超密集部署下以用戶為中心的分簇與資源分配
2020-06-06 02:27:44尼俊紅尹喜陽李霜冰
科學技術與工程 2020年12期
尼俊紅,張 爍,尹喜陽,李霜冰
(1.華北電力大學(保定)電氣與電子工程學院,保定 071003;2.國網天津市電力公司信息通信公司,天津 300010)
部署非常密集的接入節點(如微基站、家庭熱點)是5G解決飆升的移動業務需求的關鍵方法。在超密集網絡(ultra-dense network,UDN)場景中[1],用戶與其相關聯的接入節點之間的距離大大減小,因此可以獲得更強的無線鏈路增益以及更好的頻譜空間重用,系統性能得到顯著提高。由于UDN中小基站彼此距離很小、數量較多,在這種情況下,用戶可能經歷更多的小區間干擾。因為來自鄰近小區的信號強度與服務小區的信號強度處于同一等級,大多數用戶都可以被看作信干噪比(signal to interference plus noise ratio,SINR)比較差的邊緣用戶,因此,抑制干擾對于UDN來說是非常重要的。協同多點(coordinated multiple-point,CoMP)傳輸作為抑制小區間干擾(inter-cell interference,ICI)的有效方法[2],在長期演進(long term evolution,LTE)和其升級版(LTE-advanced,LTE-A)中得到了廣泛研究和應用,同時也被認為是可以在5G[3]以及未來云無線接入網(cloud radio access network,C-RAN)架構中[4]繼續發揮重要作用的干擾消除技術。
利用CoMP技術可以將多個基站的數據同時傳輸給一個特定的用戶設備,將這多個基站劃分到一個所謂的“簇”中,這樣就引入了分簇的概念。分簇方式可以分為以網絡為中心的分簇(network-centric clustering,NCC)和以用戶為中心的分簇(user-centric clustering,UCC)[5]。NCC是從網絡的角度出發,將宏基站區域內的小小區劃分為若干互不相交的簇,一個簇服務區域內的所有用戶由簇中的所有小區或部分小區提供服務。這種方法的優點是易于實施,但簇邊緣處的用戶易遭受簇間干擾。UCC方法是每個用戶單獨選擇自己的小區簇,簇與簇之間允許重疊。這種方法消除了邊緣的簇間干擾問題,能夠提供更好的SINR增益,但需要更高的回程容量并且更復雜。
傳統的靜態分簇中[6],小基站不可以同時屬于兩個虛擬小區簇,一旦小基站加入到一個虛擬小區簇,簇中的小基站以及小基站的數量就會保持不變,這種類型的虛擬小區簇無法適應用戶位置和信道條件的變化。為了解決靜態分簇的問題,動態分簇以增加基站之間的信令開銷為代價,根據用戶的位置和信道條件,動態地生成簇以最大化整個系統的性能,例如系統吞吐量、系統能效等。Papadogiannis等[7]利用了一種貪婪算法以最大化和速率為目標進行動態分簇,直到所有基站都成功加入某個簇。盡管非重疊的動態分簇可以優化系統性能,仍會有部分用戶受到屬于其他虛擬小區簇的臨近基站的干擾,因此可重疊分簇開始受到研究者的關注。Marsch等[8]研究了具有三個協作基站的分簇,并證明了可重疊分簇和非重疊分簇相比可以更加接近理想分簇的性能。Feng等[9]提出了一種可重疊的動態分簇算法,該算法利用基站的可重疊分簇,實現了整個網絡的無縫覆蓋,然而這種可重疊分簇的網絡是正六邊形網絡,實際中微基站無法這樣規則的部署。
在未來的網絡建設中,用戶的業務需求多樣化,每個用戶對流量、時延、中斷率的要求不統一,例如視頻業務對流量及中斷率要求較高而對時延并不那么敏感,而車聯網業務對時延要求較高但對流量的需求并不算大[10]。因此未來的系統性能應該以用戶為中心去考慮問題,而不是繼續在網絡為中心的基礎上不斷優化。Bassoy等[5]以最大化小區簇的頻譜效率為目標,提出了一種兩階段的UCC分簇算法,在盡量減小對頻譜效率影響的條件下平衡簇內負載。Li等[11]設計了一種結合動態點降低功率(dynamic point reduced power,DPRP)和聯合傳輸的基于UCC的CoMP方案,在不會使吞吐量降低太多的基礎上提高能效。Li等[12]提出了一種5G CoMP系統的多媒體傳輸智能調度和功率控制框架,根據親和傳播(affinity propagation,AP)分簇算法在每個物理資源塊(physical resource block,PRB)中為每個邊緣用戶確定簇;然后,基于納什議價解決方案(nash bargaining solution,NBS),開發了一種考慮傳輸延遲的功率控制方案,以保證用戶的廣義比例公平性。
現有的研究文獻少有考慮分簇后移動用戶的服務質量問題,為了優化移動用戶在分簇后的平均頻譜效率和用戶吞吐量的滿足率,在考慮CoMP簇內資源塊約束的條件下,設計以用戶為中心的分簇算法。
1 系統模型
研究控制-數據分離架構(control-data separation architecture,CDSA)下的超密集異構網絡場景,考慮下行鏈路傳輸。假設宏基站用戶使用正交的頻譜資源,微基站復用宏基站的全部頻譜資源。宏基站位于區域中心,宏基站覆蓋范圍內隨機部署了n個微基站,分布有m個移動用戶,定義移動用戶和微基站的單元索引分別為i和j。
1.1 用戶與單基站間的鏈路
移動用戶i和基站j之間的信干噪比如式(1)所示:
(1)
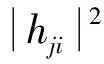
1.2 用戶與多基站間的合作鏈路
定義移動用戶i與基站j的關聯情況:
(2)
移動用戶i和基站組Ci之間的信干噪比如式(3)所示:
(3)
結合香農公式,得到在t時刻移動用戶的吞吐量為
(4)
2 以用戶為中心的分簇
將用戶分為宏基站用戶設備(cellular user equipment,CUE)和微基站用戶設備(small-cell user equipment,SUE),假設基站與用戶間的平均接收功率已知,用戶可以自行選擇成為CUE或者SUE。重點研究對象是服務SUE的微基站的選擇問題,以下移動用戶均指的是SUE。為了支持用戶的移動性和一定的速率需求,應對用戶在移動過程中的服務質量問題,為每個移動用戶設定了一個隨機的速度向量,并根據速度向量對用戶在下一個分簇周期起始時刻的位置進行預判,并以此為依據進行預分簇,但用戶位置的預測算法不在的研究范圍。
2.1 遍歷分簇算法
假設用戶在每一個分簇周期起始時刻的位置可以估計,并將一個分簇周期分為T個時段。由于動態分簇復雜程度高,信息交互過于頻繁,采用可增長分簇周期的半動態分簇,即根據移動用戶信道條件為每個用戶預先選用一個協作集,然后通過計算不同基站組合的服務質量來確定最終提供服務的協作簇。
定義用戶-基站關聯矩陣:
(5)
當關聯矩陣中某一個元素aji=1時,表示用戶i接入基站j。關聯矩陣第i列中非零元素對應的行索引集合Ci表示服務于移動用戶i的協作簇。
定義移動用戶i在一個分簇周期內的平均頻譜效率為
(6)
則目標函數可表示為
(7)
約束條件:
(8)
aji∈{0,1}, ?j∈N
(9)
(10)
式(7)的約束條件中:式(8)表示基站j為用戶分配的帶寬資源需要小于最大的系統可用帶寬,W表示基站的總帶寬;式(9)表示用戶的關聯矩陣元素的取值范圍;式(10)表示服務用戶的基站簇滿足個數限制,即簇成員的個數小于k1。由于式(7)無法使用常規計算進行求解,因此遍歷用戶i的所有可能備選基站來求解目標函數。
算法實現:
Step1根據用戶的速度向量判斷用戶是否為移動用戶,若是,按以下步驟為該用戶分配基站組。
Step2若不是移動用戶,則根據用戶當前的信道增益為其分配基站組。
Step3重復Step1、Step2步驟。
2.2 預分簇方案
由于遍歷分簇算法需要計算備選基站所有組合的增益大小,計算量較大,為了降低分簇算法的計算復雜度,設計一種預分簇的方案。考慮當前用戶的下一移動位置,對下一移動位置的基站增益進行預估計,并引入權重因子。在這種方法中不需要對所有備選基站的組合進行計算,因此有效降低了計算的復雜程度。
(11)
3 基站組的資源分配
使用結合優先級的著色法,根據用戶的信道條件為各個用戶分配資源塊。假設功率均分在每個資源塊上,對于簇間CoMP而言,重點就在于需要滿足進行聯合傳輸的基站使用相同的資源,對于本論文而言即為同一個用戶提供服務的協作小基站使用相同資源塊。基站的資源塊分配方案如式(12)所示:
(12)
約束條件:
bij,r∈{0,1},r∈{1,2…,50}
(13)
(14)
(15)
(16)
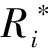
為了避免信道條件較差的用戶的服務得不到滿足,設置資源分配的優先級,定義用戶在一個分簇周期內的吞吐量滿意度為
(17)
則可以根據式(18)得出所有用戶的優先級調度值Q,對所有優先級調度值進行升序排序,根據由小到大的順序依次對用戶進行資源塊的分配。
(18)
根據上一節的分簇結果,結合優先級對移動用戶逐一進行資源分配,具體資源分配步驟如下:①初始化資源塊占用標識bij,r=0,計算分簇后的用戶達到目標速率所需資源塊最少個數,并根據式(18)計算各個用戶的優先級;②對高優先級用戶優先分配資源并更新資源塊占用標識;③輪詢所有用戶后可能會有個別未得到服務用戶,記錄;④對未得到服務用戶重新進行分簇并執行①、②,直到所有用戶都得到服務。
4 仿真結果
4.1 仿真參數
表1所示為仿真參數。路損參數中d表示基站與用戶的距離,單位為km。
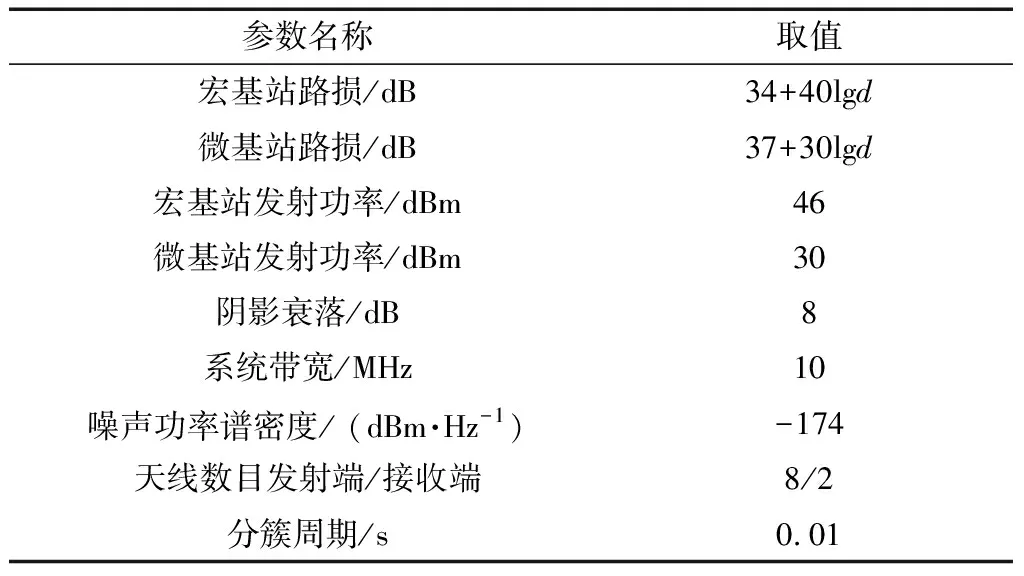
表1 仿真參數Table 1 Simulation parameters
考慮下行鏈路,區域中心位置布置一個宏基站,覆蓋半徑為500 m,在其覆蓋區域內隨機分布微基站及用戶。基站的位置服從隨機均勻分布,用戶分為靜態用戶及移動用戶。移動用戶的產生概率為0.9,移動速度為30 m/s,方向隨機;用戶的初始位置也服從隨機均勻分布。一個分簇周期內的時段T定為4,系統的資源塊個數為50,備選基站的閾值δ為3 dB,備選基站個數最大為k2=7個,預分簇的權重因子α設置為0.8,仿真次數均為5 000次。
4.2 仿真結果及分析
原算法為文獻[13]的分簇算法,對原算法、遍歷算法以及預分簇算法進行仿真和性能比較,系統內基站和用戶數量均為100。圖1為移動用戶的速率累積分布圖,圖1中虛線表示該算法中簇的大小是固定為4;實線表示該算法中簇的大小為可變的,簇大小根據用戶接收信號的強弱變化。用戶接收到的信號較好時,基站簇的大小較小,最小值為2;用戶接收到的信號較差時,基站簇的大小較大,最大值為4。
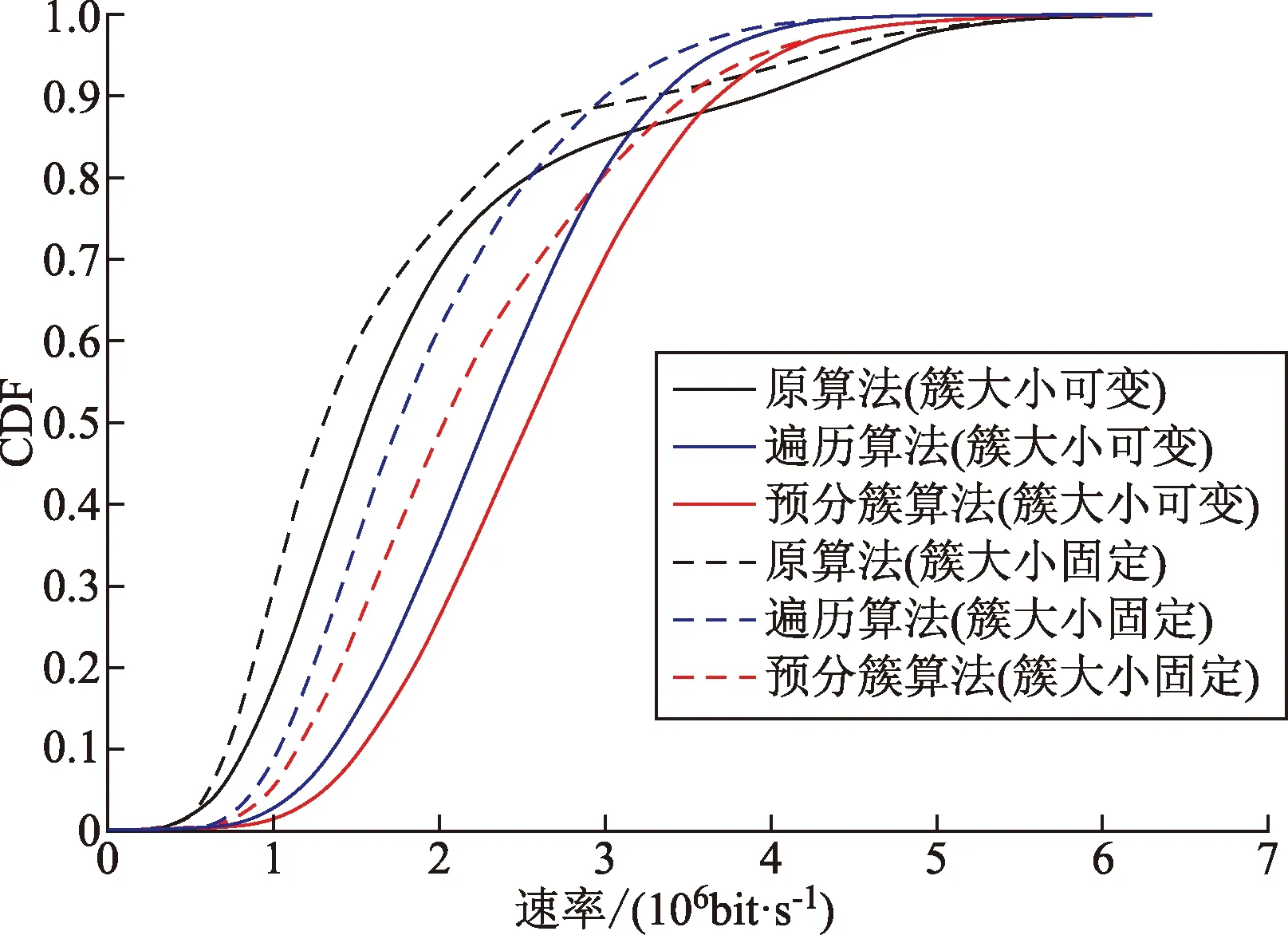
圖1 移動用戶速率累計分布Fig.1 Rate cumulative distribution of mobile users
圖1為移動用戶速率累積分布函數(cumulative distribution function,CDF)圖,可觀察到原算法移動用戶的速率曲線不圓滑,這是由于原算法在每次分簇周期的開始只考慮當前的信干噪比,并未考慮用戶在確定好分簇基站組后的移動給用戶通信帶來的負面影響,尤其是信干噪比較差的用戶,影響更加嚴重。原算法中低速率的用戶較多,而本文算法在滿足用戶的速率要求上表現較好,即較多的用戶平均速率大于1 Mbit/s。統計仿真結果,得到移動用戶滿足平均速率大于1 Mbit/s的比率如表2所示。

表2 比率統計結果Table 2 Statistics results of ratio
表2中算法1、2、3分別為原算法、遍歷算法和預分簇算法,-1和-2分別代表固定的分簇大小和可變的分簇大小。從表2中可以看出,對應每一種算法,簇大小可變的分簇方式相比簇大小固定的分簇方式在滿足用戶的需求速率方面做得更好。圖2為移動用戶的頻譜效率累積分布。由圖2可以看出,簇大小固定的算法頻譜效率要優于簇可變的算法,這是由于對那些接收信號質量較好的用戶,協作簇大小不會改變,依然會有較多的基站參與對其進行協作傳輸,從而提高了這部分用戶的頻譜效率。
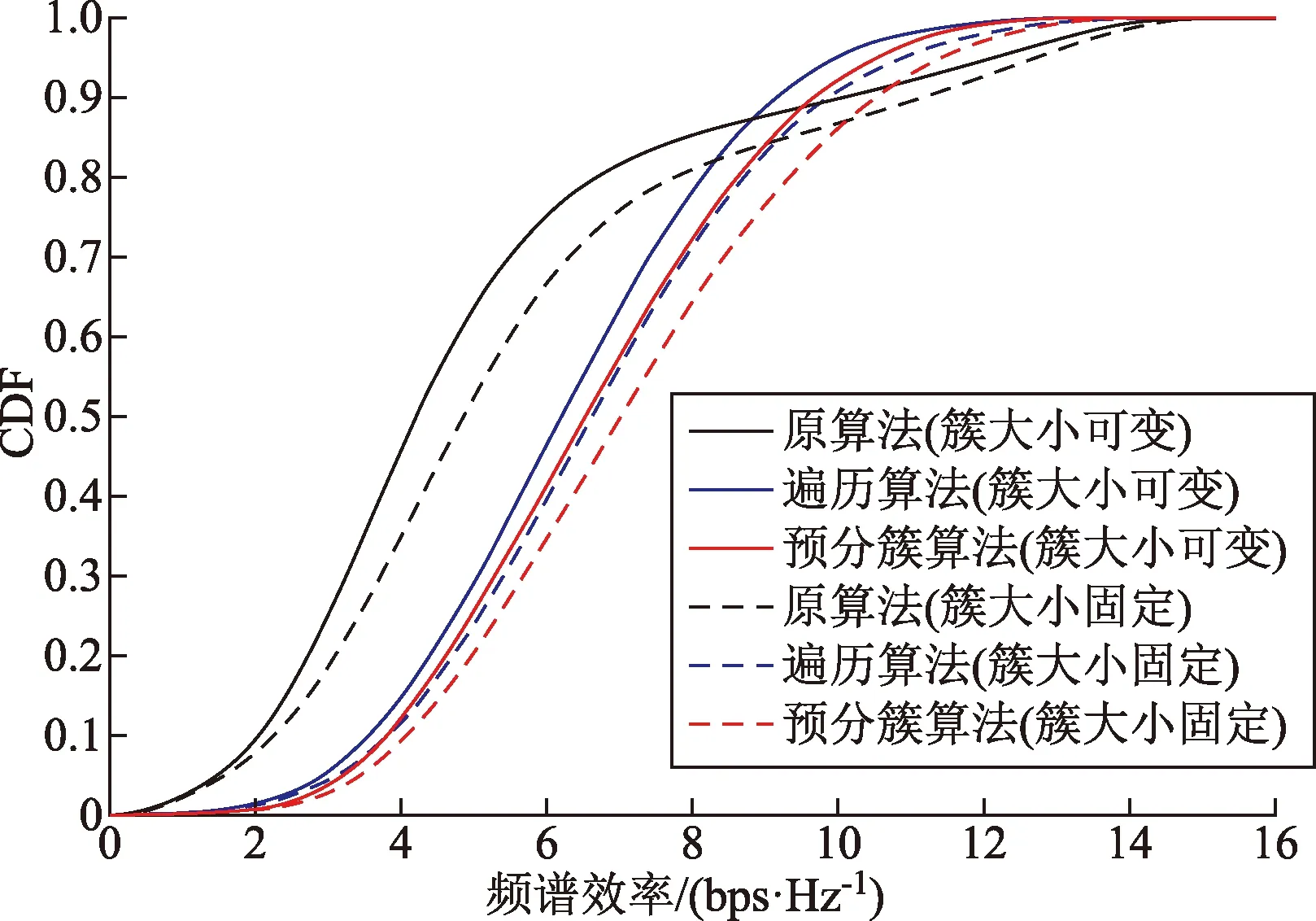
圖2 頻譜效率累積分布Fig.2 Cumulative distribution of spectral efficiency
從所有用戶的平均頻譜效率的統計值和系統中平均每個用戶的頻譜效率這兩個方面來驗證選擇的預分簇的權重值。
圖3為預分簇中權重對用戶平均頻譜效率占比的影響。對5 000次仿真中所有移動用戶的平均頻譜效率進行統計,計算得出平均頻譜效率大于4的所占比率。由圖3可明顯看出,當預分簇的權重為0.8時,用戶平均頻譜效率大于4的比率較大,效果較好。
圖4為權重變化對系統內每個用戶的平均頻譜效率的影響,運行5 000次仿真后取平均值,可得出權重值為0.8時系統內每個用戶的平均頻譜效率最大。
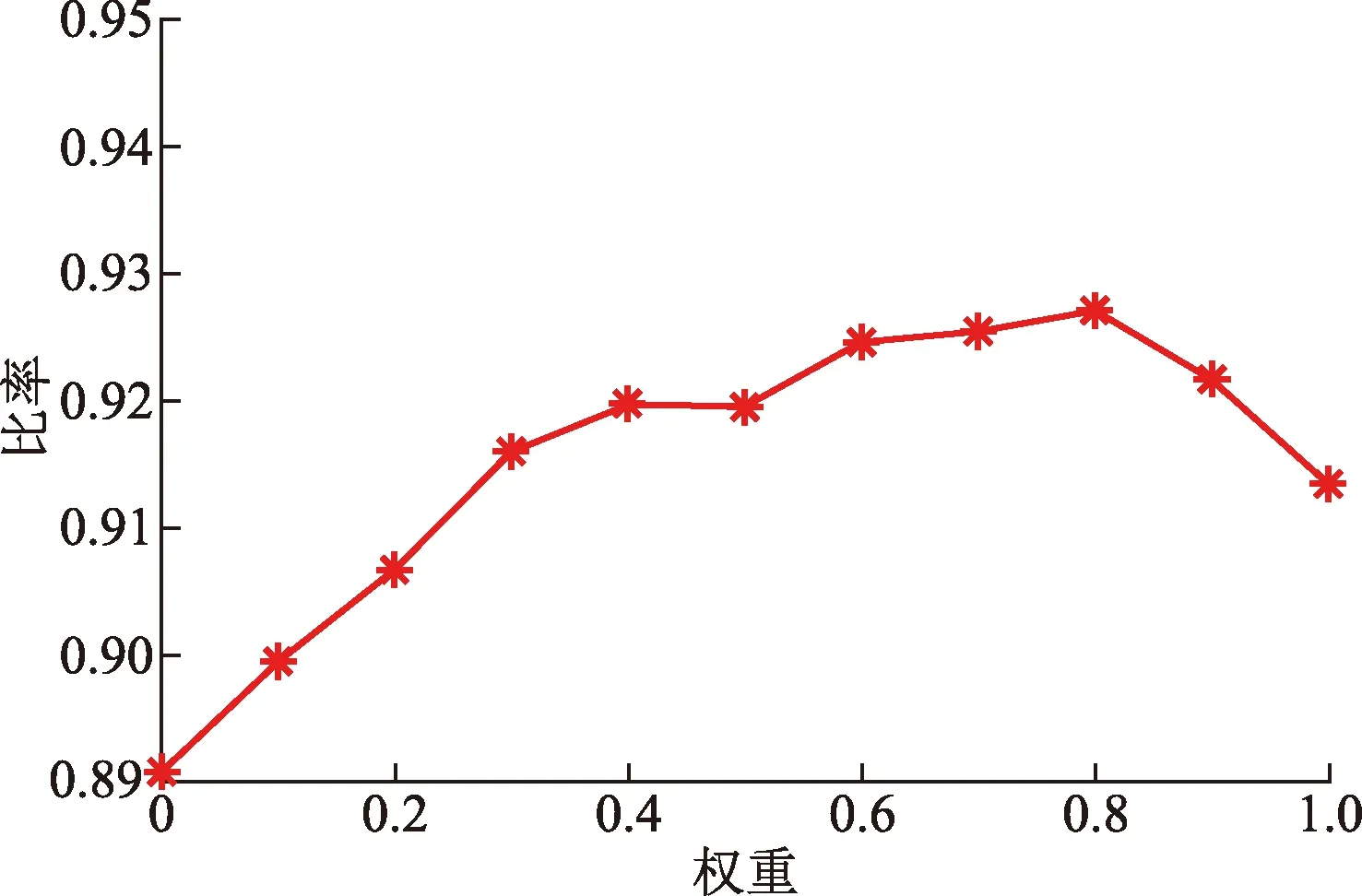
圖3 權重變化對頻效占比的影響Fig.3 Effect of weight change on frequency ratio
5 結論
本文算法考慮了超密集部署下的異構網絡中用戶移動帶來的負面影響,結合對下一調度時刻用戶位置的預測,在用戶選擇基站組方面進行預處理,考慮CoMP傳輸基站的資源約束條件設計了以用戶為中心的分簇算法,并比較了同種算法中固定大小的分簇與可變大小的簇的優劣。本文算法與原算法相比在用戶需求的滿足率上得到了較大的提升,在平均頻譜效率上也有所改進。
猜你喜歡
甘肅教育(2020年14期)2020-09-11 07:57:42
中學生數理化(高中版.高考數學)(2020年5期)2020-06-02 09:19:08
商周刊(2017年9期)2017-08-22 02:57:49
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
時代英語·高二(2015年1期)2015-03-16 00:08:11
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
創業家(2015年5期)2015-02-27 07:53:25
