基于半監督學習的網絡應用流識別研究
2020-04-29 11:02:08余翔湛郝科委
智能計算機與應用 2020年2期
趙 洋, 余翔湛, 郝科委
(哈爾濱工業大學 計算機科學與技術學院, 哈爾濱 150001)
0 引 言
目前,隨著互聯網技術的飛速發展和網絡設施的不斷升級進步,越來越多的網絡應用已經進入人們日常生活中來。人們對互聯網技術的認可度提升以及網絡的應用范圍也日趨寬廣,使得人們的生活越來越依賴來自這些網絡應用所提供的服務。網絡應用在各領域的普及推廣不但為人們的日常生活帶來便利,同時更極大提高了社會的工作效率。目前,寬帶計入能力的提升、不斷更新的通信方式、“三網融合”工程的加速開展、“百兆鄉村”政策的出臺、物聯網技術的應用與發展以及“互聯網+”重大工程的實施,綜上的論述都切實表明中國正處在、并將會長期處在全民網絡時代。但隨著網絡應用的強勁拓展態勢,網絡流量及網絡規模迅速增大,產生的海量數據使得對網絡應用流量的安全管理工作愈發艱難。同時,由于互聯網的虛擬性、開放性和交互性,使得網絡應用質量參差不齊,良莠混雜,甚至還有某些不良網絡應用利用現在先進的技術,假借正常端口或者協議來傳播。而且,悄然伺機而動的病毒、木馬也會伴隨著新的網絡應用,威脅著用戶的隱私數據安全,給人們帶來巨大的損失。因此,隨著國內計算機技術的廣泛應用與飛速發展,網絡安全已躍升至國家安全戰略地位,“沒有網絡安全就沒有國家安全”的理念已日益深入人心。作為網絡安全的重要環節,網絡應用識別技術的研究尤為重要。
1 研究現狀
目前識別方法主要分為機器學習識別和非機器學習模型兩種。其中,非機器包括基于端口的報文識別檢測技術和基于負載的識別檢測技術,隨著網絡應用技術成果的相繼問世,這些傳統的方法已經難以適應不斷變化的協議規則,因而逐漸為機器學習方法所取代。
相對于非機器學習,機器學習方法更加依賴于數據包和數據流特征而不是簡單的特殊字段識別和匹配。影響機器學習方法主要取決于2個方面:特征提取方法和分類算法選擇。其中,特征選擇可以定制在2個層面上:數據包和數據流。數據包特征是通過對數據流一定范圍內數據包的特征,諸如:最長包長、最短包長、平均包長、包長中位數方差等信息進行統計,最終整合得到結論。數據流特征則是包括:客戶端端口、服務器端端口、數據流平均包長、數據流空包數、數據包傳輸平均時間間隔等特征,對應用流或是應用進行識別。一個好的識別模型,一般都會根據所識別的內容特性,選用兩者中的適當內容進行分類訓練識別。這里,對目前主流的研究方法可闡釋論述如下。
(1)基于端口的網絡應用識別。這是人們最早用來識別網絡數據流路的方法。在早期的簡單網絡中,網絡應用種類少且大都使用特殊的端口號,所以只需要觀察并識別傳輸層報文頭中的端口號,就可以辨識出相應的網絡應用。這種識別方法不僅高效,而且所耗費的資源也是所有方法最低。起初,大部分網絡都會選擇特定端口號,而且不同種類的應用一般都配有不同的傳輸端口。基于端口號的應用識別技術便可以根據人工統計,選擇特定的報文傳輸端口來確定目前應用類型。
(2)基于載荷的應用流識別方法。這是基于端口識別方法的傳承和進化。相對于基于端口的識別方法,基于載荷的識別方法選擇了應用層數據中的特殊字段,通過對大量的應用層協議的分析和統計,找出屬于每一個應用層協議的特征碼,再通過新來的數據流與特征碼的整合匹配,得出識別效果。考慮到每種協議都具有其特定的規則和使用方式,所以一個好的特征碼提取算法和特征碼匹配算法往往會取得非常好的識別準確率和效率。
(3)決策樹。是在已知標簽數據分析基礎上,通過構建決策樹來求取凈現值的期望值大于等于零的概率,判斷可行性的一種決策方法。在眾多數據挖掘和機器學習研究中,決策樹歸納法是應用最廣的方法之一。決策樹中的每個節點代表在一個識別過程中的測試或是識別,若其含有分支則表示當前節點的識別結果,每個葉節點代表其最后的類型。
(4)基于神經網絡方法。分析可知,數據量較少的時候,決策樹的準確率、效率都優于神經網絡。但隨著訓練數據的不斷增加,學習強度的不斷上升,神經網絡的準確性能將更加出色。特別是隨著新應用的漸次出現,一些直觀的屬性已經難以完全區分應用類型,特征的選取也越發困難,那么基于神經網絡的識別方法在應用識別方面就尤為突顯其強大適用性了。
根據準確性、復雜性、拓展性以及加密流量識別能力,本文對上述4種方法進行了對比分析,得到的結果見表1。
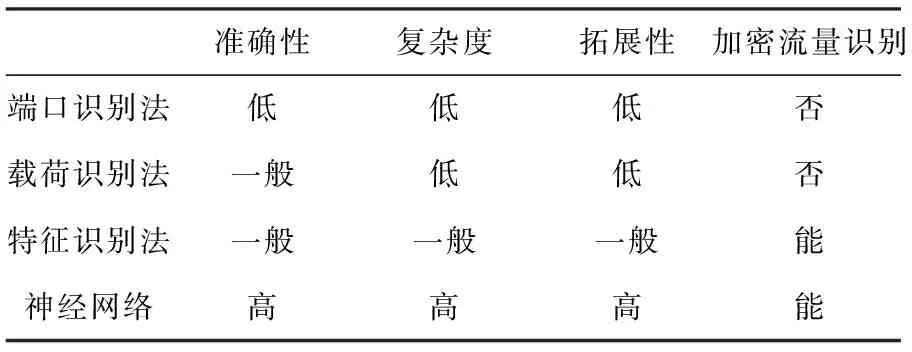
表1 網絡應用識別的方法對比
2 數據聚類標識法
2.1 輸入數據流特征選擇
伴隨著人工智能的發展,機器學習的方法已經成為各領域解決問題的重要方法。基于決策樹、行為特征的方法都使得應用流識別的準確率大大提升。傳統的基于機器學習的應用流識別方法一般是基于以往訓練經驗,選擇最具有代表性的數據包或數據流的具體特征集,通過對特征集合向量化作為訓練模型和測試部分的輸入。而后,即是不斷調整決策樹構造或者隱藏層的權值,使訓練集識別準確率達到最優。但是目前的研究現狀是,網絡應用及網絡協議的數量已經越來越多,有限數量的顯示特征已經不能完全地作為當前網絡流量的代表集合,自動去尋找代表特征集合就非常重要。而且現實場景中對網絡數據流的標識工程量較大、難度高,所以應用與訓練的標識數據相對于海量的未標識數據少之又少,基于監督學習的神經網絡分類器很難直接從少量的標識數據流中學得準確識別信息。因此融合了監督學習與無監督學習優勢的半監督學習方法隨即提出了通過在無監督學習提供大量標識數據的基礎上,再使用監督學習建立分類器的方法。
2.1.1 基于五元組的數據流拼接
本文訓練數據來自由抓包軟件從網卡抓取的離線pcap文件,測試數據則是實時從網卡抓取的pcap文件。由于實際網絡中會含有多進程通信,應用流自然不會單獨出現在實際網絡中,為了更好地識別網絡應用流種類,就需要將網絡應用流拼接起來。
在實際的網絡應用流分析中,研究發現多數情況下,在一個較短的時間內同樣的2個ip使用相同端口一般只通信一次。這使得可以通過對五元組的組合計算,將同一個短期的pcap中所有應用流單獨拼接出來,并按順序存成對應數據。在本研究課題中,每個數據流的區別特征值key的計算公式為:
key=str(ip.src)+str(ip.dst)+str(port.src)+
str(port.dst).
(1)
在一個pcap中,每讀入一個數據包,將計算其key值,根據key值將相同的數據包拼接在一起。數據流的拼接過程詳見圖1。

圖1 pcap數據流拼接
2.1.2 數據特征選擇
根據數據流拼接的結果,研究獲得了單個數據流信息。但是在實際網絡中,將很難保證每個抓取的數據流都不存在缺失、重傳、或是截取不完整等問題,同時很多基于流的特征并不能作為最好的選擇去代替這個應用流,而基于數據包的特征也不能去代替整個應用流。
在解決數據流代表性問題上,本文使用了數據流原文作為訓練的輸入。通過觀察發現,數據流原文是一串十六進制的數字,而2個十六進制的數字則最終組成了0~255的數字,并且恰好對應了灰度圖像中的灰度值范圍,使用深度學習的研究思路也隨即廣受關注。而且,由于每個流的長度不同,數據包個數、甚至每個數據包大小也不同,就需要選取每個數據流的相同數量、長度的報文作為特征向量。
首先將每種應用報文按照一字節8位為一維特征,將每種應用的應用流拼接成圖像,通過對不同類型的數據流圖像進行對比,如圖2所示,發現相同的應用類型,如圖2(a)與(b)均為QQ消息數據流,具有相似的圖像;而不同的應用類型的數據流原報文圖像則如2(c)所示,與前2個QQ圖像存在較大的差異,所以使用原報文方法是可行的。而后,根據文獻[1-4]識別研究過程的原理解析,研究分別選擇包長、數據包應用層協議類型、數據包數據段長度等顯性特征來繪制出圖像;并對TCP頭設置push位包數、從客戶端到服務器方向,以初始端口發送tcp負載大小和從服務器到客戶端平均負載大小等基于數據流的特征進行統計分析。圖3隨即展示了QQ聊天與其他udp應用前50數據包長度統計對比。其中,藍色和綠色的線條代表QQ聊天,橙色代表其它的udp應用。顯而易見,在前50數據包長度對比上,相似的應用同樣具有相似的性質。與此同時,研究還針對其它特征都進行了比對,效果大致相似。

圖2 QQ聊天與其它udp應用的特征圖片對比

圖3 QQ聊天與其它 udp應用前50數據包長度統計
Fig. 3 Top 50 packet length statistics for QQ chat and other udp applications
為此,可推得如下研究結論:每個流前50~100報文由于其包含應用流建立連接和控制報文的交換信息,而且也會帶有少量的其它通信信息,故而選擇前50個數據包能夠有效地代表數據流。而在每個數據包中,使用相同的傳輸層協議往往具有相似的傳輸層結構,不能很好地代表報文特征。研究中為區分應用流,則選擇使用了應用層報文。通過統計分析,選擇前50字節作為每個數據包的代表特征值。這樣一來,每個數據流就可以使用50*50=2 500維數據作為輸入向量訓練模型。
2.2 基于自編碼的數據降維
在聚類的開始階段,通過分析觀察報文的原文則會發現,有很多的報文原文中數值為0,且數據段相對較短的報文內容向量,本文也對其進行了補0處理,這里為了使距離度量相似性的設定不會失效,將首先使用數據降維的方法對輸入的矩陣向量做出降維處理。
與傳統識別方法提取數據流、數據包特征識別方法不同,基于數據包原文的識別方法在每個維度上取值范圍、代表含義都是相同的。這使得在維度下降方面,基于報文原文的方法可以使用相對優質的特征下降法而不僅局限于特征選擇。通過試驗對比分析,研究選擇使用自編碼器降維方式。對此,文中將給出研究論述如下。
2.2.1 自編碼器模型
AutoEncoder是一個將數據的高維特征進行壓縮降維編碼,再經過相反解碼過程的一種學習方法。學習過程中通過解碼得到的最終結果與原數據進行比較,再根據修正權重偏置參數降低損失函數,不斷提高對原數據的復原能力。學習結束后,前半段的編碼過程得到結果即可代表原數據的低維“特征值”。通過學習得到的自編碼器模型可以實現將高維數據壓縮至所期望的維度,原理與PCA相似。本課題使用的自編碼器結構則如圖4所示。輸入是由每個數據流前50數據包,每個數據包使用前50字節,共2 500維向量組成。中間通過對隱藏層的訓練,選擇最優的隱藏層權值,使得還原結果更加準確,也就是說使得輸出層的低維向量更具有代表性。

圖4 自編碼器實現結構
2.2.2 自編碼維度選擇
選擇不同的維度對原始數據進行表達會產生不同的表達效果。為了使自編碼器能夠對原始數據的表達性更強,研究分別將輸出層數設置為10~600,并將2萬多組的網絡數據流分為20組,對每組均采用了編碼/解碼操作,通過求取20組平均前后數據方差值,描繪后的展現即如圖5所示。由結果顯示可知,選取200維作為最終聚類維數不但降維效果很好,而且還原度也相對較高。
2.3 基于k-means的數據聚類標識法
在降維后,數據變為200維特征的矩陣集。為了能夠獲得充足的標識數據作為構造分類器的訓練數據,半監督分類方法選擇使用無監督聚類結合少量標簽數據對大量的未標識數據進行標識操作。在聚類方法選擇上,根據目前半監督分類和聚類應用于數據流識別的現狀,研究選擇聚類效果較好的k-means算法進行聚類標識。使用k-means聚類標識數據的研發過程詳述如下。
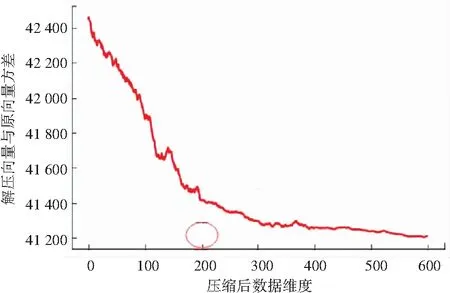
圖5 壓縮維度選擇與還原效果關系圖
2.3.1 k-means算法k值選擇
k值作為k-means算法的核心關鍵點之一,其選擇策略對于最終聚類效果有著至關重要的影響。與傳統的k-means以中心點收斂為終止條件不同,由于聚類的數據流存在新類別,使得中心點應當具備一定的數量調整能力。基于此,本文使用了循環聚類的方法,將每次的聚類結果作為下一次聚類方法選擇的判定條件。以一定的距離作為閾值,閾值之外的點作為本輪未標注點,如果未標注點達到一定數量,則啟用k+1作為下輪k-means的k值,重新選擇中心聚類,直至k值不變并收斂。如果中心點收斂且未標識數據沒有達到閾值,聚類結束。
2.3.2 k-means算法距離選擇
傳統k-means算法一般以歐式距離為衡量類別間相似的標準,但對于數據包原文來說,雖然每一位的取值范圍相同,但每一維度所代表含義的差異可能使傳統歐氏距離的區分效果大打折扣。本文選擇加權的歐氏距離作為各點之間的距離度量方法,可以避免維度特征之間的差異。
加權的歐氏距離也可以解讀為標準化歐氏距離,是針對歐氏距離的一種改進,在計算距離前將對每一個維度進行數據標準化使得期望為0,方差為1。先求出帶標識數據在第n維度上的標準差sn,對于2個向量a(x1,x2...,xk)和向量b(y1,y2,...,yk)之間的加權距離公式可以表示為:
(2)
2.3.3 k-means算法實現描述
算法基于加權歐氏距離的k-means算法
輸入:帶標簽和未帶標簽的2組數據集
輸出:識別之后帶標簽數據集及標簽集
Step1通過對有標識數據的統計,得出現有標識類別數作為k初始值。
Step2將帶標識數據按照標簽分別存入不同的集合中。
Step3計算所有數據在各個維度上的標準差。
Step4分別計算各個集合標簽集中向量在各維度上的均值,組成各個集合的初始k個中心點。
Step5分別計算各個集合中距離中心點最遠的距離作為本輪閾值d。
Step6帶標記的向量不動,分別計算不帶標記向量到各個中心加權距離,如果該點所有中心點最小距離大于d,則將該數據暫時放入unknow隊列。如果最小距離小于d,則將其歸入距離最近的集合中。
Step7將所有新集合向量各個維度取均值作為新的中心點,若中心點與上輪不同,重復Step 6。
Step8如果中心點相同,統計unknow數量,若大于本次聚類標簽數最少的類別數,則將k+1,取unknow數組中位數下標的向量作為新的聚類中心,重新進入Step 6。
Step9若小于最少類別數,則將unknow數據拋棄。對當前每個集合中的數據進行分組標記。對于新分出來的集合采用人工標記法,隨機抽取一定數量的應用流進行人工識別,對標識結果進行比對。若最多類型數量超過90%,使用該類型標識這個集合,否則舍棄。
3 實驗結果與分析
通過對32 000組標記數據流進行模擬,并選擇分組聚類標識法測試,其中包括coco數據流8 378條,zello數據流7 693條,skype數據流7 752條,ftp站點數據流3 653條,隨機應用流4 524條。選擇4種有標記數據流各1 000條作為已標識數據集。其余的28 000條以4 000為一組作為未標識應用集。使用已知標識的數據集分別與每組未知標識數據進行聚類標記,通過與原標記進行對比識別,得識別運行結果詳見表2。

表2 聚類結果統計
接下來在表2基礎上,處理得出識別準確率的仿真運行結果,如圖6所示。
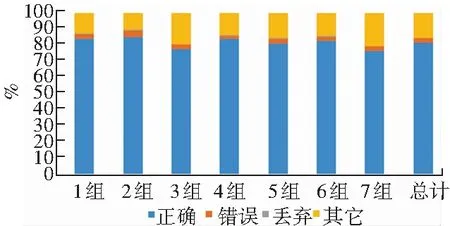
圖6 聚類準確率的運算結果
圖6給出的聚類后根據識別效果對每組識別準確率進行統計顯示,每組標識數據識別錯誤率均不超過5%,因距離過遠而丟棄的數據都不足1%,而標識為其它的數據與已知的未標注數據在總量上彼此相近。結合在一起,可以判定總體數據的聚類標識準確度達到95%以上,該效果可以用來對未標識數據進行有效的標注。
4 結束語
針對不斷出現的新應用流的識別,傳統的非機器學習方法無法對新類型應用進行識別,只能夠重新建立模型;而傳統的基于特征的機器學習方法也很容易出現識別錯誤和特征選擇不具典型性的問題。基于數據報文的應用流識別使得識別過程可以從應用流本身挖掘特征而非僅依賴于選擇的特定特征,極大地增強了模型的自身學習能力和對新應用類型識別和學習的適應性。在分類識別之前,大量的有標識應用流是必要的,通過半監督學習的方式可以采用少量的標識數據對大量的未標識數據進行準確的標記,從而為準確的監督學習模型分類器的建立提供堅實的基礎。
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
兒童故事畫報(2019年5期)2019-05-26 14:26:14
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
