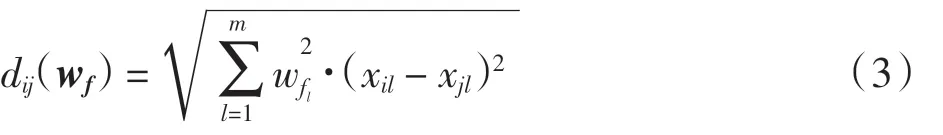
傳統的K 近鄰方法中,訓練集中用于預測測試樣本類別的K 個近鄰樣本的貢獻是相同的,這忽略了不同近鄰樣本的重要性的大小,距離越小,它們屬于同一類別的可能性越大,也就越重要.因此,可以對K個近鄰的貢獻進行加權,距離越小的近鄰分配的權重越大.距離加權函數w 應滿足以下性質:
(1)w(d)為一個單調遞減函數.
(2) w(0) =1.
(3)w(∞)=0.
本文采用的距離加權函數為

考慮特征加權與距離加權后測試樣本xi的預測值Pi(wf)定義為
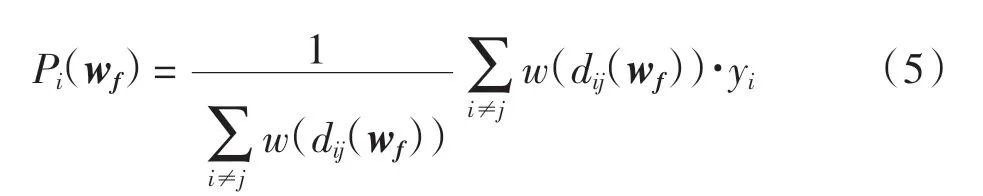
損失函數用預測值Pi(wf)與目標函數的真實值yi的差表示,定義損失函數為
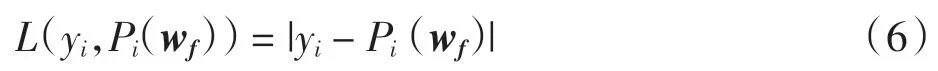
成本函數用所有訓練樣本損失函數的平均值表示,成本函數值越小說明整體的預測誤差越小.成本函數定義為
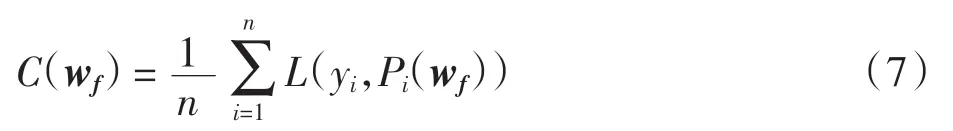
1.2 遺傳算法
采用遺傳算法搜索最優特征權重向量.
(1)初始化種群:使用(0,1)中的實數隨機初始化含有m 位基因的個體,每個個體代表一個特征權重向量.
(2)適應度函數:個體t 的適應度函數定義為

其中Max 是給定的使Ft(wf)≥0 的正整數.
(3)選擇算子: 使用輪盤賭選擇(也稱為比例選擇方法)[21]作為選擇算子.
(4)交叉算子: 因為本文使用的是實數編碼方式,因此采用算術交叉算子,使下一代盡可能地遺傳上一代中優秀個體的性狀.先根據概率隨機選擇一對父代個體P1、P2作為雙親,然后進行如下隨機線性組合產生 2 個新的子代個體
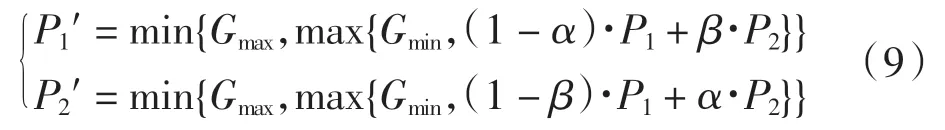
其中:α、β 為(0,1)中的隨機數,個體基因的取值范圍為[Gmin, Gmax].如果(1 - α)·P1+ β·P2的值小于 Gmin(或大于Gmax), 則P1′的值為Gmin(或Gmax), P2′的值同理可得.
(5)變異算子:變異算子采用高斯變異,這種操作方式能重點搜索原個體附近的某個局部區域.高斯變異使用符合均值為μ、方差為σ2的正態分布的一個隨機數Q 來替換原來的基因值.Q 的計算公式為

其中: ri是在[0,1]范圍內均勻分布的隨機數, μ 和 σ的計算公式為
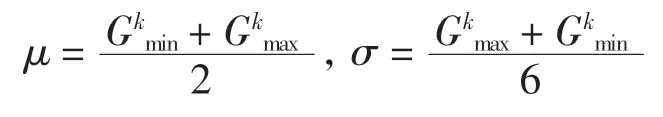
1.3 WKNNFS特征選擇方法
對于回歸問題D=(F,X,Y),首先,用實數編碼方式初始化一個種群, 種群中每個個體為一個權重向量;然后,對于當前代的每個個體t,用基于K 近鄰的方法計算訓練集中每個樣本的預測值Pi(wf)及該個體對應的適應度函數值Ft(wf),為了更好地找到全局最優解,將當前代最大的適應度函數值和對應個體保存到Results 中;最后,分別執行選擇、交叉、變異3 個遺傳算子產生新的種群,并重復上述操作直到滿足終止條件,即達到給定的迭代次數.
迭代操作結束后,將Results 中的適應度函數值降序排序,獲得適應度值最高的個體,則可得到最優特征權重向量,再對最優特征權重降序排序,即可得到對應特征分類能力的降序序列.
WKNNFS 特征選擇方法的具體流程如下:


2 實驗與性能分析
2.1 數據集
為驗證WKNNFS 算法的正確性和有效性, 在6個數據集 Q_green、hcc-data2、Sonar、clean1、Prostate 和brain 上進行實驗,前4 個數據集下載自UCI 機器學習庫[22],后2 個數據集下載自學習網站http://ligarto.org/.實驗中對這些數據均做了歸一化處理,所用數據集的具體描述見表1.
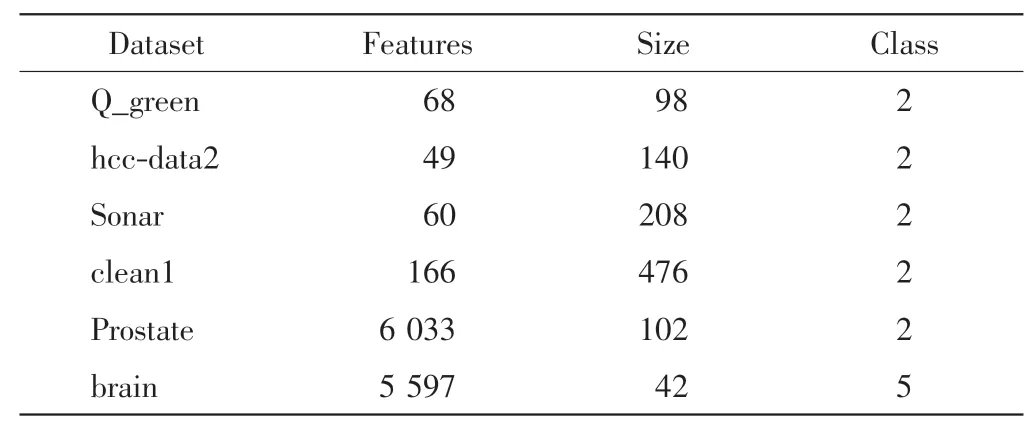
表1 數據集Tab.1 Datasets
2.2 實驗環境及參數設置
使用PyCharm 集成開發環境,對每個數據集進行十重交叉檢驗.在以上6 個數據集上,將WKNNFS 與現有的3 種特征選擇方法MIFS、DISR 和CIFE 進行比較,并使用K 近鄰、隨機森林、樸素貝葉斯、決策樹和支持向量機5 種分類器對每個方法所選擇的特征進行分類預測.實驗中初始化種群包含80 個個體,迭代次數為260 次,交叉概率為0.8,變異概率為0.08.
2.3 實驗結果及性能分析
實驗所用數據集中部分是不平衡數據集,所以本文采用F1-measuer 指標來衡量分類性能.F1-measure指標綜合了精確度(precision)和召回率(recall),其定義為實驗結果見圖1,圖中,橫坐標表示選取前N 個特征,縱坐標為選取前N 個特征后5 個分類器進行分類預測得到的F1 的平均值.
由圖1 可見,WKNNFS 與其他3 種方法相比,不僅獲得的分類性能最高, 而且在多數情況下最快獲得了最高分類性能.在數據集Q_green、hcc-data2 和Sonar 上(圖1(a)~(c)), WKNNFS 相比另外 3 種方法能夠很快達到最高分類性能.在數據集clean1 上(圖1(d)), 當選取前 N(N=1,2,…,20)個特征時, 4 種方法的分類性能相近,但隨著特征數的增加,WKNNFS的性能明顯優于另外3 種方法.在數據集Prostate 和brain 上(圖1(e)~(f)), WKNNFS 達到最高分類性能的過程較慢, 這可能是因為這2 個數據集的維度較高.由圖1(a)和(b)可見, 4 種方法的分類性能達到最高后, 再增加所選特征數, 分類性能反而呈下降趨勢,這表明特征數過高可能會降低模型的分類性能.
表2 給出了在6 個數據集上4 種方法獲得的最高分類性能(F1)及其對應的特征數(m).每個數據集上的最高分類性能用粗體表示.
由表2 可見,在6 個數據集上WKNNFS 達到的最高分類性能均高于其他方法.當達到最高分類性能時,WKNNFS 在所有數據集上都優于CIFE 方法,即達到最高分類性能時選取的特征數較少.WKNNFS 與另外2 種方法相比,當達到最高分類性能時,在4 個數據集(hcc-data2、Sonar、Prostate 和 brain)上選取的特征數較少,在數據集Q_green 上選取的特征數相差不大,而在數據集clean1 上選取的特征數較多,這可能是因為遺傳算法在搜索最優特征權重向量過程中陷入局部最優, 而后又跳出局部最優(由圖1(d)WKNNFS 的分類性能曲線可見,在N =13 和N =35附近曲線下降).

圖1 4 種方法在不同數據集上F1 的平均值Fig.1 Mean of F1 on different datasets of 4 methods
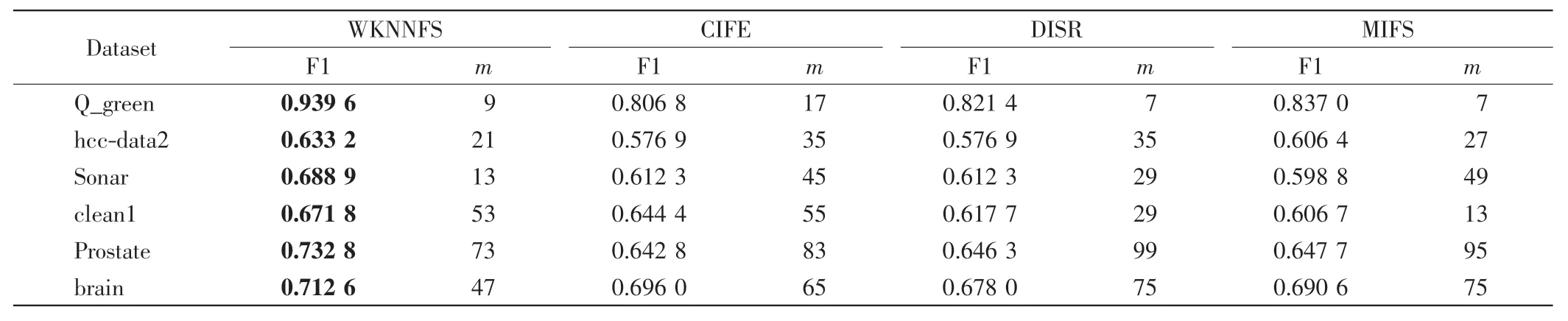
表2 在6 個數據集上4 種方法的最高分類性能(F1)及對應的特征數(m)Tab.2 Highest classification performances and the number of features selected of 4 methods on 6 datasets
3 結語
特征選擇是機器學習和數據挖掘等領域常用的降維技術.本文提出了基于加權K 近鄰的特征選擇方法,同時使用遺傳算法搜索最優特征權重向量,在6個真實數據集上與其他3 個特征選擇方法進行比較實驗,結果表明,WKNNFS 獲得的分類性能最高,且能較快獲得最高分類性能.在未來的工作中可以嘗試其他距離公式或遺傳算子, 以進一步提高分類準確率,降低預測誤差.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
