基于Anchor-free架構的行人檢測方法
2020-06-04 00:59:24張慶伍關勝曉
網絡安全與數據管理 2020年4期
張慶伍,關勝曉
(中國科學技術大學 微電子學院,安徽 合肥 230026)
0 引言
行人檢測是智能安防和車輛輔助駕駛等實際應用的關鍵技術。隨著計算機視覺技術的快速發展,目標檢測算法的性能也不斷提升。目前基于深度學習的目標檢測方法按照是否提出預選框可以分為兩大類:一類是基于預選框的檢測算法,該類算法首先預先設置預選框,然后通過預選框和真實目標進行匹配,最終選出合適的預選框進行訓練,這類算法以Faster-RCNN[1]和SSD[2]為代表;另一類是不使用預選框的檢測算法,該類算法首先對預測目標的關鍵點進行標注,然后將深度神經網絡的輸出設置成相同的格式,直接進行訓練,這類算法以YOLO[3]和DenseBox[4]為代表。其中,Anchor-free的算法框架結構簡潔,更加適用于計算資源較少的實際應用場景。本文在Anchor-free算法的基礎上,首先使用不同的基礎網絡構建檢測算法,然后選出性能穩定的基礎網絡,利用特征金字塔結構[5]對不同卷積層上的特征圖進行融合,提升檢測效果,最后使用多尺度預測的方法,通過不同尺度的預測圖生成了更多的檢測結果,再次提升了檢測效果。本文算法在Citypersons[6]數據集上進行了驗證,其檢測精度相較其他行人檢測算法有一定提升。
1 相關工作
1.1 行人檢測
到目前為止,行人檢測的發展大致分為三個階段:早期的圖像處理階段(基于背景建模的方法)、特征模型分類階段(基于統計學習的方法)和深度學習方法階段。DALAL N等人[7]提出了梯度方向直方圖特征(HOG)。HOG基于梯度信息并允許塊間相互重疊,用于刻畫人體的邊緣特征。FELZENSZWALB P等人[8]提出了DPM(Deformable Parts Model)算法,這是一種基于部件的檢測方法,對目標的形變具有很強的魯棒性,采用了改進后的HOG特征、SVM分類器和滑動窗口的檢測思想。Zhang Liliang等人[9]將Faster RCNN用在了行人檢測領域,通過在RPN網絡后添加隨機森林,對RPN網絡篩選出來的候選區域做分類,提高了網絡對于小目標的檢測能力。Zhou Chunluan等人[10]為了解決行人檢測中的遮擋問題,提出訓練兩個卷積神經網絡分支網絡來分別做全身估計和可見部分估計的方法,并將兩個分支網絡的輸出進行互補,以減少遮擋對檢測的影響。Liu Wei等人[11]提出了一種級聯結構,并將其使用在單步檢測框架中,在保證檢測速度的情況下,進一步提升了檢測精度。
1.2 Anchor-free檢測框架
早期的深度學習檢測框架多是基于預選框(Anchor-base)的,在使用時,需要在特征圖上密集平鋪大量預選框,但其中僅有少量樣本是正樣本,最終導致計算資源花費在無用的樣本上。另外,對預選框的預處理進一步增加了算法的計算量。同時,預選框的各項參數都需要人為設置,這使得算法的檢測性能會很大程度上受到預設參數的影響,而且調參的過程十分復雜。基于上述原因,Anchor-free算法開始受到關注。DenseBox構建了一種Anchor-free檢測框架,即特征提取網絡和檢測頭組合的方式。FSAF[12]則將Anchor-base和Anchor-free兩種檢測方式相結合,在原有的FPN網絡上添加一個分支網絡,同時利用兩種檢測方式生成的結果,在COCO[13]數據集上做出了有競爭力的結果。隨后Anchor-free框架逐漸被使用到行人檢測的任務中,Song Tao等人提出了基于Anchor-free架構的行人檢測方法TLL[14],將人體中軸線作為標注。為了提升檢測效果,又采用了基于馬爾可夫隨機場的后處理方案。Liu Wei等人設計了基于Anchor-free的檢測方法CSP[15],將行人的中心點作為標注,其主要關注的是如何用盡量簡單的結構完成檢測并獲得好的效果,其網絡結構相較其他工作更加簡潔。
Anchor-free框架拋棄了提出預選框的步驟,將算法的流程簡化為特征提取、檢測頭和后處理三個部分。但一味地簡化會造成檢測精度的損失,所以本文在Anchor-free架構的基礎上將算法流程增加為特征提取、特征融合、檢測頭、后處理四個部分,按照該流程重新設計了卷積神經網絡,并使用中心點和高度作為標注訓練神經網絡,最終在Citypersons數據集上進行驗證。
2 算法設計
2.1 模型設計
模型的結構共包括三個部分:特征提取網絡、特征融合網絡、檢測頭。模型為全卷積的網絡結構。通常將特征提取網絡中生成的第N層特征圖命名為StageN,特征提取網絡可以描述為:
φi=F(φi-1)
(1)
φi表示第i層的特征圖,φi-1表示第i-1層的特征圖,F表示兩個特征圖之間的卷積、池化、歸一化等操作。可以將N層的特征圖表述為一個集合:
Φ={φ1,φ2,…,φN}
(2)
式中,φi表示第i層的特征圖,Φ表示所有特征圖的集合。然后使用這些特征層構建特征融合模塊。構建的方式可以表述為:
(3)
其中,f表示反卷積操作,φ表示特征融合網絡的特征圖,φ表示特征提取網絡的特征圖。算法網絡結構如圖1所示。特征提取網絡將輸入圖像轉化成不同分辨率的特征圖。以ResNet為例,ResNet的所有中間層可以被劃分成5個部分,本文取其中的后四層,分別下采樣至原圖大小的1/16,1/64和1/256,然后經過特征融合網絡生成特征金字塔結構,最后通過檢測頭生成預測圖。訓練時使用640×1 280大小的圖像,將其下采樣至160×320,80×160,40×80這三種大小,然后分別用檢測頭生成預測結果。

圖1 算法網絡結構
相比CSP和TLL兩種方法,本文的方法增加了特征融合網絡,代替了原有的對特征圖直接反卷積然后拼接的方式。
2.2 標注方法和損失函數設計
2.2.1 標注方法
使用Anchor-free框架的檢測算法的標注方式有檢測框的角點、目標中軸線、目標中心點等。為了減少計算量,本文使用目標中心點和目標高度作為標注。通過該種標注方法,生成一張高斯熱圖,該圖可以表述為:
(4)

(5)
其中,x,y是目標中心點在高斯熱圖中的坐標,(i,j)表示高斯熱圖中的位置,k表示目標的標號,(σw,σh)為目標的寬和高。生成的高斯熱圖如圖2所示。

圖2 高斯熱圖可視化
可以看出,越靠近目標中心點,標注的值越接近1,越遠離目標中心點,標注的值越接近0。
2.2.2 損失函數
總的損失函數由兩個部分組成:中心點損失和目標尺度損失。對于中心點的預測,使用Focal Loss[16]。為了平衡正負樣本對于總的損失函數的貢獻,增加了αij項。

(6)
式中,W和H為原圖的寬和高;r為預測圖的縮放比例;k表示該原圖中目標的個數;Pij表示預測圖中坐標為(i,j)的點上的預測值;yij表示預測圖中坐標為(i,j)的點上是否存在中心點;γ和β是兩個可以設置的超參數,分別用于控制訓練速度和正負樣本平衡;Mij的含義如式(4)所示,表示預測圖中坐標為(i,j)的點上的標注值。
對于目標高度的預測,使用SmoothL1[17]損失函數使訓練過程更加平滑,函數表述為:
(7)
(8)
其中,sk、tk分別是目標高度的預測值和真實值,將sk、tk的差值作為SmoothL1函數的輸入。k是目標的標號,K表示所有目標的個數。
總的損失函數可以表述為:
L=λcLcenter+λsLscale
(9)
其中,L表示總的損失函數,Lcenter和Lscale的含義如式(6)和式(7)所示。λc和λs分別設置為0.01和1,用于控制兩部分損失函數的比重。
3 實驗
為了對本文提出的方法進行有效的評估,使用Citypersons數據集進行驗證。該數據集共有2 975張圖片,包含19 238個行人,平均每張圖片上含有行人6.47個。其中被輕微遮擋的目標占整個數據集的55.9%,被一般遮擋的目標約占整個數據集的20%,檢測難度相對較大,更加適合驗證算法的性能。實驗均在Ubuntu16.04操作系統,GTX080Ti的GPU集群上使用Keras框架完成。
為了更好地評估算法的性能,將檢測指標分成三類,各種遮擋情況下的數據示例如圖3所示。嚴重遮擋示例(遮擋率60%以上)如圖3(a)所示,普通遮擋示例(遮擋率30%~60%)如圖3(b)所示,輕微遮擋示例(遮擋率30%以下)如圖3(c)所示。其中遮擋率是被遮擋部分與目標大小的比值。

圖3 驗證集部分樣本圖
3.1 不同基礎網絡的實驗效果
特征提取網絡是Anchor-free算法的基礎網絡,為了選擇合適的基礎網絡,首先對各種基礎網絡的性能進行測試,也就是分別利用不同的基礎網絡進行特征提取,然后比較檢測效果。比較的結果如表1所示,評估指標使用漏檢率(Miss Rate)。

表1 各種基礎網絡性能比較 (%)
經過比較,ResNet的性能最為穩定,MobileNet的速度更快,但是檢測精度略有下降。由于顯存爆炸問題,本文將DenseNet的批尺寸(Batchsize)設置為4,但其整體性能仍略遜于ResNet。所以本文使用Resnet-50進行后續實驗。
3.2 特征融合策略
為了能將含有更多細節信息的淺層特征圖和含有更多語義信息的深層特征圖進行融合,本文在算法中加入了特征金字塔網絡(FPN)結構。加入FPN后的實驗結果如表2所示,結果從100到150 Epoch中選取。

表2 加入FPN后的實驗效果 (%)
從表2可以看出,加入FPN后,輕微遮擋和一般遮擋情況下的檢測效果并沒有明顯變化,遮擋嚴重情況下的檢測效果提升較為明顯,檢測結果如圖4所示。產生該現象的原因是被遮擋目標的信息在池化過程中會不斷丟失,而淺層特征圖能保留這些信息,深層特征圖能更好地描述目標的位置信息。所以使用FPN融合兩種特征圖能夠提升嚴重遮擋情況下的檢測效果。

圖4 加入FPN后的部分檢測結果
3.3 多尺度預測
為了獲得更好的檢測效果,本文采用了多尺度預測的方法。分別使用FPN三個不同尺度的特征圖生成預測結果。預測得到的高斯熱圖分別為原圖大小的1/16,1/64,1/256,再將所有的檢測結果整合。將結果在Citypersons數據集上與其他算法對比,結果如表3所示。
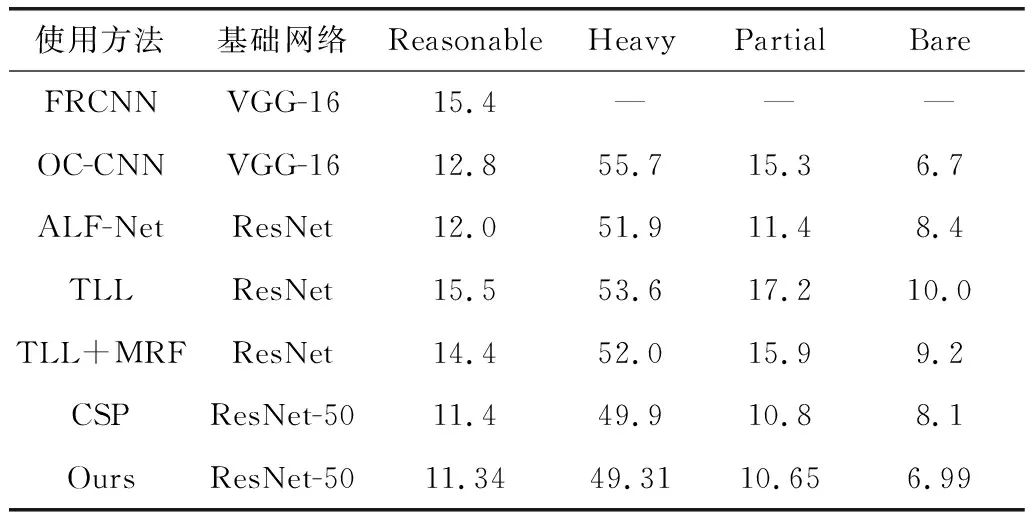
表3 行人檢測算法效果對比 (%)
與其他算法的實驗結果相比,本文算法在目標遮擋嚴重和普通遮擋的兩個指標上有更好的表現,原因是由于使用了多尺度的檢測結構,同一目標的周圍產生了更多的高質量預測框,且多尺度預測針對不同大小的目標有著不同的預測效果,小尺度的預測圖更加適合預測大型目標,大尺度的預測圖對小目標的預測效果更好。
使用多尺度檢測方法后,在嚴重遮擋情況下的漏檢率有所上升,但是普通遮擋和輕微遮擋時漏檢率均有所下降,檢測結果如圖5所示。產生該現象的原因是由于在嚴重遮擋情況下,在目標周圍生成的預測結果更多,但后處理過程使用了非極大值抑制(NMS),并沒有處理這些無效預測框,反而將正確結果抑制刪除。

圖5 使用多尺度預測方法后的部分檢測結果
從上述結果可以看出,檢測失敗的情況多為無效檢測或重復檢測。造成該現象的原因是多尺度預測策略同時增加了正確和無效的檢測結果,且無效檢測結果的數量更多。針對該問題,本文嘗試了不同的輸出閾值,即為預測得到的高斯熱圖設置一個閾值,若預測值大于該閾值則認為該點存在目標中心點。實驗結果如圖6所示。

圖6 漏檢率和輸出閾值的對應關系
從圖6可以看出,隨著輸出閾值的提高,漏檢率先降低后升高。算法在輸出閾值設為0.15時檢測效果最好。這是由于輸出閾值過小會導致算法輸出大量的無效預測,而過高的輸出閾值又會抑制算法輸出正確結果。
本文使用的測試用例共500張,測試圖片大小為1 024×2 048,測試10次取平均值。平均每張圖片耗時0.36 s。將圖片縮放至480×640大小后,平均每張圖片耗時約61 ms,基本滿足應用要求。
4 結束語
本文基于Anchor-free架構,設計了一種特征提取、特征融合加多尺度檢測頭的網絡結構。融合了不同特征圖的信息并對同一目標提出了更多的有效預測,實驗證明該方法提高了檢測效果。
由實驗結果還發現,在使用多尺度預測方法后,目標周圍產生的部分無效預測會抑制正確結果,導致檢測失敗。解決這個問題需要對檢測結果做進一步后處理。Anchor-free架構往往采用NMS進行后處理,所以下一步可以通過優化NMS進一步提升檢測效果。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
電子制作(2019年15期)2019-08-27 01:12:00
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
海峽科技與產業(2016年3期)2016-05-17 04:32:12
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
