基于GA 和網絡日志的人格傾向分析
2020-06-08 08:04:24古勇成陳平華秦勇
現代計算機 2020年12期
古勇成,陳平華,秦勇
(1.廣東工業大學計算機學院,廣州510006;2.東莞理工學院計算機學院,東莞523808)
0 引言
如今,網絡已經滲透到人類工作、學習、生活的方方面面,并對人們的生活方式與心理行為產生了深刻的影響。我們應該看到,網絡在給人們帶來便利與進步的同時也不可避免地引發許多問題,如網絡成癮、網絡犯罪等。因此,近年來互聯網使用方面的心理學研究也受到了國內外學者的廣泛關注[1]。
心理學家們曾為了深入了解網絡用戶,關注并研究了用戶人格特性與網絡使用行為之間的關系。在過去的研究表明,用戶的人格特性可以通過用戶的網絡行為來體現。在對網絡用戶人格的分析研究中,目前的方法是利用社交網絡上的數據來實現[2]。在各種網絡媒體(例如微博、Facebook 等)[3-5]上的研究也證實了這一方法的可行性。
但是,以往的這些研究內容主要集中于人格分析在社交網絡上的實現,適用面僅局限于社交網絡上的用戶,可以說該方法只利用了用戶在網絡空間行為中的一部分數據而已,對于一些社交網絡數據量少或沒有的用戶群體來說,該方法并不適用于他們,因此光靠社交網絡上的數據不能實現對每個上網用戶人格情況的分析。
故針對上述問題,本研究在總結人格測量的標準與方法的基礎上提出了一種基于網絡日志信息和遺傳算法相結合的分析方法。該方法所使用的用戶網絡特征數據為網絡日志數據,該數據直接與每個上網用戶相聯系,能直觀全面地反映每個用戶的上網行為習慣,從而為用戶人格傾向的分析預測提供更為客觀、全面、準確的數據來源。且結合遺傳算法能夠從廣闊的網路日志特征空間中,尋找出最適合用于人格傾向分析的特征組合,從而達到降低特征維度,提高模型精度。
1 遺傳算法介紹
1.1 遺傳算法定義
遺傳算法(Genetic Algorithm,GA)是模擬達爾文生物進化論的自然選擇和遺傳學機理的生物進化過程的計算模型,是一種通過模擬自然進化過程搜索最優解的方法。其主要特點是直接對結構對象進行操作,不存在求導和函數連續性的限定;具有內在的隱并行性和更好的全局尋優能力;采用概率化的尋優方法,不需要確定的規則就能自動獲取和指導優化的搜索空間,自適應地調整搜索方向。其中,選擇、交叉和變異構成了遺傳算法的遺傳操作;參數編碼、初始群體的設定、適應度函數的設計、遺傳操作設計、控制參數設定五個要素組成了遺傳算法的核心內容[6]。
1.2 遺傳算法原理及步驟流程
遺傳算法對于特征選擇的基本原理是用遺傳算法尋找到一個最優的二進制編碼,編碼中的每一位都對應著特征向量表中的一個特征,若第i 位為“1”,則表示對應的特征被選取,為“0”,則表示該特征未被選取,最后所有選取的特征將用于分類器的構建。其基本步驟為:
(1)編碼:采用二進制的編碼方式,選中的特征位為“1”,沒有選中的特征位為“0”。
(2)初始化種群:隨機生成N 個攜帶特征基因的群體。
(3)適應度函數:適應度函數用于衡量個體的優劣性。即用一個數值來計算出攜帶不同特征基因個體對于解決問題的優劣程度。
(4)選擇:將適應度最大的個體,即種群中最好的個體根據選擇策略選擇出來,就如同自然界中優勝劣汰的規律。
(5)交叉和變異操作:對于經過選擇后的群體,挑出一部分作為父代,一部分作為母代,進行基因的交叉。同時設定一個變異的概率,使群體的基因能夠發生變異。交叉和變異均是用于擴大特征基因的組合方式,使問題的解不至于陷入局部最優的情況。
(6)繁衍:設置一個種群的繁衍次數,即對于上述步驟4、5、6 進行迭代操作,同時記錄下最優的個體。算法執行流程如圖1 所示。
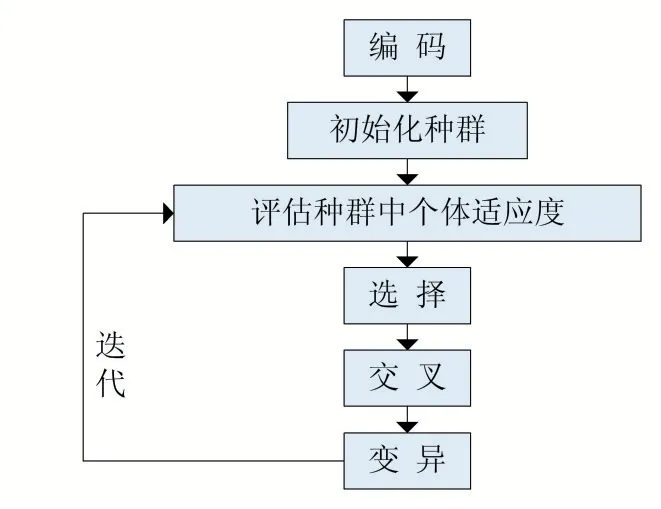
圖1 遺傳算法流程圖
2 基于遺傳算法(GA)和網絡日志的人格傾向分析模型
通過用網絡日志數據作為人格傾向分析模型的輸入,能夠全面地反映上網用戶的上網行為特征,再通過結合遺傳算法模型,便可以得到人格傾向分析的最優特征數據組合。其模型結構如圖2 所示。

圖2 模型結構圖
2.1 模型的輸入處理
2.1.1 標簽數據的選取及處理
Myers Briggs Type Indicator(MBTI)是人格類型說的典型代表,MBTI 是一種基于量表的人格測評方法,它的理論原型是分析心理學的創始者Carl G Jung 的人格類型說,人格類型說的理論類似于數據挖掘中的分類問題,即假定某一類型的人的行為與其他類型人的行為明顯不同,把全部個體分為固定的幾個類別。MBTI 量表的結構清晰,完全符合理論模型,具有非常理想的結構效度,而一個量表的信效度最根本的證據就是結構效度。故采用MBTI 量表來評估用戶的人格內外傾向是具有一定的信效度的。
本次的人格數據是通過在校內網絡問卷平臺上發布邁爾斯布里格斯類型指標(MBTI)量表來獲得的。MBTI 的指標類型如表1 所示,評估結果展示如圖3所示。

表1 MBTI 類型指標表
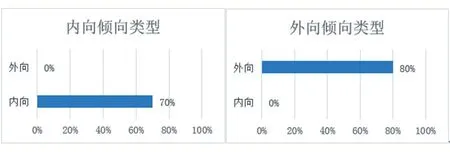
圖3 MBTI評估結果圖
處理方法:
對于樣本中內外向傾向類型的數據,通過對該量表的了解,為了讓樣本數據更加具有區分性,我們設定30%作為該數據的一個閾值,對于大于該閾值的數據,我們進行保留,并進行標簽二值化處理,將外向類型標記為“0”,內向類型標記為“1”。2.1.2 特征數據的選取及處理
源日志主要來自于專門的網絡日志采集服務器,通過用戶申請訪問網絡的情況,采集其訪問的鏈接數據,從而獲得用戶的網絡日志信息。在征得學生本人的同意下,本研究采集了在校1000 名學生一個月的網絡日志信息。日志格式為:“用戶在某時間點訪問某網絡類型的記錄”。日志樣本如表2 所示。
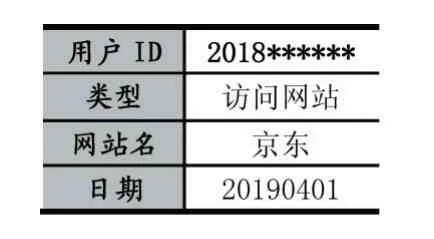
表2 日志樣本
日志信息處理:
(1)對日志中的關鍵詞信息進行提取,包括用戶訪問類型、網站的名字、時間和日期。
(2)對于提取到的關鍵信息,把同義及相近的類型歸在為一類,做合并處理。
(3)制定上位詞,如“購物”是“天貓,淘寶,京東”的上位詞替代,用“購物”這一上位詞作為該類型的集合名稱。
(4)對一個月內各類型的網絡日志數據進行統計,這樣可以降低短期內偶發性網絡數據的影響,從而從一個較長的時間范圍內來分析用戶的人格傾向。
2.2 模型的訓練
本文的模型是基于遺傳算法(GA)的分析模型,其訓練方法主要是依據適應度函數的計算值和選擇策略的結果對有標記的監督樣本進行有限次的迭代操作,從而選出最適合用于區分人格內外傾向的特征組合方式。
2.2.1 適應度函數的選取
本文使用基于距離判據的適應度函數,該判據直接依靠樣本本身的數據進行計算,直觀簡潔,物理概念清晰。通過計算同類樣本之間的距離和異類樣本之間的距離來判斷樣本的可分性。其相應計算內容及公式如下:
(1)總體類內散布矩陣:
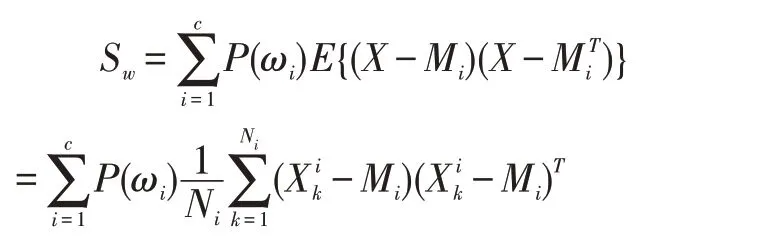
(2)總體類間散布矩陣:
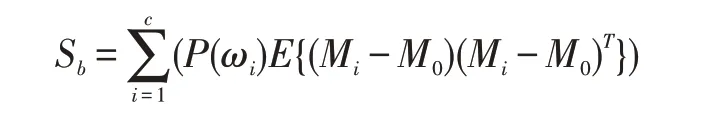
(3)適應度函數:
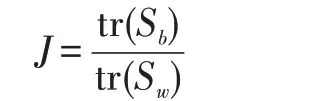
顯然,對于同類樣本來說,樣本之間的距離越小越好。對于異類樣本來說,樣本之間的距離越大越好。也就是說,同類樣本的距離越小,異類樣本的距離越大,模型的分類效果越好。故用類內散布矩陣Sw和類間散布矩陣Sb的跡來衡量類內距離和類間距離,進而給出的類間-類內距離判據J,J 越大,類別可分性越好。
2.2.2 選擇策略
本文使用輪盤賭的選擇策略。該方法是一種有放回的隨機采樣方法,根據每個個體適應度函數的計算值占群體適應度函數值之和的比值作為其能夠被選中進入下一代的概率,所以適應度函數計算值越高的個體越容易被保留下來。計算公式如下:
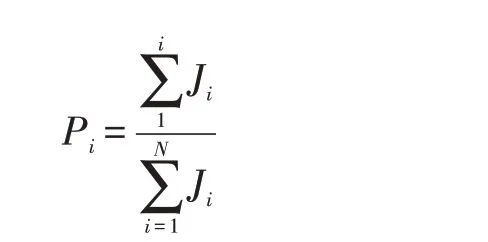
本文在訓練過程中采用如下改進策略:
(1)為避免選擇策略的隨機性,我們將適應度函數最優的個體直接保留到下一代迭代群體中
(2)在迭代算法前期,為保障群體的多樣性,避免算法過早陷入局部最優的狀況,我們將適當降低高適應度個體的適應度值,提高低適應度個體的適應度值,從而保證前期在進行選擇策略時,群體所含的解的空間范圍能夠盡可能的大。
最后,在實際的模型訓練過程中,為了得到穩定可靠的模型,減少偶然誤差的影響,實驗取10 次訓練結果的平均值。
3 實驗結果分析
3.1 實驗環境
表3 實驗環境及配置
3.2 參數設置
具體參數設置如下:初始種群N=100,迭代次數tmax=100,變異概率因子p=0.02,改進策略中前期指迭代次數t≤15。
3.3 實驗結果分析
本文用于人格傾向分析的網絡行為特征共有17種,分別是:視頻網站、彈幕視頻網站、旅行、聊天、體育、新聞、貼吧、微博、音樂、FM、閱讀、網頁游戲、手游、直播、漫畫、金融、購物。
模型結果如圖4。
由圖4 可以看出,當選擇的特征數為5 個時,遺傳算法模型中的適應度數值達到最大,說明此時選出的特征數據組合是最優的,其對人格內外傾向標簽的區分度最高,這組特征最能體現出不同人格傾向類型的上網行為差異,模型輸出的最優特征組編號為:[0.1.0.0.0.0.0.1.1.0.0.0.1.0.0.0.1],其對應的特征名為:[“彈幕視頻網站”,“微博”,“音樂”,“手游”,“購物”],在這5 個維度的網絡行為特征上,內外傾向的人格上網行為具有一定的區分性。
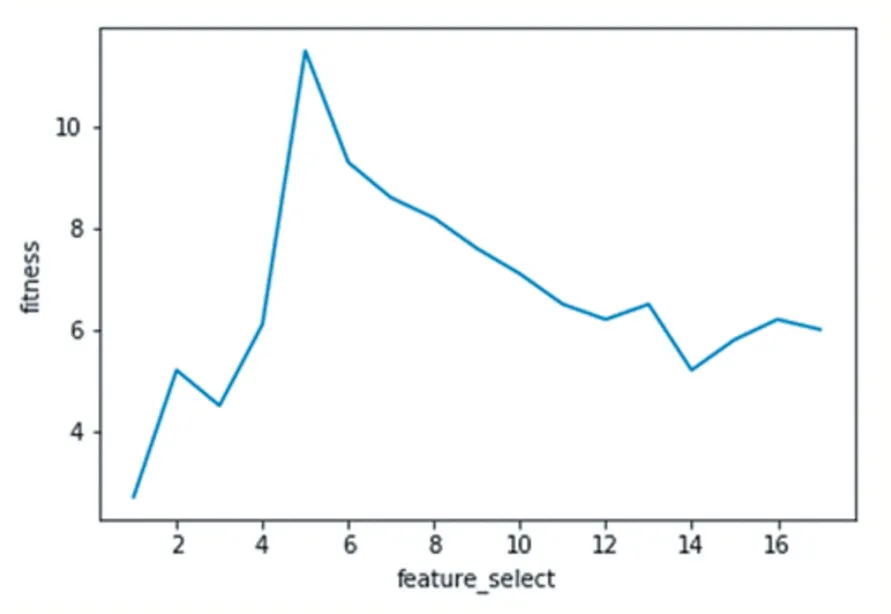
圖4 模型結果圖
為驗證基于網路日志的遺傳算法選出的特征組合的有效性,我們用機器學習模型中的分類模型來驗證其結果,模型的評價參數有:
P 值:樣本的總體精確率
R 值:樣本的總體召回率
F1 值:F1 分數同時考慮精確率和召回率,讓兩者同時達到最高,取得平衡。
該模型結果如表4。
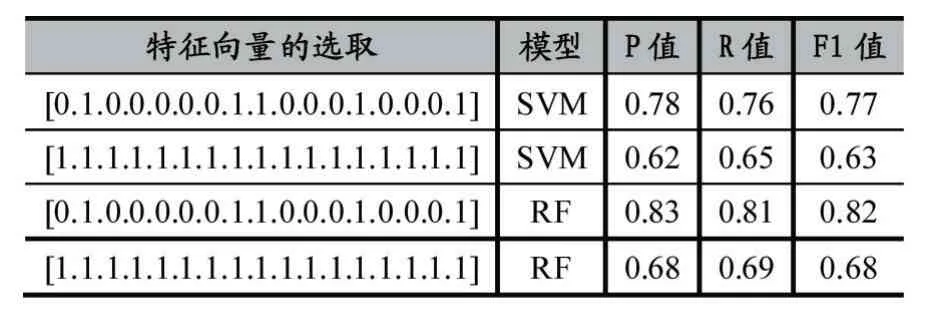
表4 分類模型驗證結果表
由表4 可知,實驗中特征向量的選取有兩種情況,一種是通過遺傳算法處理后,選取部分特征的情況:[0.1.0.0.0.0.0.1.1.0.0.0.1.0.0.0.1],一種是沒經過處理,全部的特征數據都采取的情況:[1.1.1.1.1.1.1.1.1.1.1.1.1.1.1.1.1],再通過用兩種機器學習的分類模型,SVM(支持向量機)和RF(隨機森林)對這兩種情況進行建模分析,證明了基于網絡日志的遺傳算法模型選出的網絡日志特征數據的組合是有效的,能夠明顯地提升分類模型分類內外人格傾向的精確度。
4 結語
本文首先介紹了遺傳算法的基本概念,之后對遺傳算法進行了部分改進,構建了一個用網絡日志信息分析人格內外傾向的模型,通過該模型的不斷迭代操作,最后我們得到了一組適應度值最高的特征數據組合,即對于內外傾向的人格來說,是最具有區分度的特征維度組合,并用機器學習的分類模型驗證了該分析模型結果的有效性。
