網頁搜索排序模型研究
2020-04-29 11:02:08李明琦
智能計算機與應用 2020年2期
李明琦
(哈爾濱工業大學 計算機科學與技術學院, 哈爾濱 150001)
0 引 言
隨著互聯網的發展以及相關技術的不斷提升與完善,人們獲取信息的主要途徑從查閱書籍、報紙等紙質材料轉向了搜索引擎。然而,用戶往往需要耗費大量時間從紛繁復雜的網頁中去甄別有用信息。因此,高效地進行信息檢索的主要挑戰是優化網頁搜索的排序以檢索出與用戶查詢相關的文檔。時下,許多搜索引擎仍在進一步研究新的排序算法,來提升用戶的滿意度。
目前,第二代搜索引擎還有一些不足之處。其一是相關性問題,即用戶使用的檢索詞與文檔的相關程度。通常使用的語言是復雜的,難以通過表面的文檔特征來判斷該文檔是否與檢索詞相關。一方面,這種判斷會使搜索引擎返回大量網頁,且容易發生排序作弊現象,另一方面,這種判斷無法返回不包含檢索詞、但相關性高的文檔。其二,大多搜索引擎是根據關鍵詞匹配,經常給出許多混合結果,不能有效解決問題。雖然搜索引擎展示的結果與用戶檢索的關鍵詞相關,但是這并不能滿足用戶對信息的需求與期待。
改善這些問題的一種方法是更好地理解用戶行為,在不斷地檢索過程中,搜索引擎收集到了大量的用戶行為數據,通過分析和利用這些數據,可以有效提升排序效果。同時,如果能在文檔特征中加深語義理解,就能使檢索詞與文檔的相關程度分析得更為精準,從而能夠提高用戶的滿意度。
近期的研究者已經轉而關注起新的研究任務,并不是因為網頁搜索排序問題已經完全解決了,而是因為這個任務到達了一個平臺期。網頁搜索排序問題仍然有著實際重要性,因此還需展開深入系統研究,推動該領域的發展與進步。
1 相關工作
網頁搜索排序,即給定一個查詢Q和一個網頁文檔集合D,基于文檔和查詢的相關性得分,給出最相關k個文檔的順序。迄今為止,許多學者嘗試了各種方法來解決這個問題,而且取得了較為可觀的成果。
搜索引擎在早期時,主要用到的網頁排序思想是根據關鍵詞在文檔中出現的位置和頻率進行排序。基本原理是,關鍵詞在文檔中的詞頻越高,出現的位置越重要,則被認為和檢索詞的相關性越好。OkapiBM25[1]是一個流行的基于tf/idf的排序函數。
然后,出現了鏈接分析排序技術,其思想源于文獻引文索引機制,若網頁被其他網頁引用的次數越多,或者被越有價值的網頁所引用,該網頁的價值就越大。
斯坦福大學Page等人[2]提出了PageRank算法,基本思想是,以PageRank值來判斷網頁的重要程度,PageRank值取決于2個特征,其一是引用該網頁的網頁個數,其二是引用該網頁的網頁重要程度。但PageRank算法會嚴重排斥新加入的網頁,并且沒有將網頁的主題相關性考慮到排序中。
斯坦福大學的HaveliWala[3]提出了主題敏感的PageRank算法,解決了主題漂流問題,然而這個算法沒有用主題的相關性來提高鏈接得分的準確性。
Google的工程師Bharat等人[4]獲得了HillTop算法的專利,解決了PageRank算法的查詢無關性的問題,文檔鏈接如果與查詢主題相同會認定為更具可靠性,并只考慮專家頁面,由專家頁面對用戶查詢進行鏈接。這就有效處理了一些想通過增加循環鏈接數量提升PageRank值來作弊排序的網頁。然而,專家頁面在查詢過程中權重非常大,這忽略了許多非專家頁面的影響。
Kleinberg[5]提出的HITS算法是另一個基于超鏈接分析的著名排序算法,但仍然無法解決主題漂流的問題,并且可能產生主題泛化等問題。
在網絡搜索領域,機器學習算法自動訓練排序模型越來越流行,因為網頁搜索中,有很多信息可以用來確定query-doc對相關性,并且可以利用大量的搜索日志。
Cao等人[6]將Ranking SVM應用于文檔檢索,并對高排名的文檔加強訓練提出了用新的損失函數解決排序問題,應用了梯度下降和二次規劃來優化損失函數。
Burges等人[7]提出一種基于PairWise的RankNet方法,使用神經網絡來訓練模型,訓練的損失函數為交叉熵,使用梯度下降來優化損失函數,時間復雜度優于Ranking SVM。RankNet優化的是pairwise錯誤的數量,但這與檢索特征并不匹配。而其后提出的LambdaRank模型[8],其設計思想是直接求梯度,而不是利用代價。LambdaMART模型[9]則是結合了MART和LambdaRank,也是基于RankNet的算法。
對于網頁搜索的點擊模型最初是考慮點擊偏置來估計相關性。Richardson等人[10]提出了位置模型,用戶點擊取決于文檔位置和query-doc對相關性。Craswell等人[11]提出了瀑布模型,研究中假設一個用戶從頭開始逐個地瀏覽文檔,并且在遇到不相關文檔后繼續瀏覽,但在遇到相關文檔后停止。許多復雜的點擊模型都是基于這兩個模型,如UBM[12]、DBN[13]、CCM[14]。Chapelle等人提出了DBN,該模型假設了一次點擊當且只當用戶檢測并且認為網頁是可能相關的。
本文采用基于統計的排序學習方法,用不同的方法對文檔進行表示,輸入到排序模型中,進行對比實驗,期望在小數據集上得到較好的排序效果。
2 文檔表示方法和排序模型
本節擬探討實驗中采取的文檔表示方法和排序模型。這里,排序任務是機器學習問題,需要抽取不同的特征來代表query-doc對,以輸入到排序模型中進行訓練。對此可做分析論述如下。
2.1 query-doc對表示方法
首先,采用手工抽取特征的方式對query-doc對進行表示,每個query-doc對都由多維向量表示,每個維度都是一個特征。本任務抽取了文本特征、相似度特征、匹配特征、點擊特征等14個特征,見表1。

表1 特征類型
文本特征考慮到了查詢和文檔,是非常傳統的用于排序學習任務的特征,長度是基于中文分詞后的結果進行統計。相似度特征是基于查詢和文檔關系的特征,由3種模型得到不同的文檔向量表示,然后計算得到查詢和文檔的余弦相似度。匹配特征是指關鍵詞在文檔標題或內容的出現情況,完美匹配即關鍵詞以連續順序出現于文檔標題或內容,非完美匹配即關鍵詞以不連續順序出現于文檔標題或內容。點擊特征是由4種流行的點擊模型(DBN, TCM[15], PSCM[16], UBM)訓練得到的點擊概率值,搜索引擎收集的各種用戶行為信息揭示了查詢和點擊文檔的相關信息,因此這些點擊模型可以根據用戶行為建立起來并且可以預測下次用戶點擊的位置,這些點擊概率給研究者提供了極具價值的查詢和文檔相關程度信息。
這種用特征表示文檔的方法是人們憑經驗提取組合的,可能并沒有足夠好的表達query-doc對,并且人工抽取特征也較為耗費時間和人力。所以,研究嘗試使用不同的深度學習方法對query-doc對進行表示,以期能夠表示query-doc對的深度語義信息,再將這些特征向量作為排序模型的輸入,可能提高整體模型的表現效果。
Word2Vec方法可以將單詞映射到向量空間,不僅考慮到了詞與詞之間的語義信息,而且還能將詞語映射到低維度的向量,解決了one-hot向量稀疏的問題,常見的用詞向量表示文檔的方式有:對詞向量的每一個維度取平均值,最大、最小值等。通常,直接拼接組合詞向量是簡單有效的方法,通過實驗證明該方法能夠在不同的NLP任務中取得較好的效果。
基于Word2Vec的文檔表示方法,考慮到了詞與詞之間的語義信息,并且能夠降低向量的維度,然而,研究時將文檔中的所有詞取平均值或最大、最小值會忽略詞與詞之間的順序,同時對文本表示信息有一定影響。基于Doc2Vec的文檔表示方法是對Word2Vec的擴展和改進,其段落向量保留了段落的主題信息,對段落進行記憶。Doc2Vec模型可以將文檔映射到固定維度的向量,既可以學習到詞與詞之間的語義信息,又可以保存詞與詞之間的順序信息,用Doc2Vec對文檔進行表示,可以很容易得進行文檔相似度等計算,對于許多含有長文本的任務都有所幫助。
2.2 排序模型
排序學習是一個有監督的機器學習過程,通過對每一對給定的query-doc對,抽取查詢文檔的特征表示,然后通過訓練排序模型,使得輸出與實際數據相似。常用的排序學習分為3種類型:PointWise, PairWise和ListWise。其中,PointWise方法只處理單獨的文檔,將文檔轉換為特征向量,根據訓練數據得到的模型對其進行打分,再將所有文檔按照得分結果進行排序。PairWise方法將相關性得分轉換為文檔對關系,例如A的相關性得分為3,B為2,C為1,則可得到A>B,B>C,A>C等關系。這樣就把排序問題轉化成了二分類問題,利用訓練模型,對所有文檔進行分類得到偏序關系,從而構造全集的排序關系。ListWise方法的輸入為一個文檔序列,通過構造合適的度量函數來優化排序,得到排序模型。
本課題通過調研選取3種穩定的排序模型進行實驗,分別為:Ranking SVM、 RankNet和LambdaMART。其中,Ranking SVM和RankNet是基于PairWise方法的,LambdaMART是基于ListWise方法的。
過程中,分別用前文所述方法對query-doc對進行表示,再與不同的排序模型進行組合,這里以使用Word2Vec取平均表示query-doc對,排序模型采取RankNet為例,設計模型如圖1所示。
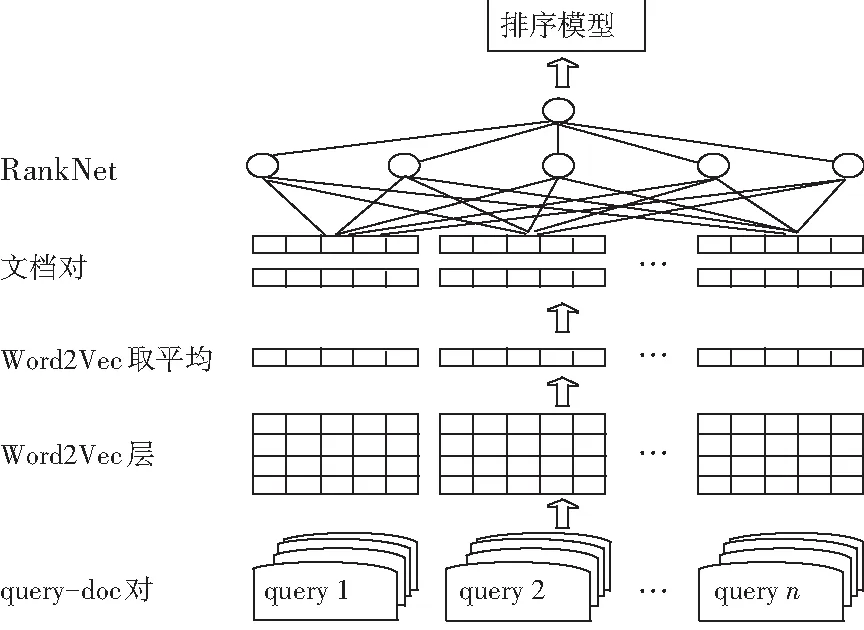
圖1 基于Word2Vec取平均的文檔表示輸入RankNet模型
3 實驗
3.1 實驗數據集
本課題用到的數據集來自NTCIR-14的WWW2任務,包含2萬個query-doc對,含有相關性標簽,其中15 000對作為訓練集,5 000對作為測試集。對于每對query-doc對,提供4種弱相關標簽,由4種流行的點擊模型得到,分別為:UBM, DBN, TCM, PSCM。這些點擊標簽利用了大量用戶行為,如點擊、跳過、停留時間。
3.2 數據預處理
原始數據為xml格式,包含查詢內容、查詢頻率、查詢id、文檔url、文檔id、文檔標題、文檔內容、html、文檔頻率、文檔點擊標簽等內容。
首先,需要對這些數據進行預處理。本課題只提取了查詢內容、文檔標題、文檔內容、點擊標簽等信息。然后過濾掉內容、標題等數據中的非中文、空格、停用詞、空數據等信息。最后,將數據進行繁簡轉換、分詞等操作。
3.3 評價指標
針對回歸、分類、排序等不同類型的問題,研究時用到的評價指標也不相同。網頁搜索排序返回的結果通常是有序的,所以需要考慮其位置信息,本課題采用信息檢索的常用評價指標如NDCG、nERR、Q-measure,來度量排序結果的優劣。
3.4 實驗結果
本節將BM25算法作為本課題研究的基線,該算法是文檔檢索的常用算法,思路非常簡單。這里對比了加入點擊特征對query-doc對進行表示的情況下,Ranking SVM、 RankNet 和LambdaMART模型的表現,具體實驗結果見表2。
表2 排序模型在不同特征組合下的實驗結果
Tab. 2 The results of ranking model under different combination of features

排序模型特征NDCG@10Q@10ERR@10LambdaMART加入點擊特征0.546 10.540 70.686 7LambdaMART未加點擊特征0.467 90.473 50.602 6RankNet加入點擊特征0.502 80.514 20.654 3RankNet未加點擊特征0.433 70.434 40.571 7Ranking SVM加入點擊特征0.445 80.453 50.569 5Ranking SVM未加點擊特征0.400 60.409 40.535 3BM250.326 70.332 20.464 1
由此可以看出,LambdaMart模型表現效果最好,并且點擊特征對排序結果非常有幫助。
采用Word2Vec,Doc2Vec等模型對文檔進行表示,在排序模型上選擇穩定性較好的Ranking SVM、 RankNet和LambdaMART進行實驗,繼而比較3種評價指標的好壞,實驗結果見表3。
由此可以看出,基于深度學習的表示方法整體優于不加入點擊特征時的手工提取特征的方法,Doc2Vec模型表現最優。
4 結束語
如今,人們在日常生活中廣泛使用互聯網,對信息的獲取主要求助于搜索引擎,因此對網頁搜索排序結果進行優化是有著重要研究價值的,好的排序結果可以節省用戶瀏覽大量低相關度網頁的時間,并且返回用戶滿意的結果,從而解決人們生活中的實際問題。
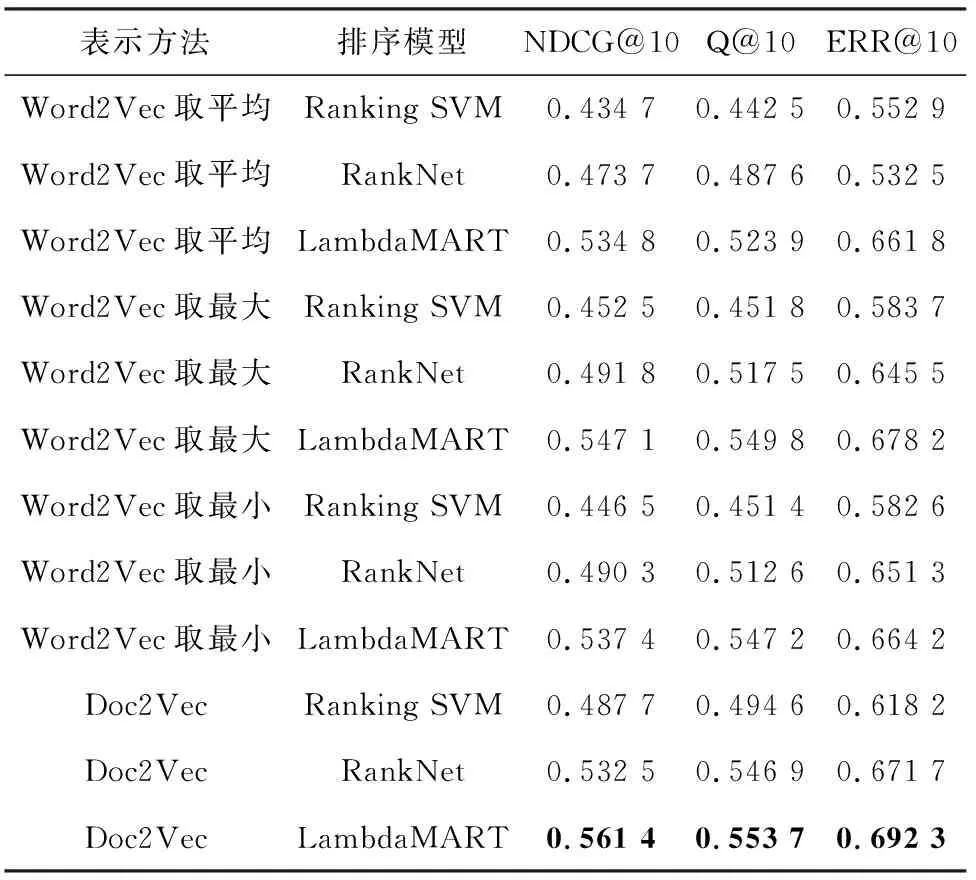
表3 基于不同文檔表示方法的實驗結果
本文在少量標注樣本數據集上,采用不同的query-doc對表示方法,對不同的排序模型如Ranking SVM、RankNet、LambdaMART進行對比實驗。實驗結果表明,點擊特征對于提升排序效果非常重要,并且LambdaMART模型在本實驗中的排序效果最好,穩定性較高。本文探索了多種基于深度學習的文檔表示方法,如Word2Vec分別取平均值、最大值、最小值,Doc2Vec模型,將以上模型生成的文檔表示向量輸入到排序模型中進行了對比試驗。實驗結果表明,用Doc2Vec模型來表示query-doc對,最終得到的排序結果是最好的,可以很好地捕捉到文檔的語義信息。本文在網頁搜索排序問題上取得了一定的研究成果,但是仍然存在一些不足。一方面,排序模型的實驗以及基于深度學習方法表示文檔的實驗對比并不充足,未能嘗試基于pointwise方法的排序模型,而且也沒有用更多的深度學習方法(如GRU模型)對文檔進行表示,這樣會使實驗結果不全面,不足以進行有效的論證。另一方面,數據樣本較小,且數據存在不平衡性,這對提升排序效果的表現產生一定影響。
后續的研究工作可以從半監督學習方面開展,排序模型效果的表現與訓練數據的多少相關,由前文可看出,即使研究嘗試了多種文檔表示方法、排序方法,排序結果的評價指標仍然沒達到最理想的狀態。因為研究中很容易地獲取到大量的無標注網頁,其中蘊含的信息對于訓練排序模型也是很有價值的,因此可以利用半監督學習方法,自動標注一部分數據,這樣就可以擴充訓練集,同時也能盡量保證標簽的準確性。
猜你喜歡
中學生數理化·七年級數學人教版(2022年11期)2022-02-14 07:14:12
科普童話·學霸日記(2020年1期)2020-05-08 16:45:11
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
小天使·一年級語數英綜合(2019年2期)2019-01-10 11:57:30
兒童繪本(2018年5期)2018-04-12 16:45:32
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
