網站用戶行為分析及服務推薦研究
2020-04-29 11:00:24張婉婷
智能計算機與應用 2020年2期
張婉婷, 趙 敏
(上海理工大學 光電信息與計算機工程學院, 上海 200093)
0 引 言
隨著互聯網的廣泛應用和迅猛發展,海量的信息也隨即涌現,人們已經進入信息過載的時代[1]。對于想要獲取信息的用戶,靠自己從龐大的數據中獲取需要的信息則存在相當難度。此外,對于提供信息的一方,如何讓自己提供的信息受到用戶的關注,也并非易事。為此有眾多高校、研究機構積極開展此項研究[2]。其中,推薦系統就是解決該問題的一項重要工具。推薦系統利用數據挖掘等相關的數據處理技術,能根據用戶的歷史行為數據,來自動生成用戶可能感興趣的信息,并將其推薦給用戶,最終為用戶提供個性化信息推薦服務[3]。
1 國內外推薦系統研究現狀
1995年,美國人工智能協會上首次提出了個性化推薦系統。隨后各大高校和研究部門開始對個性化推薦系統進行深入研究。與此同時,又陸續推出了多種推薦算法,其中,目前獲得較大成功、有著較為廣泛應用的則是基于協同過濾的推薦算法[4]。
針對協同過濾推薦算法自身的問題(冷啟動和稀疏數據問題等)[5],學界提出了多種改進的方法。對于冷啟動問題,文獻[6]中給出了一種基于新用戶的冷啟動推薦方法。將用戶模型和信任/不信任網絡結合,以此來識別值得信任的用戶,取得了較好的效果。對于稀疏數據問題,文獻[7]將貝葉斯網絡引入到協同過濾當中,并通過對網絡的進一步優化,提高了系統的準確率[8]。對于協同過濾推薦算法存在的其他問題,韓林嶧等人[9]基于用戶之間的共同/不同特征,創建了新的相似度計算方法,并在基于K近鄰的協同過濾算法中得到應用。
在協同過濾推薦算法基礎上,文獻[10]改進了協同過濾推薦算法,并比傳統方法的推薦準確度更高。即使用戶評分數據極端稀疏,推薦效果仍較好。另外,為了滿足不同用戶的多樣化需求,產生了多種混合的推薦算法。Girardi等人[11]通過將領域本體技術與協同過濾進行混合,并取得了理想的推薦效果。Vekariya等人[12]通過將知識和協同過濾相結合構造混合推薦算法,不僅證明了該算法的有效性,而且取得了較好的效果。
在前人的思想上,本文主要通過基于物品的協同過濾推薦算法對法律資訊平臺建立個性化推薦系統。一個完整且完善的推薦系統通常具有用戶行為信息收集、用戶喜好模型建立和信息推薦等功能。
2 推薦算法
2.1 相似度計算
在推薦系統中,最重要的計算就是用戶-物品偏好二維矩陣運算。可以將某個用戶對所有物品的偏好作為一個向量,計算用戶之間的相似度,或將所有用戶對某個物品的偏好作為一個向量,計算物品之間的相似度[13]。常用的相似度計算方法有:余弦相似度法、歐幾里德距離法和皮爾遜相關系數法。基于優化思想的考慮,本文的法律資訊信息推薦系統采用皮爾遜相關系數法。
皮爾遜相關系數可表示兩變量間的線性相關程度。該系數取值-1到+1,越接近1或-1說明變量之間線性關系越強。如果一個變量增大,另一個變量也增大,則變量之間正相關,相關系數大于0。如果一個變量增大,另一個變量卻減小,則變量之間負相關,相關系數小于0。如果相關系數等于0,則表明變量之間不存在線性相關關系[14]。
皮爾遜相關系數計算公式為:
(1)

2.2 系統評估
本文法律資訊信息推薦系統主要采用均方根誤差(RMSE)、平均絕對誤差(MAE)對系統進行評估,用來評估本文構建的推薦系統的推薦質量。對此可做研究分述如下。
(1)均方根誤差(RMSE)。可通過式(2)進行計算:
(2)
(2)平均絕對誤差(MAE)。可通過式(3)進行計算:
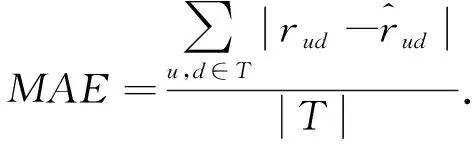
(3)
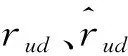
2.3 K-近鄰算法
K-近鄰算法(KNN)的原理可表述為:特征空間中有k個最相鄰的樣本,當某一個不知類別的樣本,與樣本中的大多數屬于同一個類別時,就認為該樣本也屬于這個類別,且該樣本也具有該類別的其它特征。K-近鄰算法在分類時,用與未知類別的樣本最鄰近的一個(或幾個)樣本的類別,來決定待分類樣本所屬的類別。
這里,給出該算法的執行步驟詳述為:
(1)計算已知類別的樣本點與待分類樣本點之間的距離。
(2)對計算出的距離進行排序。
(3)確定與待分類樣本點距離最小的數個已知類別的樣本點。
(4)計算距離最小的數個樣本點所在類別的出現頻率。
(5)返回距離最小的數個樣本點中出現頻率最高的類別作為待分類樣本點的預測分類。
3 協同過濾
3.1 協同過濾的選擇
協同過濾主要依靠用戶歷史行為數據和屬性的相近性來實現個性化推薦服務。協同過濾不僅可以對喜好相近的用戶進行信息收集,還可以將有用的信息推送給其他相似用戶作為參考。常用的協同過濾方法有基于用戶(user-based)與基于物品(item-based)的協同過濾。本文是以某大型法律資訊網站提供的數據為基礎來構建推薦系統。
基于用戶的協同過濾推薦方法是通過和目標用戶相似的用戶的興趣喜好來預測目標用戶的興趣偏好,并推薦目標用戶可能喜歡的物品[16]。該方法是以用戶訪問行為的相似性為基礎,來推薦用戶可能感興趣的內容和資源。依此建立的法律資訊信息推薦系統的基本思想是將與自己有相同或相似興趣偏好的用戶所喜歡的法律知識(網站)推薦給自己。
與基于用戶的推薦方法相反,基于物品的協同過濾推薦方法是根據用戶平時瀏覽過的一些法律知識(網站)及其喜好程度,通過計算各不同法律知識(網站)之間的線性相關程度,推薦給用戶與之前訪問法律知識(網站)相似的其它法律知識(網站)。
隨著互聯網的快速發展,網站用戶的數目也越來越龐大。考慮到基于用戶與基于物品的協同過濾的區別,在實際應用中,計算用戶的興趣相似度矩陣越來越困難(例如龐大的稀疏矩陣)。運算的時間復雜度和空間時間復雜度呈指數增長。基于用戶的協同過濾方法不利于實際中的研究應用,而且對推薦的結果也不能做出很好的解釋[17]。因此本文法律資訊信息推薦系統是在基于物品的協同過濾前提下進行研發的,主要是對法律咨詢中婚姻這一大類進行小類別的推薦。
3.2 基于物品的協同過濾
該算法可以理解為,法律知識A和法律知識B具有很大的相似度,那么喜歡法律知識A的用戶也大都喜歡法律知識B。
研究可知,法律資訊信息推薦系統中基于物品的協同過濾推薦思路如圖1所示。由圖1可知,此方法的基本思想是把與用戶喜歡的法律知識(網站)相似度較高的其它法律知識(網站)推薦給用戶。

圖1 法律資訊信息推薦系統中基于物品的協同過濾推薦思想
Fig. 1 Item-based collaborative filtering recommendation in legal information recommendation system
基于物品的協同過濾推薦算法首先會收集用戶、物品信息。建立用戶興趣模型。計算目標物品與其他物品的相似度,并對相似度排序。然后根據推薦算法給用戶推薦和目標物品最相似的i個物品[18]。基于物品的協同過濾推薦算法中用戶u對物品n的感興趣程度的度量公式見如下:
(4)
其中,qNn表示物品n和目標物品N的相似度,duN表示用戶u對目標物品N的感興趣程度。
基于物品的協同過濾推薦算法的設計步驟可以描述為:
(1)計算目標物品與其他物品之間的相似度。
(2)根據用戶的歷史行為、物品間相似度的大小等生成推薦列表。
4 設計法律資訊信息推薦系統
4.1 操作步驟
(1)數據預處理。數據預處理主要是對得到的用戶原始的瀏覽信息進行一定的處理,例如篩選、去除無用的信息等操作。本文采用的是某大型法律資訊網站提供的數據,每一個用戶數據包括realId、fullURL、網頁標題、網站所屬法律知識的類別等。本次預處理操作包括篩選出訪問婚姻相關信息的用戶數據、刪除有殘缺的數據、把具有翻頁功能的網站還原到初始網頁等。
(2)用戶偏好程度設置。考慮到無法真實地獲知用戶對哪種法律知識比較關注(喜好),本文通過統計用戶對某一類法律知識網頁訪問的(不同)次數來作為用戶的關注(喜好)程度,并做歸一化處理。
(3)確定輸入數據模型。本次系統的建立是采用Python的surprise包,因此輸入數據模型將根據其內部的要求采用如下數據模型,即:<用戶 id><物品 id><用戶偏好得分>。
(4)相似度矩陣計算。本文采用基于KNN算法的協同過濾推薦系統,采用皮爾遜相關系數計算其相似度。
(5)得出推薦結果。根據某一用戶之前的訪問狀況給出某一類別法律知識,推薦給用戶可能關注的不同法律知識及網站。
4.2 運行推薦系統
法律資訊信息推薦系統以某大型法律資訊網站提供的數據為基礎。對法律知識中的婚姻資訊進行推薦系統的建立和實驗驗證。
以婚姻中“財產分割”為例,推薦給關注該法律知識的用戶5個相關的法律知識類別并列出相關的網站。
(1)法律資訊信息推薦系統推薦結果。見圖2。

圖2 法律資訊信息推薦系統的推薦結果
Fig. 2 Recommended results of the legal information recommendation system
由圖2可知,法律資訊信息推薦系統給出了與婚姻中“財產分割”相似度最高的五類法律知識及相關網站,即:“繼承法”、“撫養費”、“離婚訴訟”、“非婚生子女”和“哺乳期”。綜上內容與“財產分割”相關性很高。
(2)法律資訊信息推薦系統評估參數。見圖3。

圖3 法律資訊信息推薦系統的評估參數
Fig. 3 Evaluation parameters of the legal information recommendation system
(3)法律資訊信息推薦系統評估結果。研究評估結果如圖4所示。

圖4 法律資訊信息推薦系統的評估結果
Fig. 4 Evaluation results of the legal information recommendation system
由圖2~圖4可知,法律資訊信息推薦系統為關注婚姻中“財產分割”的用戶推薦的結果,比較符合實際情況。此外,該系統在RMSE和MAE上也有較好的表現。
5 結束語
本文的法律資訊信息推薦系統是基于物品的協同過濾設計的個性化推薦系統。文中通過一系列設計研發步驟,最終取得了令用戶信服的仿真測試結果。
在整個算法研究過程中,考慮到用戶信息數據的龐大[19],本文只對法律知識中婚姻資訊進行推薦系統的建立和實驗驗證。雖然如此,系統運行速度仍然較慢,還要不斷改進算法,盡量使其運行得更快。此外,算法本身的數據稀疏問題、用戶興趣遷移問題等,也影響著推薦效果,這些均有待更進一步的研究去改進與完善。
猜你喜歡
法律方法(2021年3期)2021-03-16 05:57:02
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
山東青年(2016年1期)2016-02-28 14:25:30
中國衛生(2015年1期)2015-11-16 01:05:56
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
浙江人大(2014年5期)2014-03-20 16:20:27
