重癥監護醫學信息數據庫隱私保護技術探討
2020-06-03 06:30:28劉寧遠成福春周蜜果
醫學信息學雜志 2020年2期
劉寧遠 成福春 馮 佳 周蜜果 邵 茵 朱 亮
(上海中醫藥大學附屬岳陽中西醫結合醫院 上海 200437)
1 引言
重癥監護醫學信息數據庫(Medical Information Mart for Intensive Care,MIMIC)是由麻省理工學院計算生理實驗室建立的大樣本、單中心危急重癥監護數據庫。目前MIMIC數據集包括MIMIC-II和MIMIC-III,本文針對MIMIC-III進行分析。MIMIC-III涉及患者生命體征、用藥情況、護理記錄、手術操作記錄、檢驗結果在內共26張表[1]。隨著信息化進程的加快,醫療系統中的數據呈爆炸式增長,但是目前這類系統在最初設計時沒有考慮到醫療數據再利用問題,更多的只是滿足醫院收費和運營等日常工作需要,因此大部分醫療機構在現有臨床數據庫的基礎上對醫療數據開展共享研究還缺乏系統、有效的手段。然而隨著MIMIC-III等科研數據集的出現,更多的國內學者和臨床醫生對數據利用產生濃厚興趣。先進的數據挖掘技術在提高信息使用率的同時也必然導致隱私泄露問題。MIMIC-III對患者數據的隱私保護完全遵循《健康保險流通與責任法案》(Health Insurance Portability and Accountability Act,HIPAA)原則,采用多種技術手段對敏感信息進行匿名化處理,為滿足臨床科研需求的多樣性,涉及的數據包括患者癥狀、診斷、用藥、檢查、檢驗、手術治療等,既有結構化數據,也有自由文本、醫學影像等非結構化數據。這些數據來自于不同信息系統,涉及不同來源的數據融合,患者數據的隱私保護成為科研數據利用分析和臨床數據共享的關鍵[3]。
2 HIPAA與隱私
2.1 隱私條款
美國關于隱私安全的立法較早,1974年通過《隱私權法》保護公民個人信息的隱私權。1996年美國通過著名的HIPPA法案,2003年HIPAA中的隱私規則和安全規則生效。隨后幾年對其補充法案進一步發布,美國形成針對個人健康信息的隱私安全法律保護體系。HIPAA分為不同部分,每個部分解決醫療保險改革中的一個獨特問題。其中兩個主要的部分是便攜性和簡化管理。便攜性是指允許個人在調換工作時醫療保險不會因為工作變動而承保中斷。簡化管理這一部分是建立用于接收、傳送和維護醫療信息的規則,確保隱私和個人身份信息的安全標準,這部分的焦點即是HIPAA中的隱私條款。
2.2 HIPAA中對隱私的定義
HIPAA中提出受保護的健康信息(Protected Health Information,PHI)概念,其定義為:主要由醫療服務提供商等適用主體或其商業伙伴持有或傳輸、以任何形式或媒體存在的可識別的個人健康信息。而可識別的個人健康信息是健康信息的一個子集,是指個人過去、目前和未來的生理和心理健康狀況、醫療護理狀況及與醫療護理相關的支付信息,這些信息至少包含法律規定的能夠識別出個人的 18 項身份識別信息中的一項。法案規定向外提供PHI時必須遵循最小必要原則,即能不披露盡量不披露,以治療為目的、向患者本人和依據患者意愿的披露除外。適用主體可以將去標識化后的數據提供給第3方,去標識化必須符合專家決定原則或者避風港原則。專家決定原則是指由行業內的相關專家決定哪些信息必須去除并且提供書面分析結果;避風港原則是指18項必須要去除的PHI,見表1。HIPAA所指定去除的PHI是絕對的,但匿名手段并不唯一,因此需要最大限度地考慮到在不同科研需求及醫療環境下其數據所獨有的研究價值,進而實行不同的匿名化方式。從另一個角度來看在國內開展臨床科研數據集工作是否一定要遵循HIPAA原則也值得思考,如特殊的宗教信仰,敏感的檢驗、檢查結果等,這些標識符屬性或敏感信息是否有必要進行處理,都需結合實際情況再做決定。

表1 HIPAA隱私條例規定的18種PHI
3 去標識化過程
3.1 概述
所謂去標識化,簡單來說就是斷開數據和個人信息主體的關聯。去標識化過程包括確定目標、識別標識、處理標識和導出數據,見圖1。經過處理后的數據必須保證可逆性,即通過嚴格授權機制可逆,以滿足不同業務需求。首先確定去標識化對象,目標數據集中存在標識符屬性時,根據事先決定的策略、法規標準、業務背景、數據用途等要素確定哪些數據屬于去標識化對象[4]。確定目標后通過查表標識法、規則分析法和專家判斷法對目標數據進行處理。
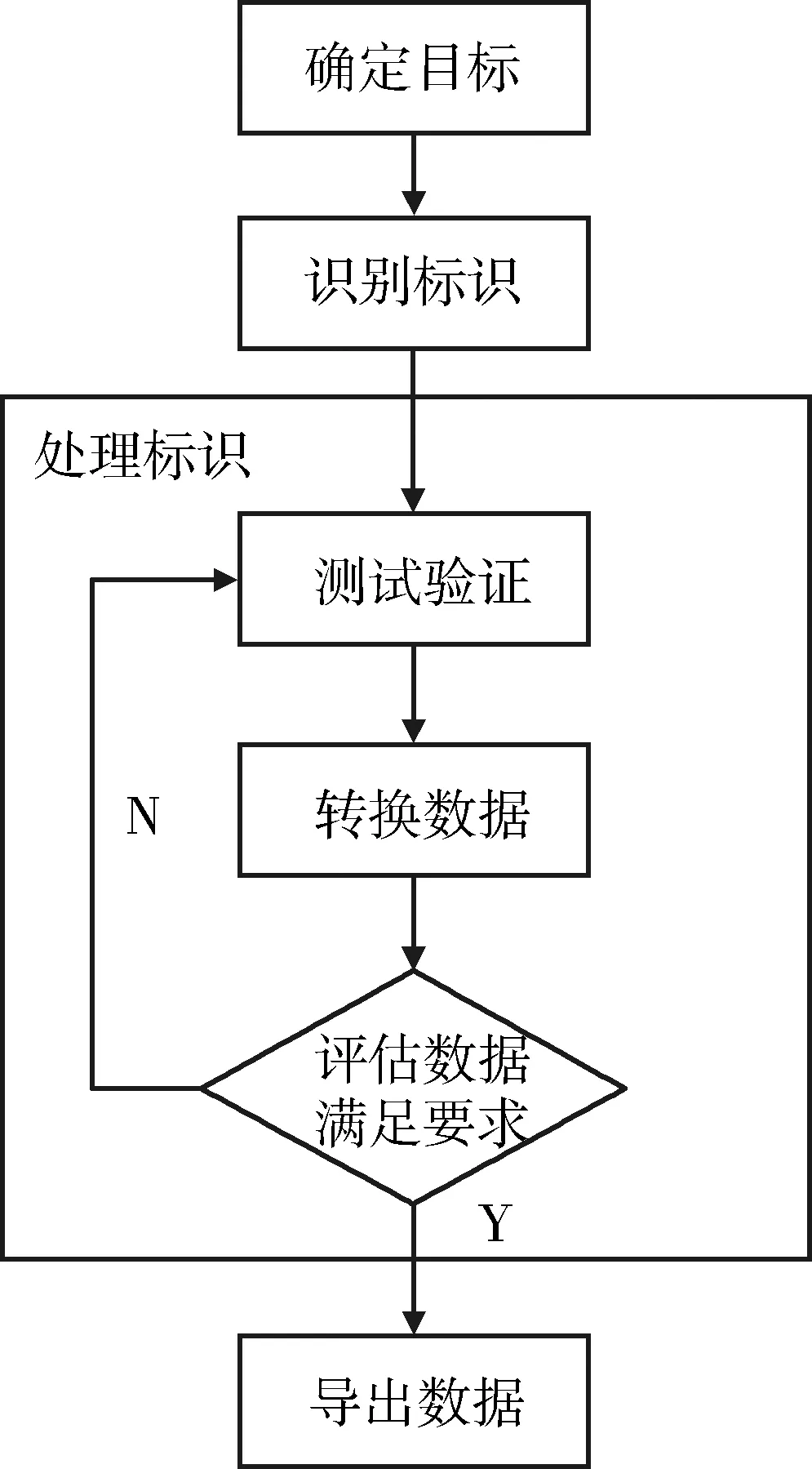
圖1 去標識化過程
3.2 查表標識法
預先建立對照數據表,存儲需要去標識化的標識符元素,在識別標識數據時將需識別數據的各個屬性名或字段逐個與對照表中的數據進行對比,再對其中的標識符屬性做相應處理。查表標識法適用于數據集與目標標識符屬性明確的關系型數據庫,如已明確姓名與身份證號等屬性。
3.3 規則分析法
通過建立規則,編寫特定程序,對不同數據集使用不同算法從目標中自動發現需去標識化的屬性。適用于非單一記錄的自由文本元素,包括以自由文本形式記錄的病史及檢查報告等非結構化數據。
3.4 專家制定法
如字面所示即通過專家審查,人工發現和確定去標識化的數據。適用于有特殊含義或特殊值的表。
4 MIMIC-III中去標識化技術分析
4.1 屬性刪除
在MIMIC-III數據集中標識符屬性包括姓名、電話、住址、社會安全卡號等。這些數據主要集中在人員字典表之中,在發布前MIMIC均對表中的這類屬性進行刪除處理。這種方式看似簡單粗暴,但能夠有效阻止攻擊者從發布的表中直接獲取到患者隱私。然而進一步的研究表明僅僅使用屬性刪除這一單一技術手段并不能有效保證患者隱私不遭到泄露,這種僅對特殊屬性進行處理的方式不能有效防范外界攻擊者通過連接攻擊等間接攻擊形式對個體隱私信息進行獲取[6]。隨著信息技術的日益進步以及互聯網的普及,攻擊者對數據的獲取途徑也在不斷增多。在對單個表進行攻擊時攻擊者很難獲取到患者隱私,但是若攻擊者將多個從不同渠道、不同系統中獲取到的匿名表通過某些特殊字段相互關聯,再經算法以及鏈接自身數據庫后就極有可能推測出患者的隱私。因此數據集的發布不能只是用單一脫敏手段,必須綜合使用多種技術手段對數據進行復合處理。
4.2 日期平移
4.2.1 時間處理 在MIMIC-III數據集中幾乎所有業務表都包含時間這一屬性,這些記錄中的時間都是受保護的PHI,然而這些時間信息對于臨床研究及數據分析又是非常重要的元素,所以MIMIC-III數據集將所有日期按照每位患者的標識屬性SUBJECT_ID按規則進行平移,每個SUBJECT_ID對應一個隨機偏移量N來使日期元素遷移到未來的某個時間點,保留業務時間的連續性以及這一屬性所獨有的周期特性,從而在保證該元素的利用及分析價值同時也保護患者隱私。為保證日期在醫療數據中的分析挖掘價值,該隨機數N有以下特征:N是7的倍數,使得轉換后的日期與真實日期具有相同的工作日周期,允許以星期為單位對數據進行分析;當N轉換為時間單位后應大于1個世紀,這樣可避免轉換日期和真實日期混淆,簡化從記錄中識別和去除遺留真實日期數據的任務;N對于單個患者的所有就醫數據都是相同的,但在患者之間是互不相同的。
4.2.2 年齡處理 MIMIC-III數據集中刪除患者年齡這一屬性,但可以通過入院時間或者記錄時間與出生時間的關聯推導出業務發生時患者的年齡。當患者年齡>89歲MIMIC會將其出生日期由入院日期向前調整300年,模糊處理以遵守HIPAA原則,這部分患者年齡中位數為91.4歲。研究者只需將Patients表中的出生時間和Admissions 中的各類業務發生時間兩兩相減后便可確定患者的入院、出院及死亡年齡。總而言之,日期平移技術使得第3方或攻擊者無法直接界定患者當前真實年齡及行為發生時間這類特殊屬性。從物理角度來看,時間連續平移對稱性保證客觀定律不會隨發生時間改變而改變,即考察的時間不同,物理系統服從的規律相同。因此日期平移技術不會改變數據的有效性、準確性和時效性,而MIMIC-III對時間數據處理的特殊手段進一步細化其變量范圍,使經處理的數據與其原始數據在屬性上更為接近,從而允許研究者在季度特征、特殊時間節點上對數據進行有效分析。時間平移技術開銷較少,對設備也無特殊要求,行之有效地顧及到適用主體的需求,值得在建設科研數據庫的過程中加以借鑒。
4.3 自由文本去標識化
4.3.1 概述 在病史記錄表NOTEEVENTS中保留著患者的詳細病史、護理記錄、檢驗檢查報告及出院報告,這些文本信息記錄在其Text屬性之中,這些自由文本信息包含著大量的標識化內容,MIMIC-III利用模式識別算法對這些數據進行遍歷,本質上該算法適用于任何醫療文本。
4.3.2 屏蔽 模式識別算法遍歷文本時根據空格進行分詞,然后與已知受保護的健康信息查找表進行關鍵詞比對,直接識別住院患者和醫護人員的姓名。由于姓名誤拼、昵稱使用和探視人員姓名不在已知查找表內,還需與常用姓名、醫院名稱等潛在查找表做關鍵詞匹配,識別潛在的命名實體[5]。得到的標識化內容被屏蔽替換后用“[]”與其他文本進行區分。
4.3.3 泛化 因HIPAA中明確規定超過89歲的年齡屬于標識化信息,所以在文本中涉及89歲以上的年齡關鍵字也需處理,統一用[**Age over 89**]代替,另外MIMIC-III對新生兒和<14周的兒童也使用相同方法。這種方法稱為泛化技術,簡單來說泛化是將原始值劃分進與其屬性相似的一組值中,這組值存在一個范圍,通過不同范圍的劃分可以有效地與表中其他數據區分,以滿足去標識化要求。總體來看這種技術保證被泛化后的屬性不會發生改變,不會對研究產生影響,更可通過泛化范圍的約束和控制滿足不同精度的研究需求,但在泛化范圍上要小心取值避免造成過度泛化。記錄案例如下:
nit No: [**Numeric Identifier 69098**]
Admission Date: [**2172-9-22**]
Discharge Date: [**2172-10-19**]
HISTORY OF PRESENT ILLNESS:Baby boy [**Known lastname 44129**] is a 31 and [**1-14**]-week boy born to a 27-year-old G1/P0 (to 1) mother with [**Name2 (NI) **] type O+, antibody negative…
4.4 標準化建議
目前國外面向電子病歷的命名實體算法已趨近完善,MIMIC數據集利用模式識別算法識別病史文本中的命名實體以實現患者數據去標識化。其通過查找表內關鍵詞對比、正則表達式和上下文檢索的簡單啟發式算法來移除PHI[5]。然而國內的病史文本語義識別較之國外還存在諸多挑戰,包括電子病歷文本的非規范性和專業性,醫療實體的獨特性和標注語料的稀缺性,都會對識別算法的可靠度產生影響。在對文本進行關鍵詞檢索設計正則表達式時一定要將中文的特殊語法和句法、分詞、命名實體的相互嵌套、跳躍、非連續性考慮在內。在對數值類型的PHI去標識時可參照MIMIC中的算法技術,通過正則表達式識別數字特殊字符,且該正則表達式必須在識別數字的同時對其文本中所包含的醫療術語進行分析,若識別出包含代表檢驗、檢查結果的關鍵字時,其中所含數字格式的文本就應被認為是臨床數據而加以保留。
5 結語
醫療信息的合理使用與發布需要建立在完善的規則與流程之上,患者隱私保護只是其中一部分。目前國內相關規則制定部門開始注意到醫療大數據平臺的構建需求,在中國醫院協會發布的《醫療機構醫療大數據平臺建設指南》中也建議參考HIPAA中的相關規則,但對具體匿名手段并無明確規定。所以完全遵循HIPAA原則的MIMIC-III數據集在目前階段更具研究價值。
數據共享要求數據公開,數據公開化是否會導致惡意濫用,從而侵犯個人隱私值得關注。首先,數據共享默認數據的可及性、透明性和可讀性;另一方面個人隱私總是要求被一種默認的非透明性所保護。這成了大數據時代存在的悖論。如今通過日益成熟的技術以及對需求環境的完善調研,學習先進案例的成功經驗,可以確信隱私并不應該成為共享的對立面。醫療數據的發布需要受到限制,這是因為其所涵蓋的內容能夠直接辨識到患者主體,但也正是這些個體所獨有的屬性影響著醫學研究成果,因此兩者關系不能孤立看待。數據共享的正當與否要綜合權衡該數據的使用場合及數據主體的知情權。醫療機構也需對整個發布過程給予適當的約束和安全防護,將信息安全作為數據利用的前提,將臨床科研數據集建設成值得信賴的平臺,實現隱私與共享、安全與利用之間的“共贏”。
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中華手工(2017年2期)2017-06-06 23:00:31
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
中外會展(2014年4期)2014-11-27 07:46:46
語文知識(2014年1期)2014-02-28 21:59:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
