面向檔案的知識圖譜構建方法研究
2020-05-08 05:02:40王電化錢立新夏春梅
湖北科技學院學報 2020年1期
王電化,錢 濤,錢立新,盛 琦,夏春梅
(1.湖北科技學院, 湖北 咸寧 437100;2.咸寧市檔案館, 湖北 咸寧 437100)
一、構建檔案知識圖譜的意義
檔案信息化在近幾年得到了快速發展,檔案數據已呈幾何級增長,形成真正意義上的檔案大數據[1]。檔案數據資源的利用特別是檔案信息檢索成為日常工作中不可或缺的組成部分。傳統檔案信息檢索系統主要采用關鍵詞匹配技術,只能進行詞形的機械匹配,導致人們難以檢索到符合自己意愿的檔案信息。然而,檢索語句中的“關鍵詞”通常存在諸多隱形的邏輯語義關系,例如對于用戶輸入查詢語句:“張三任職局長”,該語句包含三個關鍵字“張三、任職、局長”,隱含著張三是公職人員,用戶想查詢是人事任命類檔案,甚至可能想查詢張三是何時在何地擔任局長的。但當前的檔案檢索系統并不能從語義的角度分析用戶的檢索意圖,也缺乏有效的檔案知識推理。
知識圖譜[2~4]技術在解決知識查詢的精度及知識推理方面展現出了巨大的優勢,成為學術與工業界研究的熱點問題。已被廣泛應用于智能搜索、智能問答、個性化推薦、內容分發等領域。當前有代表性的知識圖譜產品包括當DBpedia[5],YAGO[6],百度知心[7],搜狗知立方[8]等。以上大部分是通用的知識圖譜,直接運用行業領域并不能達到較好性能。因此領域知識圖譜也受到越來越多的重視。構建基于檔案的知識圖譜能效進行檔案知識推理,是實現檔案智能檢索的關鍵技術和主要路徑之一。然而,作為強領域屬性的檔案領域,當前缺乏系統的基于檔案知識圖譜的構建方法與應用研究。
本文以知識圖譜技術與檔案知識相結合,提出基于大規模檔案領域知識圖譜的構建方法,目的是建立大規模檔案知識圖譜,用于融合語義關系與知識推理的檔案智能搜索系統。論文首先論述了知識圖譜的研究現狀;然后討論了檔案知識圖譜構建的關鍵技術,最后給出結論。
二、研究現狀
知識圖譜技術由Google于2012提出[9],應用于其搜索引擎,用以提高查詢質量。知識圖譜本質是一種語義網絡。其由具有屬性的實體通過關系鏈接而成的網狀知識庫,即具有有向圖結構的一個知識庫,其中圖的節點代表實體或者本體,而圖的邊代表實體——本體之間的各種語義關系。
知識圖譜具有規模大、語義豐富、結構清晰等特點,是人工智能進一步發展的核心技術之一。因此其知識圖譜受到了廣泛的關注,在國外,比較有代表性的知識圖譜產品包括: DBpedia[5], YAGO[6]和Probase[10],這些知識圖譜包括百萬級別的實體及十億級別的關系邊。當前國內針對知識圖譜的研究正快速發展,在開放域方面有百度知心[7]、搜狗知立方[8]、Zhishi.me[11],CNN-DBpedia[12]等。然而這些產品都是通用知識圖譜,直接用于行業領域研究不能達到較好效果。
不同于通用知識圖譜,領域知識圖譜能利用領域特有知識快速構建知識庫,如醫療知識圖譜[13]、地理知識圖譜[14]、軍事知識圖譜[15]及農業知識圖譜[16]等。作為強領域特性的檔案領域,當前仍主要集中在檔案本體知識庫的構建與應用研究,如:賈永剛[17]提出采用五步來構建檔案領域本體。李海軍[18]系統的討論了檔案信息本體在檔案管理信息系統中的使用。張園[19]利用檔案本體來提升檔案檢索系統性能。周義剛和董慧[20]針對電子政務領域的特點,探討電子政務領域數字檔案本體的構建過程。這些本體構建通常采用手動構建。由于本體模型本質上屬性概念級別的知識庫,并不能真正實現語義推理與檢索。本文利用自然語言的處理技術,在人工構建知識本體的基礎,探討檔案知識圖譜的構建關鍵技術研究。
三、檔案知識圖譜構建流程
知識圖譜是一種結構化的語義知識網絡,用于描述現實世界中的概念、實體、事件及其關系,其中實體對應于客觀世界中的事物,屬性代表事物的特征,概念是對具有相同屬性事件的概括與抽象,事件可表示為不同時空狀態下一系列實體及其聯系。通過概念與概念、概念與實體、實體與實體、實體與屬性等之間的關系,形成網狀的語義知識圖譜。
知識圖譜通常采用自頂向下和自底向上2種方式構建。自頂向下構建一般首先頂層關系本體,然后將抽取到的實體及關系更新到所構建的頂層本體中。自底向上構建是指從公開采集的數據中采用一定的技術手段提取出實體關系模式,然后進行一定的知識加工與處理,選擇其中置信度較高的加入到知識庫中,將具有相似屬性的實體進行抽象歸納,形成相應的概念,再逐層向上匯集,最終構建頂層概念本體模式。對于開放領域,由于所涉及知識非常廣泛,通常采用自底向上的方式構建知識圖譜;而對于特定領域,由于知識概念相對明確,一般采用自頂向下的方式構建。由于檔案領域即具有領域性,又具有開放性,本文采用將二者方式相結合,其構建整體流程如圖1所示。具體步驟如下:
1.檔案本體建模:根據檔案管理、檔案信息標準化及應用特點,構建統一共享的檔案領域概念模型,包括本體、關系及屬性。該概念模型將對知識發現起著指導和約束作用。
2.檔案來源:包括從已有檔案業務管理系統、領域百科及其它外部系統中導入數據。其數據類型包括:結構化數據、非結構化數據和半結構化數據。它是知識獲取的主要來源。
3.知識發現:從不同類型數據源在本體概念模型規則約束下進行實體識別、關系抽取與屬性識別。
4.知識融合:對發現的實體、關系與屬性進行知識整合,并進行知識更新。
5.知識存儲與訪問:大規模知識圖譜分布式儲存與訪問。利用圖搜索算法,對存儲知識庫實現高效訪問。

圖1 檔案知識圖譜構建流程
1.檔案知識本體建模
知識本體建模是構建知識圖譜的首要步驟,是對領域知識結構與概念設計的過程。主要包括本體設計、關系設計及屬性設計。檔案本體建模的目標是捕獲檔案領域的知識, 提供對檔案領域知識的共同理解, 確定本領域內共同認可的詞匯, 并從不同層次的形式化模式上給出這些詞匯間相互關系的明確定義。本體作為共享的形式化概念模型,清晰定義概念之間的關系,使得被刻畫的知識富含語義,具有良好的概念層次結構和對邏輯推理的支持。
檔案具有強領域性,檔案通常按主題按單位進行詳細分類,每一檔案都有一明確的目的和主題,表達單一確定事件,例如在文書檔案里,事件通常包括:人事安排、工資提級、機構設置等。事件是動態的復雜的概念,它通常包含是地點、人物、時間等要素。利用事件概念,能明確的描述檔案事件單一性特點,如關于人事安排的檔案,通常包括發文機關、所涉及人物,時間、地點等相關要素。本文主要以檔案標準文件《中國檔案分類法》和《中國檔案主題詞表》為依據,結合檔案自身特點以及系統的業務需要,提出以事件概念為中心的本體構建。以事件為中心概念,然后擴展至其它概念:機構、人物、文件,同時事件還包括地點、時間兩個屬性,對每一概念,又分別進行子類分類,如事件按其內容可分為:人事、學籍、科研、財政等。文件按其用途可分為:通知、公告、決定等。機構劃分為:政府、國企業、私企、事業單位等,人物劃分為公職、商界、公眾。圖2顯示了檔案本體的核心架構。
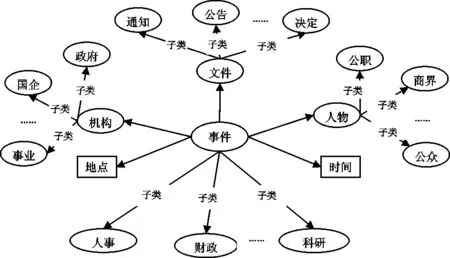
圖2 檔案本體建構核心架構
2.檔案知識抽取模型
檔案領域知識來源主要包括原有業務系統、領域百科、外部系統等結構化、半結構化及非結構化數據。對結構化與半結構化數據,可采用規則方法把實體映射到知識圖譜中;對于非結構化數據主要是檔案文本,需要從中抽取實體及關系等知識。手動的知識抽取代價太高,因此需要采用自然語言處理及機器學習相關技術可實現領域知識的自動識別和抽取。
根據前節所述檔案本體知識架構,從檔案文要識別的本體包括機構、人物、地點、時間及事件。本體關系則包括上下位、子類、近義、反義及所屬事件關系。圖3給出了本文所提檔案領域實體識別與關系抽取流程。首先對檔案全文進行預處理如分詞、詞性標注、句法分析,然后把這些語言特征轉化為分布式表示,進行實體與關系抽取。實體識別采用基于深度學習的Bi-LSTM-CRF模型[21],該模型避免了復雜的特征設計,并且能充分利用全局信息進行優化。在實體識別基礎上,關系抽取采用基于遠程監督的關系抽取模型[22]。該模型能有效減少了模型對人工標注數據的依賴。
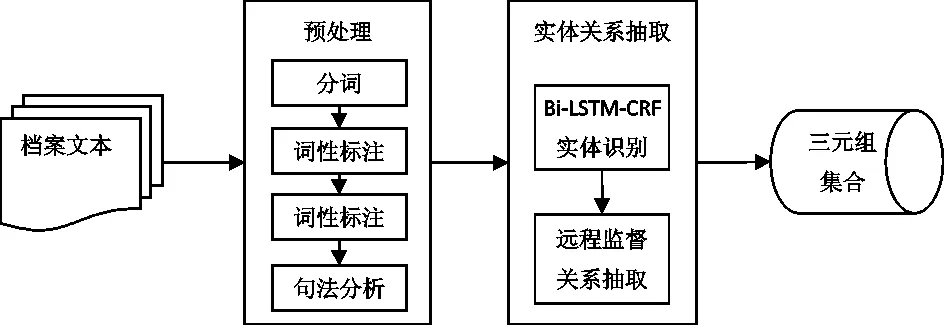
圖3 檔案領域實體識別與關系抽取流程圖
3.知識圖譜存儲與檢索
知識圖譜通常采用圖數據庫存取,在完成檔案知識圖譜構建與存儲之后, 需要利用圖數據檢索技術來提高知識圖譜的查詢效率, 為大規模實時動態查詢和推理奠定基礎。
本文檔案系統采用圖數據庫Neo4j存儲。領域知識中的概念、實體、關系分別對應于Neo4j中的標簽、節點、邊/關系。Neo4j提供Cypher命令對圖數據進行檢索操作。例如對于第1節所述查詢語句:“張三任職局長”。檢索系統首先利用分詞工具對其進行分詞,然后識別出其中的命名實體。可采用如下查詢語句:
Match (a:Person)->[:Person_In]->(m)<-[:Organize_In]-(d) where a.name=‘張三’and a.title=’局長’//查詢事件、機構及人物結點
Match(m)-[File_In]->(f) //查詢所屬文件結點
Return a,m,d,f; //顯示結果
其查詢結果顯示如下圖4所示。
可以看出,利用知識圖譜可以進行深度語義理解與知識推理。知識圖譜是一種開放式的知識結構,如果不考慮存儲工具的限制,理論上基于現有知識圖譜能無限拓展領域相關各種類型知識。
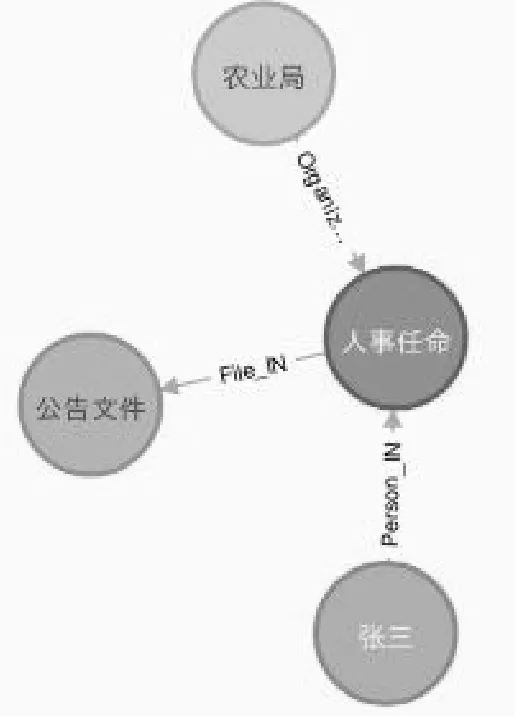
圖4 檔案知識圖譜檢索示意圖
知識圖譜的構建技術主要以數據挖掘、 機器學習、 自然語言處理、 信息檢索等多學科交叉技術為支撐。基于檔案領域既具有領域性,又具有開放性,本文提出檔案知識圖譜構建框架,并探討了檔案知識本體構建架構,檔案知識抽取模型、知識圖譜存儲與檢索等關鍵技術。知識圖譜作為智能檢索的核心技術,具有重要的理論研究和實際應用價值。檔案知識圖譜將在檔案智能化信息管理中發揮重要作用。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
開放教育研究(2020年2期)2020-03-31 01:54:14
現代裝飾(2020年2期)2020-03-03 13:37:44
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
衡陽師范學院學報(2015年2期)2015-02-26 03:24:39
當代修辭學(2011年6期)2011-01-29 02:49:50
