基于Python 對(duì)資訊信息的網(wǎng)絡(luò)爬蟲(chóng)設(shè)計(jì)
2020-06-03 02:21:44嚴(yán)家馨
科學(xué)技術(shù)創(chuàng)新 2020年5期
嚴(yán)家馨
(重慶大學(xué)經(jīng)濟(jì)與工商管理學(xué)院,重慶400033)
1 相關(guān)概念
1.1 Python 語(yǔ)言
Python 是一種面向?qū)ο蟆⒔忉屝汀⒖梢浦驳慕换ナ骄幊陶Z(yǔ)言。其語(yǔ)法簡(jiǎn)單清晰,容易理解,非常適合編程初學(xué)者學(xué)習(xí)使用。且Python 語(yǔ)言的標(biāo)準(zhǔn)庫(kù)和第三方庫(kù)非常龐大豐富,使其功能非常強(qiáng)大,能夠完成數(shù)據(jù)采集、數(shù)據(jù)分析、數(shù)據(jù)挖掘、網(wǎng)站開(kāi)發(fā)等。
1.2 網(wǎng)絡(luò)爬蟲(chóng)
網(wǎng)絡(luò)爬蟲(chóng)是一種按照一定的搜索規(guī)則,自動(dòng)爬取web 網(wǎng)頁(yè)的應(yīng)用程序。首先從一個(gè)初始頁(yè)面的URL 開(kāi)始,通過(guò)分析頁(yè)面中的其他相關(guān)URL,抓取新的網(wǎng)頁(yè)鏈接,然后在這些網(wǎng)頁(yè)鏈接下,再繼續(xù)尋找新的網(wǎng)頁(yè)鏈接URL,反復(fù)循環(huán),直到爬取和分析完所有頁(yè)面內(nèi)容。
1.3 Scrapy 框架
Scrapy 是Python 技術(shù)語(yǔ)言開(kāi)發(fā)的一個(gè)高層次,快速抓取web 網(wǎng)頁(yè)的框架,用于抓取Web 網(wǎng)頁(yè)中的內(nèi)容。Scrapy 的應(yīng)用非常廣泛,常被用于網(wǎng)絡(luò)爬蟲(chóng),且其擁有很多簡(jiǎn)化的高級(jí)函數(shù)和中間件接口,可以靈活地完成各種需求。
1.4 MySQL
MySQL 是一個(gè)關(guān)系型數(shù)據(jù)庫(kù)管理系統(tǒng),其可以將網(wǎng)絡(luò)爬蟲(chóng)爬取的數(shù)據(jù)信息保存在不同的表中以增加儲(chǔ)存速度并提高靈活性。并且能夠作為一個(gè)單獨(dú)的應(yīng)用程序,也可以作為一個(gè)庫(kù)嵌入到其他的軟件。被用于Navicat 數(shù)據(jù)庫(kù)軟件。
2 網(wǎng)絡(luò)爬蟲(chóng)程序的設(shè)計(jì)
2.1 伯樂(lè)在線網(wǎng)絡(luò)爬蟲(chóng)的流程結(jié)構(gòu)圖
首先確定最新文章的種子地址為start_url,進(jìn)入最新文章后便通過(guò)response.css 選擇器來(lái)得到第一頁(yè)及所有下一頁(yè)的url,選取一部分作為目標(biāo)url,其余部分放入待爬取的url 隊(duì)列中等待爬取。在目標(biāo)url 中同樣通過(guò)response.css 得出每篇文章特定的目標(biāo)內(nèi)容并解析匹配保存到navicat 數(shù)據(jù)庫(kù)中。以此再進(jìn)入下一個(gè)循環(huán),直到最新文章的資訊內(nèi)容全部爬取完成。
2.2 伯樂(lè)在線網(wǎng)絡(luò)爬蟲(chóng)的環(huán)境搭建(圖1)
開(kāi)發(fā)環(huán)境:Windows 系統(tǒng)
開(kāi)發(fā)語(yǔ)言:Python 語(yǔ)言,配置系統(tǒng)環(huán)境變量Path
開(kāi)發(fā)工具:Pycharm
Web 抓取框架:Scrapy
數(shù)據(jù)庫(kù)管理系統(tǒng):Mysql 和Navicat
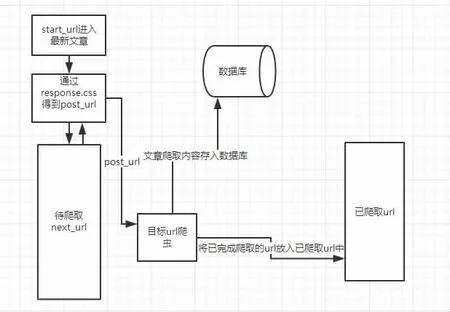
圖1
2.3 伯樂(lè)在線網(wǎng)絡(luò)爬蟲(chóng)的詳細(xì)設(shè)計(jì)
本爬蟲(chóng)是以Python 語(yǔ)言作為腳本語(yǔ)言編寫(xiě),Pycharm 作為此爬蟲(chóng)的工具,Scrapy 是此系統(tǒng)的框架。在Pycharm 中創(chuàng)建jobbole 項(xiàng)目并進(jìn)行Python 語(yǔ)言網(wǎng)絡(luò)爬蟲(chóng)代碼的編寫(xiě)。
2.3.1 伯樂(lè)在線資訊信息的獲取
a. 進(jìn)入伯樂(lè)在線的開(kāi)始地址為start_url: ['http://python.jobbole.com/all-posts/']
b. 通過(guò)css 選擇器獲取最新文章中一頁(yè)的url 和目標(biāo)文章post_url 并交給scrapy 下載后進(jìn)行解析。

d.在parse_detail()方法中通過(guò)css 選擇器獲取文章的封面圖、標(biāo)題、創(chuàng)建時(shí)間、收藏?cái)?shù)、點(diǎn)贊數(shù)、評(píng)論數(shù)、內(nèi)容等并使用正則表達(dá)式進(jìn)行匹配。

e.item 類的實(shí)例化
item 類在Python 中可以指定字段,通過(guò)實(shí)例化item,網(wǎng)絡(luò)爬蟲(chóng)爬取的數(shù)據(jù)不容易出錯(cuò)。
實(shí)例化:article_item =JobboleItem()
調(diào)用article_item 類:

2.3.2 伯樂(lè)在線資訊信息的存儲(chǔ)
首先通過(guò)MysqlPipelines()方法建立數(shù)據(jù)庫(kù)的連接,然后將伯樂(lè)在線網(wǎng)站獲取的標(biāo)題、封面圖、日期、內(nèi)容等存入數(shù)據(jù)庫(kù)中。

3 網(wǎng)絡(luò)爬蟲(chóng)程序的測(cè)試
3.1 最新文章中封面圖的儲(chǔ)存,通過(guò)pipelines()方法將封面圖存儲(chǔ)在images 文件中。
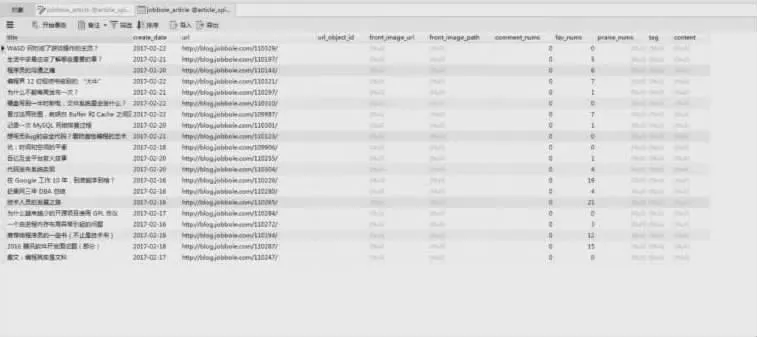
3.2 數(shù)據(jù)庫(kù)的存儲(chǔ),在pipelines 中編寫(xiě)MysqlPipelines ()方法,將獲取到的所有資訊內(nèi)容存儲(chǔ)到Navicat 數(shù)據(jù)庫(kù)中。
結(jié)束語(yǔ)
本文基于Python 語(yǔ)言的網(wǎng)絡(luò)爬蟲(chóng)對(duì)伯樂(lè)在線最新文章的資訊信息進(jìn)行了采集設(shè)計(jì)與測(cè)試,通過(guò)借助Pycharm 工具和Scrapy 網(wǎng)頁(yè)抓取框架編寫(xiě)Python 語(yǔ)言的網(wǎng)絡(luò)爬蟲(chóng)代碼,將伯樂(lè)在線最新文章中的URL、標(biāo)題、內(nèi)容、封面圖、點(diǎn)贊數(shù)、評(píng)論數(shù)等信息抓取并保存到數(shù)據(jù)庫(kù)中。此設(shè)計(jì)大大提高了人們對(duì)目標(biāo)資訊信息采集的速度和準(zhǔn)確度,也為后續(xù)準(zhǔn)確高效挖掘與分析數(shù)據(jù)提供了保證。
猜你喜歡
科學(xué)大眾(2022年11期)2022-06-21 09:20:52
文苑(2020年4期)2020-05-30 12:35:30
小學(xué)生作文(中高年級(jí)適用)(2018年3期)2018-04-18 01:24:47
財(cái)經(jīng)(2017年2期)2017-03-10 14:35:35
華北電力大學(xué)學(xué)報(bào)(社會(huì)科學(xué)版)(2016年4期)2016-12-01 03:59:30
臺(tái)聲(2016年2期)2016-09-16 01:06:53
財(cái)經(jīng)(2016年15期)2016-06-03 07:38:02
財(cái)經(jīng)(2016年3期)2016-03-07 07:44:46
財(cái)經(jīng)(2016年6期)2016-02-24 07:41:51
少兒科學(xué)周刊·少年版(2015年4期)2015-07-07 21:11:17
