基于CNN集成的面部表情識別
2020-05-20 15:05:18陸嘉慧張樹美趙俊莉
青島大學學報(工程技術版) 2020年2期
陸嘉慧 張樹美 趙俊莉

摘要:針對面部表情識別在許多領域的重要應用,本文提出了一種基于卷積神經網絡(convolutional neural network,CNN)集成的面部表情識別(facial expression recognition,FER)方法。采用3種網絡結構不同的卷積神經網絡進行訓練,利用這些深層模型,使用基于驗證準確性的多數投票、簡單平均和加權平均的集合方法,在CK+數據集和FER2013數據集上分別測試單一網絡模型和集合網絡模型。測試結果表明,單一模型的最佳識別率分別為98.99%和66.45%,集合網絡的最佳識別率分別達到99.33%和67.98%,說明使用集合方法的模型比單一模型表現更佳,其中加權平均的集合方法優于簡單平均和多數投票,說明本文所提出的方法能夠滿足面部表情識別的要求。該研究具有一定的實際應用價值。
關鍵詞:表情識別; 卷積神經網絡; 網絡集合; 表情數據集
中圖分類號: TP391.413文獻標識碼: A
面部表情是表達內心世界最自然的方式,它在社會交往中起著至關重要的作用。20世紀70年代初期,D. Ekman等人[1]提出所有文化中都存在6種普遍的情感表達,即驚訝、悲傷、憤怒、厭惡、快樂和恐懼。近年來,面部表情識別的調查引起了廣泛關注[23],A.Krizhevsky等人[4]認為基于深度學習的新方法可以改善面部表情分類任務,尤其是ImageNet Challenge的最新改進以來,使CNN代表了相關的突破。CNN將特征提取和分類結合在一起,通過輸入原始數據得到最終的分類標簽,不需要任何輔助過程。擁有數千萬參數的CNN可以處理大量的訓練樣本,自動從網絡中學習特征,不需要手工提取。目前,這些端到端方法通過使用深度學習分類器的集合進行改進,整體由一組CNN組成,它聚合每個分類器的部分結果,以在測試時間內產生統一的響應。T. Connie等人[5]將SIFT特征與從原始圖像中學習的CNN特征合并,提高FER性能;H. Jung等人[6]提出了深度網絡結合時間外觀特征和一組特定面部地標的時間幾何;Ding H等人[7]先用正則化約束調整CNN權重,再添加全連接的圖層,這些圖層在初始階段的預訓練特征之上學習分類參數;Yu Z等人[8]通過可學習權重將多個CNN模型結合在一起,以最大限度地減少鉸鏈損失;B. K. Kim等人[9]提出了基于驗證準確性的指數加權平均值,以強調合格的個體,并通過實施多數投票或更高層次的簡單平均,構建委員會的等級架構;G. Pons等人[10]使用不同大小的濾波器和全連接層中不同數量的神經元來構建各種CNN;Yu Z[11]通過使用對數似然損失和鉸鏈損失來自適應地為每個網絡分配不同的權重。使用CNN集合可以勝過單個CNN分類器,單一的CNN分類器在應用中常常受到一定條件的限制,而集合CNN融合各單分類器判別信息的同時,實現了各分類器之間優缺點的互補。因此,尋求提高分類性能的方法構造好的組合分類器非常重要。本文提出了一種基于卷積神經網絡集成的面部表情識別方法,該方法能夠滿足面部表情識別的要求。該研究可使面部表情識別應用到眾多領域。
1集成CNN的構建方法
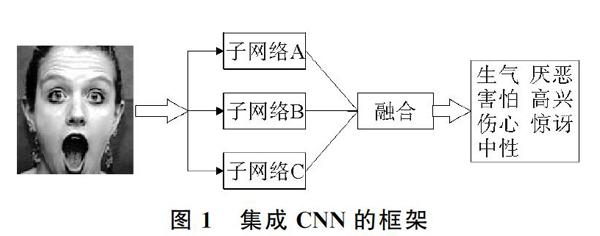
使用一組CNN組成的框架可提高識別過程的準確性。集成CNN的框架如圖1所示。為了獲得最佳性能,CNN的集合必須是多樣的,以在集合時提高整個框架的識別能力。為了尋求有效的網絡設計完成任務,易于訓練,選擇適當的集合方法執行這組CNN。受VGG Net[12]提供的整潔結構的啟發,本文設計了3個不同的結構化子網絡,分別包含3,5,10個卷積層,將子網絡定義為i,i=[A,B,C]表示這3個子網。
1.1預處理
在FER2013[13]和Extended Cohn-Kanade(CK+)[14]數據集上測試該模型。FER2013是野外面部表情圖像數據集,在ICML 2013表征學習挑戰中,包含28 709個訓練圖像,3 589個驗證和3 589個測試,分為7種類型的表情,即憤怒、厭惡、恐懼、快樂、悲傷、驚喜和中立。由于標簽噪聲,此數據的人為準確度為(65±5)%。FER2013的所有類別都有比CK+更多的圖像。CK+是實驗室控制的標準表情數據集,其樣本數量很少,由來自123個受試者的593個序列組成,其中327個序列具有基于FACS的情緒標記。每個圖像分配:驚訝、悲傷、快樂、憤怒、蔑視、厭惡和恐懼7種表情之一。CK+和FER2013數據集的7種表情示例如圖2所示。由于每個圖像具有不同的姿勢,因此FER2013數據集中的圖像更具挑戰性。
在圖像預處理過程中,對CK+數據集運行2個步驟來減少原始圖像中的干擾,即人臉檢測和直方圖均衡化。在面部檢測部分中,檢測結果基于OpenCV中的Haar-like特征,這是用于面部檢測的最經典的特征之一,它可以減少需要處理的數據量,并有效地避免圖像中不同背景和其他對象對識別結果的干擾。在獲取圖像的正面部分之后,還應考慮其他麻煩的問題。由于拍照時的光照條件不同,人臉部分也會出現不同的亮度,這不可避免地會對識別結果造成很大的干擾。因此,在識別之前進行直方圖均衡化(histogram equalization,HE)。HE是一種簡單但有效的圖像處理算法,可以使不同圖像中的灰度值分布更均勻,減少不同光照條件下的干擾,更好地呈現重要特征,并且盡可能統一所有圖像。
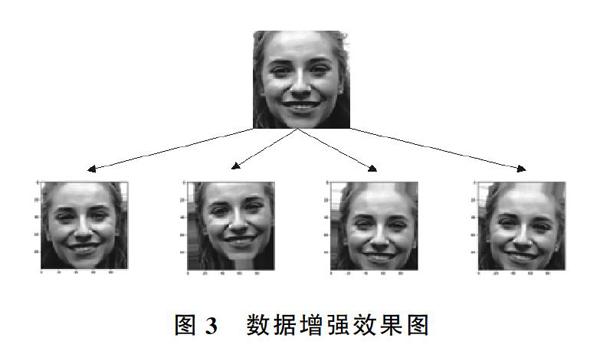
將兩個數據集所有圖像的大小標準化為100×100像素。為了使模型對噪聲和輕微變換更加魯棒,采用了數據增強。數據增強利用多種能夠生成可信圖像的隨機變換來增加樣本,即從現有的訓練樣本中生成更多的訓練數據,使模型在訓練時不會兩次查看完全相同的圖像,可觀察到數據的更多內容,具有更好的泛化能力。變換包括水平翻轉,在(-10,10)之間具有隨機角度的旋轉以及水平和豎直方向隨機移動0.1比例,數據增強效果圖如圖3所示,所有圖像都被歸一化為零均值和單位方差。
所有實驗都是在NVIDIA GeForce MX150 GPU上使用TensorFlow開發,內存為8 GB。TensorFlow是一個將復雜數據結構傳輸到人工神經網絡進行分析和處理的系統,使用數據流圖進行數值計算,它可以用在很多深度學習領域,如語音識別和圖像識別等。
1.2子CNN結構
CNN結構主要由卷積層、池化層和全連接層構成。卷積層的作用是實現由一些卷積核組成的特征提取,對輸入圖像上做卷積運算,加上偏移量,并將結果輸出到激活函數中以獲得輸出,減少了網絡參數的數量,降低了參數選擇的復雜性。圖像可以直接作為網絡輸入,避免了傳統方法中復雜的特征提取和數據重建表13個子網絡模型配置比較過程。池化層可以保持某種不變性(旋轉、平移、縮放等)。卷積層的作用是檢測上一層特征的局部連接以實現特征提取,而池化層的作用是結合相似的特征。池化層通常與卷積層一起使用,通過降采樣來減小尺寸,從而得到特征的不變性。常見的降采樣方法包括最大池、平均池等。全連接層是輸入輸出層神經元的全部連接,由于卷積運算是一種線性運算,因此生成的特征也是一種線性特征。
本文構建了3個從頭開始設計的自定義CNN網絡架構。3個子網絡配置比較如表1所示,建立3種不同的網絡架構,保證網絡的多樣性,由于卷積層的數量不同,可以學習不同的特征,卷積層越多,子網絡學習到的特征就越細微。
子網絡A由3個卷積層和3個最大池化層組成,卷積濾波器的數量分別為32,64,128,過濾器的窗口大小為11×11,5×5,3×3;子網絡B由10個卷積層和4個平均池化層組成,卷積濾波器的數量分別為16,32,64,128,256,7,過濾器的窗口大小為7×7,5×5,3×3,最后應用全局平均池化,一個特征圖全局平均池化后再進行Softmax會減少很多參數。子網絡C由5個卷積層和3個最大池化層組成,子網絡A和子網絡C最后都是兩個密集的全連接層。每次添加最大池化層時,下一個卷積濾波器的數量都會翻倍,且最大池化層大小均為2×2。最大池化層用于總結濾波器區域,該濾波器區域被視為一種非線性下采樣,有助于提供一種平移不變性,并減少了更深層的計算。
1.3集成方法
在描述了前3個子網之后,為CNN構建整體架構(見圖1),該模型包括2個階段。第1階段將面部圖像作為輸入,并將其提供給3個CNN子網。3個子網設計緊湊,易于訓練,是架構的核心組件;第2階段負責根據前一階段輸出預測表情,將這些子網絡輸出結合起來,以獲得最準確的最終決策。使用不同CNN來解決諸如情感識別之類復雜問題的主要優點是它們可以相互補充。在訓練多個CNN時,有的在識別某些情緒時會比其他更好。
決策級集合最常用的規則是多數投票規則、簡單平均規則和加權平均規則。在多數投票規則中,每個CNN獲得的預測類別標簽,可用于確定具有最高票數的類別,將多數分類器預測結果作為最終分類結果,即
其中,mod e為眾數;A,B,C分別是3個子網絡模型。簡單平均規則使用從每個分類器產生的與類相關的分數,而不是使用標簽。因此,從子網絡A、子網絡B和子網絡C中獲得平均分數最高的類作為最終輸出,從而提高模型的準確性。輸入圖像x屬于表情e的概率為
加權平均使用每個有不同權重的分類器產生的與類相關的分數,獲得平均分數最高的類作為最終輸出,輸入圖像x屬于表情e的概率為
通常要求wi≥0,w1+w2+w3=1。每一個模型都以Softmax層作為最后一層,輸出范圍在0~1,輸出最高概率的表情為最佳匹配表情,即
通過這種架構,將人臉圖像映射到7個基本表情標簽之一,結合不同結構化CNN模型結果,使它們成為整個網絡的一部分。使用決策以獲得更好的性能,因為每個CNN子網都會產生一些錯誤,并且它們在協同工作中互補。
2訓練過程
考慮小數據集引起的過擬合,在卷積層和全連接層之后仍然會添加dropout,通過防止特征提取器的共同適應,即它可以創建不依賴于彼此的特征,產生有用的輸出來降低網絡過度擬合的風險,增加網絡的泛化能力。為了提高網絡的非線性特性,本文使用線性整流函數(rectified linear unit,Relu)作為激活函數。對于任何給定的輸入值x,Relu定義為
其中,x是神經元的輸入。使用Relu激活函數可避免由其他一些激活函數引起的消失梯度問題。在網絡最后階段,放置具有7個輸出的Softmax層,將單個節點的輸出變成一個概率值,神經元的原始輸出不是一個概率值,實質上是輸入的數值x做了復雜的加權和與非線性處理之后的一個值zi,即
其中,wij是第i個神經元的第j個權重;b是偏移值。給這個輸出加上一個Softmax函數,即
其中,Si是第i個神經元的輸出概率。將與Softmax分類器相對應的交叉熵方法用作損失函數,交叉熵損失函數是用來判斷實際輸出概率與期望輸出概率的距離,即交叉熵的值越小,兩個概率分布越接近,設概率分布p為期望輸出,概率分布q為實際輸出,H(p,q)為交叉熵,則
網絡使用Adam[15]進行優化,Adam是一種基于自適應梯度的優化方法。在訓練過程中,還引入了批量歸一化層(batch normalization,BN)[16]和L2正則化,以提高訓練速度,降低網絡的擬合能力。
2.1批量歸一化
神經網絡的學習過程本質上是為了學習數據的分布規律。一方面,若每批訓練數據的分布各不相同,網絡則需要每次迭代去學習和適應不同的分布,這樣會大大降低網絡的訓練速度;另外,如果訓練數據與測試數據的分布不同,則網絡的泛化能力會很大程度降低。除此之外,數據分布對激活函數也極為重要,數據分布范圍太大,不利于利用激活函數的非線性特性,為了緩解這些問題,提出了BN。因此,在每層網絡輸入時,插入一個歸一化層,即先做歸一化處理,然后再進入網絡的下一層,它是一個可學習、有參數的網絡層。
BN算法具有提高網絡泛化能力的特性,并且BN在實際應用中收斂非常快,因此可以選擇更小的L2正則約束參數,不需要使用局部響應歸一化層,因BN本身就是一個歸一化網絡層。此外,它可以徹底打亂訓練數據,防止每批訓練時某一個樣本被經常選到。
2.2L2正則化
在數據集有限的情況下,另一種防止過擬合的方式就是降低模型的復雜度。在損失函數中加入L2正則化項,L2正則化傾向于使網絡的權值接近0,降低了前一層神經元對后一層神經元的影響,使網絡變得簡單,降低了網絡的有效大小,也就意味著降低了網絡的擬合能力。實質上L2正則化是對權值做線性衰減。相比于初始的交叉熵損失函數,訓練過程中的損失函數多了最后的正則化項,即
其中,λ>0為正則化參數;n為訓練集包含的實例個數。L2正則化項是指w的平方項,該項實質上是神經網絡中的權重之和。
在神經網絡中,正則化網絡更傾向于小的權重,這樣數據x隨機變化不會對神經網絡模型造成太大影響,所以受數據局部噪音的可能性影響更小。而未加入正則化的神經網絡權重大,易通過較大的模型改變來適應數據,更容易學習到局部的噪音。
3實驗結果與討論
采集CK+數據集2 940張,FER2013數據集28 709張,為測試算法的有效性,實驗采取五折交叉驗證方法。將數據集隨機分成5份,其中4份用作訓練,1份用作測試,進行5次實驗,最后取5次實驗結果的平均值。
基于CNN集成的表情識別由2個階段組成。在訓練階段,構建了所有單獨的分類器,在測試階段,實現融合方法得出面部圖像的最終分類。為了產生不同的結果,構建最佳組合方法。首先構建3個深度CNN,這3個子網絡分開訓練,共享一個類似的模式。通過應用各種網絡體系結構及隨機初始化訓練深層模型。在兩個數據集上,對當前最先進的方法進行比較,不同模型的分類精度比較如表2所示。
經過交叉驗證,子網絡B的識別率最佳,在CK+數據集上達到98.99%,在FER2013數據集上達到66.45%,證明使用小濾波器不僅可以減少參數數量,還可以提高深度神經網絡的準確率。
從實驗中得出訓練多個學習器并將其結合,使用結果明顯超過當前的先進方法,采用集合方法的識別率優于單一模型的識別率,通過訓練多個子網絡模型,提取不同的互補深度特征表示,從而提高了網絡模型性能。其中,加權平均的集合方法在CK+和FER2013數據集上表現最佳,這是由于加權平均方法考慮了個體的重要性和置信度,這里將子網絡B的權重設置要比其他子網絡大一些。模型在CK+數據集上7種表情評估結果如表3所示,模型在FER2013數據集上7種表情評估結果如表4所示。由表3和表4可以看出,表情“高興”的準確率非常高,這也是人類最容易識別的表情。
4結束語
本文提出了一個基于集合CNN的面部表情識別方法,根據子網絡產生的后驗概率訓練CNN,允許捕獲子網絡成員之間的非線性依賴關系,并從數據中學習這種組合。構建了3個結構不同的子CNN,以保證網絡的互補性,這些子網在訓練集上分別訓練。同時為了提高網絡的泛化能力和識別率,在網絡中加入了L2正則化和批量規范化,使用多數投票、簡單平均和加權平均的集成方法,通過后驗概率找到最優集合方式,在CK+標準數據集和FER2013野外數據集中進行評估。該研究與單個CNN模型相比,網絡架構通過組合和平均不同結構CNN的輸出,報告了更好的性能,在實驗的準確度方面取得優異結果。在更大的數據集中對網絡進行研究,設計不同的目標函數,訓練子CNN是下一步研究的重點,并且對集成方法進行深入研究,以獲得更多樣化的網絡集合方法,進一步提高面部表情識別精度。
參考文獻:
[1]Keltner D, Ekman P, Gonzaga G C, et al. Facial expression of emotion[J]. Encyclopedia of Human Behavior, 2012, 30(1): 173183.
[2]Sariyanidi E, Gunes H, Cavallaro A. Automatic analysis of facial affect: a survey of registration, representation, and recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(6): 11131133.
[3]Corneanu C A, Oliu M, Cohn J F, et al. Survey on RGB, 3D, thermal, and multimodal approaches for facial expression recognition: History, trends, and affect-related applications[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2016, 38(8): 15481568.
[4]Krizhevsky A, Sutskever I, Hinton G E. Imagenet classify cation with deep convolutional neural networks[C]∥NIPS Curran Associates Inc. Nevada: NIPS, 2012: 10971105.
[5]Connie T, Al-Shabi M, Cheah W P, et al. Facial expression recognition using a hybrid CNN-SIFT aggregator[C]∥International Workshop on Multi-Disciplinary in Artificial Intelligence. Gadong, Brunei: MIWAI, 2017: 139149.
[6]Jung H, Lee S, Yim J, et al. Joint fine-tuning in deep neural networks for facial expression recognition[C]∥2015 IEEE International Conference on Computer Vision. Santiago: ICCV, 2015: 29832991.
[7]Ding H, Zhou S H K, Chellappa R. Facenet2expnet: regular izing a deep face recognition net for expression recognition[C]∥ 2017 12th IEEE Computer Society. Washington: IEEE, 2017: 118126.
[8]Yu Z D, Zhang C. Image based static facial expression recognition with multiple deep network learning[C]∥Acm on International Conference on Multimodal Interaction. denver, USA: IEEE, 2015: 435442.
[9]Kim B K, Lee H, Roh J, et al. Hierarchical committee of deep CNNs with exponentially-weighted decision fusion for static facial expression recognition[C]∥ Emotion Recognition in the Wild Challenge @ ACM International Conference on Multimodal Interaction. USA: ICMI, 2015: 427434.
[10]Gerard P, David M. Supervised committee of convolutional neural networks in automated facial expression analysis[J]. IEEE Transactions on Affective Computing, 2018, 9(3): 343350.
[11]Yu Z D, Zhang C. Image based static facial expression recognition with multiple deep network learning[C]∥Acm on International Conference on Multimodal Interaction. Seattle: ACM, 2015: 435442.
[12]Simonyan K, Zisserman A. Very deep convolutional networks for large-scale image recognition[C]∥International Conference on Learning Representations, 2015: 114.
[13]Goodfellow I J, Erhan D, Carrier P L, et al. Challenges in representation learning: a report on three machine learning contests[C]∥Neural Information Processing. Berlin: Springer Berlin Heidelberg, 2013: 117124.
[14]Lucey P, Cohn J F, Kanade T, et al. The extended cohn-kanade dataset (CK+): a complete dataset for action unit and emotion-specified expression[C]∥2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition-Workshops. San Francisco, CA, USA: IEEE, 2010: 94101.
[15]Kingma D P, Ba J. Adam: A method for stochastic optimization[C]∥International Conference on Learning Representations. San Diego: LCLR, 2015.
[16]Ioffe S, Szegedy C. Batch normalization: accelerating deep network training by reducing internal covariate shift[C]∥International Conference on Learning Representations. 2015.
[17]Liu M, Li S, Shan S, et al. AU-inspired deep networks for facial expression feature learning[J]. Neurocomputing, 2015, 159: 126136.
[18]Mollahosseini A, Chan D, Mahoor M H. Going deeper in facial expression recognition using deep neural networks[C]∥2016 IEEE Winter Conference on Applications of Computer Vision (WACV). Lake Placid: IEEE, 2016: 110.
[19]Goodfellow I J, Erhan D, Carrier P L, et al. Challenges in representation learning: a report on three machine learning contests[J]. Neural Information Processing, 2013, 8228: 117124.
[20]Arriaga O, Valdenegro-Toro M, Plger P, et al. Real-time convolutional neural networks for emotion and gender classification[C]∥Computer Vision and Pattern Recognition. Octavio Arriaga: ICAR, 2018.
收稿日期: 2019-09-23; 修回日期: 2019-12-17
基金項目:中國博士后科學基金資助(2017M622137);國家自然科學基金資助(61702293);教育部虛擬現實應用工程研究中心基金資助(MEOBNUEVRA201601)
作者簡介:陸嘉慧(1995-),女,山東青島人,碩士研究生,主要研究方向為圖像識別與處理、深度學習。
通信作者:張樹美(1964),女,山東萊西人,博士,教授,碩士生導師,主要研究方向為時滯非線性系統的分析與控制、圖像識別與處理。 Email: shumeiz@163.com
