基于Msmall-Patch訓練的夜晚單幅圖像去霧算法——MP-CGAN
2020-06-06 02:07:16王云飛王園宇
計算機應用 2020年3期
王云飛,王園宇
(太原理工大學信息與計算機學院,山西晉中030600)
(*通信作者電子郵箱w_h7377@163.com)
0 引言
霧是懸浮在空氣中的微粒子,會對光造成散射、折射等現象,在夜晚光照強度低的情況下,霧會加重色彩失真、能見度低的程度,給人的戶外行動造成不便,因此,如何有效去除夜間霧具有研究意義。
現有夜間去霧方法大都是對白天去霧方法的改進,如對暗通道先驗(Dark Channel Prior,DCP)[1]與大氣散射模型[2]改進:文獻[3]提出用顏色轉移法[4],將夜晚圖片轉換為灰色圖片,結合DCP 去霧,結果存在偽影;文獻[5]提出用光照補償實現光照平衡后得到大氣光,結果出現顏色失真;文獻[6]提出用層分離技術[7]去除光輝,結合DCP 去霧,結果出現噪聲;文獻[8]提出用局部大氣光與全局大氣光的均值作為大氣光值,其結果出現顏色失真,這是因為大氣光取值不準確;文獻[9]在文獻[6]基礎上使用超像素算法去霧,其計算量較大;文獻[10]使用圖像融合方法實現去霧,其結果存在偽影;文獻[11]提出用最大反射先驗得到大氣光,其取得的大氣光值存在偏差;文獻[12]提出用權重熵估計透射率,結合DCP 去霧結果存在偽影。綜上所述,用這些方法實現夜間去霧會出現顏色失真、偽影及噪聲等現象,這是因為相對白天,夜晚大氣光不均勻,因此,這些方法取得的中間參數大氣光及透射率值不準確,導致恢復圖像存在顏色失真、偽影、噪聲等現象。方帥等[13]提出通過估計光照圖求得大氣光值,用信息熵估計透射率,其結果存在偽影,這是因為信息熵估計透射率不準確;楊愛萍等[14]提出將圖像分為結構層與紋理層,在結構層用中值濾波器求得大氣光值,在紋理層上估計透射率,最后將兩者結合去霧,其結果存在顏色失真,這是對大氣光取值不準確造成的。
與上述方法相反,文獻[15]提出用卷積神經網絡(Convolutional Neural Network,CNN)實現從夜晚霧圖到清晰圖直接去霧,但其恢復圖像存在模糊現象,這是由像素損失自身缺陷造成的。近些年生成對抗網絡(Generated Adversarial Network,GAN)[16]在圖像重建方面取得了不錯的效果,其由生成器與鑒別器構成,將噪聲輸入生成器學習真實數據分布,鑒別器判斷數據真假性,其缺點是生成不受控制。為解決GAN生成自由的問題,文獻[17]提出條件生成對抗網絡(Conditional Generated Adversarial Network,CGAN),將條件與噪聲同時輸入生成器,目標函數如式(1)所示:
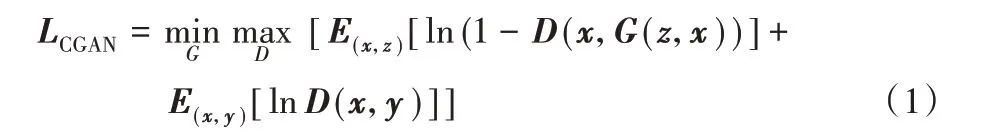
其中:x指輸入圖片,y指清晰圖片,z指隨機噪聲。但CGAN會引入噪聲,對此,文獻[18]提出感知損失,即用已經訓練好的深層神經網絡提取圖片高級特征;文獻[19]在CGAN 損失基礎上加入像素損失,其結果仍存在噪聲偽影;文獻[20-23]在文獻[19]基礎上加入感知損失,其結果仍有偽影出現,這說明感知損失不足以消除CGAN 產生的噪聲偽影;文獻[24]在生成器訓練時對鑒別器最后Patch 部分使用Min-Pool方式訓練,這是因為得分低的區域是圖片中最假的區域,然而,生成器與鑒別器訓練是迭代進行的,僅對生成器采取這種訓練使得兩者訓練不同步,造成鑒別器容易將生成器生成的圖片誤判為真。
鑒于上述分析,由于圖像去霧亦屬于圖像重建,因此本文使用CGAN 實現夜間圖像去霧,這跳過估計中間參數步驟,同時避免了像素損失缺點;然而,CGAN 容易產生噪聲及偽影,同時容易誤判,對此,本文提出基于Msmall-Patch 訓練的條件生成網絡(Multiple small-Patch training for Conditional Generated Adversarial Network,MP-CGAN)去霧算法,首先對生成器與鑒別器都使用Msmall-Patch 訓練,即只對圖片的關鍵部分懲罰,一方面加強了對糟糕區域或容易被誤判區域的懲罰,另一方面保持了生成器與鑒別器訓練的同步性;與之對應,提出重度懲罰損失,即提取數個最大損失值懲罰圖片;另外,為得到更好的去霧效果,提出新的復合損失函數,將重度懲罰損失、感知損失與對抗感知損失結合使用,并對UNet(U Network)網絡[25]改進,對其增加多個密集塊緩解梯度消失。
1 本文方法
1.1 生成器
生成器的作用是輸入夜間霧圖片產生清晰圖片,除去霧外,生成器還可以保留原始圖片的結構與細節,深層的神經網絡可以提取更多的高級特征;然而,這也容易造成梯度消失,使網絡訓練與收斂困難。鑒于上述分析,本文采用的生成器網絡結構與文獻[26]類似,將UNet 與密集神經網絡(Densely connected convolutional Network,DenseNet)[27]結 合 即UDNet(U Densely connected convolutional Network)網絡,這是因為DenseNet 網絡設計了多個密集塊(Dense Block,DB),密集塊中的每一層神經元彼此連接,大量短連接緩解了梯度消失,同時加強信息流動與特征復用,減少參數計算量與特征丟失;UNet 用長跳躍連接,將編碼器淺層特征直接連接到對稱的解碼器深層特征,減少低維特征丟失。將兩種網絡結合使用比單獨使用UNet 網絡有較好的去霧效果,具體細節在實驗2.3節詳述,UDNet 網絡結構如圖1 所示,生成器包括編碼器與解碼器,密集塊中每層神經元之間包括組合操作,其由歸一化層(Batch Normalization,BN)、ReLU(Rectified Liner Uints)激活函數及卷積層組成,目的是保持圖片大小不變;編碼器密集塊之間是下采樣(Downsampling,D)層,包括卷積與平均池化操作,目的是降低圖片維度大小;解碼器密集塊之間是上采樣(Upsampling,U)層,只包括反卷積操作,目的是增加圖片維度大小;生成器網絡結構參數設置在2.1節詳述。
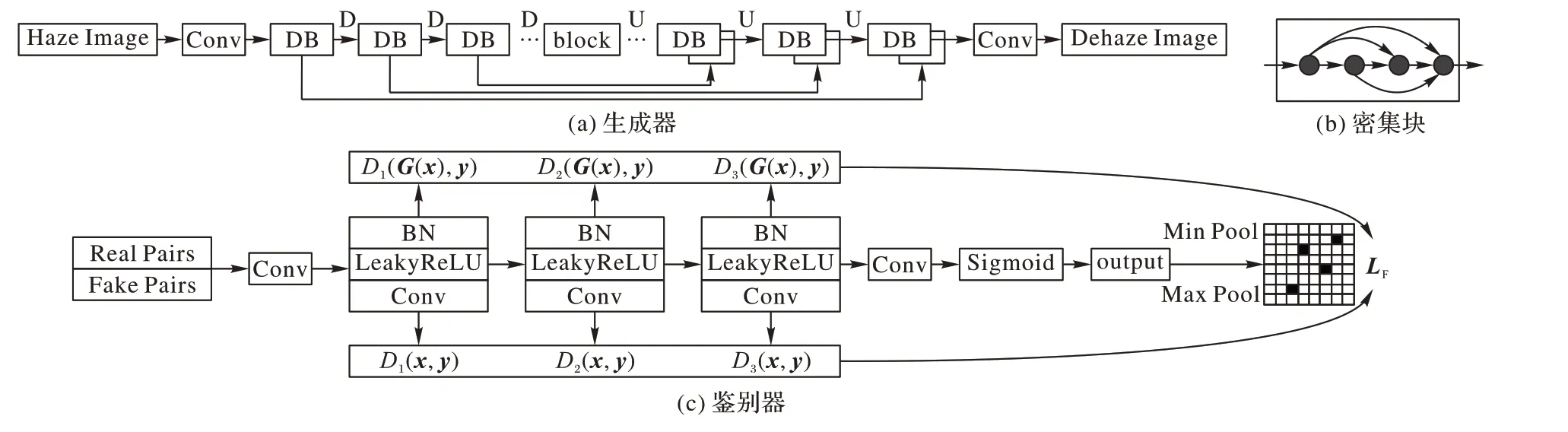
圖1 MP-CGAN網絡結構Fig. 1 Network structure of MP-CGAN
1.2 鑒別器
鑒別器的作用是判斷圖片的真假性,將真實圖片與假圖片對輸入鑒別器判斷:若為真實圖片,鑒別器給出一個接近于一的高分;若為假圖片,給出一個接近于零的低分。生成器期望生成的假圖片能騙過鑒別器,而鑒別器的目的就是鑒別出真假圖片,兩者互相抗衡,保持動態平衡訓練直到鑒別器無法判別圖片真假性停止訓練。
與文獻[20]相似,本文采用卷積層、BN、LeakyReLU(Leaky Rectified Liner Uints)激活函數組成鑒別器網絡,并采用文獻[19]提出的Patch GAN 結構,即判別器判斷圖片每塊區域的真假性;然而,本文與文獻[19-20]網絡結構有以下方面不同:1)利用鑒別器網絡多個隱含層提取真實圖片與假圖片的中低級特征,將特征圖誤差作為對抗感知損失,以最大限度保留全局結構;2)若生成器訓練能力強,會導致其生成的假圖片很容易騙過鑒別器,因此采用Msmall-Patch 網絡結構,即在原先Patch結構基礎上作優化,目的是提取糟糕區域或容易被誤判區域,對其重度懲罰,同時使兩者對彼此的抗衡能力增強,提高生成圖片質量,具體細節在1.3節與1.4節詳述,鑒別器網絡結構參數設置在2.1節詳述,網絡結構如圖1所示。
1.3 Msmall-Patch訓練
文獻[19]CGAN 采用Patch 訓練,鑒別器輸出N×N個概率值,每個概率值表示原圖中的某一個區域有多大概率是真實圖片;然而,Patch 訓練是對多個區域實施平均懲罰,其容易忽略對糟糕區域懲罰,且容易誤判;另外,人的視野總是容易被糟糕區域吸引,即使圖片中大部分區域很真實,若有一小部分區域是糟糕區域,這幅圖片會被認為是質量不好的圖片。因此提出對生成器與鑒別器都使用Msmall-Patch 訓練,即對提取到的多個小區域實施重度懲罰,這些小區域對應糟糕區域或容易被誤判區域,另外,這樣保持了生成器與鑒別器訓練同步性,會加快訓練收斂。具體方式為:生成器訓練與文獻[24]類似。鑒別器訓練時,當輸入假圖片時對鑒別器最后Patch 部分用Max-Pool方式訓練,這是因為假圖片中得分較高的區域容易被誤判為真實圖片;同理,輸入真實圖片時對鑒別器最后Patch 部分采用Min-Pool方式訓練。綜上所述,生成器采用Msmall-Patch 訓練重點懲罰糟糕區域,鑒別器采用Msmall-Patch 訓練提高鑒別器鑒別能力,減少誤判。圖2(a)展示輸入假圖片時鑒別器使用Msmall-Patch 訓練,可以看出Patch 訓練對圖片的每一部分都懲罰(圖片顯示大小為4×4),而Msmall-Patch 訓練只對最容易被誤判部分懲罰(圖片顯示大小為2×2,對應圖2(b)白框區域)。

圖2 Msmall-Patch訓練Fig. 2 Msmall-Patch training
1.4 損失函數
1.4.1 重度懲罰損失
Patch 訓練對應平均懲罰損失,即對所有損失取均值懲罰圖片;公式如式(2):
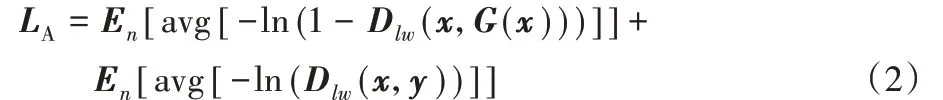
其中:x指霧圖片,y指清晰圖片,l、w、n分別指樣本圖片的長度、寬度與批處理數,E指期望值,avg 指對所有損失取均值。平均懲罰損失會對所有區域實施均勻懲罰,這會造成對噪聲偽影出現的區域懲罰力度不夠的問題。為解決此問題,與Msmall-Patch 訓練相對應,提出重度懲罰損失,即選取數個最大損失值取均值懲罰圖片,具體表現為:生成器方面,產生最大損失值的區域對應糟糕區域,鑒別器方面,產生最大損失值的區域對應易被誤判區域。因此,使用重度懲罰損失可以加強對噪聲的懲罰,其公式如式(3):
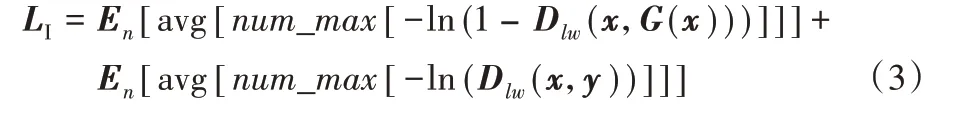
其中,num_max指從輸出中選取數個最大損失值;圖3(a)、(b)展示了平均懲罰損失與重度懲罰損失。可以看出,平均懲罰損失對每個區域都懲罰,而重度懲罰損失只懲罰部分關鍵(糟糕或被誤判)區域。
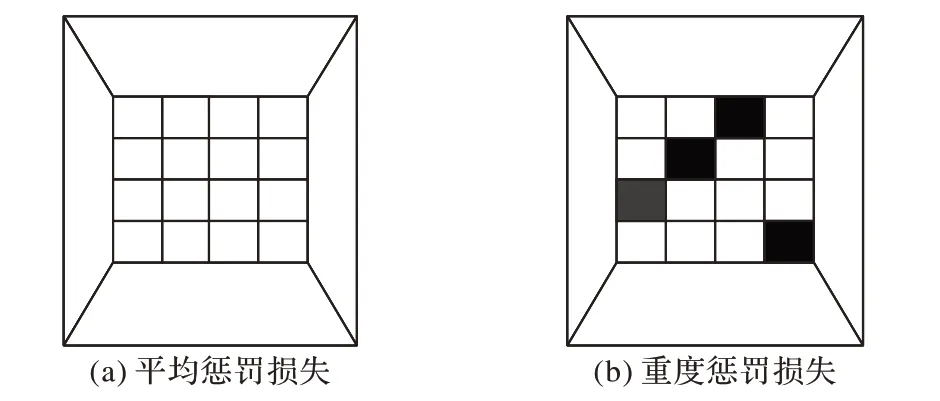
圖3 損失對比Fig. 3 Loss comparison
1.4.2 對抗感知損失
CGAN 會引入噪聲,為去除噪聲,文獻[19]加入像素損失,但像素損失會導致圖像全局結構上出現細節丟失、顏色失真和模糊現象,且容易誤判,如兩幅圖像上僅有少量像素不同,人腦識別兩幅圖像是相似的,像素損失卻判斷兩幅圖像有較大不同;為進一步提升生成圖片質量,文獻[28]提出特征匹配損失,即將真假圖片輸入鑒別器,對其中某一層隱含層作特征提取,這可以闡述人的視覺感受,解決像素損失的缺點,同時提高對噪聲的懲罰,提高生成圖片質量。盡管Msmall-Patch訓練會加強對噪聲的懲罰,但仍有殘留,為提取更豐富的中低級特征,去除由CGAN 引入的噪聲等,與像素損失不同,本文將對抗感知損失[29]加入生成器損失,其特點是將鑒別器多層隱含層作為特征提取器,將真實圖片與假圖片輸入鑒別器網絡提取圖片特征,將轉換圖片與目標圖片的特征圖誤差作為對抗感知損失,其公式如式(4):
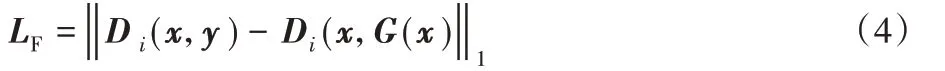
其中:x表示真實霧圖,y表示真實清晰圖片,Di表示鑒別器網絡第i層隱含層提取的特征圖。
1.4.3 感知損失
盡管引入對抗感知損失會去除一部分噪聲偽影等,但仍有殘留,為減小顏色失真與進一步提升生成圖片細節,本文引入感知損失。與對抗感知損失類似,感知損失[18]也是將CNN網絡隱含層作為特征提取器,然而,感知損失是用已經訓練好的圖片分類網絡VGG(Visual Geometry Group)[30]作特征提取;相對鑒別器網絡,VGG 有更深的網絡結構與多層卷積塊,不僅可以保留全局結構,還可以提取更豐富的高級特征與細節,如顏色與紋理方面,在視覺效果上有更好的表現;另外,感知損失不需要成對圖片輸入網絡,而對抗感知損失與此相反,這使感知損失訓練參數較少,效率較高。過程是將真實圖片與假圖片輸入VGG 網絡隱含層提取高級特征,經過pool4 層之后計算感知損失,公式如式(5):

其中:V表示VGG 網絡的隱含層提取的特征圖,x指夜晚霧圖片,y指真實清晰圖片。綜上所述,生成器損失為:
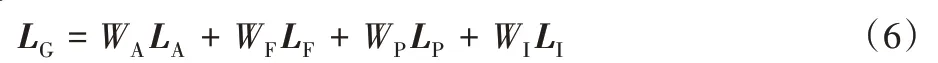
其中:W指權重,通過最小化式(6)訓練生成器;生成器與鑒別器依次迭代訓練,鑒別器損失為:

2 實驗
2.1 實驗訓練及網絡結構參數設置
本文使用來自文獻[15]中的數據集,圖片包括城市、街道及其他普通夜景,數據集包括黃色與白色背景合成霧圖,如圖4所示;數據集共有20 000張,其中訓練集有19 000張,測試集有800 張,驗證集200 張。生成器網絡結構參數設置:編碼器與解碼器各包括5 個密集塊,每個密集塊有4 層神經元,瓶頸層設1 個密集塊12 層神經元,通道增長率為15,密集塊中的卷積核大小是3×3,零填充為1,步幅為1;密集塊之間采用為2×2 平均池化,生成器通道數為C(60)-DB(120)-D(60)-DB
(120)-D(60)-DB(120)-D(60)-DB(120)-D(60)-DB(120)-D(60)-DB(240)-U(60)-DB(240)-U(60)-DB(240)-U(60)-DB(240)-U(60)-DB(240)-U(60)-DB(240)-C(3),其中:C(K)指卷積后輸出的通道數,DB(K)指密集塊輸出的通道數,D(K)指下采樣后的通道數,U(K)指上采樣后的通道數。

圖4 數據集圖片Fig. 4 Images in dataset
鑒別器網絡結構參數設置:網絡共設五層卷積層,其中前兩層卷積核大小為3×3,步幅為1,零填充為1;后三層卷積核大小為4×4,步幅為2,零填充為1;鑒別器輸出patch 大小為32×32(其中每一個值對應原始圖片70×70 區域),Max/Min-Pool 大小為8×8,Msmall-Patch 大小為4×4;鑒別器網絡由BN-LeakyReLU-Conv 組成,簡寫為BLC,則鑒別器通道數為C(64)-BLC(128)-BLC(256)-BLC(512)-C(1)。
模型使用Tensorflow 框架在TitanX GPU 上訓練大約15 h;生成器的輸入輸出大小為256×256×3,鑒別器的輸入大小為256×256×6,輸 出 大 小 為256×256×1;在 訓 練 階 段,設 置batchsize=10,epoch=250,采用Adam 優化算法訓練網絡,β1=0.5,學習率設為1×10-4,經過50 次epoch 訓練后每個epoch 學習率衰減1×10-6倍,鑒別器與生成器循環迭代訓練,設置WA=WI=0.01,WF=0.001,WP=10;VGG 網絡輸入圖片大小設為224×224,每經過25 次epoch 訓練驗證集進行驗證,由于生成對抗網絡損失無法指示學習過程,所以在生成圖片質量好時停止訓練。
2.2 分析網絡結構作用
本文采用UDNet 網絡,相對UNet 網絡來說,UDNet 網絡在其基礎上增加多個密集塊進一步加強信息流動與特征復用;為證明UDNet 網絡的有效性,本文在相同條件設置下對UNet 網絡也進行訓練,圖5 展示了兩種網絡結構的去霧質量效果,盡管UNet 與UDNet 能產生相似結果,但相比UNet(29.54 dB,0.89),UDNet(29.98 dB,0.92)產生較大的峰值信噪 比(Peak Signal-to-Noise Ratio,PSNR)與 結 構 相 似 性(Structural SIMilarity,SSIM)值。
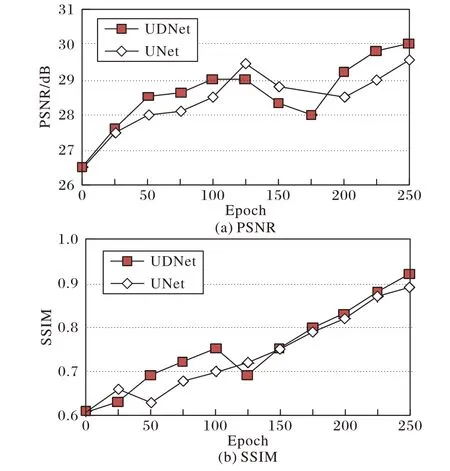
圖5 兩種網絡訓練時的評估值變化曲線Fig. 5 Evaluation value-curves oftwo networks during training
2.3 分析損失函數作用
為生成質量更高的圖片,本文提出新的復合損失函數;為了驗證每一種損失的有效性,本文在驗證集上驗證,并用表1說明。可以看出,相對平均懲罰,重度懲罰損失在PSNR 上略有提升,在SSIM 上有較大提高,這是因為重度懲罰損失對結構的懲罰程度更大;對抗感知損失在PSNR 上有較大提高,感知損失在SSIM 上有較大提高,這是因為相對對抗感知損失,感知損失提取的特征為高級特征,提取的細節更豐富;復合損失函數使用時PSNR 值與SSIM 值最高。同時,圖6 展示了驗證集例子在不同損失下的去霧效果,圖6(b)表示加入平均懲罰損失雖然去掉部分霧,但引入偽影及噪聲(如燈籠處及燈光處),圖6(c)表示加入對抗感知損失,發現消除了一部分偽影,但仍有霧殘留,圖6(d)表示加入感知損失消除了偽影,但在圖像細節及顏色保真方面與真實清晰圖仍有差距;圖6(e)表示重度懲罰損失仍會產生少許的偽影;圖6(f)表示加入對抗感知損失消除了偽影;圖6(g)表示加入感知損失去霧效果與圖6(h)(真實清晰圖)較接近,這是因為感知損失能提取更豐富的紋理、顏色特征。
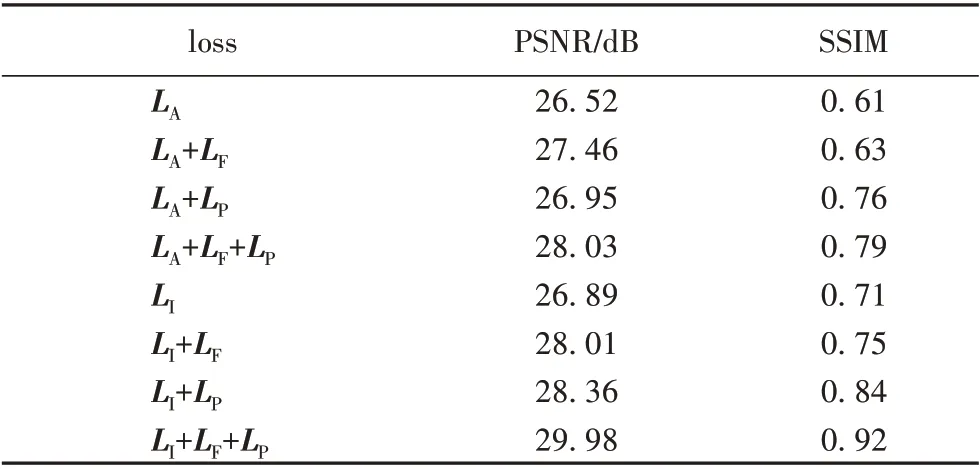
表1 不同損失的去霧質量評估Tab. 1 Dehazing quality evaluation with different losses

圖6 不同損失的去霧效果Fig. 6 Dehazing effect with different losses
2.4 合成霧圖上的去霧比較及分析
本節將本文方法與其他夜間去霧方法在合成數據集上進行去霧效果比較,用PSNR 與SSIM 作為評估標準。表2 表示圖像去霧質量評估,結果表明本文方法無論是PSNR 還是SSIM 都比其他方法較高,這是因為:使用Msmall-Patch訓練方法(重度懲罰損失)加強了對糟糕區域或容易被誤判區域的懲罰,提升了PSNR與SSIM值;加入感知損失加強了對高級特征的提取,提升了SSIM 值;加入對抗感知損失加強了對中低級特征的提取,盡可能地保留全局結構,提升了PSNR 值。同時,用四個測試集例子進行說明,如圖7 所示:前兩行表示黃色背景合成霧圖,后兩行表示白色背景合成霧圖,可以看出,文獻[5]、文獻[6]、文獻[9]方法普遍存在著顏色失真(如黑框區域)及霧殘留,這是由于對大氣光取值不準確造成的;文獻[5]及文獻[6]方法在圖片天空出現塊效應、偽影及噪聲(如白框區域),這是由于對透射率取值不準確造成的;文獻[15]方法去霧后存在模糊現象且仍有霧殘留,這是由像素損失本身缺陷造成的;文獻[22]方法會出現少量噪聲及偽影,這說明感知損失缺乏對低級特征的提取,僅加入感知損失不足以消除CGAN 產生的噪聲偽影。而本文方法產生的去霧與顏色保真效果與真實清晰圖較接近,這是因為本文方法跳過了估計透射率與大氣光步驟,避免了因取值不準確而導致的重建圖像出現噪聲、顏色失真等現象;另外,使用Msmall-Patch 訓練方法(重度懲罰損失)提高了生成器與鑒別器的互相抗衡能力,使生成的圖片質量更好;同時結合感知損失與對抗感知損失避免了像素損失缺點,加強了對噪聲的懲罰,提升了生成圖片細節。
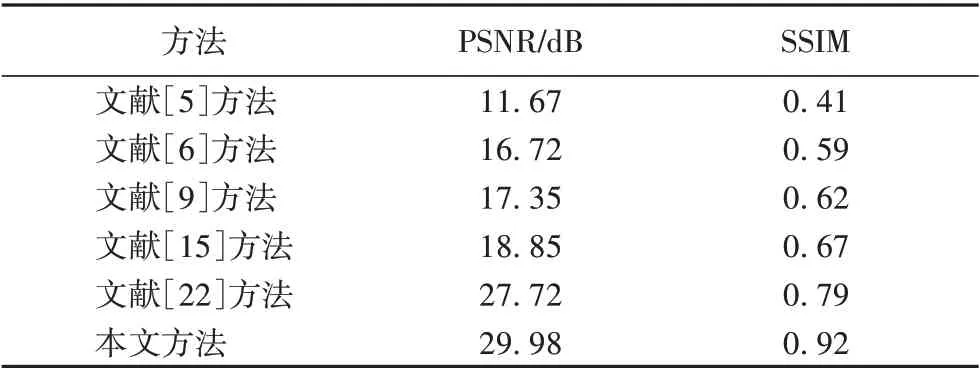
表2 本文方法與其他方法在合成霧圖上的去霧質量評估Tab. 2 Dehazing quality evaluation of the proposed method and other methods on synthetic images with haze

圖7 本文方法與其他方法在合成霧圖的去霧效果Fig. 7 Dehazing effect of the proposed method and other methods on synthetic images with haze
2.5 真實霧圖上的比較及分析
盡管本文方法在合成霧圖上有較好的去霧效果,為進一步驗證本文方法的優越性,在真實霧圖上將本文方法與其他夜晚去霧方法及先進CGAN 去霧方法比較,如圖8 所示,前兩行表示黃色背景真實霧圖,后兩行表示白色背景真實霧圖,可以看出,文獻[5]方法雖然可以去掉一些霧,但會出現顏色失真并有大量噪聲出現,這是因為其提出的大氣散射模型不具有魯棒性;文獻[6]方法雖然可以很好地去掉光輝,但容易出現大量偽影及塊效應,這是因為其對透射率取值不準確造成的;文獻[9]方法盡管能去掉一些霧及塊效應,但仍有霧殘留及存在顏色失真,這說明傳統大氣散射模型不適應夜間去霧;文獻[15]方法去霧后存在模糊現象,這說明像素損失對噪聲的懲罰能力弱;文獻[22]方法會有少量偽影存在,這說明僅提取高級特征不會完全去除偽影;本文方法能產生較好的去霧效果與顏色保真,是因為本文方法跳過估計中間參數步驟,而且針對CGAN 產生的噪聲及偽影,提出Msmall-Patch 訓練,加強了生成器與鑒別器的同步性訓練,加快收斂,提高了生成圖片質量,并提出新的復合損失函數提高了對高級與低級特征的提取,加強了對噪聲的懲罰,使用UDNet網絡減少了特征丟失,因此MP-CGAN模型可以產生較好的去霧效果。

圖8 本文方法與其他方法在真實霧圖的去霧效果Fig. 8 Dehazing effect of the proposed method and other methods on real images with haze
3 結語
本文提出新的條件生成對抗網絡(MP-CGAN)實現夜晚圖像端對端去霧,跳過估計透射率與大氣光步驟,避免了傳統夜間去霧方法的缺點;為驗證本文方法優越性,分別在合成霧圖與真實霧圖與CGAN 去霧方法及其他夜間去霧方法比較,實驗表明本文方法具有較好的去霧效果與顏色保真;這證明,本文提出的Msmall-Patch 訓練方法提高了對噪聲的懲罰力度,復合損失函數提高了生成圖片質量;同時,UDNet 網絡能更有效地去霧;然而,網絡允許輸入圖片大小固定,不具有靈活性,未來工作研究如何使網絡具有更好的靈活性。
猜你喜歡
小讀者(2020年2期)2020-03-12 10:34:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
趣味(語文)(2018年1期)2018-05-25 03:09:58
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
學苑創造·A版(2015年6期)2015-07-01 09:00:12
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
英語學習(2007年8期)2007-12-31 00:00:00
時文博覽(2007年9期)2007-12-31 00:00:00
