基于YOLO算法和RK3399平臺的行人檢測實時性研究
2020-06-04 12:55:32胡鵬張光建
數(shù)字技術與應用 2020年3期
胡鵬 張光建


摘要:為了解決在固定背景下端到端的行人檢測難于達到實時性問題,并且結合實際開發(fā)板的特性與任務特點,提出了新的骨干特征提取網絡,采用YOLO作為檢測算法基礎結構。所提出的方法以預測速度快為目標,該方法取得了在RK3399開發(fā)板上運行效率達11.842fps的良好結果,達到了實時性目的。在實驗上從訓練、預測兩個方面于YOLOv1、v2、v3的其它精簡版網絡進行了對比。研究表明訓練時損失值與網絡的復雜性并無明顯的相關性,同樣的與mAP也無明顯相關性,預測時新的特征提取骨干網絡能在單類別目標檢測任務中在大幅度提高檢測速度的同時有較好的預測精度。
關鍵詞:YOLO;RK3399;實時性;固定背景;行人檢測
中圖分類號:TP391.4 文獻標識碼:A 文章編號:1007-9416(2020)03-0078-04
0 引言
作為目標檢測領域里的一個較為重要的一個分支,固定背景下的行人檢測在視頻監(jiān)控等方面得到廣泛的應用。經過幾十年的不斷發(fā)展,從人工特征工程到機器學習特征工程,從人工設計模板發(fā)展為端到端深度學習,在檢測精度上有了很大的提高。同時在當前檢測精度尚可的情況下,研究更多的關注點是在有限的條件下?lián)碛懈俚挠嬎懔浚斓念A測速度。
YOLO[1]將檢測任務視為回歸任務進行處理,在基礎骨干網絡相同的情況下,有著更快的預測速度。通過借鑒YOLO這一思想,保障了預測的Benchmark速度。但在部署到嵌入式端時(如RK3399平臺),發(fā)現(xiàn)如若不對骨干特征提取網絡進行更改,依舊難于達到實時預測,由此引出本文。
1 行人檢測與網絡訓練
1.1 改進的網絡設計
為了能達到實時性目的,并結合實際數(shù)據(jù)目標特征,對特征提取網絡進行大幅度修改。相比于YOLO_v1/2/3的精簡版(Tiny)還要精簡。取消了上采樣層與疊加層,只保留了卷積層和最大池化層。骨干特征提取網絡層數(shù)縮減到只有8層,遠小于YOLO_v1-Tiny的15層,YOLO_v2-Tiny的15層,YOLO_v3-Tiny的20層。
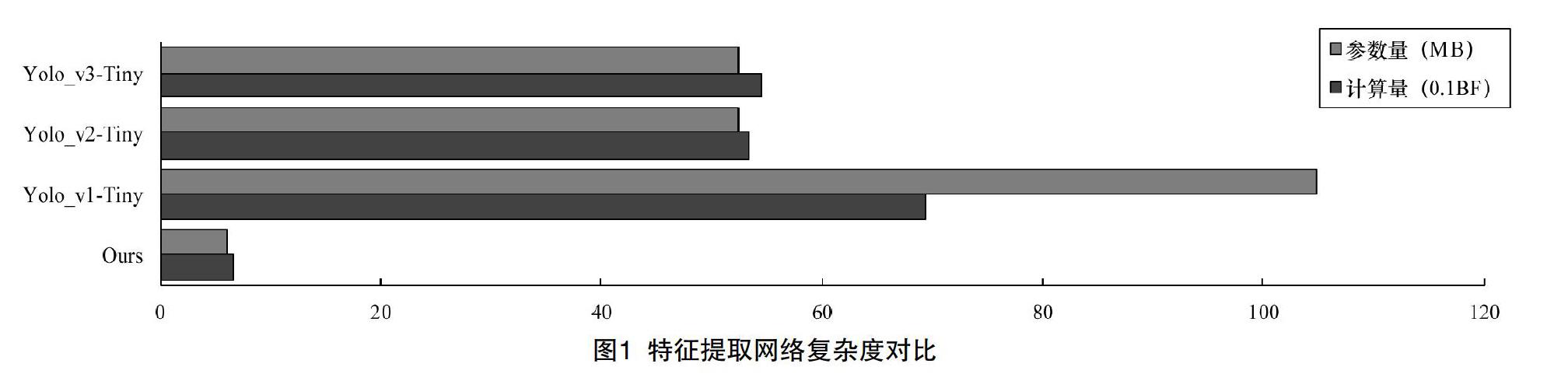
同時,為了衡量網絡模型復雜度,從計算量與參數(shù)量這兩個指標進行評價,如圖1所示,本文模型相比于YOLO_v2/3-Tiny分別是后者的~12.4%和~11.7%,甚至相比于YOLO_v1-Tiny而言分別是后者的9.66%和5.86%。骨干特征提取網絡的更簡單,為在開發(fā)板上達到實時性要求打下了良好的基礎。
在設計特征提取網絡時,考慮到計算量這一條件限制,并沒有使用小卷積核將網絡加深的方式來獲取更大的感受野與更少的參數(shù)量[2],而是通過增大卷積核大小與步長的方式,這樣做的目的一方面是增加卷積核感受野。另一方面是將特征圖尺寸快速降下來,減少后續(xù)的計算量。同時,低層特征卷積核個數(shù)設計得并不多,原因是根據(jù)對數(shù)據(jù)集的觀察,發(fā)現(xiàn)小紋理并不豐富。豐富的是高層網絡的上下文。期望的是通過最后兩次的1x1卷積進行維度整合與達到全鏈接層的目的[3],使得網絡層頂部特征上下文能變得可分(圖2)。最后得到35×35×30大小的特征圖用于回歸預測。
1.2 訓練數(shù)據(jù)集
本文實驗數(shù)據(jù)集圖片來源于固定的雙目網絡攝像頭,先拍攝成雙目視頻,然后解幀而成。單個攝像頭的分辨率為320×240。俯視角度或高角度下拍攝得到,標注框標定結果為頭與肩位置(人工篩選剔除有傘遮擋情況的目標標注框)。經過標注處理,得到最終的數(shù)據(jù)集共包含了6280張圖片(圖3),隨機劃分為訓練集5000張,測試集1000張,驗證集280張。在訓練之前,先利用K-means對訓練集里標注對象框的寬高尺寸進行聚類分析,得到標注框寬高相對圖片寬高比結果為:(0.7236,1.0382),(1.0214,1.1645),(0.9048,1.5255),(1.2038,1.3900),(1.1960,1.8314),作為Anchor參數(shù)輸入,Anchor與標注框的平均IoU為85.03%。
1.3 訓練過程
整個實驗與對比試驗訓練過程在Intel Core i7-7700k+ NVIDIA RTX2080ti硬件條件下完成。由于完全自定義骨干特征提取網絡、預訓練模型并不一定有明顯促進效果[4]、以及對比試驗公平性等原因,均沒有在ImageNet等數(shù)據(jù)集上進行預訓練以及使用預訓練模型。在訓練策略上,為了防止過擬合,均啟用了飽和度、曝光、色調的隨機調整來進行數(shù)據(jù)增強,權重衰減正則項值為0.0005。為了避免陷入局部最優(yōu)的情況,動量值為0.9。采用了多分布策略學習率。Batch大小均為64。
為了降低訓練的偶然因素,本文將整個訓練過程重復了5次,相同繪制節(jié)點數(shù)據(jù)值取的是5次訓練算數(shù)平均值。所有網絡模型訓練實驗Loss在2000批之前迅速降低且之后趨于收斂。每個網絡模型最大訓練次數(shù)為40000次終止,沒有設置提前終止條件。每1000個Batch保存一次模型,得到40個網絡模型,并在測試集內進行測試。在計算mAP時,選擇IoU的閾值為0.5,預測結果mAP值總體趨勢均為先快速上升,然后振蕩緩慢上升,在25000個Batch過后相對穩(wěn)定。在計算aIoU時,選取的置信度閾值為0.25,得到平均交并比預測結果,值在25000個Batch后相對穩(wěn)定,而前期均有不同程度的振蕩過程(圖4)。
設計的模型損失收斂值與YOLO_v1-Tiny,YOLO_v2-Tiny基本持平。值得注意的是YOLO_v3-Tiny的收斂值則有將近3倍之多,而在測試集上在25000批之后趨于穩(wěn)定的測試值來看,無論是IoU閾值為0.5時的mAP值還是置信度閾值為0.25時的aIoU值,YOLO_v3-Tiny均為最佳。并且從曲線圖也可以發(fā)現(xiàn)在25000批之后平均損失值最小的是YOLO_v1-Tiny,但mAP與aIoU表現(xiàn)均不是最優(yōu)。可以看出損失收斂值與測試集上得到的mAP與aIoU值沒有明顯的相關性。證明在目標檢測任務中損失值并不一定是越小越好。
