基于視覺誤差與語義屬性的零樣本圖像分類
2020-06-01 10:58:48肖永強陳開志廖祥文吳運兵
計算機應用 2020年4期
徐 戈,肖永強,汪 濤,2,陳開志,廖祥文*,吳運兵
(1. 閩江學院計算機與控制工程學院,福州350108; 2. 福州大學數學與計算機科學學院,福州350116;3. 福建省網絡計算與智能信息處理重點實驗室(福州大學),福州350116;4. 數字福建金融大數據研究所,福州350116)
(?通信作者電子郵箱liaoxw@fzu.edu.cn)
0 引言
在進行圖像分類的過程中,圖像類別數往往較多。如果每次都采用人工去標注每個類別標簽,工作量會非常巨大。例如,在文字識別過程中,單字類別數量成千上萬,對每一個單字類別都進行標注幾乎是一件難以完成的工作。針對這樣的情況,如何利用機器學習訓練分類器,在不標注新類別的情況下仍然可以對其分類值得研究。顯然傳統(tǒng)的分類器并不能實現這樣的目的,所以研究者提出零樣本學習(Zero-Shot Learning,ZSL)概念[1]。
零樣本圖像分類思想屬于遷移學習的范疇,通過訓練已有的視覺類別信息然后遷移到新圖像類別,并實現對其分類。人類能夠通過學習將已見過的視覺信息與語義信息建立聯系,并通過這樣的聯系去判別新圖像類別,使得我們具備識別未見過的圖像類別的能力。在零樣本學習圖像分類中,未知的圖像類別并沒有已知的源圖像訓練樣本,但可以通過對已知圖像類別相關知識的學習,然后遷移到未知的圖像類別當中,從而對未知的圖像類別樣本進行結果預測。屬性作為中層語義特征,可以建立跨類別、多層級關聯。屬性語義描述通常由人工標注得到,因而能夠有效反映出類別之間的關系以及表示每一個類別。對零樣本圖像分類研究有助于解決目標類別數據標簽缺失問題、促進對人類智能推理的深入研究,具有重要的理論研究意義和實際應用價值。
根據測試時的圖像類別不同,零樣本學習通常分為兩種:傳統(tǒng)的零樣本學習(ZSL)和廣義零樣本學習(Generalized ZSL,GZSL)。其中:傳統(tǒng)零樣本學習只測試模型在未知類上的分類正確率;而廣義零樣本學習的測試類別既包括已知類,也包括未知類。對比方法在提升未知類上的分類性能的同時影響到了已知類上的分類性能,在已知類和未知類之間存在較嚴重的預測偏置。受此啟發(fā),本文提出一種基于視覺誤差預測的方法來判別輸入圖像是否屬于已知類,并根據其結果將圖像嵌入不同的類別語義空間進行預測。
1 相關工作
在早期的方法中,Lampert 等[2-3]提出一種直接屬性預測模型(Direct Attribute Prediction,DAP),該學習方法先訓練已知樣本的視覺特征,以及相對應類別的屬性特征,這樣可以學習得到一個分類器預測屬性,從而得到測試樣本每一個未見過類別的后驗概率,最后使用最大后驗估計法,對未知類測試圖像進行結果預測。Romera-Paredes 等[4]提出了一個較為通用的神經網絡框架,該網絡將特性、屬性和類之間的關系建模為兩個線性層網絡,其中頂層的權重不是由環(huán)境來學習,而是由環(huán)境來給出。通過將其作為域自適應方法,進一步給出了這種方法的泛化誤差的學習界限。第一線性網絡層建立圖像特征和屬性特征之間的聯系,第二線性網絡層建立屬性特征和類別標簽之間的聯系。
針對各個屬性特征的某些語義關系,一些文獻對其進行了不同程度的研究。比如,Liu 等[5]提出了一個統(tǒng)一的框架進行屬性的學習,屬性關系和屬性分類共同提高屬性預測的能力。具體來說,將屬性關系學習和屬性分類器設計成一個共同的目標函數,通過它不僅可以預測屬性,還可以自動發(fā)現數據中屬性之間的關系。鞏萍等[6]提出了一種基于屬性關系圖正則化特征選擇的零樣本圖像分類方法,通過訓練樣本中類別和屬性矩陣來計算屬性之間的正負相關性,該屬性相關性直接預測屬性。
也有一些文獻提出將樣本的圖像特征和類別的語義特征同時映射到一個公共空間的方法。比如,文獻[7]提出了一種結構化聯合嵌入(Structured Joint Embedding,SJE)方法,利用映射空間矩陣將圖像特征和語義特征嵌入到一個公共的特征空間,并基于公共特征空間計算各模態(tài)特征內積和,內積和最大的即為預測可能性最高的類別。Xian等[8]對SJE進行改進,提出了一種隱藏嵌入(Latent Embedding,Lat Em)模型,在零樣本分類中學習圖像和類別嵌入之間的兼容性,通過結合深度變量來增強雙線性兼容性模型,使用基于得分排序的目標函數訓練模型,該目標函數懲罰給定圖像的真實類別的錯誤得分排序。Akata 等[9]提出的聯合嵌入框架將多個文本語義部分映射到一個公共空間,具體操作是先將圖像劃分成多個塊,然后為各塊獲得相應的文本特征,最后用聯合嵌入模型將它們映射到公共的特征空間當中。
近年來利用深度學習充分融合屬性語義特征與圖像特征進行分類,不需要考察每一類之間的距離度量,可以直接端到端訓練分類。文獻[10]設計了深度嵌入模型,選擇合適的嵌入方式,對多個語義模態(tài)(屬性和文本)融合后端到端學習,體現了一種自然機制,速度和正確率都有所改觀。文獻[11]設計出來的網絡使用的是一種比較的思想,通過比較來對新類別進行分類,在性能上比文獻[10]方法略有提升。文獻[12]設計的神經網絡是生成對抗的方式,利用均勻分布或高斯分布噪聲對文本與屬性特征產生新的圖像特征(包含已知的和未知的),從而對圖像特征進行分類。文獻[13]設計了3 個網絡,分別是FNet(提取圖像特征)、ZNet(定位感興趣區(qū)域并放大)和ENet(特征映射),并聯合訓練3 個網絡,其中ZNet 是參考文獻[14]方法利用重復注意力機制來定位。
本文采用深度學習方法重新設計神經網絡,充分融合屬性語義特征與圖像特征進行端到端訓練。訓練包括兩個步驟:1)訓練半監(jiān)督學習方式的生成對抗網絡,提取圖像視覺誤差信息;2)訓練零樣本圖像分類,使用屬性語義信息指導圖像分類,能夠識別未知類。
本文的主要工作如下:
1)提出一種半監(jiān)督學習方式的生成對抗網絡,采用編碼器-解碼器-編碼器(encoder-decoder-encoder)架構,得到已見過類別和未見過類別在網絡深層次抽象特征的誤差值。該誤差值的作用在于區(qū)分已知類和未知類,防止在GZSL下預測發(fā)生偏置問題。
2)提出一種零樣本圖像分類網絡,采用圖像特征與屬性語義特征完全拼接(feature concatenation),得到的模型既能在傳統(tǒng)設定下又能在廣義設定下獲取良好的分類表現。
3)通過視覺誤差參數設定閾值的選擇,可根據實際需要調整,縮小零樣本圖像分類在廣義設定下預測類別的搜索空間,具體可分為兩段和三段視覺誤差。
2 模型方法
2.1 問題描述
本問題描述分成兩部分:一部分是零樣本學習,主要描述如何融合屬性語義實現識別目標數據,包括具體識別已知類和未知類;另一部分是視覺異常識別,主要描述如何通過訓練已知類來預測辨別未來數據中已知類和未知類,以下使用圖像數據為例進行描述。


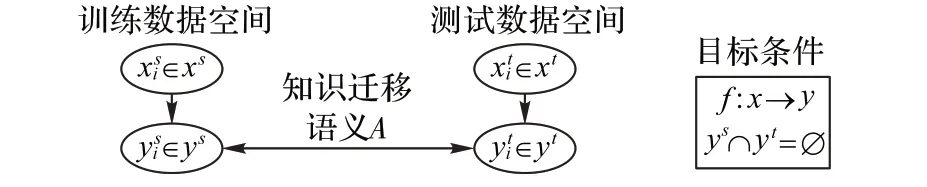
圖1 零樣本學習Fig.1 Zero-shot learning
用于類別知識遷移的描述包括訓練類別數據屬性語義描述Atrain,以及測試類別數據屬性語義描述Atest。這里的每個類別yi∈Y都可以表示為一個語義特征向量ai∈A的形式表示,比如“黑白色”“有條紋”“有四條腿”“食肉的”“有羽毛”“有尾巴”等,屬性語義特征向量每個維度都代表著一種高級的屬性描述,當這個類別具備某些屬性時,則在其對應的維度上會被設置成非零值(具體可參看3.1 節(jié)中的數據集)。對于全集類別,每個類別屬性語義向量維度都是一定的,一般經過多個人工標注后就可以得到該類別準確的屬性語義描述信息。


如圖2 所示,訓練數據為已知類,而測試數據既有已知類也有未知類,異常識別問題是希望通過訓練已知類去識別已知類和未知類。可以將已知類當作正常樣本,而未知類當作異常樣本,異常識別問題被理解為二分類問題。由于訓練數據沒有未知類,所以該訓練方式屬于半監(jiān)督學習。

圖2 視覺異常識別Fig.2 Visual anomaly recognition
2.2 利用生成對抗網絡提取視覺誤差信息
網絡設計思路借鑒GANomaly[15]模型,該生成對抗網絡為半監(jiān)督異常識別:編碼器-解碼器-編碼器(Encoder-Decoder-Encoder )流水線內的新型對抗自動編碼器,捕獲圖像在深度特征空間內的訓練數據分布;是一種有效且新穎的異常識別方法,可以在統(tǒng)計和計算上提供更好的性能,如圖3 模型框架所示。
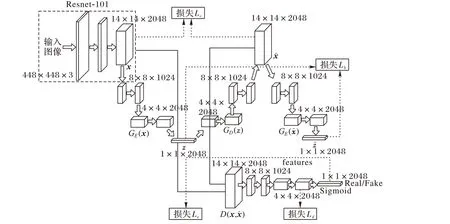
圖3 半監(jiān)督學習方式的生成對抗網絡框架Fig.3 Generative adversarial network framework of semi-supervised learning mode
整個框架由4部分組成:
1)視覺特征網絡。采用深度殘差網絡,去掉最后的分類層和池化層,最后提取到深度特征圖像(feature map)。
2)生成網絡由編碼器GE(x)和解碼器GD(z)構成。對于送入深度特征圖數據x 經過編碼器GE(x)得到深度視覺向量z,z經過解碼器GD(z)得到x的重構數據
4)重構編碼網絡GE。對重構圖像編碼,由編碼器GE得到重構圖像編碼的深度視覺向量使用Lb可以不斷縮小深度視覺向量z 與差距,理想情況下它們是完全一樣的。
在訓練階段,整個模型均是通過已見過類別的正常樣本做訓練。也就是編碼器GE(x)、解碼器GD(z)和重構編碼器都適用于正常樣本。測試階段,當模型在測試階段接收到一個異常樣本,此時模型的編碼器、解碼器將不適用于異常樣本,此時得到的編碼后深度視覺向量z 和重構編碼器得到的深度視覺向量差距是大的。這時候規(guī)定這個差距是一個分值,通過設定閾值φ,一旦深度視覺向量之間的均方誤差大于設定閾值φ,模型就認定送入的樣本x為未見過類別的異常樣本。對于目標測試數據,經過源數據訓練,根據閾值φ,目標數據可以正確被區(qū)分已知類和未知類。
2.3 利用屬性語義信息實現零樣本圖像分類
融合屬性語義特征實現零樣本圖像分類網絡作為基準實驗(Baseline),它由視覺特征網絡、屬性語義轉換網絡和視覺-屬性語義銜接網絡構成。視覺特征網絡采用在ImageNet[16]預訓練1 000 類別的Resnet-101[17]模型,去掉最后分類層獲取2 048個特征向量。視覺-屬性語義銜接網絡將高維屬性語義特征嵌入到視覺特征。由于不同的數據集的屬性語義特征維度不同且特征數量維度比較低,所以需要引入屬性語義轉換網絡,實現特征從低維空間映射到高維空間,平衡屬性語義特征影響程度與視覺特征的影響程度,該子網絡采用了雙層的線性激活層。圖4 展示了屬性語義轉換子網絡與視覺-屬性語義銜接子網絡。
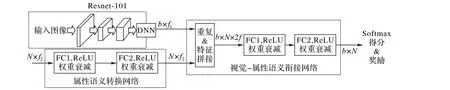
圖4 視覺-屬性語義嵌入網絡Fig.4 Visual-attribute semantic embedding network
屬性語義轉換網絡用于產生所有類別的屬性特征表征。在訓練階段,將源數據已知類別數Ns的屬性語義特征映射到高維;在預測階段,將目標數據已知和未知總類別數Ns+t的屬性語義特征映射到高維,規(guī)定與DNN 視覺特征的維度數相同。當確定要輸入訓練的類別屬性特征N × f2(f1和f2表示特征維度)后將其送入屬性語義轉換網絡,特征映射到N × f2′,再使用Repeat 產生和圖像表征一樣的批大小b,即張量維度變?yōu)閎× N × f2′,通過特征拼接(Feature concatenation)操作完全拼接視覺-屬性語義特征輸出張量維度b× N × 2f,最后送入視覺-屬性語義銜接網絡,視覺-屬性語義銜接網絡也同樣使用了兩層的線性激活層,得到b× N。對于送入的源數據,最后計算的是分類得分。
2.4 融合視覺誤差信息提升零樣本圖像分類
對于生成對抗網絡,首先,生成器網絡中采用編碼器-解碼器-編碼器子網絡使得模型能夠將輸入圖像映射到較低維度的矢量,該較低維度矢量用于重建所生成的輸出圖像;然后,在訓練期間最小化這些圖像與深度視覺向量之間的距離有助于學習正常樣本的數據分布,而在預測階段圖像編碼的深度視覺空間下進行對比,源數據圖像在深度視覺空間下差異下,目標數據在深度視覺空間下差異大;最后將訓練好的深度視覺空間特征差異融入屬性語義訓練指導零樣本圖像分類訓練中。
融合視覺誤差信息的方式在這里直接用目標數據中每一個實例樣本的均方誤差值。首先訓練好生成對抗網絡,并設定一個好的閾值φ(一般取經驗值0.2,然后微調),使盡可能得到較強區(qū)分目標數據中已見過類別和未見過類別的能力;然后訓練零樣本圖像分類網絡,輸入的數據不使用無標簽的目標數據,反之是訓練全量數據下的零樣本圖像分類;接著分別訓練好生成對抗網絡與零樣本圖像分類網絡后進行測試,測試階段在視覺-語義嵌入網絡融入視覺誤差信息,利用視覺誤差信息確定目標數據中已見過類別和未見過類別,根據閾值φ 來決定視覺-語義嵌入網絡在已見過類別空間和未見過類別空間搜索。
視覺-語義銜接網絡在重復與特征拼接操作時候被視覺誤差信息選定了已見過類別空間和未見過類別空間,這樣再進行兩層的線性激活層分類可以有效防止類別預測偏置,即:未知類被預測到已知類,而已知類也可能被預測到未知類。
在理想情況下,生成對抗網絡能夠完美區(qū)分目標數據中已知類和未知類,但由于異常數據等問題,實際情況仍然會有交叉預測樣本。所以在融入視覺誤差信息時,差分閾值φ 可以根據實際情況來調整。另外差分閾值的選定可以不止一個,比如也可以是兩個,將誤差區(qū)域分成三段,如圖5 所示,第一段是可以很大程度劃分出已見過類別的數據,第二段是可以很大程度劃分出未見過類別的數據,第三段介于第一段與第二段之間。第一段在已知語義空間預測,第二段在未知語義空間預測,第三段在全集類別語義空間預測。這樣可調節(jié)分段閾值的好處就在于進一步提高目標數據的預測,同時也有助于實際應用的需要。

圖5 三段類別樣本分布空間Fig.5 Sample distribution space of three-segment category
2.5 模型優(yōu)化
模型優(yōu)化主要是損失函數,包含半監(jiān)督生產對抗網絡和視覺-屬性語義嵌入網絡。
視覺-屬性語義嵌入網絡在訓練階段執(zhí)行的是強監(jiān)督學習,所以定義如下損失函數La:

半監(jiān)督學習方式的生成對抗網絡框架的損失函數設置如圖3 所示,由四部分損失構成,分別是:深度視覺向量誤差Lb、原圖與重構圖誤差Lc、特征匹配誤差Ld以及真假判別損失Le。
1)深度視覺向量間的誤差優(yōu)化函數Lb:


3)用于在判別網絡中深度圖像特征層面做優(yōu)化,設置一個特征匹配誤差損失函數Ld:

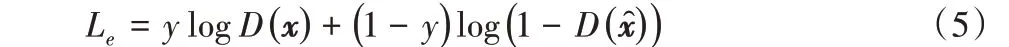
其中:y ∈{0,1},“1”表示優(yōu)化判斷是源數據x,而“0”表示判斷為重構數據
訓練過程只有已知類數據參與,模型只對已知類數據可以做到較好的編碼解碼,所以送入未知類數據在編碼解碼下會出現編碼得到的深度視覺向量差異大從而使得差距分值φ大,判斷為未見過類別即是異常。對于模型,整個損失函數的優(yōu)化分為生成器LG和判別器LD表示為:

其中:ωb、ωc、ωd和ωe是調節(jié)各損失的參數,可以根據具體實驗設置。式(6)展示了各損失函數之間關系,模型訓練分別學習生成器和判別器,協(xié)同交替迭代更新。
3 實驗與結果分析
3.1 實驗數據集和評價指標
數據集來源與評價指標主要參考文獻[12],所屬領域分別是鳥類與動物類,每一類的圖像數據相對均衡,數據劃分比例也基本均衡。
1)CUB(Caltech-UCSD-Birds-200-2011)數據集。全部都為鳥類的圖像,總共200 個類,其中:150 類為訓練集,50 類為測試集。類別的屬性語義特征維度為312,共有11 788 張圖片,劃分情況見表1所示。
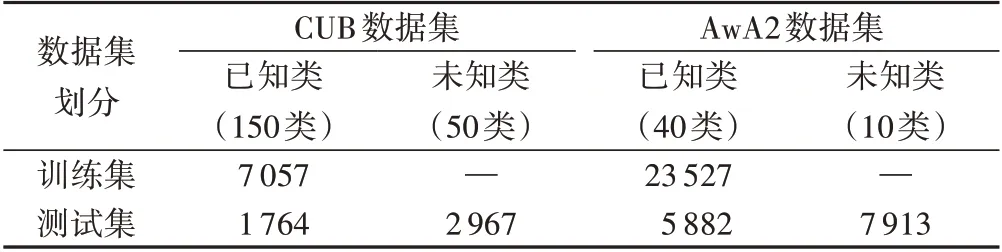
表1 CUB和AwA2數據集劃分情況Tab.1 Division of CUB and AwA2 datasets

圖6 CUB和AwA2數據集樣例Fig.6 Samples of CUB and AwA2 datasets
2)AwA(Animal with Attributes)數據集。
提出ZSL定義的作者,給出的數據集都是動物的圖片,包括50個類別的圖片,其中:40個類別數據作為訓練集,另外10個類別數據作為測試集。每一個類別的屬性語義特征維度為85,總共37 322 張圖片,本文使用AwA2 數據集,劃分情況見表1所示。
評估指標有四個,分別是T1、ACCsenn、ACCunseen和H。
1)正確率。
ZSL:只評估在未知類下的正確率T1(傳統(tǒng)設定下)。
GZSL(ACCseen,ACCunseen):分別評估在全集類別下預測已知與未知類的正確率(廣義設定下)。
2)調和指標H值:
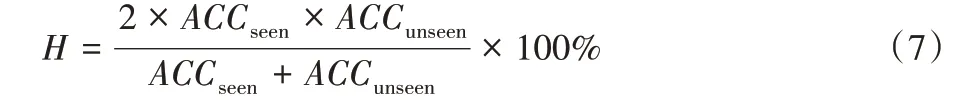
3.2 對比模型
為了驗證模型的有效性,本文選取了以下模型作為基準實驗。
1)深度嵌入模型(Deep Embedding Model,DEM)[11]:該方法使用深度ZSL 模型成功的關鍵是選擇合適的嵌入空間,即使用視覺空間作為嵌入空間,而不是嵌入語義空間或中間空間。在這個空間里,隨后的最近鄰搜索將受到中心問題的影響,因此變得更有效。該模型設計還提供了用于端到端方式聯合融合和優(yōu)化的多個語義模態(tài)(例如,屬性和句子描述)的自然機制。
2)GAZSL[12]:該方法將關于未知類(例如維基百科文章)的噪聲文本描述作為輸入,并為該類生成視覺特征。通過添加偽數據,將零樣本學習自然地轉換為傳統(tǒng)的分類問題。另外,為了保持所生成特征的類間區(qū)分,提出了視覺樞軸正則化作為顯式監(jiān)督。
3)關系網絡(Relation Network,RN)[13]:是從頭開始端到端訓練的。在元學習期間,它學習深度距離度量以比較一批中的少量圖像,每個圖像旨在模擬少數樣本設置。一旦經過訓練,RN就能夠通過計算查詢圖像與每個新類的少數樣本之間的關系得分來對新類別的圖像進行分類,而無需進一步更新網絡。
3.3 實驗設置
將本文提出的融合視覺誤差信息提升零樣本圖像分類方法分別在AwA2 和CUB 數據集中進行實驗,對比不同方法所得到的分類結果的調和指標H值。所有基準實驗的實驗環(huán)境均為單機環(huán)境,處理器為Intel Xeon CPU E5-2620 v4@2.10 GHz,操作系統(tǒng)為Ubuntu 16.04.1 LTS,內存為64 GB RAM,GPU 為GeForce GTX 1080Ti,顯 存 為11 GB,開 發(fā) 平 臺 為Python 2.7.13,所有算法實現語言為Python,使用深度學習框架PyTorch。實驗基本參數設置包括零樣本圖像分類網絡和生成對抗網絡,分別如表2和表3所示。

表2 零樣本圖像分類網絡實驗參數設置Tab.2 Setting of experimental parameters for zero-shot image classification network
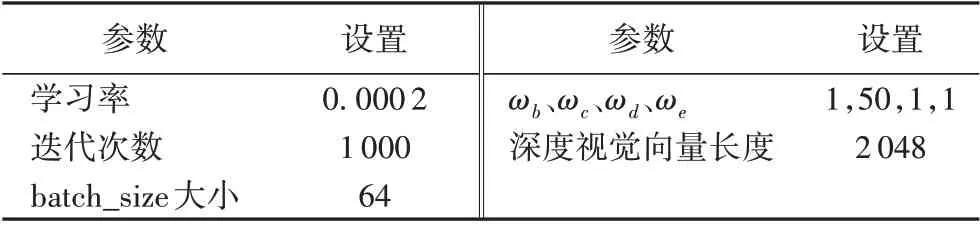
表3 生成對抗網絡實驗基本參數設置Tab.3 Setting of basic experimental parameters for generative adversarial network
訓練半監(jiān)督學習方式的生成對抗網絡,隨著訓練不斷迭代進行,已知類和未知類區(qū)分程度越來越明顯,其損失下降也將變得緩和。分別將AwA2數據集和CUB 數據集的測試數據使用均方誤差計算在生成網絡下z 和誤差結果,如圖7~8所示。
分別從實驗結果中取閾值φ 的合理區(qū)間,AwA2 選擇[0.32,0.38]閉區(qū)間,CUB選擇[0.10,0.12]閉區(qū)間,再通過微調可以確定具體值。在零樣本圖像分類實驗中,僅使用有標簽數據,而假設情況下的測試數據用于Baseline效果測試。
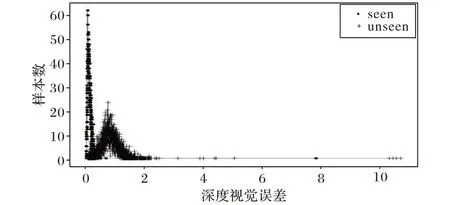
圖7 AwA2數據集視覺誤差檢測結果Fig.7 Visual error detection results of AwA2 dataset
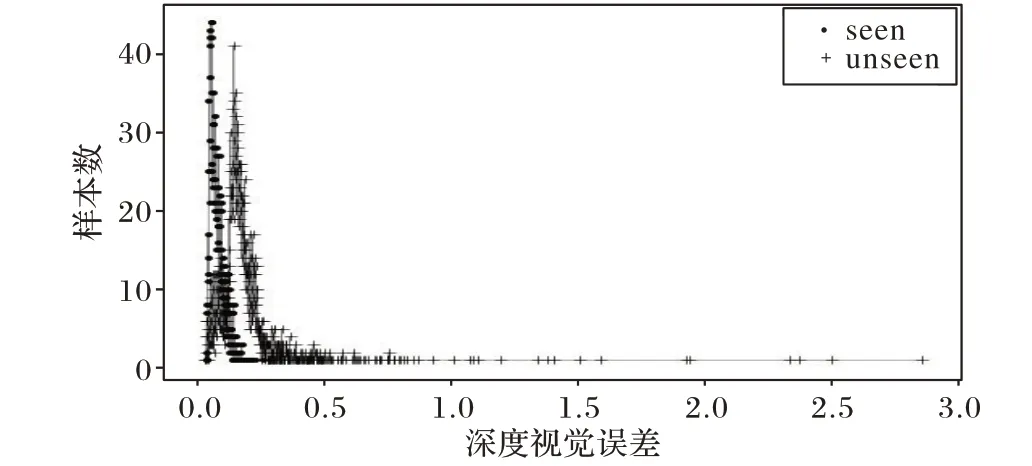
圖8 CUB數據集視覺誤差檢測結果Fig.8 Visual error detection results of CUB dataset
比較生成對抗網絡中使用判別網絡視覺誤差,分別將AwA2 數據集和CUB 數據集的測試數據使用均方誤差計算f(x)和f(誤差結果。采用判別網絡計算的視覺誤差在已知類和未知類上幾乎同分布,使判別網絡難于區(qū)分已知類和未知類。由此確定,半監(jiān)督生成網絡與判別網絡相比,半監(jiān)督生成網絡生成的深度視覺誤差更能夠區(qū)別已知類和未知類。
在使用生成對抗來獲取視覺誤差時,有兩個問題需要確定:1)不增加判別網絡D(x,對區(qū)分已知類和未知類是否有影響;2)不增加重構編碼網絡GE(而直接用判別網絡D(x,來提取視覺誤差對區(qū)分已知類和未知類的效果如何。這兩個問題通過控制變量法來確定。以AwA2 數據集和CUB數據集為例,問題1)將生成對抗剔除判別網絡,只訓練生成網絡和重構編碼網絡;問題2)剔除重構編碼網絡,只訓練生成網絡和判別網絡。
對問題1)的實驗情況,在同等條件下,增加判別網絡會比不增加判別網絡學習區(qū)分已知類和未知類更快,且更加穩(wěn)定(可將階段性學習過程可視化觀察)。值得注意的原因是判別網絡的對抗學習的確可以促進生成網絡的學習能力。對問題2)的實驗情況,在同等條件下,不增加重構編碼網絡會比增加重構編碼網絡對區(qū)分已知類和未知類的能力差。值得注意的原因是減少了深度視覺向量間的誤差損失會降低網絡學習能力。
3.4 結果分析
利用生成對抗提升零樣本圖像分類方法將生成對抗網絡實現異常檢測結果的視覺誤差信息融入到零樣本圖像分類當中,實驗分別在AwA2 數據集和CUB 數據集上對比基準實驗效果。Baseline 是只利用屬性語義信息實現零樣本圖像分類結果,GAN_enhance_ZSL 是融合了視覺誤差信息和屬性語義信息后的提升結果。提升結果有兩組數據:第一組,實驗微調閾值φ,將視覺誤差分成兩段,確定AwA2 數據集的具體值是0.33,確定CUB 數據集的具體值是0.11。第二組,視覺誤差分成三段,確定AwA2 數據集視覺誤差三段區(qū)間為[0,0.27]、(0.27,0.40]、(0.40,∞),確定CUB 數據集視覺誤差三段區(qū)間為[0,0.10]、(0.10,0.13]、(0.13,∞)。
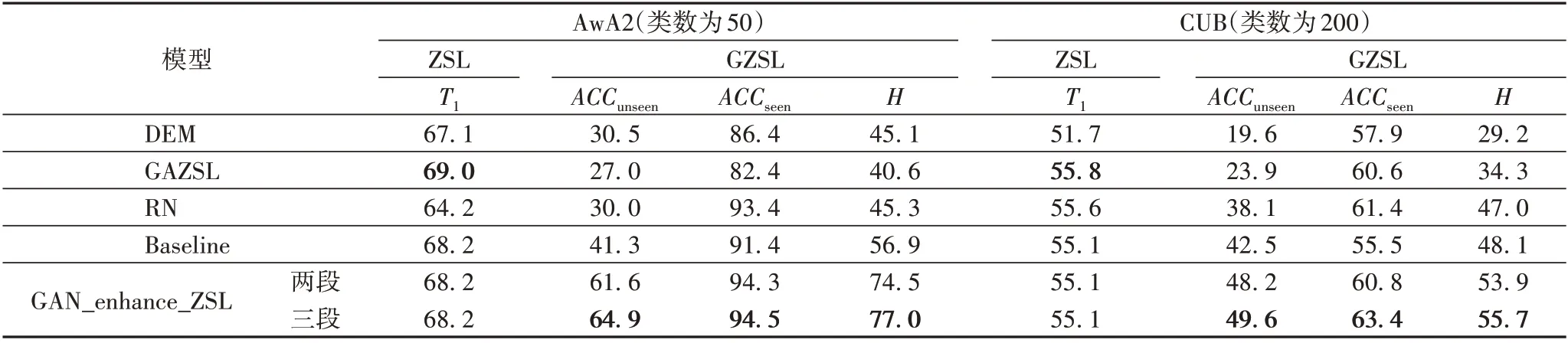
表4 對比基準實驗效果 單位:%Tab.4 Comparison with the benchmark experiment unit:%
對于本文Baseline 只使用屬性語義信息的實驗,在AwA2數據集上,對比DEM 網絡,ACCunseen提升10.8 個百分點,而ACCseen提升5.0 個百分點;對比RN 網絡,ACCunseen提升11.3 個百分點,但ACCunseen下降2.0 個百分點。在CUB 數據集上,對比RN 網絡,ACCunseen提升4.4 個百分點,但ACCunseen下降5.9 個百分點。在T1指標上表現良好,而調和指標H 在AWA2 數據集優(yōu)于CUB 數據集,值得注意的原因是AWA2 數據集訓練數據集樣本數相對較多且類別相對少。
對比Baseline,融入視覺誤差信息后ACCseen和ACCunseen指標均有所提升。在AWA2 數據集上,保證ACCseen提升2.9 個百分點情況下,ACCunseen還提升20.3 個百分點,調和指標H 提升17.6個百分點;在CUB數據集上,保證ACCseen提升5.3個百分點情況下,ACCunseen還提升6.7個百分點,調和指標H提升了5.8個百分點。
對于GAN_enhance_ZSL 實驗,第二組實驗分成三段的視覺誤差明顯優(yōu)于第一組實驗分成兩段的視覺誤差,主要原因與使用預測類別空間相一致。在AwA2 數據集上,同樣對比RN網絡,在保證ACCseen提升1.1個百分點情況下ACCunseen提升34.9個百分點,調和指標H提升31.7個百分點。在CUB數據集上,對比未使用測試數據的RN 網絡,在保證ACCseen提升2.0 個百分點情況下ACCunseen提升1.7 個百分點,調和指標H提升8.7 個百分點。在傳統(tǒng)定義下的指標T1,相比GAZSL 略低,但仍表現良好。
只使用屬性語義信息的Baseline實驗中,T1指標總是遠大于ACCunseen,顯然預測發(fā)生極大偏置現象,具體發(fā)生在未知類預測為已知類,而當融入視覺誤差信息后這種現象隨即緩解。另外只使用屬性語義信息的Baseline 雖然在AWA2 數據集和CUB數據集的ACCunseen指標相比基準實驗都提高,但是需要降低ACCseen的代價。融入視覺誤差信息后,實驗效果明顯有大幅度提升,說明使用半監(jiān)督學習方式的生成對抗網絡不僅有效促進神經網絡辨別已知類和未知類,還能縮小零樣本圖像分類在廣義下預測類別空間,有效防止預測發(fā)生偏置問題。對比AwA2 與CUB 結果,AwA2 的提升比CUB 提升多很多,值得注意的原因是數據集本身的區(qū)別,動物類的形態(tài)迥異,而鳥類形態(tài)大都相似,所以使用半監(jiān)督學習方式的生成對抗網絡區(qū)別已知類和未知類對類別差異大的效果更好。
4 結語
本文針對現有零樣本圖像分類方法僅利用屬性語義信息來指導分類而未使用視覺誤差信息,導致模型無法顯式地辨別已知類和未知類,存在較大的預測偏置的問題,提出融合視覺誤差信息與屬性語義信息來提升零樣本圖像分類。當模型學習完已知類的源圖像數據后,對于目標圖像數據中已知類視覺誤差小,而未知類視覺誤差大。利用視覺誤差信息在一定程度上有助于零樣本圖像分類模型將目標圖像數據中已知圖像類別和未知圖像類別區(qū)分開來,還能縮小零樣本圖像分類在廣義下預測類別的搜索空間,可以有效防止預測類別發(fā)生偏置問題。視覺誤差信息的獲取采用半監(jiān)督學習方式的生成對抗網絡,零樣本圖像分類采用融合屬性語義信息訓練。實驗結果表明,與基準模型相比,本文所提出來的融合視覺誤差信息后的零樣本圖像分類在AwA2數據集和CUB 數據集的評價指標上均有大幅度提升趨勢,驗證了本文方法在提升零樣本圖像分類問題上的有效性。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
開放教育研究(2020年2期)2020-03-31 01:54:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
現代語文(2016年21期)2016-05-25 13:13:44
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
大連民族大學學報(2015年2期)2015-02-27 08:28:11
當代修辭學(2011年6期)2011-01-29 02:49:50
