基于強化學習的DASH自適應碼率決策算法研究
2020-05-27 12:55:00馮蘇柳姜秀華
中國傳媒大學學報(自然科學版) 2020年2期
關鍵詞:策略
馮蘇柳,姜秀華
(中國傳媒大學信息與通信工程學院,北京100024)
1 引言
隨著無線通信技術的飛速發展和智能手機、平板電腦、移動電視等視頻觀看設備的多樣化,內容提供商和用戶對可變網絡環境下提供高QoE(用戶體驗質量)視頻流服務的需求不斷增加。在這樣的背景下,能夠根據網絡環境動態調節請求碼率以最大化QoE的自適應流媒體傳輸應運而生。目前基于HTTP的動態自適應流媒體傳輸(MPEG-DASH)標準具有覆蓋廣泛、兼容性良好、部署較簡便等特性,成為自適應流媒體傳輸的研究重點。在DASH中,一個視頻流被切割成固定時長的分片,每個分片存儲有多種碼率,客戶端的播放器根據當前網絡狀況以及播放信息,采用碼率自適應(ABR)決策算法,選擇下個分片請求的最優碼率。DASH標準中并沒有指定ABR算法,所以存在很大的研究空間。ABR算法的總體目標是:1)避免由緩沖區下溢引起的播放中斷,即重緩沖;2)最大化視頻質量;3)最小化視頻質量切換次數及幅度以保證視頻播放平滑度。而實現最優的ABR算法存在著以下挑戰:1)動態網絡環境下實現精確的吞吐量預測難度較大;2)ABR算法必須平衡各種QoE指標,但這些指標存在著內在沖突,例如高碼率和重緩沖;3)當前的碼率決策會對后續的決策產生級聯效應;4)ABR算法可用的決策碼率是粗粒度的,僅限于給定視頻的可用碼率。所以對ABR算法的研究一直在不斷提升中。
目前基于客戶端的ABR算法主要有基于吞吐量、基于緩沖和基于混合/控制理論這三類,但這些算法都存在局限性,即它們都使用基于特定環境的低準確性的建模來實現固定的控制算法,這使它們很難捕獲和反映真實網絡環境中動態網絡的變化情況,并且很難在不同的網絡環境下和不同的QoE目標上實現最佳決策。強化學習(RL)作為新興的機器學習方法,通過學習環境的動態特性,反復試驗并通過反饋的回報不斷調整執行策略,逐漸收斂到最優策略,目前已廣泛應用于無人駕駛、智能控制機器人等領域。近幾年開始有研究將強化學習應用于ABR算法并取得了比啟發式算法更好的效果。所以,采用強化學習來研究自適應流媒體傳輸中的ABR算法,為用戶提供更加智能化的視頻流服務,對提升用戶體驗質量,具有重大的意義。
本文采用了強化學習和深度神經網絡相結合的深度強化學習算法,對動態網絡環境下的DASH客戶端碼率決策算法進行優化。
本文第二章介紹目前的基于客戶端的碼率自適應算法研究現狀,第三章介紹本文所采用的的基于深度強化學習的碼率決策算法,第四章為實驗部分,新算法和現有算法進行比較并分析,最后一章為結論。
2 研究現狀
目前基于客戶端的ABR算法主要有基于吞吐量、基于緩沖和基于混合/控制理論這三類。
文獻[1]提出了一種基于TCP的AIMD算法,使用平滑的吞吐量測量來探測空閑網絡容量并檢測擁塞,漸進向上切換碼率,檢測到網絡擁塞時乘性減小碼率。文獻[2]提出了一種多個商業DASH播放器共享瓶頸鏈路,基于公平性、效率和穩定性三個評估指標的碼率自適應算法,采用歷史吞吐量的調和均值估計當前帶寬,并且采用有狀態和延遲的碼率更新以及隨機下載塊調度。文獻[3]提出了一種基于緩沖區的碼率自適應算法,構建了基于重緩沖、分片質量和質量切換的QoE模型,并表示為非線性隨機最優控制問題,設計了基于動態緩沖區的PID控制器,該控制器可以確定每個分片的比特率并穩定緩沖區級別。文獻[4]提出了基于緩沖區的Lyapunov 算法(BOLA),將碼率自適應表示為效用最大化問題,并使用Lyapunov優化技術來求解最優策略。BOLA現在是dash.js中實驗算法的一部分。文獻[5]提出了一種基于模型預測控制(MPC)的算法,該算法結合吞吐量和緩沖區占用反饋信號,使用過去5個塊的吞吐量調和均值進行吞吐量預測,并采用CPLEX等現有技術來解決QoE優化問題。他們還提出了robust-MPC[6],其控制器等效于吞吐量取下限估計值輸入的MPC。
近年來開始出現了基于馬爾可夫決策過程(MDP)的碼率自適應算法,將碼率決策模型化為有限狀態的MDP,在波動的網絡環境下做出決策。文獻[7]提出了基于Q-learning算法的控制算法,客戶端通過學習網絡環境的動態特性,根據每個狀態下不同動作的Q值選擇當前的最佳動作,并更新狀態-動作值Q表。與現有的啟發式算法相比,QoE增加了9.7%。文獻[8]將狀態空間減少為兩個變量:緩沖區級別和可用帶寬,并簡化了回報函數。文獻[9][10]也提出了一種基于Q-learning的控制模型,改進之處主要在于對回報函數的調整。但由于Q-learing算法要求狀態空間必須是離散的以及維度災難問題,因此出現了使用神經網絡來逼近價值函數的深度Q-learning算法(DQN)。文獻[11]采用double-DQN,其主網絡輸出不同動作的近似Q值,目標網絡輸出目標Q值。D-DASH[12]根據分片大小來估計SSIM代替碼率來作為分片質量度量標準[13],還使用混合神經網絡框架,包括前饋神經網絡和循環神經網絡。Pensieve[14]采用A3C算法,該算法結合了策略梯度和基于值函數的方法,用值函數來指導策略更新,取得了更高的QoE值。
本文同樣采用了深度強化學習的方法,通過學習環境的動態特性做出決策,并根據回報來調整策略,強化學習算法本文采用了OpenAI推出的將值迭代和策略梯度算法相結合的近似策略優化算法(PPO)[15]。
3 基于并行PPO的ABR算法研究
3.1 PPO算法簡介
強化學習采用近端策略優化算法(PPO),PPO是2017年OpenAI推出的一種新的基于Actor-Critic算法。本文選用該算法的原因是PPO結合了策略梯度算法和值函數的優勢,但是之前的策略梯度算法存在著學習步長難以確定的問題,在訓練過程中新舊策略的的變化差異如果過大,相當于用了一個較大的學習率,不利于學習。而PPO提出了新的目標函數,經過理論推導得出只要策略參數朝著增大目標函數的方向更新,就可以保證策略的期望回報是單調遞增的,解決了策略梯度算法中步長難以確定的問題。
原始的AC算法的策略網絡的損失函數如式(1)所示。
(1)
其中pθ(st,at)為狀態s下采取動作a的概率,優勢函數Aθ(st,at)的含義是在狀態s下采取動作a所獲得的價值相比于平均價值有多好,損失函數的含義是增大獲得較大回報價值的動作發生的概率。

(2)
為了保證策略的回報期望是單調遞增,PPO限制新舊策略不能相差過大。PPO有兩種算法,第一種是PPO-penalty,目標函數如式(3)所示,增加了兩個策略的KL散度懲罰項。
KL散度的系數β隨KL散度而變化,若大于設定目標值,則增大懲罰系數使得參數朝著減小KL散度的方向更新,反之亦然。
(3)
第二種是PPO-clip,它不在損失函數中加KL散度懲罰項,而是直接對式(3)的第一部分進行裁剪,限制在預設范圍(1-ε,1+ε)內,損失函數如式(4)所示。
(4)
為了增加模型探索性,在目標函數中加入了概率熵,熵權值隨著訓練次數增加而減小。
本文將實現PPO-penalty和PPO-clip這兩種算法。
3.2 算法實現
3.2.1 強化學習元素
狀態選用六種特征,包括過去k個視頻塊的吞吐量測量矢量;過去k個視頻塊的下載時間矢量,代表了吞吐量測量的時間間隔;下一個視頻塊的可下載大小的矢量,矢量長度為可選碼率數量;當前緩沖水平;視頻還存留的塊數;上一個塊下載的碼率。
回報函數選用了ABR算法中常用的線性Qoe模型,包括三個部分:媒體分片質量、重緩沖事件、碼率切換事件,如式(5)所示。碼率切換部分需要先判斷當前緩沖是否小于預設最低閾值,若小于預設閾值,則獎勵減小決策碼率的行為,懲罰增大碼率的行為;若大于預設閾值,則懲罰減小決策碼率的行為,獎勵增大碼率的行為。
(5)
3.2.2 網絡框架
本文采用PPO結合神經網絡的算法,包括actor策略網絡和critic值網絡,網絡框架圖如圖1所示。
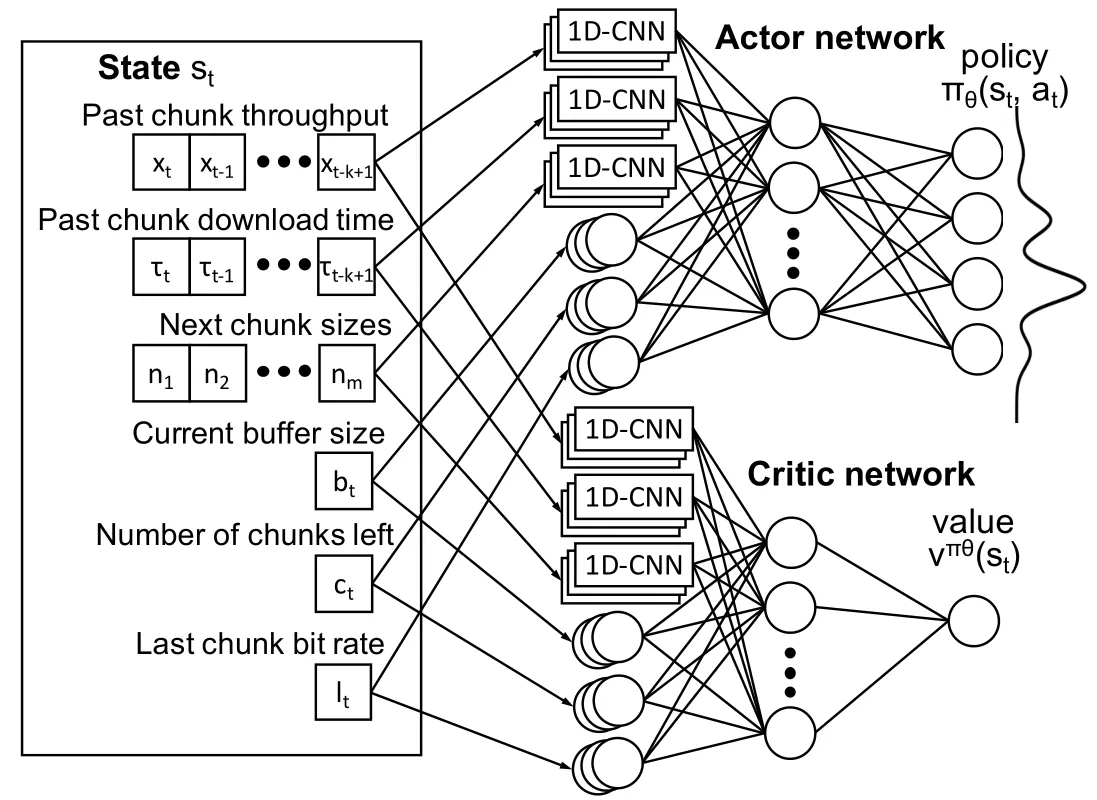
圖1 PPO算法框架
Actor網絡和Critic網絡的輸入層和隱藏層設置相同。輸入層為6個狀態特征,輸入的狀態中的三個序列,包括吞吐量、分片下載完成時間、當前分片大小列表,經過一個一維卷積層,卷積層的size為4,濾波器個數設置為128。輸入狀態的其他單值特征則輸入一層全連接層,節點數設為128,然后第一層隱藏層的所有輸出合在一起輸入一層全連接層,最后接輸出層。
Actor網絡的輸出層為softmax層,輸出節點數為動作數量,對應輸入狀態s下不同動作a對應的概率分布p(a|s),Critic網絡的輸出層為全連接層,輸出節點為1,對應為輸入狀態s的狀態價值V(s)。
3.2.3 算法訓練
本文采用并行訓練的方法訓練PPO算法,即采用多個不同訓練環境采集樣本,可以提升訓練速度,并且樣本分布更加均勻,更利于網絡的訓練。相比于值函數方法中用經驗池來存儲歷史樣本,再隨機抽取樣本訓練,并行訓練可以大大地節省存儲空間。并行訓練的框架如圖2所示。
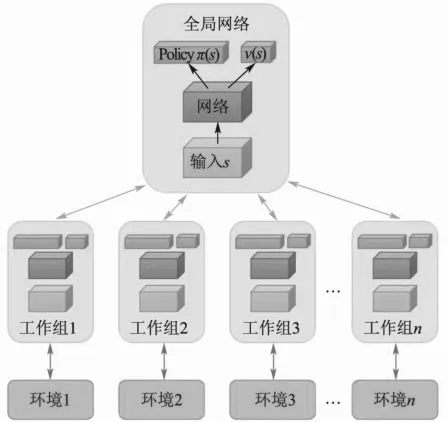
圖2 并行訓練框架
各個agent在各自的環境下進行不斷決策,獲取到決策軌跡(s,a,r,s_next),然后積累到一定樣本時送到central_agent,對網絡參數進行更新,更新完之后把參數復制給agent網絡。
本文采用了兩種并行訓練的方式,一種是同步并行,即等所有agent采集完足夠的樣本,把所有agent的(s,a,r,s_next)送入到central_agent,計算梯度然后更新網絡參數,更新完后把參數分發給各個agent。另一種是異步并行,即只要有一個agent采集完足夠的樣本,就把該agent的(s,a,r,s_next)送入到central_agent,計算梯度然后更新網絡參數,更新完后把參數分發給該agent。本文將同時采用這兩種訓練方式。
4 實驗結果
4.1 實驗準備
測試視頻選用DASH-246 JavaScript參考客戶端的“Envivio-Dash3”序列,該視頻采用H.264/MPEG-4編碼,總時長為193秒,被分割成48個分片,每個分片的可用碼率包括{300,750,1200,1850,2850,4300}六種,分片時長為4秒。訓練和測試的網絡軌跡選用挪威收集的3G / HSDPA移動數據集,由傳輸過程中(如通過公交、火車等)流媒體視頻的移動設備生成。訓練集包含了127個軌跡文件,每個文件包括300-1500個時刻的吞吐量測量值;測試集包含了147個軌跡文件,每個文件只有50-250個時刻的吞吐量測量值。吞吐量范圍在0.2~6Mbps。本實驗是在ubuntu16.04的Pycharm中下進行仿真,模擬碼率決策和分片下載過程。
4.2 實驗結果
采用PPO-clip的算法,且同步并行訓練。輸出本課題算法及現有算法在測試軌跡集上的總回報均值,如表1所示。
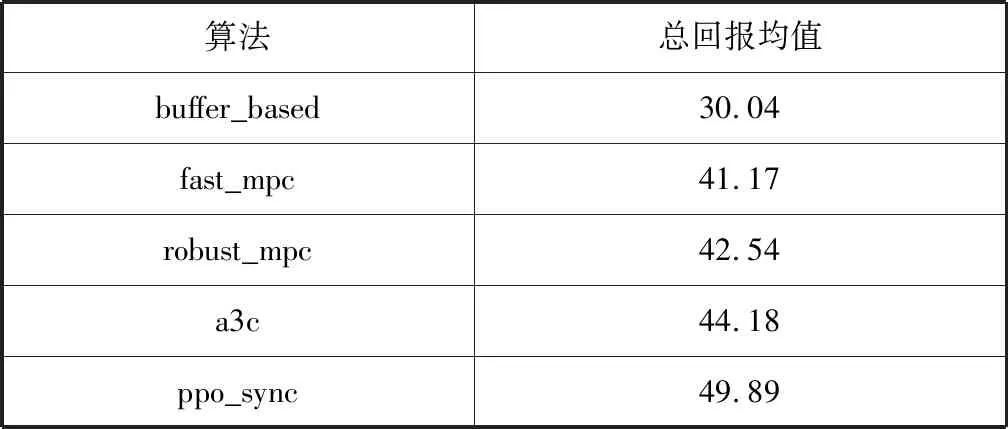
表1 不同算法在各個測試軌跡的總回報均值
可以看出,本文的算法在相同的測試軌跡下獲得的總回報均值要高于現有算法。繪制不同算法在測試軌跡集上的總回報的累積分布曲線,如圖3所示。
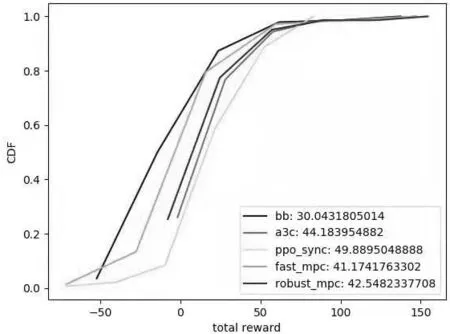
圖3 不同算法在測試軌跡上的總回報累積分布曲線
可以看出,在橫軸相同的區間范圍內,本文算法在縱軸的比例較大,說明PPO算法落在較高回報值區間的比例最大。
隨機選取一個軌跡,輸出各個算法在測試軌跡下的碼率選擇,緩存區余量,帶寬隨時間變化曲線,如圖4所示。
可以看出,PPO算法能夠保證選擇較高碼率并且較穩定,碼率切換頻率較小,并且能夠充分利用緩沖,在吞吐量即使較小時,如果緩沖區較充足,仍然選擇較大碼率,同時在緩存區低于門限值時能夠立即減小碼率。
選用ppo-pen、ppo-clip和同步并行、異步并行組合訓練,輸出四種方法下在測試軌跡集上的總回報均值,如表2所示。
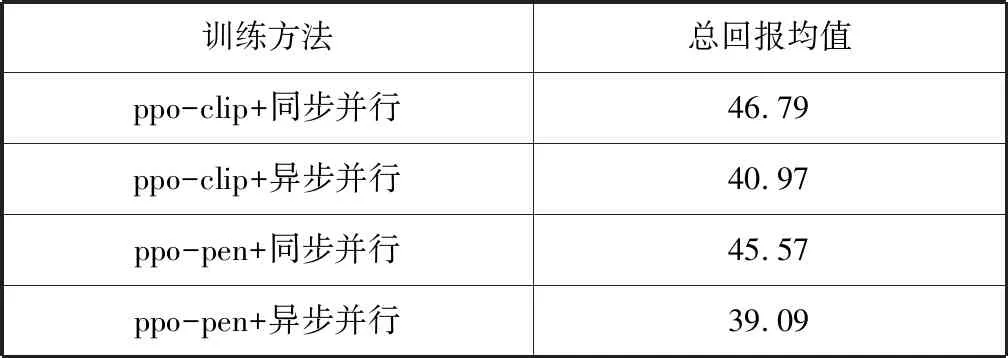
表2 ppo-pen、ppo-clip及同步并行、異步并行組合訓練在測試軌跡上的總回報均值
從ppo算法上看,ppo-clip總回報值要略高于ppo-pen,從并行訓練方式上看,同步并行總回報值較高于異步并行。
從ppo算法分析,從式(3)和式(4)可以看出,ppo-clip是直接對新舊策略的比值進行一定程度的裁剪,可以保證兩次更新之間的分布差距不大。從并行訓練方式分析,異步并行會導致過期梯度情況,即cenral_agent在更新當前網絡參數時使用的從agent傳來的梯度可能是多次更新之前的參數,這樣會導致梯度下降的過程變得不穩定,而實驗中輸出agent使用的參數,小于當前central_agent的參數版本在10-16,充分說明過期梯度的問題。對于這個問題,目前有研究提出給梯度增加延時補償,利用梯度函數的泰勒展開來有效逼近損耗函數的Hessian矩陣。
輸入狀態的時間序列長度slen分別設置為1,4,8,16,采用ppo-clip及同步并行訓練,輸出這四種設置在測試軌跡上的總回報均值,如表3所示。
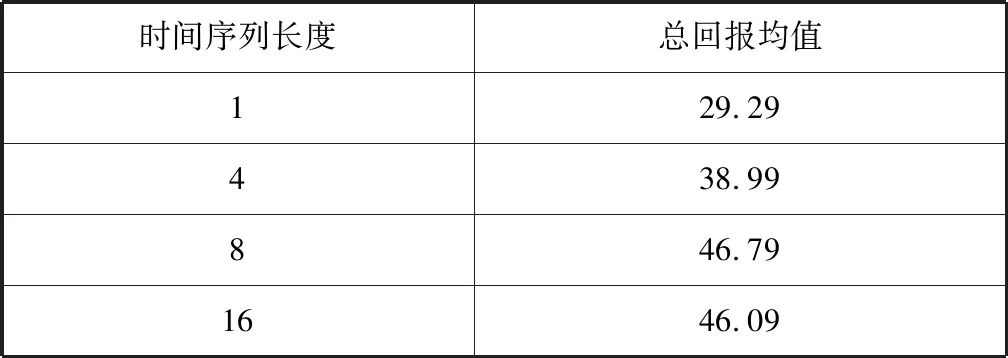
表3 四種不同的時間序列長度在測試軌跡上的總回報均值
可以看出,時間序列由1增大到4、由4增大到8時,總回報均值均有較大提升,但是由8增大到16時,總回報均值沒有增大,反而有略微減小。
結果說明一定程度的增大歷史吞吐量的數量可以提升碼率決策性能,因為一定的歷史吞吐量信息有利于較為準確地預測當前帶寬,但是歷史吞吐量數量增大到一定程度性能不再提升,因為當前動作對未來回報的影響是逐漸衰減的,越久之前的信息對當前影響越小。
5 結論
本文采用了強化學習和深度神經網絡相結合的DRL算法,實現了DASH客戶端的自適應碼率決策算法。在真實網絡軌跡數據集上進行多種算法的測試,實驗結果表明:本文所采用的算法能夠獲得比現有算法更高質量的用戶體驗,并且具有較少的重緩沖事件和質量切換事件。
猜你喜歡
教學考試(高考化學)(2021年2期)2021-05-30 06:15:52
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:42
中學生數理化·高一版(2020年3期)2020-04-21 08:03:20
中學生數理化(高中版.高考理化)(2020年2期)2020-04-21 05:32:50
小學生作文(低年級適用)(2019年9期)2019-10-08 08:37:10
小學生作文(低年級適用)(2018年9期)2018-10-08 02:29:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:10
數學大世界(2018年1期)2018-04-12 05:39:14
幸福(2017年18期)2018-01-03 06:34:53
中國衛生(2016年8期)2016-11-12 13:26:50
